检测和分类不同,检测过程中,图片处理以后,bbox往往也需要同步变换
里面碰到最坑的地方,在于cv.rectangle(),如果是对图像进行操作,一定要deepcopy
文章目录
1. 水平翻转
对于ToTensor操作,只需要将图片由img转为tensor。target可以不变
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),
"val": transforms.Compose([transforms.ToTensor()])
}
class ToTensor(object):
"""将PIL图像转为Tensor"""
def __call__(self, image, target):
image = F.to_tensor(image)
return image, target
class RandomHorizontalFlip(object):
"""随机水平翻转图像以及bboxes"""
def __init__(self, prob=0.5):
self.prob = prob
def __call__(self, image, target):
"""随机生成概率,如果<0.5 就进行水平翻转
水平翻转的时候,bbox的位置也发生了变化的
"""
if random.random() < self.prob:
"""b,c,h,w """
height, width = image.shape[-2:]
image = image.flip(-1) # 水平翻转图片
bbox = target["boxes"]
# bbox: xmin, ymin, xmax, ymax
"""
bbox[:,[0,1,2,3]] ,第一维度为图片中bbox的数量,第二维度才是xmin, ymin, xmax, ymax 下标分别为0 1 2 3
水平翻转后的坐标变换
高度没有变化,只有宽度在变
xmin撇 = 宽度-原来的xmax 从图中可以观察出来 (xmin撇还是左上, 同理右下)
"""
bbox[:, [0, 2]] = width - bbox[:, [2, 0]] # 翻转对应bbox坐标信息
"""替换掉原来的信息,返回就行"""
target["boxes"] = bbox
return image, target
对应的程序理解如下
只有x的坐标会发生变换,y的坐标是不变的
x1, y1, x2, y2
---->
x1_ = w - x2
x2_ = w - x1
新的坐标 : (x1_, y1, x2_, y2)
写成矩阵 : bbox[:, [0, 2]] = w - bbox[:, [0, 2]]

1.1 图片示例
from lxml import etree
import cv2 as cv
import matplotlib.pyplot as plt
from copy import deepcopy
import numpy as np
def parse_xml_to_dict(xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def get_xml_info(xml_path):
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = parse_xml_to_dict(xml)["annotation"]
bboxes = []
for index, obj in enumerate(data["object"]):
# 获取每个object的box信息
xmin = int(obj["bndbox"]["xmin"])
xmax = int(obj["bndbox"]["xmax"])
ymin = int(obj["bndbox"]["ymin"])
ymax = int(obj["bndbox"]["ymax"])
# bbox = np.array([xmin, ymin, xmax, ymax])
bbox = [xmin, ymin, xmax, ymax]
bboxes.append(bbox)
return bboxes
img_path = "test_img_xml/1.jpg"
xml_path = "test_img_xml/1.xml"
img = cv.imread(img_path)
tmp = deepcopy(img)
h, w = img.shape[:2]
bboxes = np.array(get_xml_info(xml_path))
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(img, pt1, pt2, (0, 0, 255), 2)
# 水平变换
tmp = cv.flip(tmp, 1)
tmp_boxes = deepcopy(bboxes)
tmp_boxes[:, [0, 2]] = w - tmp_boxes[:, [2, 0]]
for box in tmp_boxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(tmp, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp[:, :, ::-1], cmap='gray')
plt.show()

1.2 利用仿射变换实现
利用仿射变换实现图像变换和坐标变换的核心在于找到正确的变换矩阵
参考链接:图像翻转之仿射变换
"""水平翻转"""
M = [[-1, 0, w],
[0, 1, 0],
[0, 0, 1]]
x_n = w - x
y_n = y
根据这种变换去得到变换矩阵即可
"""垂直翻转"""
M = [[1, 0, 0],
[0, -1, h],
[0, 0, 1]]
"""水平垂直翻转"""
M = [[-1, 0, w],
[0, -1, h],
[0, 0, 1]]
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
from copy import deepcopy
img_path = "../test_img_xml/1.jpg"
bboxes = np.array([[71, 252, 216, 314],
[58, 202, 241, 295]])
img = cv.imread(img_path) # h=500, w=375
h, w = img.shape[:2]
# 水平垂直翻转
F = np.eye(3)
F[0, 0] = -1
F[0, 2] = w
F[1, 1] = -1
F[1, 2] = h
tmp = cv.warpAffine(img, F[:2], (w, h))
tmp_boxes = []
for box in bboxes:
x1, y1, x2, y2 = box
x1_n, y1_n, _ = F @ np.array([[x1], [y1], [1]])
x2_n, y2_n, _ = F @ np.array([[x2], [y2], [1]])
x1_n = int(x1_n)
y1_n = int(y1_n)
x2_n = int(x2_n)
y2_n = int(y2_n)
"""其实应该再做一个限制宽高和取整操作"""
tmp_boxes.append([x1_n, y1_n, x2_n, y2_n])
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(img, pt1, pt2, (0, 0, 255), 2)
for box in tmp_boxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(tmp, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp[:, :, ::-1], cmap='gray')
plt.show()
水平垂直翻转结果如下

2. resize
只需要先计算得到ratio_x, ratio_y即可
bbox = bbox * np.array([ratio_x, ratio_y, ratio_x, ratio_y])
# 如果有padw、padh,补充上即可
bbox[:, [0,2]] += padw
bbox[:, [1, 3]] += padh
代码如下
from lxml import etree
import cv2 as cv
import matplotlib.pyplot as plt
from copy import deepcopy
import numpy as np
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
dw = int(dw)
dh = int(dh)
if shape[::-1] != new_unpad: # resize
img = cv.resize(img, new_unpad, interpolation=cv.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv.copyMakeBorder(img, top, bottom, left, right, cv.BORDER_CONSTANT, value=color) # add border
return img, ratio[0], (dw, dh) # letterbox默认等比缩放,取一个值就可
def parse_xml_to_dict(xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def get_xml_info(xml_path):
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = parse_xml_to_dict(xml)["annotation"]
bboxes = []
for index, obj in enumerate(data["object"]):
# 获取每个object的box信息
xmin = int(obj["bndbox"]["xmin"])
xmax = int(obj["bndbox"]["xmax"])
ymin = int(obj["bndbox"]["ymin"])
ymax = int(obj["bndbox"]["ymax"])
bbox = [xmin, ymin, xmax, ymax]
bboxes.append(bbox)
return bboxes
img_path = "../test_img_xml/1.jpg"
xml_path = "../test_img_xml/1.xml"
img = cv.imread(img_path)
tmp = deepcopy(img)
h, w = img.shape[:2]
print(h, w)
bboxes = np.array(get_xml_info(xml_path))
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(img, pt1, pt2, (0, 0, 255), 2)
tmp, ratio, pad = letterbox(tmp, (640, 640))
tmp_boxes = deepcopy(bboxes)
tmp_boxes_n = tmp_boxes * ratio
tmp_boxes_n = tmp_boxes_n.astype(np.int)
tmp_boxes_n[:, [0, 2]] += pad[0]
tmp_boxes_n[:, [1, 3]] += pad[1]
for box in tmp_boxes_n:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(tmp, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp[:, :, ::-1], cmap='gray')
plt.show()
resize前后的变化(等比缩放,因此才有填充出现)

2.1 多尺度
其实,多尺度和resize概念差不多
额外加上填充,如果有padw和padh
# 测试一下多尺度变换后,bbox的变化
# bboxes是(x1,y1,x2,y2);target是归一化0~1之间的,(x,y,w,h) 中心点,宽高坐标形式
# 经过证明,若对图像进行resize操作,比例为固定值时。若原来的坐标为(x1,y1,x2,y2)时,则只需要bboxes * ratio即可
# 若标签为(x,y,w,h)形式时,则无需对其进行处理
# 当然,若出现填充,padw和padh时,则均需要再额外加上填充
import numpy as np
import cv2 as cv
from copy import deepcopy
import matplotlib.pyplot as plt
img_path = "../test_img_xml/1.jpg"
img = cv.imread(img_path)
img_h, img_w = img.shape[:2]
bboxes = np.array([[71, 252, 216, 314],
[58, 202, 241, 295]])
targets = []
for box in bboxes:
xmin = box[0]
xmax = box[2]
ymin = box[1]
ymax = box[3]
xcenter = xmin + (xmax - xmin) / 2
ycenter = ymin + (ymax - ymin) / 2
w = xmax - xmin
h = ymax - ymin
xcenter = round(xcenter / img_w, 4)
ycenter = round(ycenter / img_h, 4)
w = round(w / img_w, 4)
h = round(h / img_h, 4)
targets.append([xcenter, ycenter, w, h])
print(targets)
tmp = deepcopy(img)
new_w, new_h = img_w * 2, img_h * 2
tmp = cv.resize(tmp, (new_w, new_h))
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
x = np.array(x)
y = deepcopy(x)
y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x 中心点减去左边的值
y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
return y.astype(np.int)
tmp_boxes = xywhn2xyxy(targets, new_w, new_h)
# tmp_boxes = bboxes * 2
print(tmp_boxes)
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(img, pt1, pt2, (0, 0, 255), 2)
for box in tmp_boxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(tmp, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp[:, :, ::-1], cmap='gray')
plt.show()

3. 裁剪
3.1 centercrop
中心点裁剪
- 先设置裁剪后的图片大小,沿中心点开始计算,
ow、oh - 计算多出来的左上角, 类似于
padw和padh,此处使用i_0、j_0表示 dst = src[j_0:j_0+oh, i_0:i_0+ow,:],切片的操作bboxes_n = bboxes - [j_0, i_0, j_0, i_0],减去多出的- bboxes_n设置边界,防止越界
- 注意一个问题,如果剩下的框的面积小于阈值,如果0.3,即,
area_new < 0.3 * area,该框可以去掉,设置为负样本
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
from copy import deepcopy
img_path = "../test_img_xml/1.jpg"
bboxes = np.array([[71, 252, 216, 314],
[58, 202, 241, 295]])
img = cv.imread(img_path) # h=500, w=375
h, w = img.shape[:2]
# center_crop选择(300,300)
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(img, pt1, pt2, (0, 0, 255), 2)
# 中心裁剪
ow, oh = 300, 350
i_0 = int((h-oh)/2) # 代表多出的高
j_0 = int((w-ow)/2) # 代表多出的宽
tmp = deepcopy(img)
tmp = tmp[i_0:i_0+oh, j_0:j_0+ow, :]
print(tmp.shape)
tmp_boxes = deepcopy(bboxes)
tmp_boxes = tmp_boxes - np.array([j_0, i_0, j_0, i_0])
tmp_boxes[:, ::2] = np.clip(tmp_boxes[:, ::2], 0, ow-1) # 防止越界
tmp_boxes[:, 1::2] = np.clip(tmp_boxes[:, 1::2], 0, oh-1) # 防止越界
for box in tmp_boxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv.rectangle(tmp, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp[:, :, ::-1], cmap='gray')
plt.show()
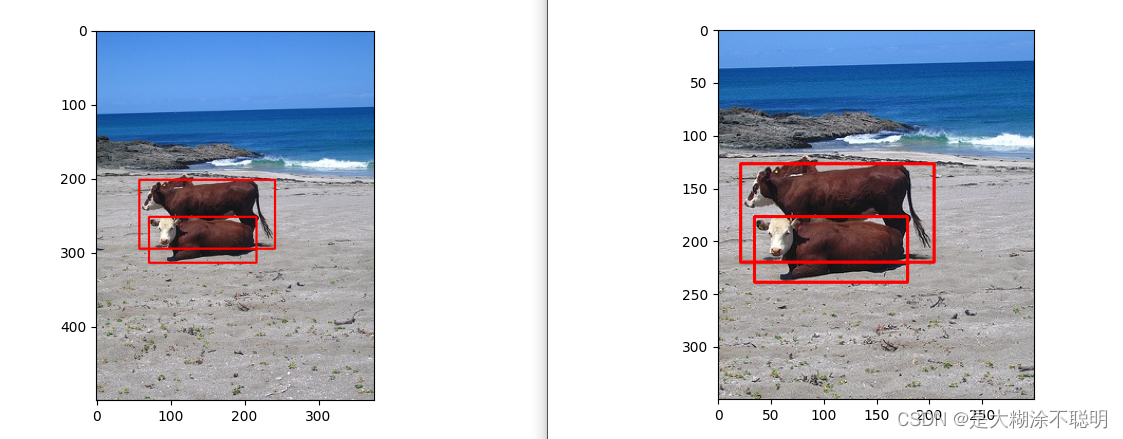
3.2 随机大小尺寸裁剪
下面的代码是为一个项目写的数据增强,
主要的功能就是从原图上,随机裁剪一块区域。
因为crop的操作,能使得一些小目标变的更大。
核心地方就是:
1.如何得到随机的区域
2.得到随机的区域后,如何处理原始的坐标和标签
由于原始的标签可能为空,因此多增加了几个if语句
主要流程如下:
- 设置一个随机数,用于充当裁剪区域的比例
- 得到裁剪区域,(i,j,h,w)
- 计算裁剪后的图片以及对应的bbox
- 将bbox和原始的面积相互比较,阈值设置为0.5
import numpy as np
from copy import deepcopy
def random_cropresize(meta_tmp, ratio_scale=(0.7, 1), thr=0.5):
"""
param meta_data: 是一个字典
param ratio_scale: 缩放的范围
param thr: 面积阈值的范围
return: 一个字典
"""
meta_data = deepcopy(meta_tmp)
img = meta_data["img"]
labels = meta_data["gt_labels"]
bboxes = meta_data["gt_bboxes"]
h, w = img.shape[:2]
ratio = random.uniform(*ratio_scale)
oh, ow = int(h * ratio), int(w * ratio) # 得到裁剪后的区域的高和宽
i = random.randint(0, h - oh) # 随机的i
j = random.randint(0, w - ow) # 随机的j
dst = img[i:i + oh, j:j + ow, :]
meta_data['img'] = dst
if bboxes.shape[0] > 0:
tmp_boxes = deepcopy(bboxes)
tmp_boxes = tmp_boxes - np.array([j, i, j, i]) # 变换坐标得到新的值
tmp_boxes[:, ::2] = np.clip(tmp_boxes[:, ::2], 0, ow - 1) # 防止越界
tmp_boxes[:, 1::2] = np.clip(tmp_boxes[:, 1::2], 0, oh - 1) # 防止越界
new_labels = []
new_bbox = []
for idx in range(tmp_boxes.shape[0]):
old_box = bboxes[idx]
tmp_box = tmp_boxes[idx]
area_1 = (old_box[2] - old_box[0]) * (old_box[3] - old_box[1])
area_2 = (tmp_box[2] - tmp_box[0]) * (tmp_box[3] - tmp_box[1])
if area_2 < thr * area_1:
continue
else:
new_bbox.append(tmp_boxes[idx])
new_labels.append(labels[idx])
if len(new_labels): # 如果new_labels里面有元素,说明此时有剩余的框。如果没有元素,则相应的赋值为空即可
new_bbox = np.array(new_bbox)
new_labels = np.array(new_labels)
else: # 下面的两行代码参考了源码的“异常情况”,早这么写,早没事...
new_bbox = np.zeros((0, 4), dtype=np.float32)
new_labels = np.array([], dtype=np.int64)
meta_data["gt_labels"] = new_labels
meta_data["gt_bboxes"] = new_bbox
return meta_data
测试代码
img_path = "../test_img_xml/1.jpg"
img = cv2.imread(img_path) # h=500, w=375
h, w = img.shape[:2]
bboxes = np.array([[71, 252, 216, 314],
[58, 202, 241, 295]])
labels = np.array([2, 1])
meta = {'img': img, 'img_info': '1.jpg', 'gt_bboxes': bboxes, 'gt_labels': labels}
new_meta = random_cropresize(meta)
new_bbox = new_meta['gt_bboxes']
tmp_labels = new_meta['gt_labels']
new_info = new_meta['img_info']
tmp = new_meta['img']
print(new_bbox)
print(new_info)
print(tmp_labels)
b = np.zeros((0, 4), dtype=np.float32)
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv2.rectangle(img, pt1, pt2, (0, 0, 255), 2)
for box in new_bbox:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv2.rectangle(tmp, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp[:, :, ::-1], cmap='gray')
plt.show()
随机裁剪,每次结果都不一致
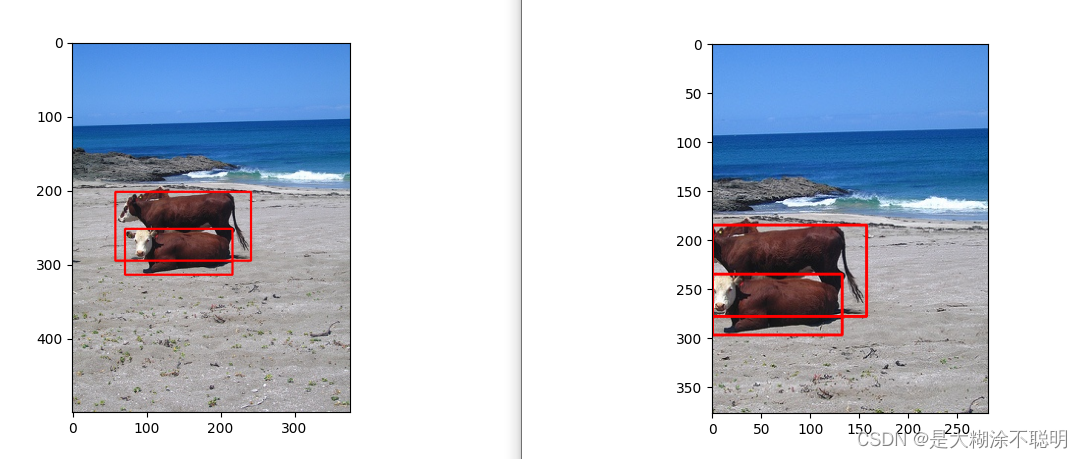
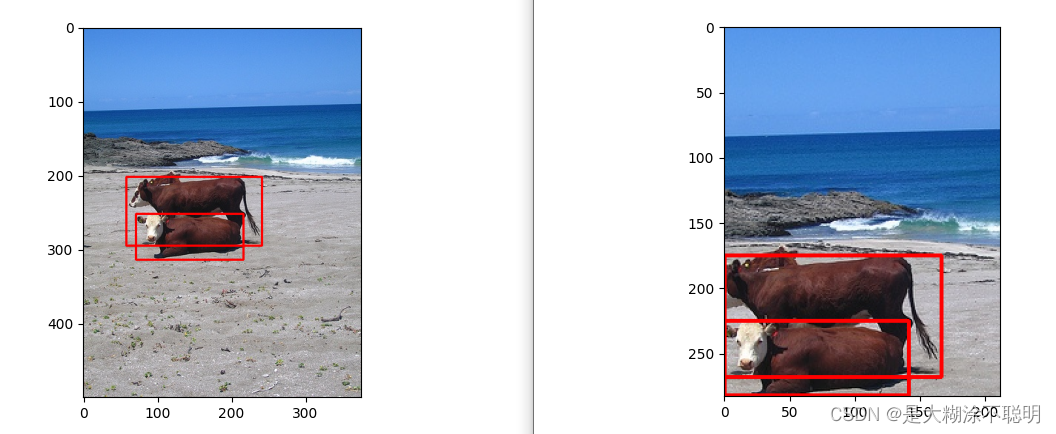
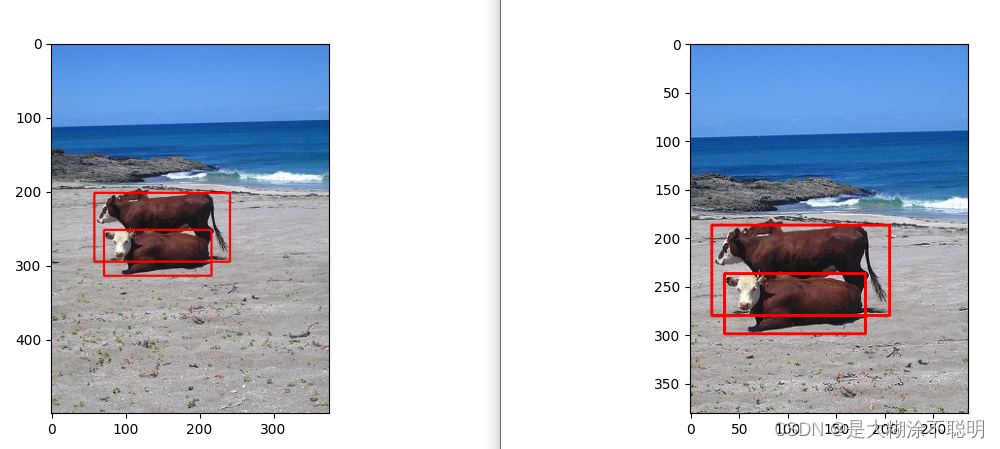
4. yolov5中多尺度训练
yolov5中datasets的加载流程是:
1. 先进行letterbox、仿射变换、颜色变换等操作
2. bgr-->rgb, hwc-->chw, torch.from_numpy
3. 是在训练的过程中才除以255的,也就是说预处理过程中,并没有除均值减标准差的操作
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0
实际上多尺度训练,是很有用的一个操作
因为它能将小目标变大
1. 设置一个整数,位于imgsz的(0.5倍,1.5倍)之间
2. 得到一个缩放比例,不发生形变的
3. 使用双线性插值,得到缩放后的图
"""
很重要的一点,因为target的坐标是(0, 1)之间,因此对于是否对bbox进行处理不会有任何的影响
"""
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + 32) // 32 * 32 # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
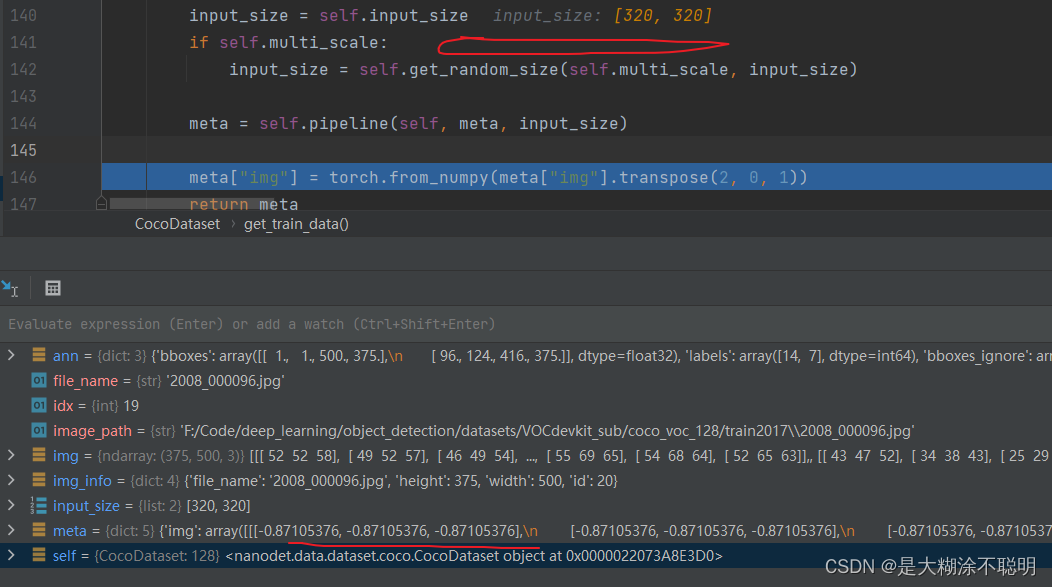
两个问题如下:
1. 这里的多尺度,根本就是不完善的...并未对bbox进行处理。 而且它的anns是左上、右下的形式,而非归一化(0, 1)之间的。
因此,如果使用多尺度训练,不对框进行处理是不对的
(2022.10.27 经过验证,多尺度没有问题)
2. 由于里面设置的问题,在无法将bgr转rgb,像素值并非(0, 255)。而是归一化(0,1),并且减均值除方差了...
可能需要修改整体的实现过程
(2022.10.31 上面的多尺度和bgr等都没有问题,无需修改)
5. 仿射变换中实现bbox的变换
当得到变换矩阵M后,最后一个保持齐次性,应该把坐标除以一个倍率,得到x' 和 y‘

5.1 带注释的程序
关于bbox的变换,涉及到4个点,左上、右下、左下、右上的,相对较为复杂
自己也是debug了比较久的时间才看明白
并且,这一段代码的本质还是矩阵的变换,因此先应该了解仿射变换的本质,才能看懂代码。
def warp_boxes(boxes, M, width, height):
n = len(boxes)
if n:
# warp points
xy = np.ones((n * 4, 3))
# 一个矩形框是4个点的,即4个坐标,左上、右下、左下、右上
tmp_box = boxes[:, [0, 1, 2, 3, 0, 3, 2, 1]]
# tmp_box_1 的shape 为(n*4, 2),即:该矩阵只有两列,代表了所有的坐标点。
tmp_box_1 = tmp_box.reshape(n * 4, 2)
# 将所有的单独点的坐标,赋给xy[:, :2]前两列
# xy中的一个元素就对应着, [x, y, 1] 齐次性,
xy[:, :2] = boxes[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(
n * 4, 2
) # 所有点,矩阵变换,求变换后的点
xy = xy @ M.T # transform
# [x,y]/1 前两列坐标x,y除以第3列坐标值,代表“齐次性”; 此时,xy已经去掉了第三列了
# 只有出现透视变换时,第三列的数值才不会为1
# 再reshape回去,就又变成了8个点[[x1,y1,x2,y2,x1,y2,x2,y1]]
# 上面的那句话不对,并不能说是同一个x和同一个y
# 因为经过仿射变换后,不一定是方方正正的矩形了,只能说,对应的几个索引的代表x的值以及y的值
xy = (xy[:, :2] / xy[:, 2:3]).reshape(n, 8)
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
# 找到所有的变换后的x坐标、y坐标,分别将其中的min、max重新构成一个集合,就是变换后的bbox
# 再根据变换后的图片的宽高,裁剪一下,得到合理的数值
# 此处的x.min(1)是axis=1的意思,按照列求min和max
# x.min(1)后的shape: (12, )
d1 = x.min(1)
d2 = y.min(1)
d3 = x.max(1)
d4 = y.max(1)
# tmp_box_2 ,默认按照行拼接, shape:(48, ) 。 就是将一个d一直排列下去
tmp_box_2 = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1)))
tmp_box_3 = tmp_box_2.reshape(4, n)
# tmp_box_3转置一下,就成了(n, 4)形式, (x1,y1,x2,y2)的结果
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip boxes
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
return xy.astype(np.float32)
else:
return boxes
5.2 不带注释的程序
"""
"""
import numpy as np
import cv2
import random
import matplotlib.pyplot as plt
import math
from typing import Optional, Tuple
def warp_boxes(boxes, M, width, height):
n = len(boxes)
if n:
# warp points
xy = np.ones((n * 4, 3))
xy[:, :2] = boxes[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(
n * 4, 2
) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform
xy = (xy[:, :2] / xy[:, 2:3]).reshape(n, 8) # rescale
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip boxes
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
return xy.astype(np.float32)
else:
return boxes
def get_flip_matrix(prob=0.5):
F = np.eye(3)
if random.random() < prob:
F[0, 0] = -1
return F
def get_perspective_matrix(perspective=0.0):
"""
:param perspective:
:return:
"""
P = np.eye(3)
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
return P
def get_rotation_matrix(degree=0.0):
"""
:param degree:
:return:
"""
R = np.eye(3)
a = random.uniform(-degree, degree)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=1)
return R
def get_scale_matrix(ratio=(1, 1)):
"""
:param ratio:
"""
Scl = np.eye(3)
scale = random.uniform(*ratio)
Scl[0, 0] *= scale
Scl[1, 1] *= scale
return Scl
def get_stretch_matrix(width_ratio=(1, 1), height_ratio=(1, 1)):
"""
这个矩阵一旦乘过去,实际上是拉伸处理了,会发生形变的
:param width_ratio:
:param height_ratio:
"""
Str = np.eye(3)
Str[0, 0] *= random.uniform(*width_ratio)
Str[1, 1] *= random.uniform(*height_ratio)
return Str
def get_shear_matrix(degree):
"""
:param degree:
:return:
"""
Sh = np.eye(3)
Sh[0, 1] = math.tan(
random.uniform(-degree, degree) * math.pi / 180
) # x shear (deg)
Sh[1, 0] = math.tan(
random.uniform(-degree, degree) * math.pi / 180
) # y shear (deg)
return Sh
def get_translate_matrix(translate, width, height):
"""
:param translate:
:return:
"""
T = np.eye(3)
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation
return T
def get_resize_matrix(raw_shape, dst_shape, keep_ratio):
"""
Get resize matrix for resizing raw img to input size
:param raw_shape: (width, height) of raw image
:param dst_shape: (width, height) of input image
:param keep_ratio: whether keep original ratio
:return: 3x3 Matrix
"""
r_w, r_h = raw_shape
d_w, d_h = dst_shape
Rs = np.eye(3)
if keep_ratio:
C = np.eye(3)
C[0, 2] = -r_w / 2
C[1, 2] = -r_h / 2
if r_w / r_h < d_w / d_h:
ratio = d_h / r_h
else:
ratio = d_w / r_w
Rs[0, 0] *= ratio
Rs[1, 1] *= ratio
T = np.eye(3)
T[0, 2] = 0.5 * d_w
T[1, 2] = 0.5 * d_h
return T @ Rs @ C
else:
Rs[0, 0] *= d_w / r_w
Rs[1, 1] *= d_h / r_h
return Rs
def get_minimum_dst_shape(
src_shape: Tuple[int, int],
dst_shape: Tuple[int, int],
divisible: Optional[int] = 0,
) -> Tuple[int, int]:
"""Calculate minimum dst shape"""
src_w, src_h = src_shape
dst_w, dst_h = dst_shape
if src_w / src_h < dst_w / dst_h:
ratio = dst_h / src_h
else:
ratio = dst_w / src_w
dst_w = int(ratio * src_w)
dst_h = int(ratio * src_h)
if divisible and divisible > 0:
dst_w = max(divisible, int((dst_w + divisible - 1) // divisible * divisible))
dst_h = max(divisible, int((dst_h + divisible - 1) // divisible * divisible))
return dst_w, dst_h
img_path = "../test_img_xml/1.jpg"
raw_img = cv2.imread(img_path) # h=500, w=375
height = raw_img.shape[0] # shape(h,w,c)
width = raw_img.shape[1]
# center
C = np.eye(3)
C[0, 2] = -width / 2
C[1, 2] = -height / 2
P = get_perspective_matrix(0)
C = P @ C
Scl = get_scale_matrix((0.6, 1.2)) # [0.6,1.4]之间得到一个随机值,得到缩放的scl矩阵
C = Scl @ C
Str = get_stretch_matrix()
C = Str @ C
R = get_rotation_matrix(10) # 沿原点旋转
C = R @ C
Sh = get_shear_matrix(0)
C = Sh @ C
F = get_flip_matrix() # 已经原图的中心点移动到原点,水平翻转中第三列就没有加上w或者h
C = F @ C
T = get_translate_matrix(0.2, width, height) # (0.2, 0.7)产生一个随机数,再乘以宽、高得到平移矩阵
M = T @ C
# 采用长边缩放的原则,根据这个宽高以及预设的(512, 512)获取实际缩放后的dst_shape
dst_shape = get_minimum_dst_shape(
(width, height), (640, 640), 32
)
ResizeM = get_resize_matrix((width, height), dst_shape, True)
M = ResizeM @ M
tmp1 = cv2.warpPerspective(raw_img, M, dsize=tuple(dst_shape))
tmp2 = cv2.warpAffine(raw_img, M[:2], dsize=tuple(dst_shape))
bboxes = np.array([[71, 252, 216, 314],
[58, 202, 241, 295]])
tmp_bboxes = warp_boxes(bboxes, M, dst_shape[0], dst_shape[1])
for box in bboxes:
pt1 = (box[0], box[1])
pt2 = (box[2], box[3])
cv2.rectangle(raw_img, pt1, pt2, (0, 0, 255), 2)
for box in tmp_bboxes:
pt1 = (int(box[0]), int(box[1]))
pt2 = (int(box[2]), int(box[3]))
cv2.rectangle(tmp1, pt1, pt2, (0, 0, 255), 2)
plt.figure(1)
plt.imshow(raw_img[:, :, ::-1], cmap='gray')
plt.figure(2)
plt.imshow(tmp1[:, :, ::-1], cmap='gray')
plt.figure(3)
plt.imshow(tmp2[:, :, ::-1], cmap='gray')
plt.show()
