需要完整代码和论文私信我
基于YOLOv3的车辆检测和车道线检测系统
1绪论
随着时代的快速发展,汽车的越发普及,城市交通事故愈发频繁,通过人力进行交通监管的方式已经无法满足当前的需要,采用智能交通系统来缓解当前交通监管面临的巨大压力已经成为了一种必然的趋势。为保障生命财产安全,各大汽车厂商愈加关注汽车的主被动安全以及辅助驾驶或自动驾驶技术。在交通系统日益繁杂的今天,仅仅依靠人为驾驶存在许多安全隐患,因此催生了人们在无人驾驶以及智能驾驶技术领域的广泛探索。自动驾驶技术是应用于车载AI中控系统的核心技术,是实现"智慧汽车"、"智慧交通"和"智慧城市"的关键,随着自动驾驶技术的日益成熟和传统汽车行业的越发饱和,基于人工智能的自动驾驶汽车将是颠覆传统汽车市场且具有深远意义的产品。
人工智能的自动驾驶技术能够有效地避免交通事故发生,而本论文是基于YOLOv3的目标检测方法实现车辆检测,并且使用开源算法在车辆检测的基础上实现车道线分割。深度学习在交通安全、无人驾驶等领域被广泛研究与应用,车辆检测作为其中不可或缺的一环,被人们所重点关注。环境感知模块是自动驾驶系统的重要组成之一,而目标检测和跟踪又是环境感知模块的基础,设计出性能优良的目标检测和跟踪模型是自动驾驶领域内的研究重点与难点之一。目标检测作为深度学习神经网络在计算机视觉方面的热门应用,在探测、医疗以及公共安全等领域都已成为研究热点,并有着丰富多元且广阔的应用前景,而车辆检测便是其重要应用分支之一,给交通及公共安全带来一层可靠保障。
目标检测是指找出图像中所有感兴趣的目标,确定它们的类别和位置,是计算机视觉领域的核心问题之一。车辆检测是目标检测中的一种,是自动驾驶中的一项关键技术,快速准确的车辆检测在减少交通事故上起着重要作用。
车道线检测与分割是无人驾驶汽车的关键任务之一。车道线规定了无人驾驶汽车的行驶规范,是路径规划和智能决策的重要依据,车道线检测问题是辅助驾驶系统乃至自动驾驶中环境感知的一个重要组成部分,对于自动驾驶系统的行车安全具有重要的意义。
由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
2研究现状
2.1 基于CNN的车辆检测现状
在卷积神经网络方面,武汉工程大学计算机科学与工程学院的金旺等人在2021年提出了《基于卷积神经网络的实时车辆检测》,他的文章内容主要是为了解决对于尺度变换较大车辆及遮挡车辆检测性能不足的问题,提出了一种实时车辆检测模型。他通过使用深度残差网络作为特征提取层,构建特征金字塔网络用于多尺度检测,并且对模型进行通道级裁剪缩减模型参数规模,节省计算资源,提高模型检测速度。他在VOC数据集的检测精度上,达到 87.6%的准确率,相较于 YOLOv3提升了 3.7个百分点,而较于SSD则提升了9.8个百分点;由于他对模型进行通道级裁剪缩减模型参数,所以在检测速度上,每秒检测帧数达到42 f/s,实现了车辆的实时检测,速度非常快。

图1 金旺等人的实验图片
2.2 基于YOLO的车辆检测现状
在YOLO算法方面,长春理工大学计算机科学技术学院的丛眸等人提出了《基于改进YOLOv3的装甲车辆检测方法》,他主要是收集不同目标类型、尺度、遮挡等条件下的装甲车辆图像并对其进行标注,利用k-means++算法计算出适用于数据集的锚框;在YOLOv3的特征提取网络中集成空间金字塔池化模块来丰富卷积特征的表达能力;通过卷积特征聚合机制并对多层级的卷积特征进行融合,从而得到改进的YOLOv3模型。与原YOLOv3方法相比,他改进的YOLOv3的查准率和查全率上分别提升了14.5%和4.2%,平均精确度提升了5.3%,效果已经达到并且满足了实时性的需求。

图2 丛眸等人的实验图片
2.3 基于SSD的车辆检测现状
在另外的SSD方面,广西大学电气工程学院的李国进等人提出了《基于改进 SSD 算法的车辆检测》,他与上者相似,他也对原有的SSD模型进行改进,设计改进 Inception 模块替代 SSD 网络中的 Conv8、Conv9 和 Conv10 层,构建多尺度特征融合均衡化网络,提高小目标车辆识别率,并且在特征提取层均引入SENet,对不同特征通道的重要性进行重标定以提高模型性能。他改进的SSD算法最终取得的效果相比改进前的 SSD 算法,在精度和速度上分别提高 2.65个百分点和 17.41 frame/s。

图3 李国进等人的实验图片
3研究意义
近年来,作为现代主要交通工具的汽车,以其特有的优越性为现代社会的发展和人类生活条件的改善做出了巨大贡献,其发展速度越来越快。一方面表现在产量不断增加,汽车制造业已成为全球一个重要的产业;另一方面还表现在汽车设计和制造技术不断提高,成为一个技术水平越来越高的技术密集型和资金密集型相结合的产业。随着车辆的普及和保有量的日益增加,不可避免地带来了交通事故、交通拥挤等诸多问题。提高车辆安全性能、减必道路交通事故一直是人们普遍关注的社会问题和科学技术进步所面临的重要课题之一。
智能机器人和智能车辆是世纪人类最伟大的发明之一,在短短的50年内发生了日新月异的变化。随着经济的发展和科技的进步,利用现代计算机及信息技术来提高道路交通的安全和效率已成为国内外研究的热点。智能道路交通系统是将先进的信息技术、通信数据传输系统、电子控制系统以及计算机处理系统有效的应用于整个运输管理体系,使人、车、路协调统一,从而建立一个全方位发挥作用的实时、准确、高效的运输综合管理系统。
车辆检测和车道线分割作为车辆自动驾驶发展的重要组成部分,在无人驾驶车辆行驶过程中起着重要作用,车辆检测和车道线分割算法研究有着重要的研究意义和应用价值,因此越来越多的国内外优秀学者开始对其进行研究工作,取得了丰硕的研究成果。车辆检测的目的判断是否有车经过检测区,并建立一个与之对应的跟踪对象,主要提供车流量等信息;车道线分割是在复杂背景及环境中将车道线准确识别并从原图像中分割出来,完成对车辆和车道线的识别后,自动驾驶系统就可以实现车辆横向运动的主动安全功能和控制功能。
随着人类社会信息化、智能化的不断进步,智能车辆与自动驾驶技术应用领域日益扩大,已经成为衡量一个国家社会文明和科技进步的重要标志之一。作为一个新型的交叉学科领域,智能车辆与自动驾驶的研究涉及图像实时处理、模式识别、人工智能、自动控制、传感器技术、卫星导航等多个学科的理论与技术,集成了信息科学与人工智能技术的最新成果,具有广泛的学科发展和理论价值,是国家科研水平综合实力的集中体现,其研究成功必将促进相关学科的迅猛发展。
4研究内容
本文的研究工作内容主要是基于AI STUDIO平台的paddlex框架,构建一个YOLOv3模型,然后获取UA-DETRAC 数据集,使用YOLOv3模型对数据进行训练,得到一个车辆目标检测模型,使用该模型用于车辆检测。基于上述的训练模型,我们还借鉴Udacity 自动驾驶汽车纳米学位开源项目,实现车道线检测。我们最终将车辆检测与车道线检测这两个功能,在基于PYQT5开发的GUI界面上进行结合。我们的主要工作内容的研究思路的流程图可见如下图。

图4本文工作流程图
5相关技术概述
5.1目标检测
目标检测一直是计算机视觉领域中一个热点研究方向, 特别是随着深度学习的兴起, 基于深度学习的目标检测方法取得了突破性进展。
目标检测大致可以分为两大系列—RCNN系列和YOLO系列,RCNN系列是基于区域检测的代表性算法,代表有Fast R-CNN和Faster R-CNN,而YOLO是基于区域提取的代表性算法,代表有YOLOv1-YOLOv5。另外还有著名的SSD是基于前两个系列的改进,例如有SSD512方法等。
计算机视觉中关于图像识别的有四大类任务,分别可见如下表。
表1 图像识别的四大类别任务
| 任务名称 | 任务概括 |
| 分类 | 给出一张图片或者是一段视频,判断里面包含了什么类别的目标 |
| 定位 | 找出给定目标的位置 |
| 检测 | 找出这个目标的位置并且判断目标事物是什么类别的目标 |
| 分割 | 分为实例的分割和场景分割,解决“每一个像素属于哪个目标物或场景”的问题 |
基于图像的目标检测技术是指利用计算机视觉等相关技术,将已经划分类别的物体自动从图像中检测出来,并对物体的类别、位置、大小进行判断。可见如下图,它很明确的表示了计算机视觉中关于图像识别的有四大类任务,例如什么是分类,什么是分类+定位等。据查找资料得知,目标检测是一个分类、回归问题的叠加。

图5 图像识别四大任务示意图
目标检测的核心问题可见如下表,它是分类+定位+各种判断的结合,要远比单纯的分类任务要复杂的多。
表2 目标检测核心问题
| 核心问题 | 主要内容 |
| 分类问题 | 我们需要检测的目标属于哪个类别 |
| 定位问题 | 目标可能出现在图像的任何位置 |
| 大小问题 | 目标有各种不同的大小,例如猫与狗的大小是不一样的 |
| 形状问题 | 目标可能有各种不同的形状,例如矩形或者是圆形 |
当今时代,目标检测算法已经是非常成熟了,而且应用的方面非常的多,例如人脸检测方面可以用来实现智能门控和员工考勤签到,行人检测方面可以用来智能辅助驾驶和安全帽/安全带检测,而本文中的车辆检测方面可以用来助力自动驾驶和关键通道检测等。
5.2 YOLOv3
YOLO的全称为You Only Look Once。据查阅资料得知,YOLO算法是是继RCNN,fast-RCNN和faster-RCNN之后,Ross Girshick针对DL目标检测速度问题提出的另一种框架,其核心思想是生成RoI+目标检测两阶段算法用一套网络的一阶段算法替代,直接在输出层回归bounding box的位置和所属类别。YOLO创造性的将物体检测任务直接当作回归问题来处理,将候选区和检测两个阶段合二为一。只需一眼就能知道每张图像中有哪些物体以及物体的位置,所以我们可以得知YOLO算法的实时性是非常强的。可见如下图各个算法的检测流程。我们可以发现YOLO算法要比其他的算法的步骤流程要少许多的。

图6 各种算法流程
实际上,YOLO并没有真正去掉候选区,而是采用了预定义候选区的方法,也就是将图片划分为7*7个网格,每个网格允许预测出2个边框,总共49*2个bounding box,可以理解为98个候选区域,它们很粗略地覆盖了图片的整个区域,具体可见如下图。YOLO以降低mAP为代价,大幅提升了时间效率。这也是为什么YOLO算法以速度著称,而不是以精度著称的原因,可是事实上,YOLO算法的精度并不差,有时候与其他的算法在同一个数据集上的map的差不多的。每个网格单元预测这些框的2个边界框和置信度分数。这些置信度分数反映了该模型对框是否包含目标的可靠程度,以及它预测框的准确程度。

图7 YOLO的预测框计算过程
由于YOLO算法注重的是算法的时间效率,所以它的优缺点也是非常明显的,具体可见如下表。
表3 YOLO算法的优缺点
| 优点 | 缺点 |
| 速度非常快,其增强版GPU中能跑45fps | 精度普遍低于其它物体检测系统 |
| 在检测物体是能很好利用上下文信息,从而不容易在背景上预测出错误的物体信息 | 容易产生定位错误 |
| 可以学到物体泛化特征 | 对小物体检测效果不好,尤其是密集的小物体 |
但是随着算法原作者的努力,YOLO算法一直改进,更新迭代,在时间效率已经精度上都有很大的提升。YOLOv3总结了自己在YOLOv2的基础上做的一些尝试性改进,使用残差模型,进一步加深了网络结构;还有是使用FPN架构实现多尺度检测。
YOLOv3在之前Darknet-19的基础上引入了残差块,并进一步加深了网络,改进后的网络有53个卷积层,取名为Darknet-53,网络结构域可见如下图。

图7 YOLO算法的网络结构图
以往车道线检测方法首先需要产生大量可能包含待检测物体的先验框,然后用分类器判断每个先验框对应的边界框里是否包含待检测物体,以及物体所属类别的概率或者置信度,同时需要后处理修正边界框,最后基于一些准则过滤掉置信度不高和重叠度较高的边界框,进而得到检测结果。这种基于先产生候选区再检测的方法虽然有相对较高的检测准确率,但运行速度较慢。
YOLO系列创造性地将物体检测任务直接当作回归问题来处理,将候选区和检测两个阶段合二为一。YOLOv3借鉴了YOLOv1和YOLOv2,虽然没有太多的创新点,但在保持YOLO家族速度的优势的同时,提升了检测精度,尤其对于小物体的检测能力。YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分多个区域并且预测边界框和每个区域的概率。YOLOv3在YOLOv2基础上做了一些尝试性改进,其中最大的两个亮点,一个是使用残差模型,进一步加深了网络结构;另一个是使用FPN架构实现多尺度检测。
YOLOv3基本过程如下:
- 将输入图像分成S*S
个格子,每个格子负责预测中心在此格子中的物体; - 每个格子预测B个bbox
(bounding box)及其置信度,以及C个类别概率; - bbox
信息(x,y,w,h)
为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化; - 置信度反映是否包含物体,以及包含物体情况下位置的准确性。定义为probject*IOU
,其中pr(object)∈{0,1}
。






YOLOv3预测原理是分别将输入图像分为13*13

、26*26

、52*52

的网格,每个网络点负责一个区域的检测。解码过程采用直接预测相对位置的方法,预测出bbox

中心点相对于网格单元左上角的相对坐标。直接预测出(tx,ty,tw,th,to)

,然后通过以下坐标偏移公式计算得到bbox

的位置大小和置信度:
bx=σtx+cxby=σty+cy

bw=pwetwbh=pheth

probject*IOUb,object=σ(to)

其中,tx

、ty

、tw

、th

就是模型的定位预测输出,cx

和cy

表示grid cell的坐标,bx

、by

、bw

和bh

就是预测得到的bbox

的中心的坐标和尺寸。
采用逻辑回归预测每个边界框的分数。如果边界框与真实框的重叠度比之前的任何其他边界框都要好,则该值应该为1。如果边界框不是最好的但确实与真实对象的重叠超过某个阈值(假设阈值是0.5),那么就忽略这次预测。网络只为每个真实对象分配一个边界框,如果边界框与真实对象不吻合,则不会产生坐标或类别预测损失,只会产生物体预测损失。
采用多标签分类预测类别信息,因此网络结构上就将原来用于单标签多分类的softmax层换成用于多标签多分类的Logistic分类器。用多个独立的Logistic分类器替代Softmax层解决多标签分类问题,且准确率不会下降。Logistic分类器主要用到sigmoid函数,该函数可以将输入约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就表示该边界框负责的目标属于该类。
5.3车道线检测
该方法是借鉴于Udacity 自动驾驶汽车纳米学位的一部分,它的主要步骤可见如下:
1、我们需要给定一组棋盘图像,计算相机校准矩阵和失真系数。

图9 棋盘图像
2、查看原始图片,以该图片进行车道检测

图10 车道线检测原图
3、首先我们需要根据校准矩阵和失真系数对原始图像应用失真校正,再使用颜色变换,渐变等创建阈值二进制图像。

图11 原始图片的处理结果
4、再应用透视变换以校正二进制图像,实现“鸟瞰图”,也就是俯视的视角。

图12 二进制图像的俯视角(鸟瞰图)
5、然后检测图像中车道像素并拟合,以找到车道边界。

图13 车道像素拟合
6、将检测到的车道边界矫正到原始图像。

图14 车道线检测最终效果
6实验数据准备
6.1数据集介绍
本实验使用的数据集是UA-DETRAC 数据集,它是一个具有挑战性的真实多目标检测和多目标跟踪基准。该数据集由10小时的视频组成,这些视频由中国北京和天津的24个不同地点使用Cannon EOS 550D摄像机拍摄。视频以每秒 25 帧 (fps) 的速度录制,分辨率为 960×540 像素。UA-DETRAC 数据集中有超过 140 000 个帧,手动标注了 8250 辆车,总共有 121 万个标记了边界框的目标,而车辆分为四类,即轿车、公共汽车、厢式货车和其他车辆;天气情况分为四类,即多云、夜间、晴天和雨天。

图15 数据集网页首页
本次实验数据一共有20522张图片,部分图片可见如下图,一共5个类别数据。

图16 数据集部分示意图片
每一张图片对应着一个配置文件,一共20522个xml配置文件。每个文件里面包括了对应的图片类别,目标的位置信息等,具体可见如下图。本次实验就是对这些图片数据以及配置数据进行训练,得到一个目标检测模型。

图17 图片的xml配置文件
6.2环境介绍
本次实验运行环境以及各种配置可见如下表。
表4 环境配置
| 软、硬件以及其他配置 | 环境详情 |
| 笔记本 | 飞行堡垒7 |
| 操作系统 | Windows10 |
| 框架版本 | PaddlePaddle 2.0.2 |
| Python版本 | python 3.7 |
| 运行平台 | AI STUDIO(百度) |
| GPU | V100 |
| 编辑工具 | Jupyter notebook |
| API | Paddlex,Pyqt5,numpy,matplotlib,opencv-python,time,pickle,tools,glob |
本次实验主要借助的库是Paddlex,PaddleX是飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通深度学习开发全流程,并提供简明易懂的Python API,方便用户根据实际生产需求进行直接调用或二次开发,为开发者提供飞桨全流程开发的最佳实践。
6.3图片数据预处理
当数据顺利导入数据后,我们就可以依据图像的具体情况对图像进行预处理了。图像的预处理基本完全与数据本身有关的,这一点是与普通的机器学习中较为固定的预处理流程不同。我们将所有有效数据导入后,我们至少要确保一下三点:
- 全部样本的尺寸是一致的(同时,全部样本的通道数是一致的)
- 图像最终以相同形式被输入预训练模型中
- 图像被恰当地归一化
其中,前两项是为了使得预训练模型能够顺利地运行起来,否则在训练过程中间断的报错会很影响整个训练效率,而第三项是为了让训练过程变得更加流畅快速。
我们本次实验主要是对输入图像按照随机大小和长宽比进行裁剪、基于概率来执行图片的水平翻转、在随机位置裁剪输入的图像、将输入数据调整为指定大小以及图像归一化处理,其中图像归一化处理分为用统一的均值和标准差值对图像的每个通道进行归一化处理和对每个通道指定不同的均值和标准差值进行归一化处理两种方式。
6.4图片数据增强
数据增强是增加数据量的技术,它是数据科学体系中常用的一种增加数据量的技术,它通过添加略微修改的现有数据、或从现有数据中重新合成新数据来增加数据量。使用数据增强技术可以极大程度地减弱数据量不足所带来的影响,还可以提升模型的鲁棒性、为模型提供各种“不变性”、增加模型抗过拟合的能力。常见的数据增强方式有旋转、模糊、饱和度调整、图片指定大小(放大和缩小)、图片亮度调整以及图片形状调整等。
本次实验使用到的图片数据增强技术主要是图片大小的修改以及图片数据的随机旋转。
7实验结果
7.1模型训练
首先在模型训练之前,我们需要定义数据迭代器以及YOLOv3模型,然后通过K-means获取YOLOv3模型中anchors参数的大小,其中,数据迭代器的主要函数以及解释可见如下表。
表5 数据迭代器主要函数
| 函数名称 | 函数解释 |
| data_dir () | 数据集所在的目录路径 |
| file_list () | 描述数据集图片文件和对应标注文件的文件路径 |
| label_list () | 描述数据集包含的类别信息文件路径 |
| transforms () | 数据集中每个样本的预处理/增强算子 |
| num_workers () | 数据集中样本在预处理过程中的线程或进程数 |
| shuffle () | 是否需要对数据集中样本打乱顺序默认为False |
而YOLOv3模型的主要函数以及函数的解释可见如下表。
表6 YOLOv3模型的主要函数
| 函数名称 | 函数解释 |
| num_classes () | 类别数,默认为80 |
| backbone () | YOLOv3的backbone网络,取值范围为[‘DarkNet53’,‘ResNet34’,‘MobileNetV1’,‘MobileNetV3_large’]。默认为‘MobileNetV1’ |
| anchors () | anchor框的宽度和高度 |
| anchor_masks () | 在计算YOLOv3损失时,使用anchor的mask索引,为None时表示使用默认值 |
| ignore_threshold () | 在计算YOLOv3损失时,IoU大于ignore_threshold的预测框的置信度被忽略 |
| nms_score_threshold () | 检测框的置信度得分阈值,置信度得分低于阈值的框应该被忽略 |
当YOLOv3模型定义好后,对上述数据预处理以及数据增强得到的数据进行输入,并且训练函数中的重要参数的设置可见如下表。
表7 模型的训练函数
| 参数名称 | 参数大小 |
| num_class | 5 |
| epoch | 50 |
| batch_size | 4 |
| learning_rate | 0.00025 |
| log_interval_steps | 100 |
| pretrain_weights | 'IMAGENET' |
由于模型的结构复杂、数据量、学习率小以及epoch大的原因,整个模型使用V100的GPU从开始训练到结束需要消耗约15个小时,其中,前10个epoch的平均损失情况可见如下表。
表8 模型的前10个epoch训练情况
| Epoch次数 | Loss大小 |
| 1 | 57.508907 |
| 2 | 28.72492 |
| 3 | 27.121746 |
| 4 | 25.801579 |
| 5 | 24.840385 |
| 6 | 24.672966 |
| 7 | 23.870062 |
| 8 | 23.66597 |
| 9 | 23.183186 |
| 10 | 22.877871 |
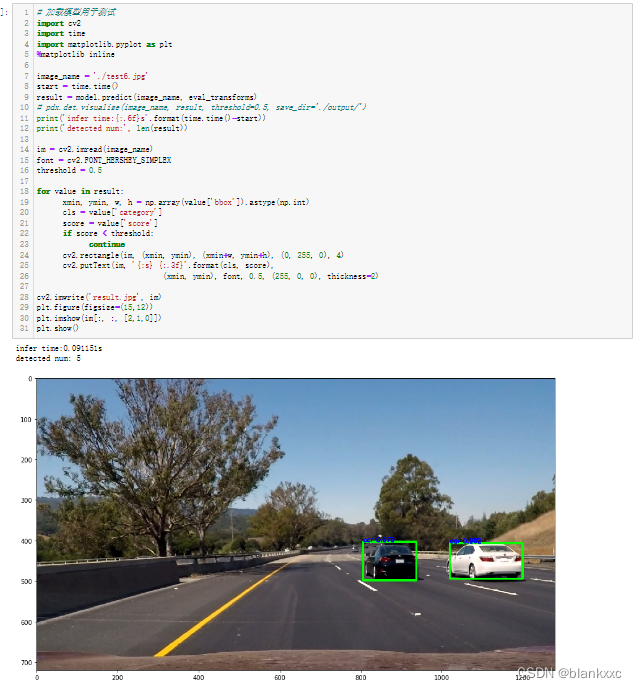
我们可以发现,随着epoch的增加,loss的变化越来越小了,所以此处只展示loss变化比较明显的前10个epoch。其中,最终第50个epoch的loss为18.182134,而最终训练得到的YOLOv3模型测试得到的map约为0.87,效果还是可观的。而模型的训练效果图分别可见如下两图。我们可以发现,图片中属于我们的目标车辆都可以被检测并且标注出来,说明模型的训练效果还是可观的。

图18 车辆检测结果

图19 车辆检测结果
7.2车道线检测
基于上述的车道线检测的步骤,我们对上述YOLOv3模型训练得到的车辆检测图片进行车道线检测,效果可见如下图。我们可以发现车辆前方的车道线已经被检测出来了,并且是基于YOLOv3模型训练得到图片的基础上进行检测的。检测简略步骤如下:
- 给定一组棋盘图像,计算相机校准矩阵和失真系数。
- 对原始图像应用失真校正。
- 使用颜色变换、渐变等来创建阈值二值图像。
- 应用透视变换来校正二值图像(“鸟瞰图”)。
- 检测车道像素并拟合以找到车道边界。
- 确定车道的曲率和车辆相对于中心的位置。
- 将检测到的车道边界扭曲回原始图像。
- 输出车道边界的视觉显示和车道曲率和车辆位置的数值估计。
检测得到的效果是非常可观的。具体的检测结果可见如下图。

图20 车道线检测结果
7.3模型部署
本次模型部署使用到的GUI界面是使用Python的一个PYQT5库来实现的。pyqt5是一套Python绑定Digia QT5应用的框架。它可用于Python 2和3。pyqt5做为Python的一个模块,它有620多个类和6000个函数和方法。这是一个跨平台的工具包,它可以运行在所有主要的操作系统,包括UNIX,Windows,Mac OS。
首先本次模型部署的界面可见如下图。它可以选择本地的图片,使用已经训练好的YOLOv3模型和车道线检测算法对预选中的图片进行检测,并且由于模型过大,检测的时间会比较长,所以我们还增加了一个用于整个检测过程时间计算的功能,用于计算检测时长。

图21 GUI界面
我们选择本地的一张图片,用于检测,具体效果可见如下图。我们可以发现检测得到的图片完整的实现了车辆检测与车道线检测的效果。由于我们预想把车道线检测模块做的更加好,所以我们对图片做了颜色的处理,使得车道线检测的效果更加好。我们还可以注意到,整个程序的运行时间大约为22秒,一般而言,该检测程序使用的时间是较久的,我们需要作出一定的改变,否则无法达到实时性的效果。

图22 程序运行效果图
8总结分析
本次实验的选题灵感来自于飞浆平台的多个开源项目的结合,我们基于UA-DETRAC 数据集使用PaddleX实现了YOLOv3模型的训练,将训练好的YOLOv3模型用于实现车辆检测,其中的最佳的map为0.87,模型的评价效果良好。除此之外,我们还结合Udacity 自动驾驶汽车纳米学位开源项目,基于图像的处理与变换,实现了车道线检测的功能。我们将两种功能结合到一起,基于PYQT5实现的GUI界面,实现了基于YOLOv3的车辆检测和车道线检测系统。
本系统还是有多个地方有待提升的,例如车辆检测部分,我们使用paddlex框架训练得到的YOLOv3模型目前的效果并不是最优的。在某些车辆比较多的场景,是有一部分的车辆没有被识别出来的,这个是因为车辆比较多并且比较混乱的情况下,训练得到的YOLOv3模型很难讲每一辆车都进行定位并且标记出来,还有部分严重的情况是该训练得到的YOLOv3模型有时候会讲图片信息中的一个“大物体”也识别成车辆并且标记出来,例如大块的石头还有垃圾桶等,都会误认为把它们识别为汽车的。其实这个问题可以归根于模型本身的问题,因为我们上述提到的YOLOv3模型具有一定的优缺点,例如它的模型虽然速度非常快,其增强版GPU中能跑45fps,但是精度普遍低于其它物体检测系统、容易产生定位错误、对小物体检测效果不好,尤其是密集的小物体。根据上述的YOLOv3模型的缺点我们可以注意到YOLOv3模型对于小物体的检测不好,尤其是密集的物体群,所以很符合我们上述提到的在车辆比较比较密集的场景中,容易检测错误的原因,而且检测定位错误的原因也符合我们上述提到的YOLOv3模型的缺点。所以本实验中产生的许多错误与误差其实是与模型本身的结构具有很大的相关性的,后面可以对模型结构进行更改或者是模型本身进行更换,尝试一下其他的目标检测模型。
在本次课程设计实验中,我们整个小组成员的收获都是挺多的,我们学习到了使用百度的AI STUDIO开源平台对一些模型结构比较复杂巨大并且对数据量比较庞大的数据集进行训练,因为该虚拟环境中为我们提供了非常强大的GPU(V100)和非常大的RAM(32GB),能够保证程序在一定的程度上可以顺利运行成功。对于一般的电脑而已,AI STUDIO平台肯定是要远远强于自己在电脑本地运行的。除此之外,我们还学习到了使用YOLOv3模型进行目标检测,对比而言目标检测是要远比以前做的图像分类的项目要有趣的多的。虽然YOLOv3本身的理论知识难于理解,但我们小组成员互帮互助,互助前行,还是将该模型理解好了,这也是我们团队合作效果的一个体现吧。
参考文献
[1] 陈辰,黄晁,孙松,等. 多模型融合车辆检测算法[J]. 计算机辅助设计与图形学学报,2018,30(11):2134-2140. DOI:10.3724/SP.J.1089.2018.17096.
[2] 梁礼明,熊文,蓝智敏,等. 改进的CornerNet-Saccade车辆检测算法[J]. 重庆理工大学学报(自然科学版),2021,35(6):137-146. DOI:10.3969/j.issn.1674-8425(z).2021.06.018.
[3] 庞彦伟,修宇璇. 基于边缘特征融合和跨连接的车道线语义分割神经网络[J]. 天津大学学报,2019,52(8):779-787. DOI:10.11784/tdxbz201802018.
[4] 李国进,胡洁,艾矫燕. 基于改进SSD算法的车辆检测[J]. 计算机工程,2022,48(1):266-274. DOI:10.19678/j.issn.1000-3428.0060031.
[5] 陈冰曲,邓涛. 基于改进型SSD算法的目标车辆检测研究[J]. 重庆理工大学学报(自然科学版),2019,33(1):58-63,129. DOI:10.3969/j.issn.1674-8425(z).2019.01.009.
[6] 丛眸,张平,王宁. 基于改进YOLOv3的装甲车辆检测方法[J]. 兵器装备工程学报,2021,42(4):258-262. DOI:10.11809/bqzbgcxb2021.04.048.
[7] 顾晋,罗素云. 基于改进的YOLO v3车辆检测方法[J]. 农业装备与车辆工程,2021,59(7):98-103. DOI:10.3969/j.issn.1673-3142.2021.07.022.
[8] 金旺,易国洪,洪汉玉,等. 基于卷积神经网络的实时车辆检测[J]. 计算机工程与应用,2021,57(5):222-228. DOI:10.3778/j.issn.1002-8331.2005-0328.
[9] 蔡英凤,张田田,王海,等. 基于实例分割和自适应透视变换算法的多车道线检测[J]. 东南大学学报(自然科学版),2020,50(4):775-781. DOI:10.3969/j.issn.1001-0505.2020.04.023.
[10] 邓元望,蒲宏韬,华鑫斌,等. 基于RC-DBSCAN的车道线检测研究[J]. 湖南大学学报(自然科学版),2021,48(10):85-92. DOI:10.16339/j.cnki.hdxbzkb.2021.10.010.
[11] 李军,钟鹏. OpenCV的车道线检测方法[J]. 华侨大学学报(自然科学版),2021,42(4):421-424. DOI:10.11830/ISSN.1000-5013.202009036.
[12] 朱威,欧全林,洪力栋,等. 基于图像序列的车道线并行检测网络[J]. 模式识别与人工智能,2021,34(5):434-445. DOI:10.16451/j.cnki.issn1003-6059.202105006.
[13] YONG-GANG WANG, GANG WEI, XU ZHU, et al. CAPACITY OF BICYCLE PLATOON FLOW AT TWO-PHASE SIGNALIZED INTERSECTION: A CASE ANALYSIS OF XI'AN CITY[J]. Promet-traffic & transportation: Scientific journal on traffic and transportation research,2011,23(3):177-186.
[14] 王景丹, 黄园刚, 郝宗波, et al. 基于智能检测车位信息的车辆识别算法 Vehicle Recognition Algorithm Based on the Intelligent Detecting Parking Information[J]. Computer Science and Application(02):96.
[15] Road transport and traffic telematics - After-theft systems for the recovery of stolen vehicles - Part 4: Interface and system requirements for long range communication; German version CEN/TS 15213-4:2006:DIN CEN/TS 15213-4-2011[S].
[16] BOUHALAIS KAMEL(超凡). Study of Automatic Vehicle Detection and Classification Using Laser Sensor[D]. 黑龙江:哈尔滨工程大学,2011. DOI:10.7666/d.y2053704.
[17] MOHAMMED MAHFUZ ABDELKADIR. Research on Detecting Moving Objects Using Background Subtraction and Frame Difference[D]. 黑龙江:哈尔滨工程大学,2012. DOI:10.7666/d.Y2235629.
[18] MEBARKI BOUDJEMAA. 基于HOG和YOLO的夜间车辆检测模型分析研究[D]. 四川:西南交通大学,2020.
附录
1程序源代码
其中包括了YOLOv3模型训练预测和车道线检测的整个流程代码,名称为yolov3.ipynb

还有基于PYQT5实现的GUI界面GUI界面.ipynb

最后一个源代码是tools.py,是用于加载的,无需独自运行它。
2实验数据
数据都来源于The UA-DETRAC Benchmark Suite,由于数据比较大,需要自己去网站上下载。

3 YOLOv3模型
我们将训练最好的一个模型文件都放在了model的文件夹里。

4其他
其他的文件夹中的都是用于模型测试的样例数据,或者是不太重要的文件。其中有一个数据的训练配置文件。


