Java基础知识
1.Java中的基本数据类型
自从Java发布以来,基本数据类型就是Java语言的一部分,分别是byte, short, int, long, char, float, double, boolean
整型:byte, short, int, long
字符型:char
浮点型:float, double
布尔型:boolean
1.1、整形
Java中最小的计算单元为字节,1字节=8位(bit),Java中整型数据属于有符号数,即第一个bit位为0表示正整数,第一个bit位为1表示负整数。
- byte
- byte属于Java中的整型,长度为1字节8bit,取值10000000(-128)到 01111111(127),变量初始化默认值为0,包装类Byte.
- short
- short属于Java中的整型,长度为2字节16bit,取值10000000 00000000(-32768)到 01111111 11111111(32767),变量初始化默认值为0,包装类Short.
- int
- int属于Java中的整型,长度为4字节32bit,取值-2^31 (-2,147,483,648)到 2^31-1(2,147,483,647),变量初始化默认值为0,包装类Integer
- long
- long属于Java中的整型,长度为8字节64bit,取值-2^63 (-9,223,372,036,854,775,808)到 2^63-1(9,223,372,036,854,775,8087),变量初始化默认值为0或0L,包装类Long
1.2、浮点型
- float
- float属于Java中的浮点型,也叫单精度浮点型,长度为4字节32bit,变量初始化默认值0.0f,包装类Float
- double
- double属于Java中的浮点型,也叫双精度浮点型,长度为8字节64bit,变量初始化默认值0.0d,包装类Double
1.3、字符型
- char
- char属于java中的字符型,占2字节16bit,可以赋值单字符以及整型数值, 变量初始化无默认值,包装类Character。
1.4、布尔型
- boolean
- 在JVM中并没有提供boolean专用的字节码指令,而boolean类型数据在经过编译后在JVM中会通过int类型来表示,此时boolean数据4字节32位,而boolean数组将会被编码成Java虚拟机的byte数组,此时每个boolean数据1字节占8bit.
2、String、Stringbulider、StringBuffer
String这个类是Java中使用得最频繁的类之一,并且又是各大公司面试喜欢问到的地方,今天就来和大家一起学习一下String、StringBuilder和StringBuffer这几个类,分析它们的异同点以及了解各个类适用的场景。
- String str="hello world"和String str=new String(“hello world”) 的区别?
想必大家对上面2个语句都不陌生,在平时写代码的过程中也经常遇到,那么它们到底有什么区别和联系呢?
public class Main {
public static void main(String[] args) {
String str1 = "hello world";
String str2 = new String("hello world");
String str3 = "hello world";
String str4 = new String("hello world");
System.out.println(str1==str2);
System.out.println(str1==str3);
System.out.println(str2==str4);
}
}
这段代码的输出结果为:
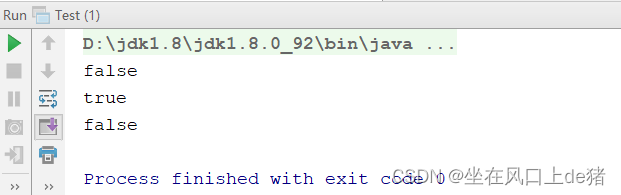
这个结果和你的答案是一致的吗?为什么是这样的结果呢?
String str1 = “hello world”;和String str3 = “hello world”; 都在编译期间生成了 字面常量和符号引用,运行期间字面常量"hello world"被存储在运行时常量池(当然只保存了一份)。通过这种方式来将String对象跟引用绑定的话,JVM执行引擎会先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量;否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。
通过new关键字来生成对象是在堆区进行的,而在堆区进行对象生成的过程是不会去检测该对象是否已经存在的。因此通过new来创建对象,创建出的一定是不同的对象。
-
String、StringBuffer以及StringBuilder的区别?
既然在Java中已经存在了String类,那为什么还需要StringBuilder和StringBuffer类呢?一起来看下面的代码
public class Main { public static void main(String[] args) { String string = ""; for(int i=0;i<10000;i++){ string += "hello"; } } } 以上代码在底层,每次循环会new出一个StringBuilder对象,然后进行append操作,最后通过toString方法返回String对象。也就是说这个循环执行完毕new出了10000个对象,试想一下,如果这些对象没有被回收,会造成多大的内存资源浪费。 -
再看下面这段代码:
public class Main { public static void main(String[] args) { StringBuilder stringBuilder = new StringBuilder(); for(int i=0;i<10000;i++){ stringBuilder.append("hello"); } } } 以上代码new操作只进行了一次,也就是说只生成了一个对象,append操作是在原有对象的基础上进行的。因此在循环了10000次之后,这段代码所占的资源要比上面小得多。
那么有人会问既然有了StringBuilder类,为什么还需要StringBuffer类?查看源代码便一目了然,事实上,StringBuilder和StringBuffer类拥有的成员属性以及成员方法基本相同,区别是StringBuffer类的成员方法前面多了一个关键字:synchronized,不用多说,这个关键字是在多线程访问时起到安全保护作用的,也就是说StringBuffer是线程安全的。
-
StringBuilder
-
StringBuffer


- String、StringBuilder、StringBuffer三者的执行效率
StringBuilder > StringBuffer > String
- String、StringBuilder、StringBuffer三者的使用场景
- 当字符串相加操作或者改动较少的情况下,建议使用 String str="hello"这种形式定义变量;
- 当字符串相加操作较多的情况下,建议使用StringBuilder
- 如果采用了多线程,则使用StringBuffer。
3、ArrayList、LinkedList、Vector
3.1、ArrayList
ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。
优点:查询快,修改快。
缺点:增删慢。
1)数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,会在原始大小上扩容1.5倍,将已经有数组的数据复制到新的存储空间中。(在内存中是连续的)
2)当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动,代价比较高。适合随机查找和遍历,不适合插入和删除。
3.2、Vector
Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。
3.3、LinkedList
LinkedList是用链表结构存储数据的,优缺点和数组正好相反。
优点:增删快
每次增加或删除的时候,不会影响到其它大量元素,只会影响链表中相关联的前后关系。
缺点:查询慢,修改慢
每次查询元素,都需要根据链接关系逐个进行匹配。
很适合数据的动态插入和删除,随机访问和遍历速度比较慢。
4、数组和链表
4.1、数组
数组必须事先定义固定的长度,不能适应数据动态地增减的情况。从栈中分配空间, 对于程序方便快速,但是自由度小。
优点:利用下标定位,随机访问性强,查找速度快。
缺点:插入和删除的效率低,内存利用率低,内存空间要求高,必须有足够的连续的内存空间。
4.2、链表
链表动态地进行存储分配,可以适应数据动态地增减的情况。从堆中分配空间, 自由度大但是申请管理比较麻烦。
优点:插入和删除的效率高。内存利用率高,不会浪费内存。
缺点:定位查询速度慢,修改慢。
总结:如果需要快速访问数据,很少或不插入和删除元素,就应该用数组;;相反, 如果需要经常插入和删除元素就需要用链表数据结构了。
5、时间复杂度与空间复杂度
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度地算法,执行效率越低。常见的复杂度并不多,从低阶到高阶有:O(1)、O(logn)、O(n)、O(nlogn)、O(n2)。
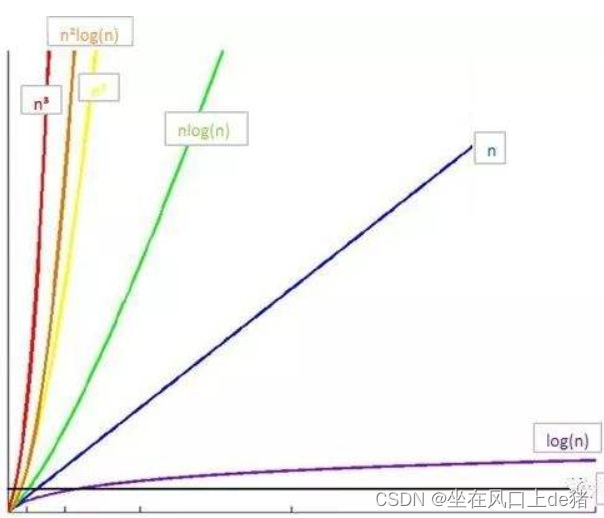
时间复杂度
执行效率是衡量算法优劣的一个重要指标,一般来说我们把代码运行一遍就能得到算法执行的时间和占用的内存大小,但这其实很不准确,结果既依赖于运行环境硬件设备又被测试规模影响。
所以我们需要一种分析方法去计算算法的运行效率,这就是大O复杂度表示法,比如我们经常看见O(n)之类的。
public int count(int n){
int sum = 0;
for(int i = 1; i <= n; i++)
sum += i;
return sum;
}
从CPU角度来说,每段代码都意味着读数据-计算数据-写数据,假设每行代码的运行时间为unit_time,那么for循环了n遍,所以运行时间为2n*unit_time,再加上第一句赋值的时间,总运行时间为(2n+1)*unit_time。
所以可以观察到代码的执行时间 T(n) 与每行代码的执行次数成正比,如果将代码的执行次数记为f(n),代码执行时间和执行次数的关系记为O,那么将其总结为公式:
T(n) = O(f(n))
大O时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
比如第一个例子T(n) = O(2n+1),如果n非常大的时候,公式中的低阶、常量、系数三部分并不左右增长趋势,所以都可以忽略。我们只需要记录一个最大量级就可以了,如果用大 O 表示法表示第一个例子的时间复杂度,就可以记为:T(n) = O(n)。
所以时间复杂度分析的重点就是只关注循环执行次数最多的一段代码,忽略执行次数公式中的低阶、常量、系数。
另外再分析下O(logn)、**O(nlogn)**这种类型的时间复杂度。
int i = 0;
while(i <= n){
i *= 2;
}
上述代码运行的次数和2的指数有关,就是运行了x次,2x = n的时候循环结束,那么运行次数x为log2n,很简单就可以得出时间复杂度为O(log2n)。
实际上,不管是以2为底、以3为底,还是以10为底,我们可以把所有对数阶的时间复杂度都记为 O(logn)。
假如将上述代码改成i = 3,那么算法执行了log3n次,根据对数转换的公式,log3n 就等于 log32 * log2n 时间复杂度就相当于log32O(log2n ),忽略掉系数log32就是O(log2n ),因此,在对数阶时间复杂度的表示方法里,我们忽略对数的底,统一表示为O(logn)。
如果一段代码的时间复杂度是O(logn),又循环执行n遍,时间复杂度就是O(nlogn) 了。而且O(nlogn) 也是一种非常常见的算法时间复杂度。比如归并排序和快速排序。
- 思考,什么情况下,时间复杂度为 n的平方?
空间复杂度
类比之前的时间复杂度,空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
比如代码申请了一个int[n]的数组,忽略其他低阶等那么空间复杂度也就是O(n)。
再举个例子比如存储一个二进制数n,那么其空间复杂度就是是O(logn)。
举例:8用二进制数表示就是3个bit,16用二进制表示4个bit,以此类推n用二进制表示就是 logn 个bit。
1000
常见的空间复杂度就是O(1),O(n),O(n的平方)。
6、排序算法(笔试题)
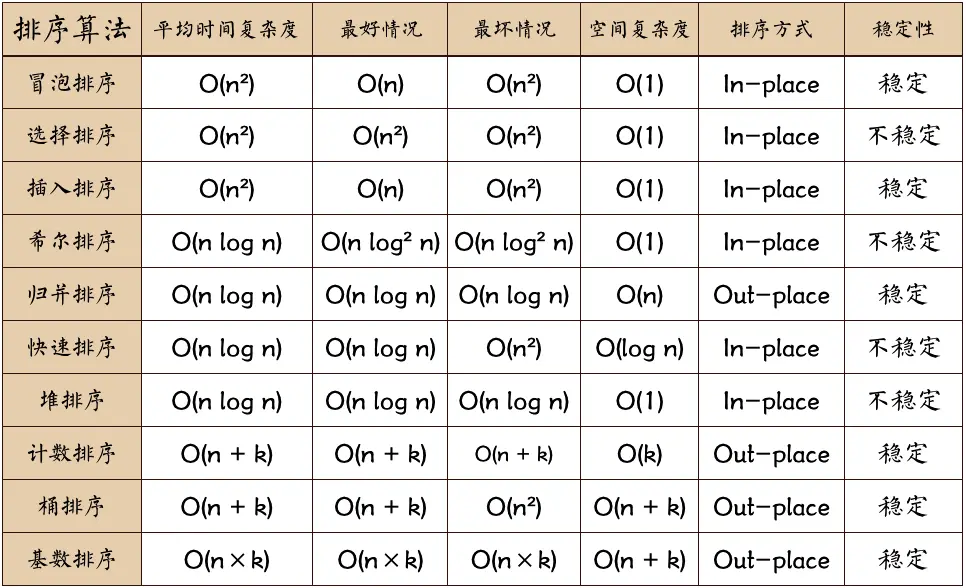
**稳定:**如果a原本在b前面且a=b,排序之后a仍然在b的前面。
**不稳定:**如果a原本在b的前面且a=b,排序之后 a 可能会出现在 b 的后面。
**时间复杂度:**对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
**空间复杂度:**是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
**内部排序:**所有排序操作都在内存中完成。本文主要介绍的是内部排序。
**外部排序:**待排序记录的数量很大,以致于内存不能一次容纳全部记录,所以在排序过程中需要对外存进行访问的排序过程。
参考资料:https://www.jianshu.com/p/47170b1ced23
7、 Java 中的重载和重写
- 重载
- 方法名要一样,但是参数类型和个数不一样,返回值类型可以相同也可以不相同。
- 重写
- 1、在子类中可以根据需要对从基类中继承来的方法进行重写。
- 2、重写的方法和被重写的方法必须具有相同方法名称、参数列表和返回类型。
- 3、重写方法不能使用比被重写的方法更严格的访问权限。
8、单例模式
所谓单例,就是整个程序有且仅有一个实例。该类负责创建自己的对象,同时确保只有一个对象被创建。在Java,一般常用在工具类的实现【加载配置,写日志,web访问计数器】。(笔试题)
8.1特点
- 类构造器私有
- 持有自己类型的属性
- 对外提供获取实例的静态方法
8.2、懒汉模式
线程不安全,延迟初始化
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
8.3、饿汉模式
线程安全,比较常用,但容易产生垃圾,因为一开始就初始化
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
8.4、双重锁模式
线程安全,延迟初始化。这种方式采用双锁机制,安全且在多线程情况下能保持高性能。
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
9、工厂模式
-
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
工厂模式分为简单工厂模式,工厂方法模式和抽象工厂模式,它们都属于设计模式中的创建型模式。其主要功能都是帮助我们把对象的实例化部分抽取了出来,目的是降低系统中代码耦合度,并且增强了系统的扩展性。本文对简单工厂模式进行讲解。
-
案例
- 我们将创建一个 Shape 接口和实现 Shape 接口的实体类。下一步是定义工厂类 ShapeFactory。
步骤 1
创建一个接口: Shape.java
public interface Shape {
void draw();
}
步骤 2
创建实现接口的实体类。
Rectangle.java
public class Rectangle implements Shape {
@Override public void draw() {
System.out.println("Inside Rectangle::draw() method."); }
}
Square.java
public class Square implements Shape {
@Override public void draw() {
System.out.println("Inside Square::draw() method."); }
}
Circle.java
public class Circle implements Shape {
@Override public void draw() {
System.out.println("Inside Circle::draw() method."); }
}
步骤 3
创建一个工厂,生成基于给定信息的实体类的对象。
ShapeFactory.java
public class ShapeFactory {
//使用 getShape 方法获取形状类型的对象
public Shape getShape(String shapeType){
if(shapeType == null){
return null;
}
if(shapeType.equalsIgnoreCase("CIRCLE")){
return new Circle();
} else if(shapeType.equalsIgnoreCase("RECTANGLE")){
return new Rectangle();
} else if(shapeType.equalsIgnoreCase("SQUARE")){
return new Square();
}
return null;
}
}
步骤 4
使用该工厂,通过传递类型信息来获取实体类的对象。
FactoryPatternDemo.java
public class FactoryPatternDemo {
public static void main(String[] args) {
ShapeFactory shapeFactory = new ShapeFactory();
//获取 Circle 的对象,并调用它的 draw 方法
Shape shape1 = shapeFactory.getShape("CIRCLE");
//调用 Circle 的 draw 方法
shape1.draw();
//获取 Rectangle 的对象,并调用它的 draw 方法
Shape shape2 = shapeFactory.getShape("RECTANGLE");
//调用 Rectangle 的 draw 方法
shape2.draw();
//获取 Square 的对象,并调用它的 draw 方法
Shape shape3 = shapeFactory.getShape("SQUARE");
//调用 Square 的 draw 方法
shape3.draw();
}
}
步骤 5
执行程序,输出结果:
Inside Circle::draw() method.
Inside Rectangle::draw() method.
Inside Square::draw() method.
优点: 1、一个调用者想创建一个对象,只要知道其名称就可以了。 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。 3、屏蔽产品的具体实现,调用者只关心产品的接口。
**缺点:**每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事
10、jvm类加载机制
-
JVM是一个进程, 用来模拟计算单元, 将.class字节码文件转成计算机能够识别的指令.
-
Java程序编译执行流程
-
类加载机制
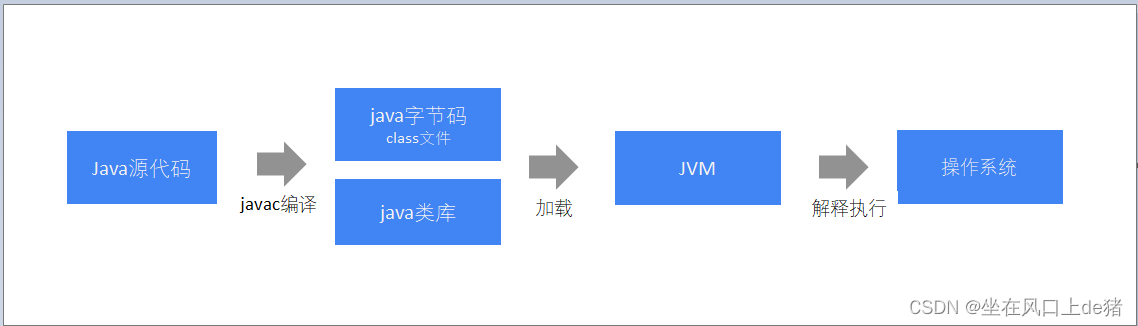
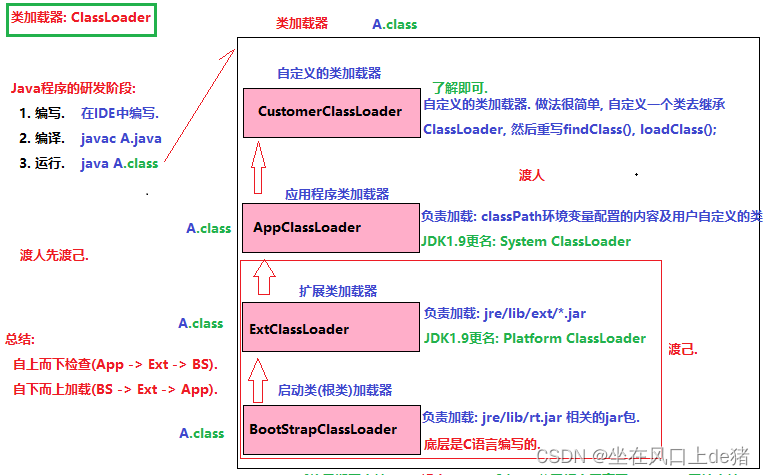
JVM底层加载类依靠三大组件:
BootStrapClassLoader //启动类加载器
//负责加载: jre\lib\rt.jar //rt: runtime, 运行的意思
ExtClassLoader: //扩展类加载器
//负责加载: jre\lib\ext\* 文件夹下所有的jar包
//这两个加载器执行完毕后, JVM虚拟机基本上就初始化完毕了.
APPClassLoader: //应用程序类加载器
//负责加载: 用户自定义的类的.
//就是加载: 用户配置的classpath环境变量值的.
- 加载顺序是: BootStrap --> ExtClassLoader --> AppClassLoader --> UserClassLoader
11、jvm内存模型
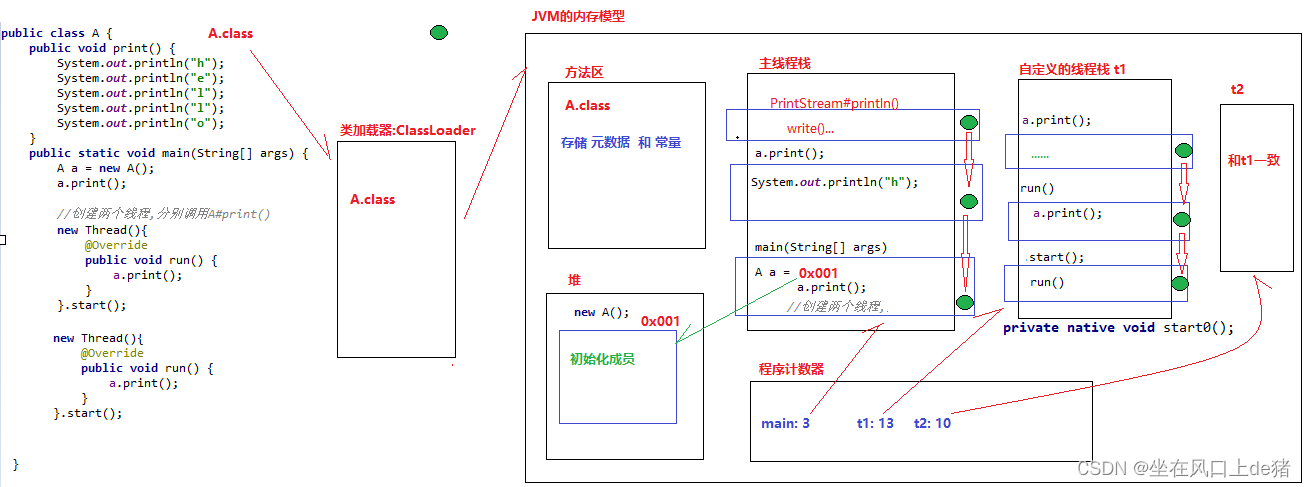
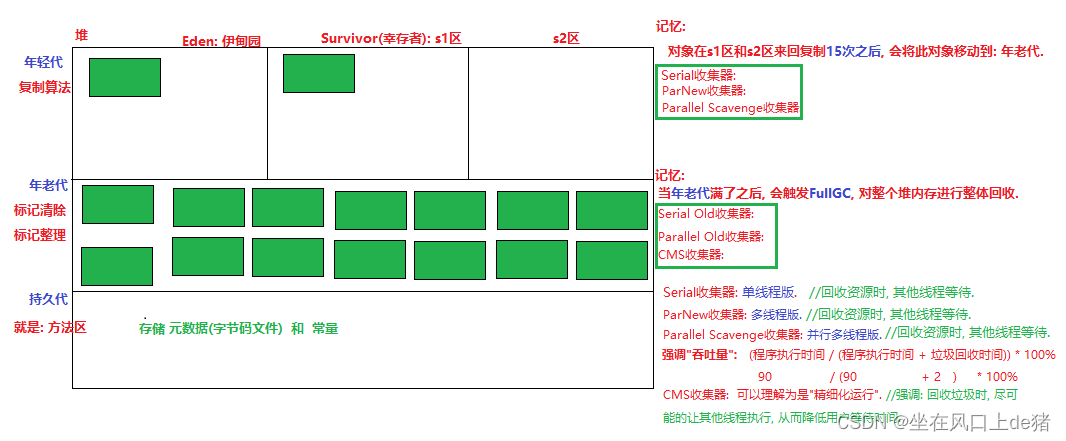
12、jvm堆内存划分及垃圾回收
- JDK1.7
-
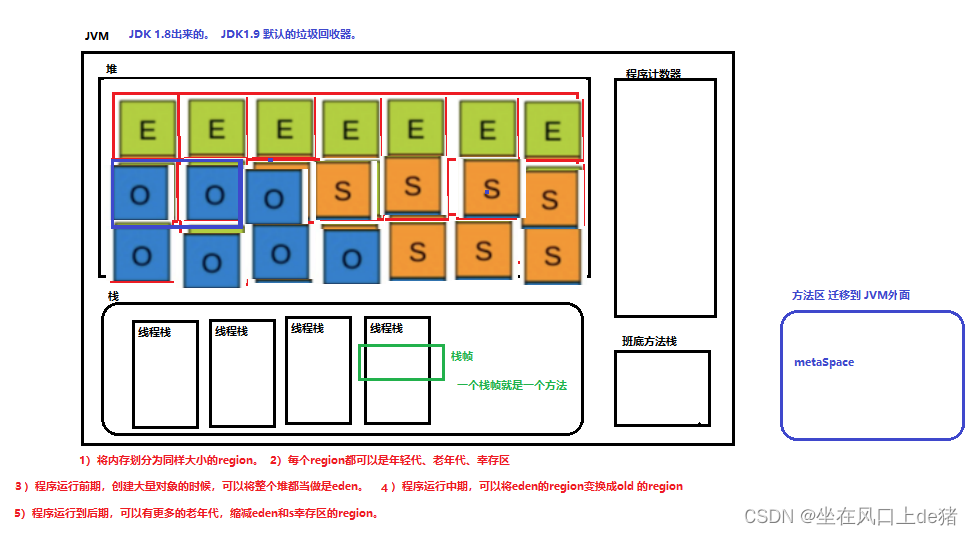
JDK1.8
13、spring项目中常用的注解
- @Controller
- @RestController
- @Service
- @Autowired
- @Resource
- @Configuration
- @Bean
- @Value
- @Scheduled
- @ExceptionHandler