python(一)基础
print输入
python2.7或者2.7以前的版本print后面不需要加括号
加括号报错
print()括号里是字符串要加双引号或者单引号
print("I’m jy")
字符串中有单引号,前后加双引号即可
print('I’m jy)也可以
字符串加数字不能同时输出
print(‘apple’+‘4’)√
print(‘apple’+4) ×
print(‘apple’+str(4)) √
print(int(‘1’)+2)=print(1+2)
print(int(‘1.2’)+2) × 应用float
基本运算符号
加减乘除运算符号
2**2=4
2**3=8
3**2=9
**表示平方
8%2=0 取余
9//4 取整
自变量variable
apple=1
print(apple)
apple_fruit=10
APPLE_FRUIT=11
appleFruit=12+3
print(apple_fruit+appleFruit)
多个自变量
a,b,c=1,2,3
print(a,b,c)
a=1
b=a**2
print(a,b)
循环语句
while for
while循环
condition=1
while condition<10:
print(condition)
condition=condition+1
while True:往下执行
False:停止执行
while True():
print(‘yes’)
无限循环
ctrl+c终止
for循环
example_list=[1,2,3,4,5,6,7]
for i in example_list:
print(i)
print(‘inner of for’)
print(‘outer of for’)
格式:ctrl+[
range(1,3) 不包括3 只有1 2
for i in range(1,10,1): 步长是1
print(i)
判断语句
if
x=4
y=2
z=3
if x>y:
print(‘x is great than y’)
x==y 'x=y’表示x赋值给y,自变量运算
x!=y
if else
x=1
y=2
z=3
if x>y:
print(‘x is great than y’)
else:
print(‘x is less than y’)
if elif else
x=1
y=2
z=3
if x>1:
print(‘x>1’)
elif x<1:
print(‘x<1’)
else:
print(‘x=1’)
python只会停留在第一次满足的条件,忽略后面的循环,然后跳出循环.
def函数
python中的定义函数要以def开头
def function():
print(‘This is a function’)
a=1+2
print(a)
function() 调用函数 在脚本或者运行框里面输出都可以
def 函数参数
def fun(a,b):
c=a**b
print (‘The c is’,c)
fun(2,3)
def默认函数参数
def sale_car(price,colour,brand,length):
print(‘price:’,price,
‘colour:’,colour,
‘brand:’,brand,
‘length:’,length)
sale_car(2000,‘red’,‘bmw’,3)
如果默认的值可以在def 函数的时候加入
def sale_car(brand,length,price=2222,colour=‘red’):
未被定义的值不可以在定义的值的前面
全局&局部变量
def fun():
a=10
print(a)
return a+100
print(fun())
函数外面定义global变量,通常大写字母
APPLE=100 #全局变量
def fun():
a=APPLE #局部变量
print(a)
return a+100
print(fun())
全局变量
APPLE=100
a=None
def fun():
global a #如果不加这句a还是原本来的None
a=20
return a+100
print(APPLE)
print(‘a past=’,a)
print(fun()) #记得运行函数
print(‘a now=’,a)
外部模块安装
numpy
文件读写
text=‘This is my first test.\nThis is next line.\nThis is last line’
print(text)
注意斜杠的方向 代表换行
text=‘This is my first test.\nThis is next line.\nThis is last line’
my_file=open(‘my file.txt’,‘w’)
my_file.write(text)
my_file.close()
w写入 r只读
文件没有会创建
打开后一定要关上文件
文件读写追加内容
append_text=’\nThis is appedded file.’
#‘This is my first test.\nThis is next line.\nThis is last line’
my_file=open(‘my file.txt’,‘a’) #append追加用append
my_file.write(append_text)
my_file.close()
读取文件
file=open(‘my file.txt’,‘r’)
content=file.readline() #readlines表示全部行
second_read_time=file.readline()
print(content,second_read_time)
class类
class Calculator:
name=‘good calculator’
price=18
def add(self,x,y): self表示本身类的属性
print(self.name)
result=x+y
print(result)
def minus(self,x,y):
result=x-y
print(result)
def times(self,x,y):
print(x*y)
def divide(self,x,y):
print(x/y)
运行框
calcul=Calculator()
calcul.add(1,2)
类init
class Calculator:
name=‘good calculator’
price=18
def init(self,name,price,hight,width,weight):
self.name=name
self.price=price
self.h=hight
self.wi=width
self.we=weight
def add(self,x,y):
print(self.name)
result=x+y
print(result)
def minus(self,x,y):
result=x-y
print(result)
def times(self,x,y):
print(x*y)
def divide(self,x,y):
print(x/y)
运行框
c=Calculator('bad calculator',12,13,14,15)
c.name
c.hight
input**
a_input=input(‘Please give a number:’)
print(‘This input number is:’,a_input)
a_input=input(‘Please give a number:’) #return a string
if a_input==‘1’:
print(‘You are beautiful’)
elif a_input==‘2’:
print(‘You are the most beautiful’)
else:
print(‘You are ugly’)
元组列表
#tuple list 用来迭代输出定位
a_tuple=(12,3,5,15,6) #括号
anther_tuple=2,4,6,8,10 #或者去掉括号
a_list=[1,2,3,4,5,4,4,4,4,4] #中括号
#for content in a_tuple:
#print(content)
for index in range(len(a_tuple)): #如果range是5,即为生成从0~4的迭代器,赋予index
print(‘index=’,index,‘number in list=’,a_tuple[index])
列表list
a=[1,2,3,4,5,6]
#a.append(0) #在列表后追加一个值
#a.insert(1,0) #在第一个位置加0
#a.remove(2) #remove掉第一次出现的2
print(a[0])
print(a[-1]) #输出最后一位
print(a[:3]) #输出从第零为到第二位
print(a[2:5]) #输出从第二位到第四位
print(a[5:]) #从第五位到最后一位
print(a.index(2)) #找到2的索引
print(a.count(1)) #出现1的次数
a.sort() #默认排序从小到大
print(a)
a.sort(reverse=True) #从大到小排序
print(a)
多维列表
a=[1,2,3,4,5]
multi_dim_a=[[1,2,3],
[2,3,4],
[3,4,5]]
print(a[2])
print(multi_dim_a[0][1])
字典
每个字典都需要一个key一个内容,字典没有顺序
#a_List=[1,2,3,4,5]
#d={‘apple’:1,‘pear’:2,‘orange’:3}
#d2={1:‘a’,2:‘b’}
#print(a_List[2],d[‘apple’],d2[1])
#del d[‘pear’] #删除元素
#print(d)
#d[‘d’]=20
#print(d)
a_list=[1,2,3,4,5]
d={‘apple’:[1,2,3],‘pear’:{1:3,3:‘a’},‘orange’:2}
print(d[‘pear’][3])
import载入模块
#a_List=[1,2,3,4,5]
#d={‘apple’:1,‘pear’:2,‘orange’:3}
#d2={1:‘a’,2:‘b’}
#print(a_List[2],d[‘apple’],d2[1])
#del d[‘pear’] #删除元素
#print(d)
#d[‘d’]=20
#print(d)
a_list=[1,2,3,4,5]
d={‘apple’:[1,2,3],‘pear’:{1:3,3:‘a’},‘orange’:2}
print(d[‘pear’][3])
import自己所创建的模块脚本
ni:def printdata(data):
print(data)
jy: import ni
ni.printdata(‘jy’)
ni:def printdata(data):
print(‘i am jy’)
print(data)
jy:import ni
ni.printdata(‘jy’)
continue&break
#a=True
#while a:
b=input(‘type something’)
if b==‘1’:
a=False
#else:
# pass
#print('still in while')
#print(‘finish run’)
#a=True
#while a:
b=input(‘type something’)
if b==‘1’:
break #跳出循环
#else:
# pass
#print('still in while')
#print(‘finish run’)
a=True
while a:
b=input(‘type something’)
if b==‘1’:
continue #跳过后面所有的语句直接进入下一个循环,跳出本次循环
else:
pass
print(‘still in while’)
print(‘finish run’)
错误处理try
try:
file=open(‘eee’,‘r+’)
except Exception as e: 报错接受他的错误,将错误的东西存在e中;
print(‘This is no file named as eee’)
response=input(‘do you’)
if response==‘y’:
file=open(‘eee’,‘w’)
else:
pass
else:
file.write(‘sss’)
file.close()
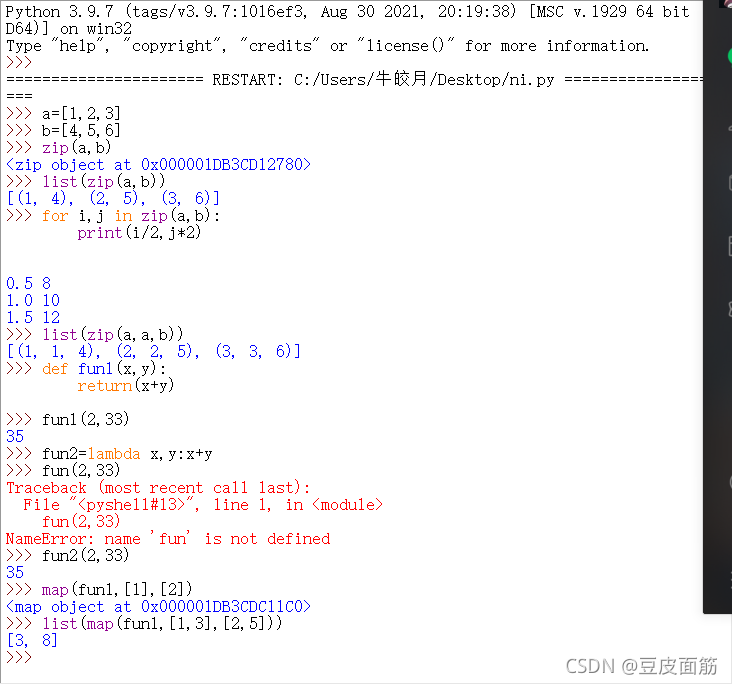
zip&lamba&map功能
copy&deepcopy
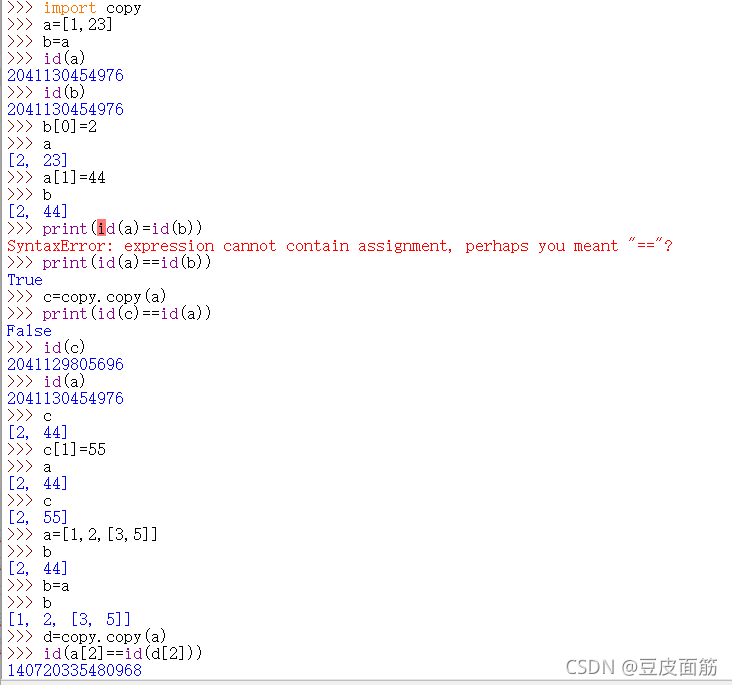

b=a在同一个内存空间上
copy.copy 相当于shallowcopy第一层列表指定到别的空间,第二层列表指定在同一个空间.
copy.deepcopy完完全全的 copy任何东西都不会被重复
threading多线程
分段处理节省时间
pyhon multiprocessing
多核,避免多线程的劣势
python tkinter
pickle存放数据
保存python运算结果,进行提取继续加工
可以保存字典列表变量等
##import pickle
##a_dict={2:3,‘bb’:‘aa’,2:[1,2,3],4:{‘da’:22,‘jj’:‘qq’}}
####file=open(‘pickle_pickle.example’,‘wb’) #wb、rb类似于w、r,表示读写二进制文件
####pickle.dump(a_dict,file)
####file.close()
##file=open(‘pickle_pickle.example’,‘rb’)
##a_dict1=pickle.load(file)
##file.close()
##print(a_dict1)
import pickle
a_dict={2:3,‘bb’:‘aa’,2:[1,2,3],4:{‘da’:22,‘jj’:‘qq’}}
with open(‘pickle_pickle.example’,‘rb’) as file: #用with 不用关闭文件
a_dict1=pickle.load(file)
print(a_dict1)
set找不同
重复的东西剔除掉
##char_list=[‘a’,‘a’,‘a’,‘b’‘b’,‘c’,‘c’,‘d’,‘d’]
##print(type(set(char_list)))
##print(type({1:2}))
##setence=‘weeeee eee rttyy fgyy ttby’
##print(set(setence))
char_list=[‘a’,‘a’,‘a’,‘b’,‘b’,‘c’,‘c’,‘d’,‘d’]
sentence=‘weeeee eee rttyy fgyy ttby’
unique_char=set(char_list)
unique_char.add(‘x’)
##unique_char.clear() #清除,传回空的set()
##print(unique_char.remove(‘a’)) #结果为None,功能的返回值为None,
##print(unique_char)
set1=unique_char
##print(unique_char.discard(‘j’)) #若没有该元素不会报错
##print(unique_char)
set2={‘a’,‘e’,‘i’}
print(set1.difference(set2)) #不同的地方
print(set1.intersection(set2))#相同的地方
RegEx正则表达式
主要用于网页爬虫,找出匹配信息
print(re.search())