目录
3.String、StringBuffer、StringBuilder区别
10.Integer a1=100 Integer a2=100,a1==a2?的运行结果?
1.new String("abc")到底创建了几个对象?
分析:
首先,这个代码里面有一个new关键字,这个关键字是在程序运行时,根据已经加载的系统类String,在堆内存里面实例化的一个字符串对象。
然后,在这个String的构造方法里面,传递了一个“abc”字符串,因为String里面的字符串成员变量是final修饰的,所以它是一个字符串常量。
接下来,JVM会拿字面量“abc” 去字符串常量池里面试图去获取它对应的String对象引用,如果拿不到,就会在堆内存里面创建一个”abc”的String对象并且把引用保存到字符串常量池里面。
后续如果再有字面量“abc”的定义,因为字符串常量池里面已经存在了字面量“abc”的引用,所以只需要从常量池获取对应的引用就可以了,不需要再创建。
结论:
- 如果abc这个字符串常量不存在,则创建两个对象,分别是abc这个字符串常量,以及new String这个实例对象。
- 如果abc这字符串常量存在,则只会创建一个对象
2.HashMap是如何解决hash冲突的?
HashMap底层采用了数组的结构来存储数据元素,数组的默认长度是16,
当我们通过put方法添加数据的时候,HashMap根据Key的hash值进行取模运算。
最终保存到数组的指定位置。
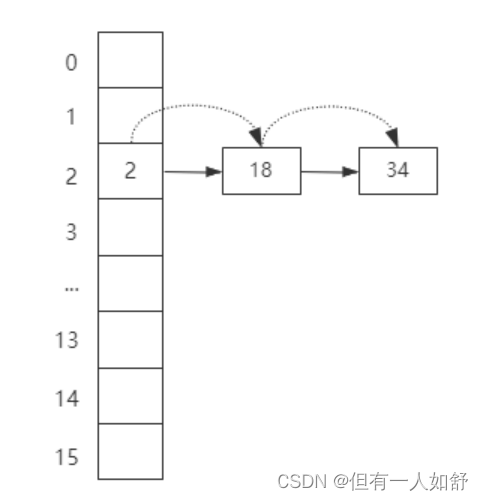
但是这种设计会存在hash冲突问题,也就是两个不同hash值的key,最终取模后会落到同一个数组下标。
(如图)所以HashMap引入了链式寻址法来解决hash冲突问题, 对于存在冲突的key,HashMap把这些key组成一个单向链表。
然后采用尾插法把这个key保存到链表的尾部。
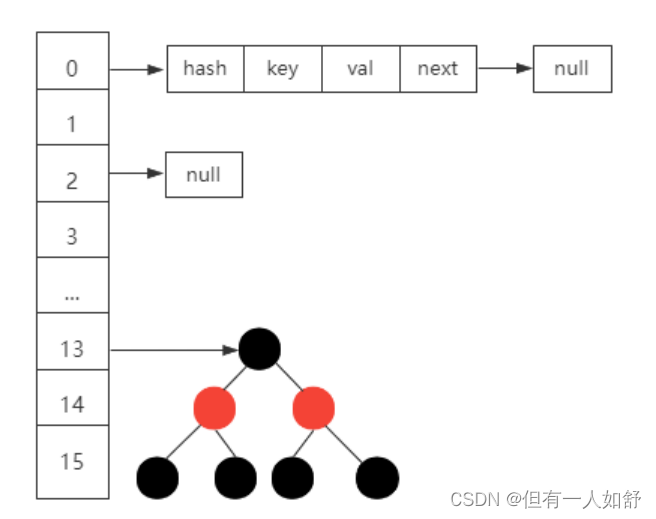
另外,为了避免链表过长的问题,当链表长度大于8并且数组长度大于等于64的时候,
HashMap会把链表转化为红黑树(如图)。
从而减少链表数据查询的时间复杂度问题,提升查询性能。
补充一下,解决hash冲突问题的方法有很多,比如
- 再hash法,就是如果某个hash函数产生了冲突,再用另外一个hash进行计算,比如布隆过滤器就采用了这种方法。
- 开放寻址法,就是直接从冲突的数组位置往下寻找一个空的数组下标进行数据存储,这个在ThreadLocal里面有使用到。
- 建立公共溢出区,也就是把存在冲突的key统一放在一个公共溢出区里面。
3.String、StringBuffer、StringBuilder区别
第一个,可变性,
String内部的value值是final修饰的,所以它是不可变类。所以每次修改String的值,都会产生一个新的对象。
StringBuffer和StringBuilder是可变类,字符串的变更不会产生新的对象。
第二个,线程安全性,
String是不可变类,所以它是线程安全的。
StringBuffer是线程安全的,因为它每个操作方法都加了synchronized同步关键字。
StringBuilder不是线程安全的。
所以在多线程环境下对字符串进行操作,应该使用StringBuffer,否则使用StringBuilder
第三个,性能方面。
String的性能是最的低的,因为不可变意味着在做字符串拼接和修改的时候,需要重新创建新的对象以及分配内存。
其次是StringBuffer要比String性能高,因为它的可变性使得字符串可以直接被修改
最后是StringBuilder,它比StringBuffer的性能高,因为StringBuffer加了同步锁。
第四个,存储方面。
String存储在字符串常量池里面
StringBuffer和StringBuilder存储在堆内存空间。
4.ArrayList的自动扩容机制
ArrayList是一个数组结构的存储容器,默认情况下,数组的长度是10.
当然我们也可以在构建ArrayList对象的时候自己指定初始长度。
随着在程序里面不断的往ArrayList中添加数据,当添加的数据达到10个的时候,
ArrayList就没有多余容量可以存储后续的数据。
这个时候ArrayList会自动触发扩容。
扩容的具体流程很简单,
- 首先,创建一个新的数组,这个新数组的长度是原来数组长度的1.5倍。
- 然后使用Arrays.copyOf方法把老数组里面的数据拷贝到新的数组里面。
扩容完成后再把当前要添加的元素加入到新的数组里面,从而完成动态扩容的过程。
5.什么是深拷贝和浅拷贝?
深拷贝和浅拷贝是用来描述对象或者对象数组这种引用数据类型的复制场景的。
浅拷贝,(如图)就是只复制某个对象的指针,而不复制对象本身。
这种复制方式意味着两个引用指针指向被复制对象的同一块内存地址。
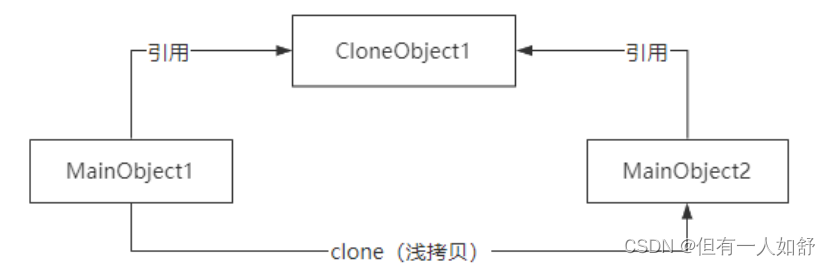
深拷贝,(如图)会完全创建一个一模一样的新对象,新对象和老对象不共享内存,
也就意味着对新对象的修改不会影响老对象的值。
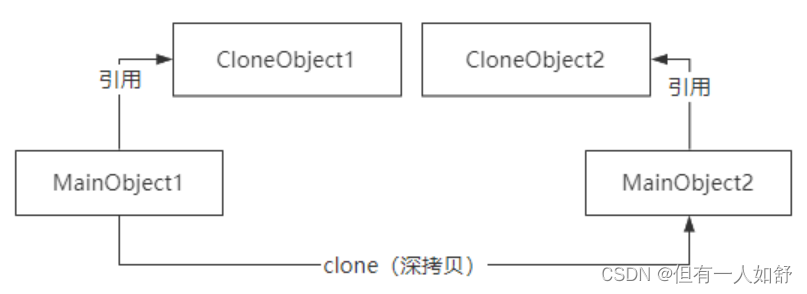
在Java里面,无论是深拷贝还是浅拷贝,都需要通过实现Cloneable接口,并实现clone()方法。
然后我们可以在clone()方法里面实现浅拷贝或者深拷贝的逻辑。
实现深拷贝的方法有很多,比如
- 通过序列化的方式实现,也就是把一个对象先序列化一遍,然后再反序列化回来,就会得到一个完整的新对象。
- 在clone()方法里面重写克隆逻辑,也就是对克隆对象内部的引用变量再进行一次克隆。
6.强引用、软引用、弱引用、虚引用有什么区别?
不同的引用类型,主要体现的是对象不同的可达性状态和对垃圾收集的影响。
强引用,就是普通对象的引用,只要还有强引用指向一个对象,就能表示对象还“活着”,
垃圾收集器无法回收这一类对象。
只有在没有其他引用关系,或者超过了引用的作用域,再或者显示的把引用赋值为null的时候,
垃圾回收器才能进行内存回收。
软引用,是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,
只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象。
软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,
当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
弱引用,相对强引用而言,它允许在存在引用关联的情况下被垃圾回收的对象
在垃圾回收器线程扫描它所管辖的内存区域的过程中,
一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,垃圾回收期都会回收该内存
虚引用,它不会决定对象的生命周期,它提供了一种确保对象被finalize以后,去做某些事情的机制。
当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,
就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
程序可以通过判断引用队列中是否已经加入了虚引用,
来了解被引用的对象是否将要进行垃圾回收,然后我们就可以在引用的对象的内存回收之前采取必要的行动。
7.finally块一定会执行吗?
finally语句块在两种情况下不会执行:
- 程序没有进入到try语句块因为异常导致程序终止,这个问题主要是开发人员在编写代码的时候,异常捕获的范围不够。
- 在try或者cache语句块中,执行了System.exit(0)语句,导致JVM直接退出
8.Integer和int的区别?
Integer和int的区别有很多,我简单说3个方面
- Integer的初始值是null,int的初始值是0
- Integer存储在堆内存,int类型是直接存储在栈空间
- Integer是对象类型,它封装了很多的方法和属性,我们在使用的时候更加灵活。
至于为什么要设计封装类型,最主要的原因是Java本身是面向对象的语言,一切操作都是以对象作为基础。
比如像集合里面存储的元素,也只支持存储Object类型,普通类型无法通过集合来存储。
9.Java反射的优缺点?
Java反射的优点:
- 增加程序的灵活性,可以在运行的过程中动态对类进行修改和操作
- 提高代码的复用率,比如动态代理,就是用到了反射来实现
- 可以在运行时轻松获取任意一个类的方法、属性,并且还能通过反射进行动态调用
Java反射的缺点:
- 反射会涉及到动态类型的解析,所以JVM无法对这些代码进行优化,导致性能要比非反射调用更低。
- 使用反射以后,代码的可读性会下降
- 反射可以绕过一些限制访问的属性或者方法,可能会导致破坏了代码本身的抽象性
10.Integer a1=100 Integer a2=100,a1==a2?的运行结果?
a1==a2的执行结果是true
原因是Integer内部用到了享元模式的设计,针对-128到127之间的数字做了缓存。
使用Integer a1=100这个方式赋值时,Java默认会通过valueOf对100这个数字进行装箱操作,
从而触发了缓存机制,使得a1和a2指向了同一个Integer地址空间。
11.粉丝福利(非常重要!!)
整理了2023年最新的一些高频面试题(都整理成一个文档),有很多干货,包含mysql,netty,spring,线程,spring cloud、jvm、源码、算法等详细讲解(大概50w字左右),也有详细的java学习规划图,一些电子书籍等等,
这些资料的梳理整整花了1年时间,现在当作福利分享给大家。
主要是不收fei..... 主打一个分享,帮助大家更好的通过面试,拿高薪。
需要获取这些内容的朋友可以关注 VX公粽号:Mic聊架构 回复暗号578就可以获取