关注上方“深度学习技术前沿”,选择“星标公众号”,
资源干货,第一时间送达!


最近冒出来很多 Neural Network Search (NAS) + 目标检测的 paper,今天介绍一篇中了 AAAI 2020 的文章:SM-NAS: Structural-to-Modular Neural Architecture Search for Object Detection。

- 论文链接:https://arxiv.org/abs/1911.09929
- 作者来自:华为诺亚方舟实验室&中山大学
论文效果展示:

思路:这篇 Paper 要做的事情和 EfficientDet 非常类似,都是将神经网络结构搜索和目标检测相结合,而且都是从目标检测算法的整个 pipeline 角度来搜。作者用了 coarse-to-fine 的思想,把 NAS 的搜索过程分为两个 stage,先进行结构层次 (structural-level) 的搜索,再进行模块级别 (modular-level) 的搜索,
下面将分别进行介绍:
Structural-level
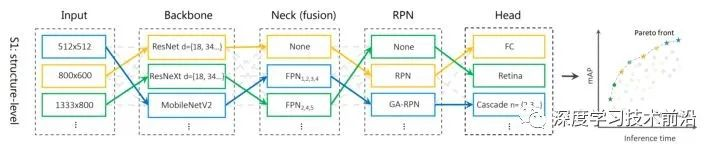
对于目标检测任务来说,整个流程可以分为 backbone, neck, RPN head, bbox head 四部分。当然像 RetinaNet 这样的 one-stage 模型也可以不要 RPN head,这样就是三部分了。之前的很多工作都是尝试优化其中的一部分,比如 DetNAS 是搜 backbone,Guided-Anchor 是优化 RPN 部分,Cascade RCNN 优化 bbox head 部分。本文的作者指出,应该考虑整个系统不同部分之间的关系,在目标检测的整个 pipeline 上联合进行起来搜索。相当于搜一个最好的组合方式来组合这些模块。
随后作者构建了这样的搜索空间:
- backbone:ResNet系列 (Res18, 34, 50, 101),ResNeXt 系列(50, 101),MobileNet V2 。并且都用了 ImageNet 初始化
- neck: 不用 FPN (也就是C4) ,FPN 从 P1 到 P6 的哪层进入哪层出 (P1-P5,P2-P5之类的)
- RPN: 不用 RPN (one-stage),RPN,Guided Anchor
- head: RCNN head, RetinaNet head, Cascade RCNN head (包括 cascade 的数量从2 ~ 4)
- 输入图片分辨率:[ 512x512,800x600,1080x720,1333x800]
把本部分的搜索空间可视化如下图所示:
作者最后得到了 11000 种候选的组合,用进化算法来搜,先随机生成初始值,然后选种变异之类的。作者最后花了 2000 GPU hours,一共搜了约500种组合。得到的结果如下图所示:
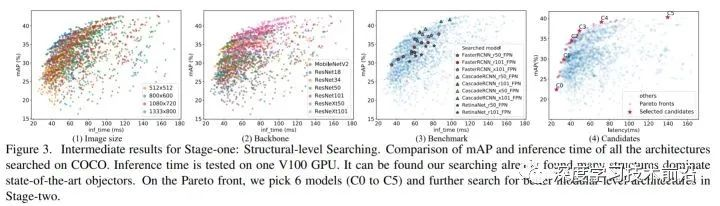
最左边的图是在不同输入图片分辨率下, speed-accuracy trade off 曲线。作者的横轴用的就是在 V100 GPU 上的 inference time,而不是 FLOPs 这些间接的指标。作者发现 MobileNet V2 虽然 FLOPs 是最小的,但是由于有比较大的内存访问开销,造成实际上用 inference time 来比的话不太行。
作者在上图最右面的帕累托最优曲线上选了6个模型,C0 - C5,送到下一个 Modular-level search 的部分。
Modular-level
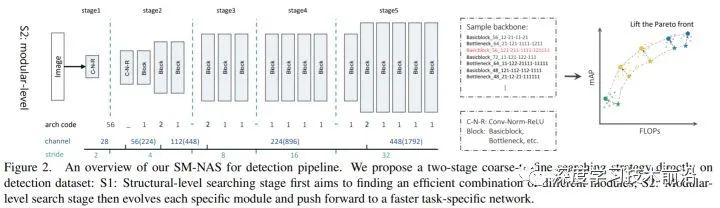
在上一步确定了选择哪些模块、模块之间的连接方式之后,这一步来单独优化每个模块。
作者先搜一个 backbone ,固定了有 5 个 stage,并且固定了要逐渐 downsample 2 倍。由于换新的 backbone 再用 ImageNet 初始化会很麻烦,作者在这里就都不用 pre-train model,随机初始化了。为了减轻不初始化的影响,作者把 Batch Normalization 替换成 Group Normalization ,并加入了 Weight Standardization。
这一部分的参数空间非常简单,其实就是搜 backbone 的 channel 数量。比如在之前的 structural-level 搜到的 C5 模型,backbone 用的是 X101_bottleneck。作者把初始的 channel 数量指定为 {48, 56, 64, 72} 四个候选值,然后搜后面的 conv 里面要在哪里把 channel 数量乘2。并没有引入新的运算。作者还搜了 FPN 和 head 部分 的 channel 数量,候选组合就是 {128, 256, 512} 。这一步作者又把衡量速度的指标从 inference time 改成了 FLOPs,作者说 inference time 在不同 GPU 上不一样,而 FLOPs 相对更 consistency。
把本部分的搜索空间可视化如下图所示:
最后搜出来的结果,E0 - E5 如下表所示:
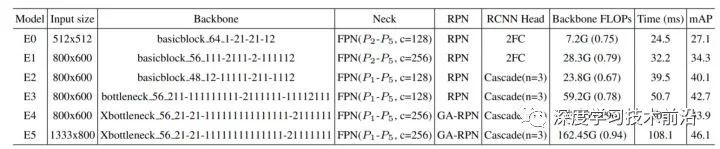
这个表里面在 Backbone 部分有很多字符串,比如"64 1-21-21-12",64 指的是初始的 channel 数量,后面的 1 表示过完 block 结构之后 channel 数量不变,2 表示 channel 数量要乘2。从这个表格上可以看出在每个 stage 开始的时候把 channel 数量乘2倍比较好。
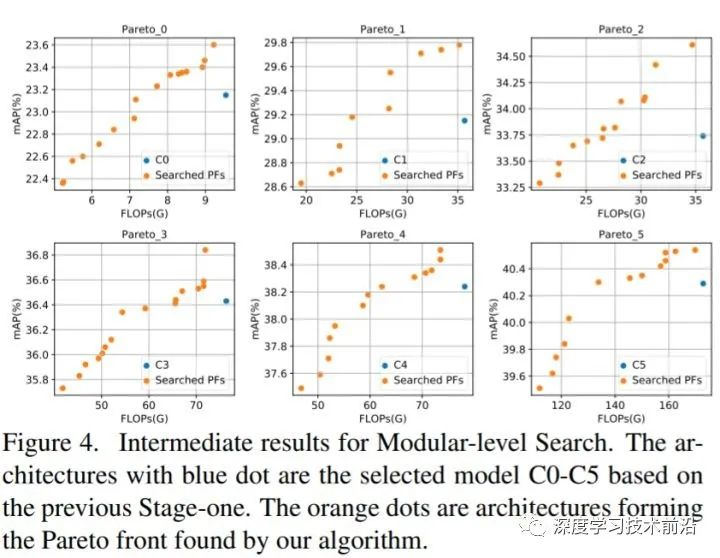
在下图中,蓝色点是上一部分 C0 ~ C5 structural-level 的结果,橘黄色点是 modular-level search 得到的模型,确实有 refine 的作用。
实验结果
和 state-of-the-art 的比较如下表,主要是在 inference time 上有优势:

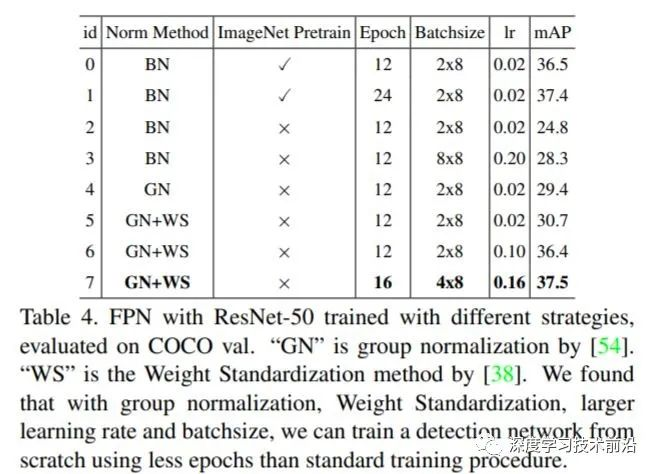
对于 training from scratch 的对照实验如下表,可以看出 BN + imagenet pretrain 的结果和 GN+WS+no pretrain 的结果接近。
换到其它数据集的结果如下表:

结论
总结一下这篇 paper,个人觉得就是它的 Novelty 和 EfficientDet 非常类似,都是用 NAS 的方法来搜整个目标检测的 pipeline。
EfficientDet 的搜索空间更加复杂,backbone 直接用 EfficientNet,还设计了一个专门的BiFPN,性能相对更好一点。
而这篇的优点在于分两个 stage 来搜,coarse to fine 的思想,对于目标检测这种 pipleline 特别长的任务可以减小搜索空间。
重磅!DLer-目标检测交流群已成立!
为了能给大家提供一个更好的交流学习平台!针对特定研究方向,我建立了目标检测微信交流群,目前群里已有百余人!本群旨在交流目标检测、密集人群检测、关键点检测、人脸检测、人体姿态估计等内容。
进群请备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+小明)
广告商、博主请绕道!
???? 长按识别,即可进群!
觉得有用麻烦给个在看啦~
