📖标题:Top-Theta Attention: Sparsifying Transformers by Compensated Thresholding
🌐来源:arXiv, 2502.08363
🌟摘要
🔸注意机制对于基于转换器的大型语言模型(LLM)的强大功能至关重要。然而,由于注意力对序列长度的二次依赖性,计算注意力是计算密集型的。
🔸我们介绍了一种称为Top Theta Attention或简称Top-j的新方法,该方法通过将不太重要的注意力元素与仔细校准的阈值进行比较,有选择地修剪它们。该方法大大提高了自关注矩阵乘法的效率,同时保持了模型的准确性,在生成解码期间将所需的V缓存行数减少了3倍,在预填充阶段将关注元素的数量减少了10倍。
🔸我们的方法不需要模型再训练;相反,它只需要一个短暂的校准阶段来适应分布变化,因此不需要重新校准不同数据集的阈值。与top-k注意不同,top-j消除了完全的向量依赖,使其适用于平铺和横向扩展,并避免了昂贵的top-k搜索。我们方法的一个关键创新是开发了高效的数值补偿技术,即使在积极修剪注意力得分的情况下,也有助于保持模型的准确性。
🛎️文章简介
🔸研究问题:Transformer模型中注意力机制存在计算和内存带宽瓶颈。
🔸主要贡献:论文提出了Top-Theta注意力方法,通过固定和校准的阈值来实现注意力稀疏化,从而显著减少计算所需的注意力元素数量。
📝重点思路
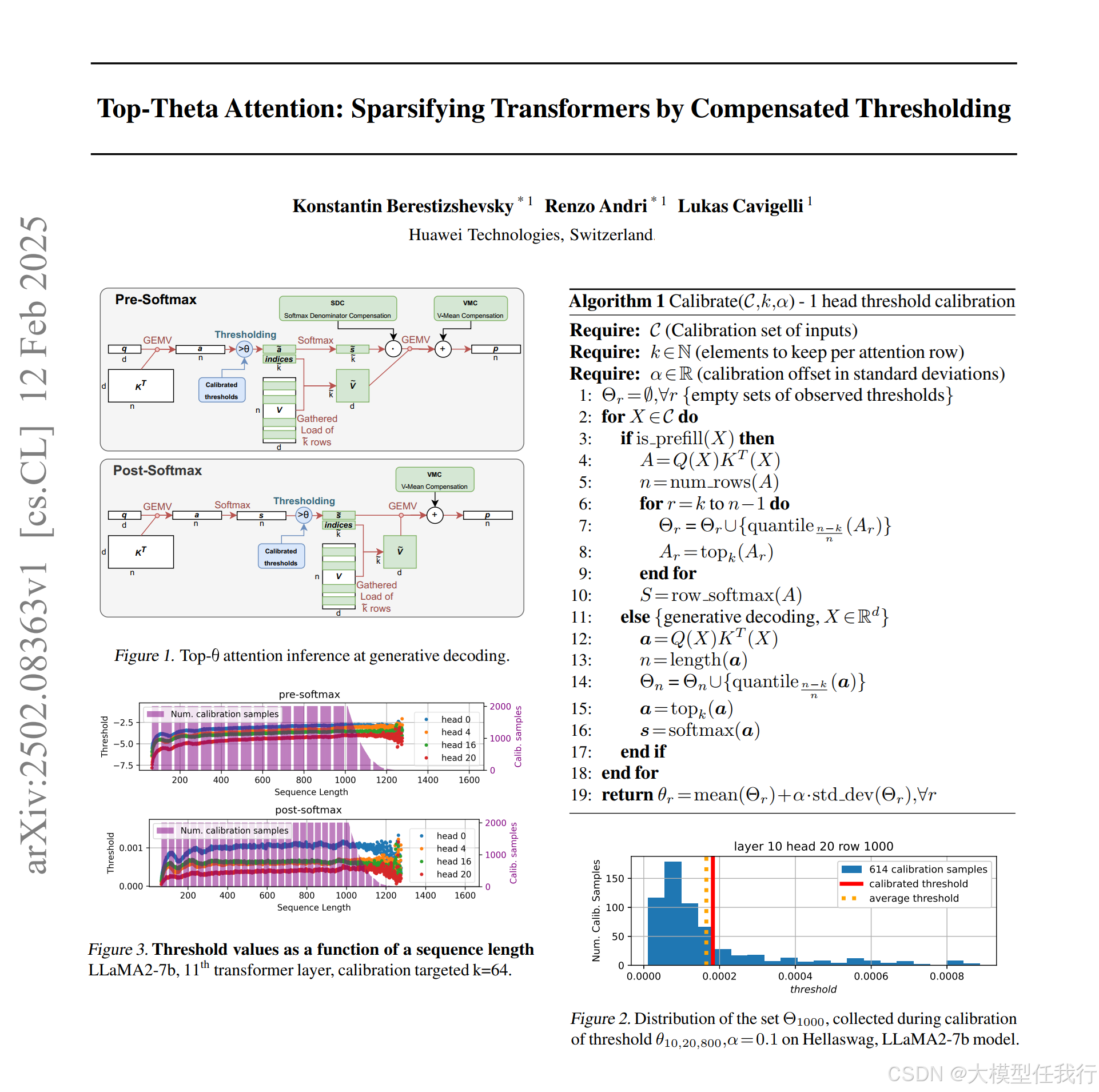
🔸阈值剪枝方法:通过校准每个注意力头的阈值,选择每个注意力行中平均约k个重要的注意力元素,从而减少注意力矩阵的计算量。
🔸补偿机制:为了弥补剪枝带来的精度损失,提出了两种补偿方法。①Softmax分母补偿(SDC):通过校准补偿值,恢复Softmax操作的分母,以保持注意力权重的归一化性质。②V均值补偿(VMC):通过补偿被剪枝注意力元素对最终输出的影响,恢复注意力机制的准确性。
🔸多k累积校准(MKC):一种灵活的校准方法,允许在不同的k值下动态调整阈值,从而实现更高效的剪枝。
🔸实验评估:通过在多个数据集和模型上进行广泛的实验,验证了Top-Theta方法在不同任务中的性能和鲁棒性。
🔎分析总结
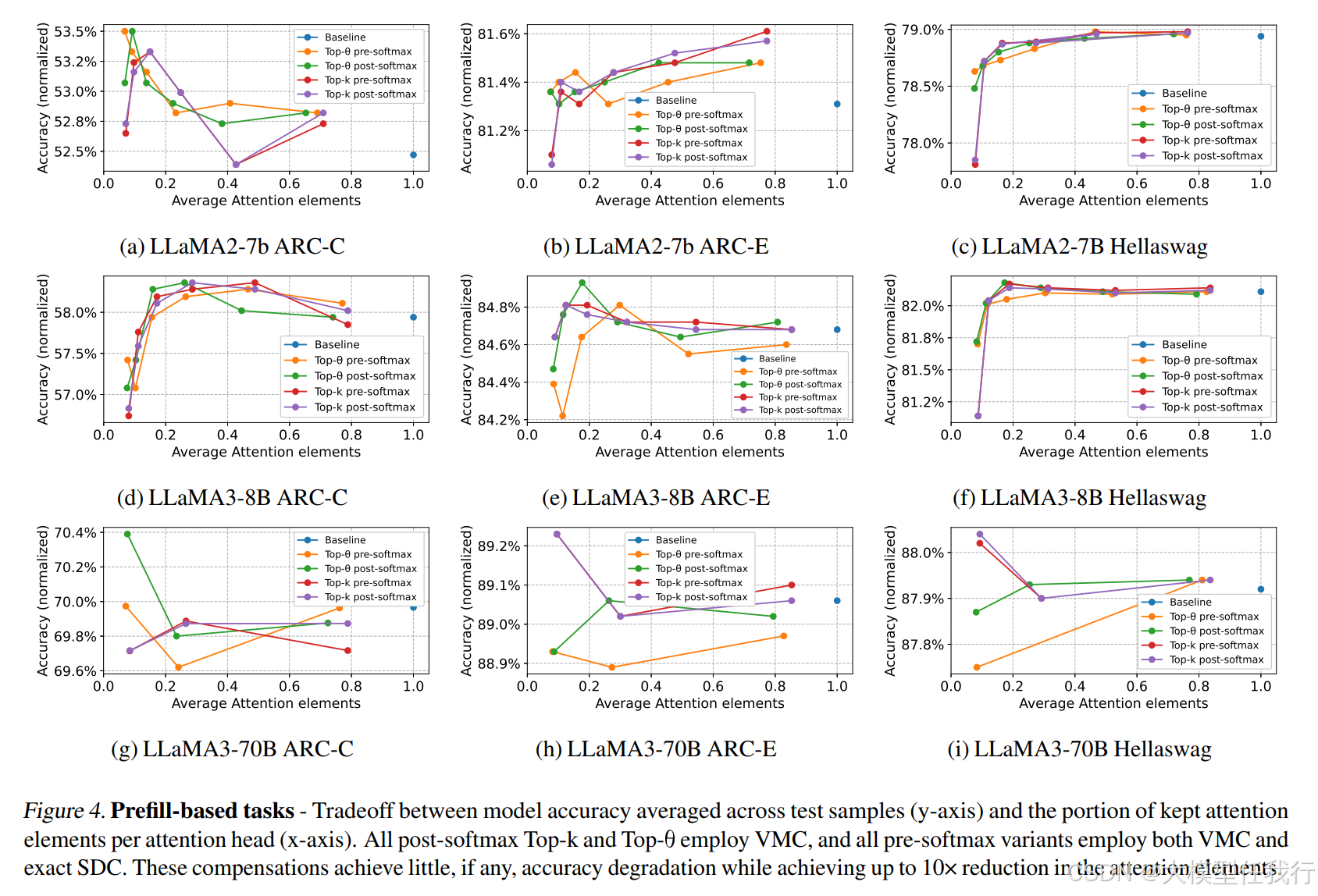
🔸Top-j与Top-k的比较:在问答和生成任务中,Top-j和Top-k的性能相似,但Top-j在减少计算量的同时保持了更高的准确性。
🔸后Softmax剪枝的优势:在问答和生成任务中,后Softmax剪枝比前Softmax剪枝更有效,且对模型性能的影响更小。
🔸模型阈值的鲁棒性:校准的阈值在不同输入域中具有较强的鲁棒性,表明阈值是模型的固有特性,只需一次性校准。
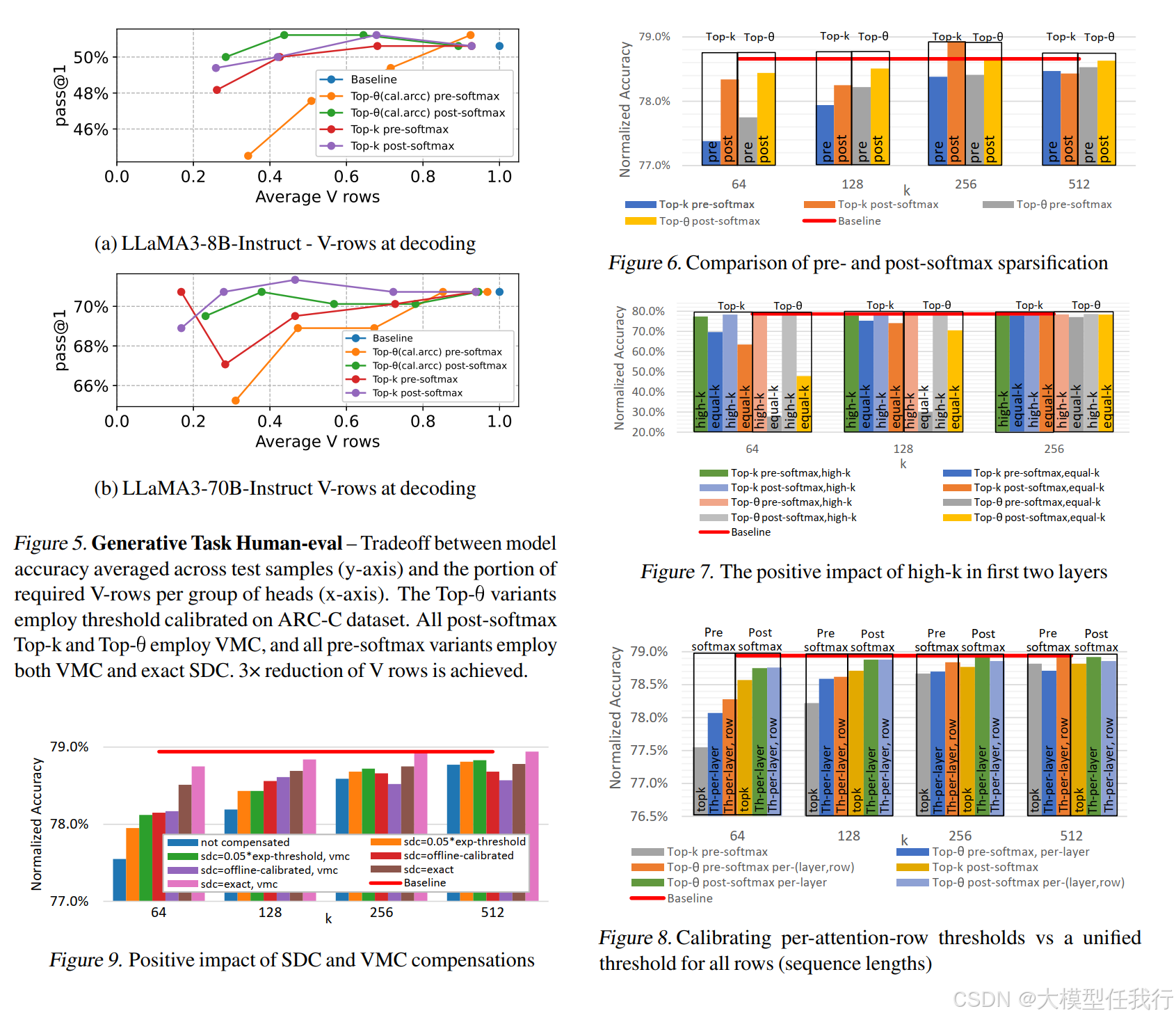
🔸生成任务中的性能提升:在生成任务中,Top-j在减少V矩阵行数的同时,保持了较高的生成质量,显著提升了推理速度。
🔸分层剪枝的必要性:在早期层中保持较高的注意力密度有助于提高下游任务的准确性。
🔸GQA中的应用:Top-j在组查询注意力(GQA)中表现出色,不同头之间的注意力选择具有一致性,减少了V矩阵行的读取次数。
💡个人观点
论文的核心在于校准注意力头的阈值,并引入了剪枝损失补偿。
🧩附录