(1)Why are Visually-Grounded Language Models Bad at Image Classification?
(2)ANALYZING AND BOOSTING THE POWER OF FINEGRAINED VISUAL RECOGNITION FOR MULTI-MODAL LARGE LANGUAGE MODELS
1. Why are Visually-Grounded Language Models Bad at Image Classification?
Accepted by nips2024
1.1 研究动机
目前很多公开的VLMs(visually-grounded language models)尽管使用了CLIP用作vision encoder,并且有很多参数,但是在图片分类任务上表现不如CLIP。探究这个现象的原因则是这篇论文的研究动机
1.2 contribution
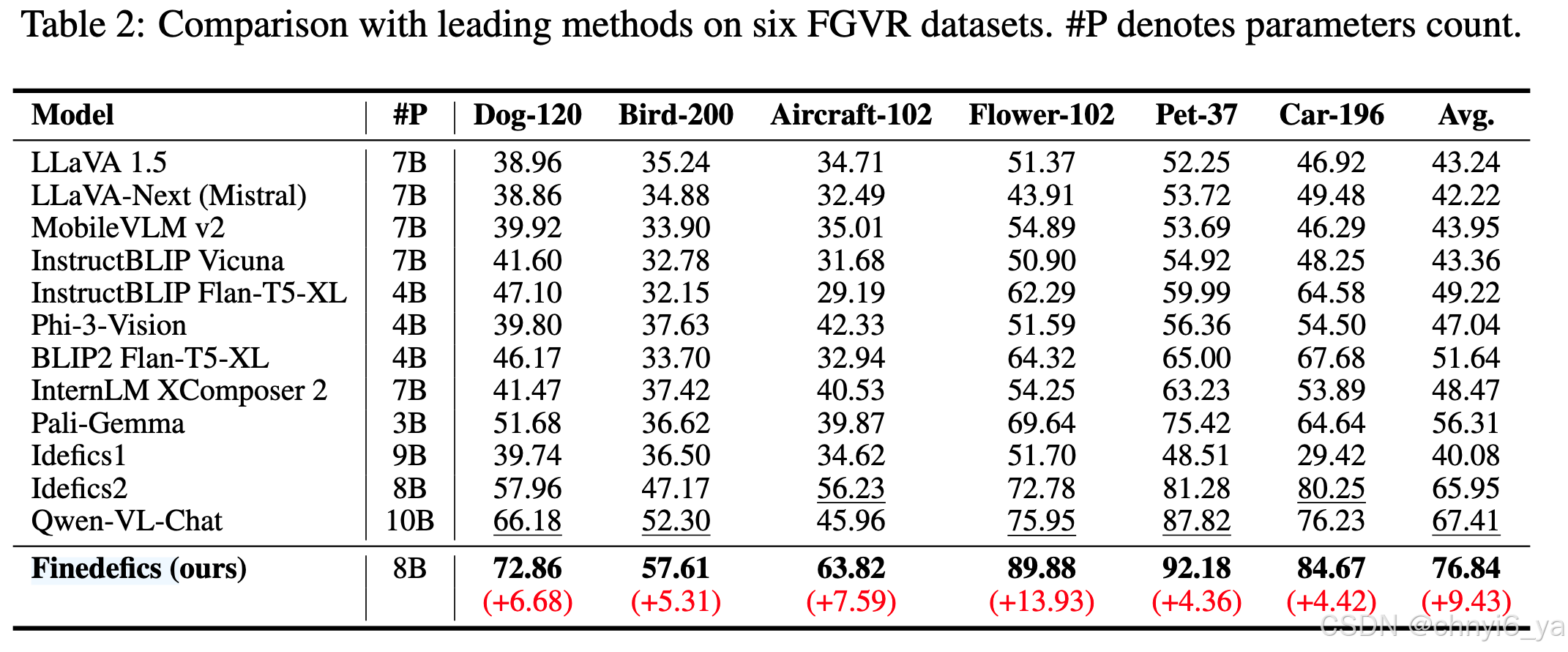
前三个贡献点分别对应下面三张图:
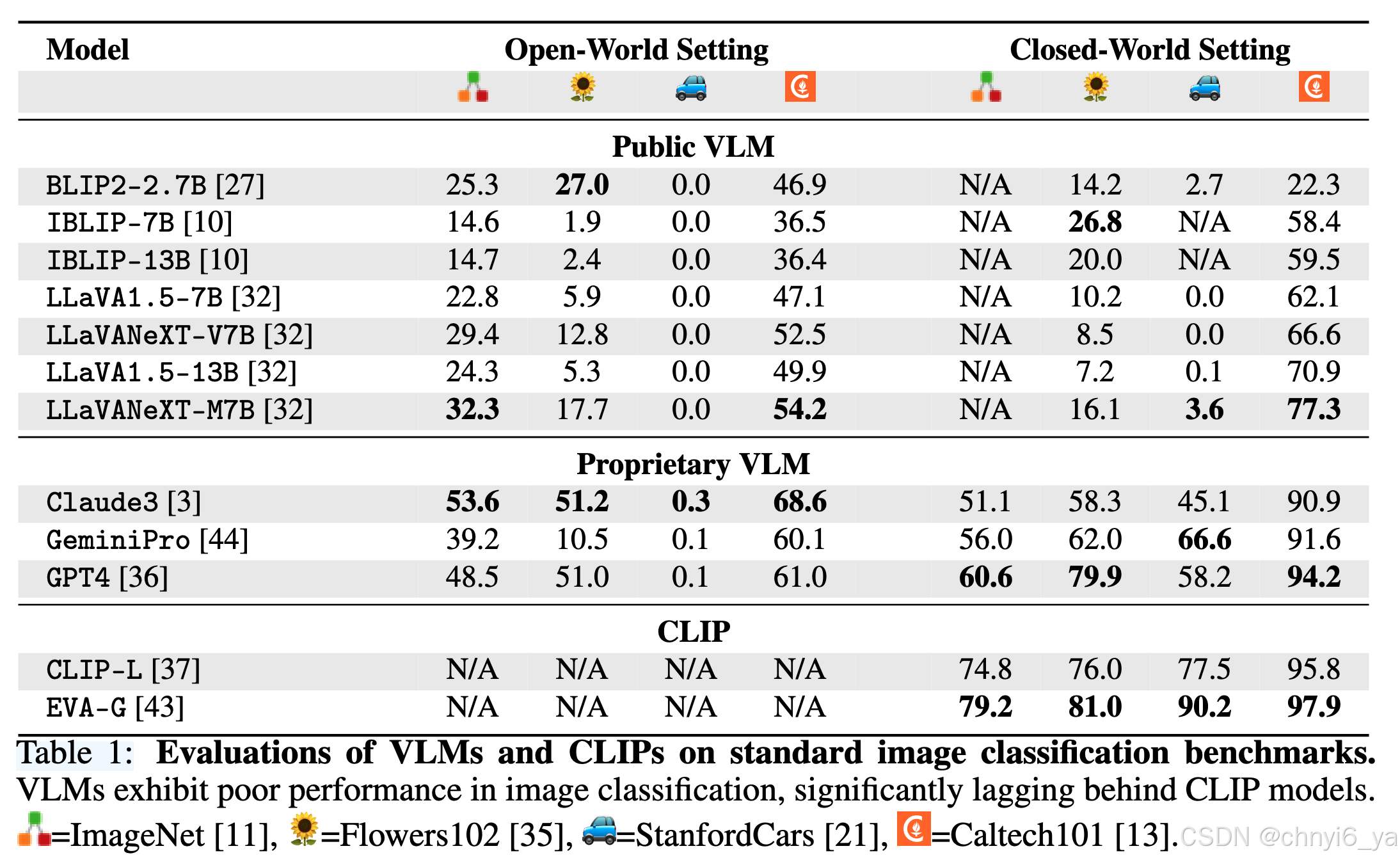
- 作者在四个benchmark上使用10个VLM进行评估,发现VLM在分类中显着落后于CLIP。
- 分析VLM在图片分类任务上表现不好的原因
作者发现:prompt的变化、减少context中的 label set size、让VLM执行概率推断(probabilistic inference),都不是VLM在image classification上和CLIP的gap很大的原因。并且视觉编码器的视觉信息是保存在VLM的latent space中的,文本生成目标函数对于学习分类一样有效。最根本的原因是 训练数据不够
-
作者提出了
ImageWikiQA数据集,是一个以object-centric的知识密集的问题。 -
通过加入classification-focused 数据来训练VLM,不仅提高分类性能,也提高了其泛化能力
在Llava1.5-7b 进行微调,微调数据是Imagenet-1.28M 和原始665K LLAVA 的instruction-tuning数据,能够显著提高Llava1.5-7b在ImageNet上的分类能力,以及在ImageWikiQA的表现。但是如果只用 Imagenet-1.28M 微调的话,反而会降低这两种表现,因此在combined的数据集上微调更好,可以防止灾难性遗忘(catastrophic forgetting)
2. ANALYZING AND BOOSTING THE POWER OF FINEGRAINED VISUAL RECOGNITION FOR MULTI-MODAL LARGE LANGUAGE MODELS
Accepted by ICLR2025
2.1 研究动机
尽管多模态大型语言模型(MLLM)在各种视觉理解任务中表现出了显着的能力。但是,MLLM仍然在细粒度视觉识别(finegrained visual recognition/ FGVR)任务上表现有局限。
2.2 contribution
- 探究MLLM针对FGVR任务的需要具备的三个典型功能:对象信息提取(object information extraction),类别知识储备(category knowledge reserve),对象类别对齐(object-category alignment)
作者发现:IDEFICS2具有很好的对象信息提取的能力(图d),并且对subordinate-level categories有足够的知识(图e),但是对象和类别表示具有巨大的语义差距(图f)。由于类别名称可能无法完全代表视觉数据的语义,因此该对象不能匹配表示空间中的地面真实类别,因此无法将其解码为正确的类别名称。
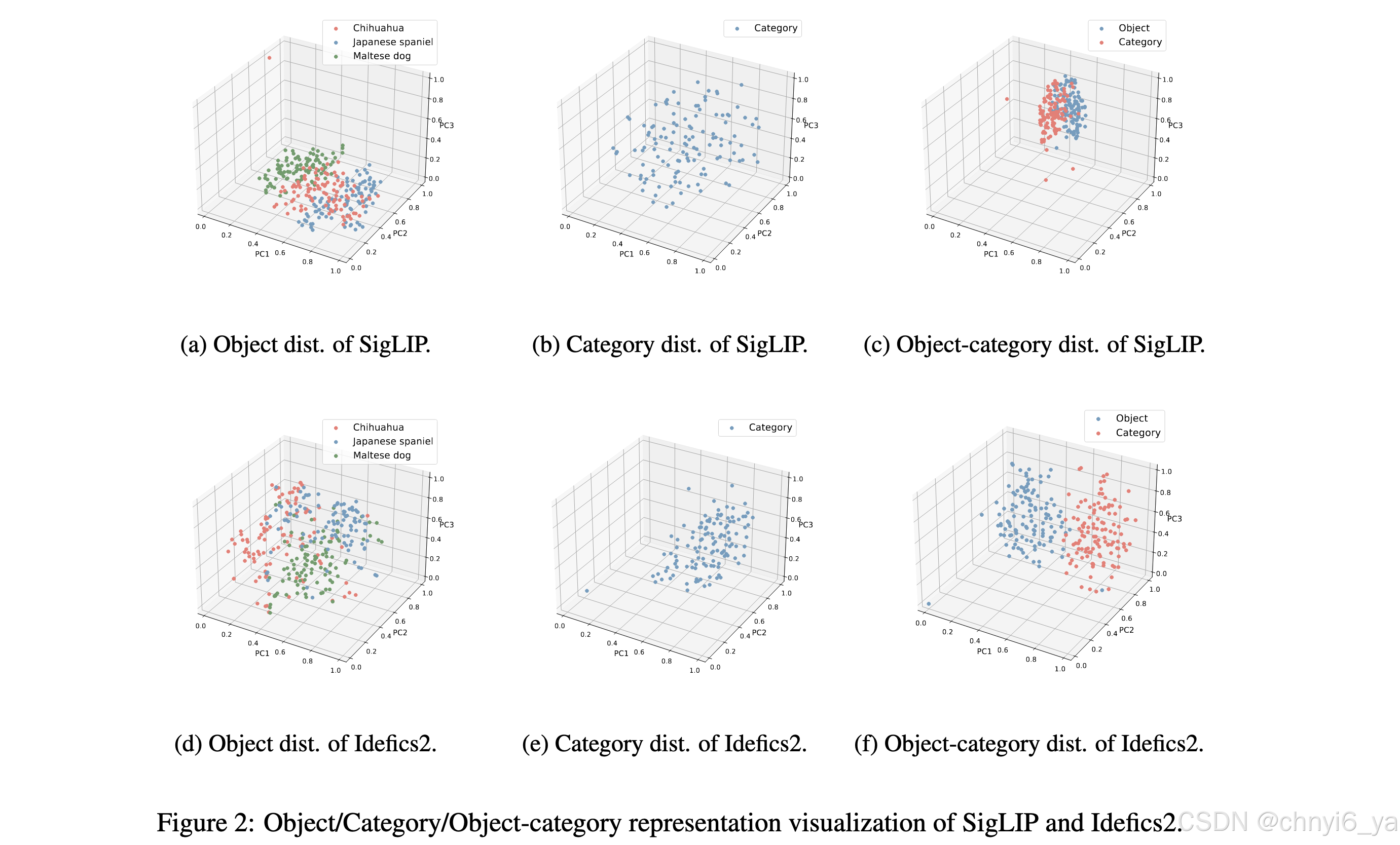
- 提出了
Finedefics多模态大模型(基于idefics2-8b)
有两个重要的组成部分:(1)Attribute Description Construction,用于提取可以区分不同类别的有用属性信息。
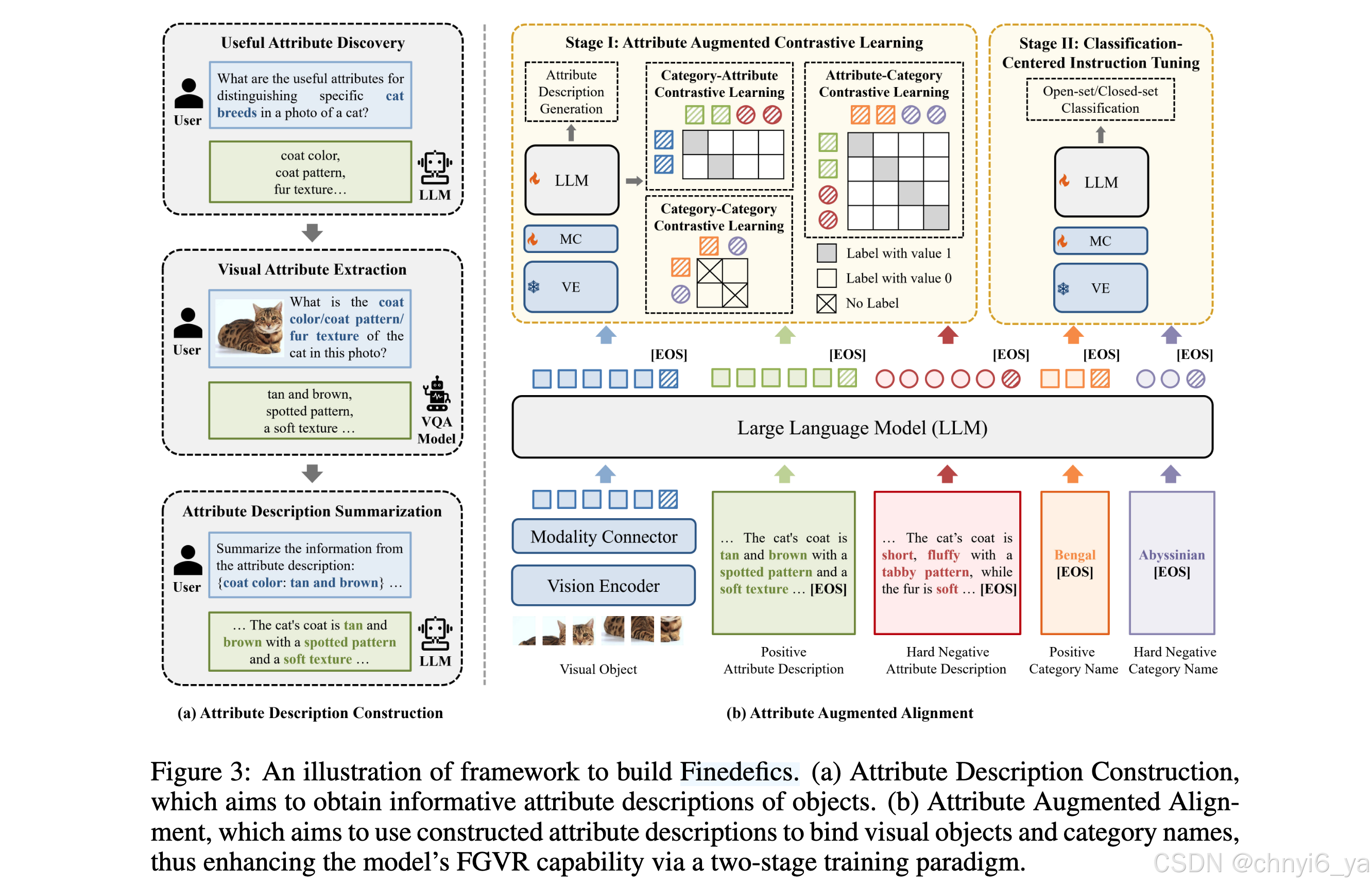
(2)Attribute Augmented Alignment,专用于使用构造的属性描述作为在LLMs表示空间中绑定视觉对象和类别名称的中间点,从而增强了后续分类中心指令调整。
ATTRIBUTE AUGMENTED ALIGNMENT 包含两个阶段:
- Stage I: Attribute Augmented Contrastive Learning.
- Stage II: Classification-Centered Instruction Tuning.
实验结果证明提出的 Finedefics 效果优于其他模型