1.数据库的类型:
数据库分为网状数据库,层次数据库,关系型数据库和非关系型数据库四种。
目前市场上比较主流的是:关系型数据库和非关系型数据库。
关系型数据库使用结构化查询语句(SQL)对关系型数据库进行操作。
2.关系型数据库
数据以二维表的形式进行存储,表和表之间可以建立关联关系(1VS1, 1VSN , NVSN ,通过主外键关系建立的:添加,修改,删除,都是有约束的)
3.mysql
mysql是一种开放源码的,轻量级的关系型数据库。
优点:体积小,成本低,速度快,开放源码等优点。
4.一款操作关系型数据库的语言---SQL(结构化查询语言)
SQL的组成
SQL=DQL+DML+TCL+DCL+DDL
5.DDL(数据的定义语言)+DML(数据的操纵语言)
5.1创建一张表(了解)
create table t_student(
sno int(6) primary key auto_increment,
sname varchar(5) not null,
sex char(1) default '男' check(sex='男' || sex='女'),
age int(3) check(age>=18 and age<=50),
enterdate date,
classname varchar(10),
email varchar(15) unique
);
5.2约束:限制字段的
【以保证数据库中数据的准确性和一致性,这种机制就是完整性约束】
- 主键约束:非空+唯一
- 非空约束:
- 唯一约束:
- 检查约束:
- 默认值约束:
- 自增约束:
- 外键约束:
根据约束的位置,可以分为表级约束和行级约束
行级约束:直接写在字段名的后面
表级约束:脱离建表语句:写在建表语句的最下方
6.DML(数据的操作语言
6.1添加语句
给表里的所有字段赋值,表名后面可以不写字段名
insert into t_student values(null,"张三",default,50,'2023-12-12','定制14班','[email protected]');
insert into t_student
values(null,"李四",'女',22,now(),'dz14b','[email protected]');
now()表示的是当前时间,可以用SYSDATE()来代替,这个是系统时间,代表电脑上的当前时间
建表后,添加外键约束
加一个班级表
create table t_class(
cno int(4) primary key auto_increment,
cname varchar(10) not null,
room char(4)
)
在学生表里加一个cno

然后增加一个外键约束
alter table t_student add constraint fk_student_cno foreign key(cno) references t_class(cno);
delete from t_class where cno=3;
执行上面的句子是不行的,因为班级内还有学生

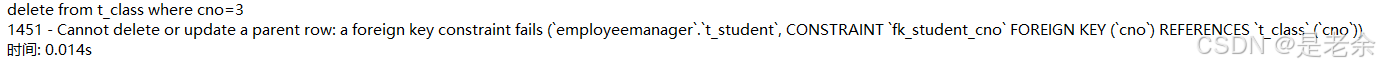
但是一般我们并不会在数据库增添各种约束,一般压力不会给到数据库,而是会把这些操作给到前端或其他部分
6.2删除语句:
delete from 表名 where 主键=值;
6.3修改语句
update 表 set 列名1=新值,列名2=新值,列名3=值 where 主键=值
删除数据操作 :清空数据
delete from t_student;
truncate table t_student;
#delete #truncate #drop
面试题重点:delete、truncate和drop的区别:
drop全部删除掉:表结构+约束+数据 都删掉
delete 只删除数据(一行一行删除数据)--效率低
truncate 删除数据(删除整张表,重新创建表)--效率高
delete属于DML语句;truncate属于DDL语句
delete 继续延续下标;truncate下标从1重新开始
delete 属于DML语句 可以拥有事务,可以回滚
truncate 属于DDL语句 自动提交事务,没办法回滚
7.DQL数据的查询语言:
查询语句的结构:
select 字段名,字段名,字段名,字段名(如果是表里所有的字段,可以换成*)
from 表名1,表名2,表名3,
where 字段=值 and/or &&|| 字段=值
group by 字段名
having 分组后 数据的筛选条件
order by 字段名,字段名
介绍select部分:
- a.给字段设置别名
select empno,ename,job,deptno depno from emp;
给deptno起个别名depno,这样如果类的创建的时候名字没有与数据库的对应,可以通过这种方式避免使用反射时修改类里的属性和方法
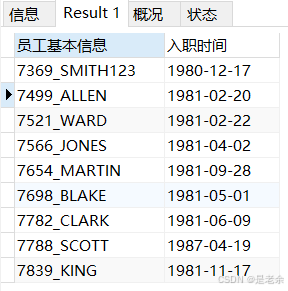
select concat(empno,'_',ename) '员工基本信息',hiredate '入职时间' from emp;
- b.简单的运算:
--显示所有员工的年薪:
select ename,sal*12+ifnull(comm,0) 年薪 from emp;
由于有的员工的奖金comm为null,无法进行算术运算,导致总年薪无法得到,因此使用ifnull函数,如果为空,赋值为0
--去重:
select distinct deptno from emp;
--显示经理的编号
select distinct mgr from emp order by mgr desc; //按经理编号倒序排
介绍where部分
等值查询:
--例子:查询部门编号为30,同时mgr编号为7361或者7788的员工信息
select * from emp where deptno=30 and (mgr=7361 or mgr=7781)
其余写法:
select * from emp where deptno=30 and mgr in (7361,7788)
范围查询:
如果是范围查询则用以下两种方法:
select * from emp where deptno=30 and mgr>=7361 and mgr<=7788
select * from emp where deptno=30 and mgr between 7361 and 7788
查询员工姓名,工资和工资等级
select ename,sal,grade,LOSAL,HISAL
from emp inner join salgrade
on emp.sal>=salgrade.LOSAL and emp.sal<=salgrade.HISAL;
模糊查询:like+% _ --->替换=
%代表0位或者多位
_代表1位
例子:查询员工名字里,或者部门名字里带“发”的所有员工信息
select * from emp inner join dept on emp.deptno=dept.deptno where dname like '%发%' or ename like '%发%';
例子:查询没有奖金的员工信息
select * from emp where comm=0 or comm is null;
空不能用等值,只能用is
不为空的
select * from emp where comm is not null;
介绍from部分:
后面跟表名 别名
介绍sql里的函数:
单行函数:n条数据,得到n个结果
多行函数:多条数据 ,只得到一个结果
count():求总个数
sum():求总和
avg():求平均
max():求最大值
min():求最小值
---求员工的总个数,使用列的别名:工资总和,最大工资,最小工资,平均工资
select count(empno) 员工总个数,sum(sal) 工资总和,max(sal) 最大工资,min(sal) 最小工资,avg(sal) 平均工资 from emp;
---查询1981年最晚入职的员工
select max(hiredate)
from emp
where hiredate between '1981-01-01' and '1981-12-31';
也可以用这种方法:
select *
from emp
where hiredate between '1981-01-01' and '1981-12-31' order by hiredate desc
limit 1;
查询入职时间3个月后的时间
select DATE_ADD(hiredate,INTERVAL 3 MONTH) from emp;
介绍group by分组查询
---显示每个部门最晚的入职时间
select max(hiredate) from emp group by deptno;
---查询每个部门的最晚入职时间,只显示2023以前的(最晚入职时间不可晚于2023-1-1)
select max(hiredate)
from emp
group by deptno
having max(hiredate)<'2023-01-01';
显示各部门的平均工资,按照平均工资倒序排列
select deptno,avg(sal)
from emp
group by deptno
order by avg(sal) desc;
刨除低于2000的员工,统计各部门的平均工资
select deptno,avg(sal)
from emp
where sal>=2000
group by deptno;
刨除低于2000的员工,统计各部门的平均工资,只显示高于3200的平均工资,对显示的数据做正序排列
select deptno,avg(sal)
from emp
where sal>=2000
group by deptno
having avg(sal)>3200;
order by svg(sal)
如果select出现了多行函数,那么剩余的字段必须要出现在group by子句里
介绍多表查询
a.普通多表查询
select e.*,d.dname
from emp e,dept d
where e.deptno=d.deptno and dname='SALES'
b.内连接多表查询
内连接的两张表,没有主次之分,数据根据关联字段进行判断显示
【等上的才显示,没等上的都不显示】
select e.*,d.dname
from emp e
inner join dept d on e.deptno=d.deptno
where dname='sales'
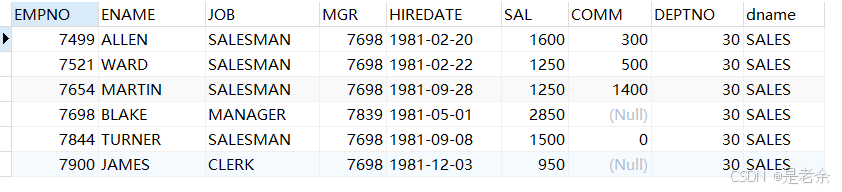
inner join …on
c.外连接多表查询
外连接的两张表,有主次之分,主表里的数据,一定会都显示出来,而次表的数据,只显示值相当的
【等上显示,没等不显示】
外连接分为左外连接和右外连接
在查询语句里,出现的第一个表为左表,第二个表为右表
如果使用左外连接进行查询,左表就是主表,那么左表里的数据就会全部显示出来
右表只显示值相等的数据
select e.*,d.dname
from emp e
left join dept d on e.deptno=d.deptno
where dname='sales'
select e.*,d.dname
from emp e
right join dept d on e.deptno=d.deptno
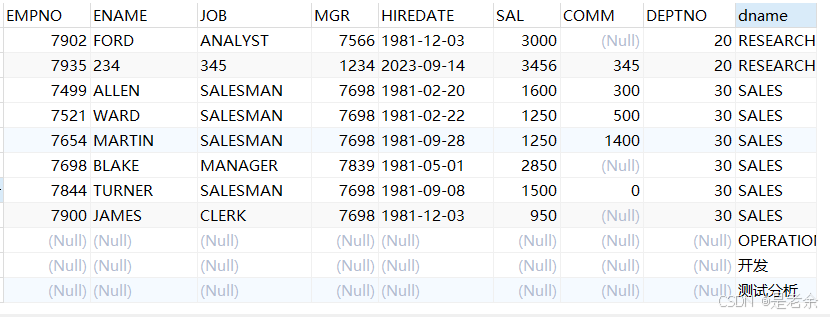
d.关联表中,关联列的名相同:
select e.*,d.dname
from emp e
inner join dept d using (deptno) --on e.deptno=d.deptno
where dname='sales'
e.关联表中,关联列的名相同,类型相同
select e.*,d.dname
from emp e
natural join dept d --inner join dept on e.deptno=d.deptno
where dname='sales' --自然连接
这个是自然连接
扩展:模糊查询
select* from emp where ename like '%M%' and hiredate>='1981-1-03' and hiredate<='1981-12-31'
结果:

子查询:
例子:查询所有员工中,最低工资是多少,同时显示是哪位员工
select ename,min(sal) from emp
查询跟上题那个人是同一个部门的所有员工信息
--不相关子查询
select *
from emp
where deptno=
(select deptno
from emp
where ename='SMITH123'
)
查询和最低工资的人在同一个部门的所有员工信息
select *
from emp
where deptno=(
select deptno
from emp
where sal=(
select min(sal)
from emp
)
)
查询和张发处于同一个工资等级的所有员工的信息
select *
from emp
inner join salgrade s on emp.sal>=s.losal and emp.sal<=s.hisal
where s.grade=(
select grade
from salgrade
inner join emp on emp.sal>=salgrade.losal and emp.sal<=salgrade.hisal
where ename='张发'
)
查询跟SCOTT同一年入职所有员工信息
select *
from emp
where YEAR(hiredate)=(select year(hiredate) from emp where ename='scott')
year(hiredate)表示的是hiredate的年的信息
数据库对象:事务,视图,索引
视图:~表
学习视图的原因?
保证查看者在权限范围内,查看对应的字段。
可以帮忙简化复杂的查询语句
创建一个视图:
create view v_empnoAndSal
as
select empno,sal
from emp;
创建视图连接3个表:
create view v_info
as
select e.*,d.dname,d.loc,s.*
from emp e inner join dept d on e.deptno=d.deptno
inner join salgrade s on e.sal>=s.LOSAL and e.sal<=s.HISAL
事务:
-
使用场合:事务应用在 业务层,在业务层做功能的整合
京东下单---控制层调用业务层的付款方法---17个各个dao层里的方法。 -
作用:让多个DML语句作为一个整体,这些DML语句要么同时成功,要么同时失败
-
事务的特征:【重要!要背!】ACID
一致性、隔离性、持久性、原子性 -
事务的并发问题:
(1)读了别人事务中没提交的数据叫脏读(Dirty read)【不可接受】
(2)读到了别人事务提交后的数据(修改操作)
不可重复读【可以接受】
(3)读到了别的事务提交后的数据(添加/删除操作),幻读【可以接受】==>针对以上三种事务的并发问题,mysql