基于多维度数据的A股大盘预测模型 。呕心沥血编程。中国宏观杠杆率+居民消费价格指数+美股股票指数数据+A 股新闻情绪指数+美联储利率决议+上证指数历史数据进行未来3天A股大盘预测。运行指标最佳 ARIMA 模型阶数、MAE、RMSE、R²。程序运行正确,截图如下,代码附后。不做投资依据,仅作学术娱乐
创作不易严禁盗图使用。

import pandas as pd
import akshare as ak
from datetime import datetime, timedelta
from statsmodels.tsa.arima.model import ARIMA
import warnings
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib.ticker import FuncFormatter
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
from statsmodels.graphics.gofplots import qqplot
from statsmodels.graphics.tsaplots import plot_acf
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings("ignore")
index_us_stock_sina_df = ak.index_us_stock_sina(symbol=".INX")
index_us_stock_sina_df['date'] = pd.to_datetime(index_us_stock_sina_df['date'])
index_us_stock_sina_df.set_index('date', inplace=True)
index_us_stock_sina_df = index_us_stock_sina_df.sort_index()
index_news_sentiment_scope_df = ak.index_news_sentiment_scope()
index_news_sentiment_scope_df['日期'] = pd.to_datetime(index_news_sentiment_scope_df['日期'])
index_news_sentiment_scope_df.set_index('日期', inplace=True)
macro_bank_usa_interest_rate_df = ak.macro_bank_usa_interest_rate()
macro_bank_usa_interest_rate_df['日期'] = pd.to_datetime(macro_bank_usa_interest_rate_df['日期'])
macro_bank_usa_interest_rate_df.set_index('日期', inplace=True)
df_index = ak.stock_zh_index_daily(symbol="sh000001")
df_index['date'] = pd.to_datetime(df_index['date'])
df_index.set_index('date', inplace=True)
df_index = df_index.sort_index()
macro_cnbs_df = ak.macro_cnbs()
macro_cnbs_df['年份'] = pd.to_datetime(macro_cnbs_df['年份'])
macro_cnbs_df.set_index('年份', inplace=True)
macro_cnbs_df = macro_cnbs_df.sort_index()
macro_china_cpi_df = ak.macro_china_cpi()
macro_china_cpi_df['月份'] = pd.to_datetime(macro_china_cpi_df['月份'].str.replace('年', '-').str.replace('月份', ''))
macro_china_cpi_df.set_index('月份', inplace=True)
macro_china_cpi_df = macro_china_cpi_df.sort_index()
start_date = '2024-01-01'
df_index = df_index[df_index.index >= start_date]
index_news_sentiment_scope_df = index_news_sentiment_scope_df[index_news_sentiment_scope_df.index >= start_date]
macro_bank_usa_interest_rate_df = macro_bank_usa_interest_rate_df[macro_bank_usa_interest_rate_df.index >= start_date]
index_us_stock_sina_df = index_us_stock_sina_df[index_us_stock_sina_df.index >= start_date]
macro_cnbs_df = macro_cnbs_df[macro_cnbs_df.index >= start_date]
macro_china_cpi_df = macro_china_cpi_df[macro_china_cpi_df.index >= start_date]
df_combined = pd.merge_asof(df_index, index_news_sentiment_scope_df, left_index=True, right_index=True)
print("合并后数据的列名:", df_combined.columns)
df_combined = df_combined[['close', '市场情绪指数', '今值', 'us_index_close', '实体经济部门', '全国-当月']]
df_combined.rename(columns={
'close': 'A股收盘值',
'今值': '美联储利率决议值',
'us_index_close': '美股标准普尔500指数收盘价'
}, inplace=True)
df_combined.fillna(method='ffill', inplace=True)
if len(df_combined) < 10:
print("数据点数量过少,请检查数据或调整筛选条件。")
else:
best_mae = float('inf')
in_sample_forecast)
if mae < best_mae:
best_mae = mae
best_model = model_fit
best_order = (p, d, q)
except:
continue
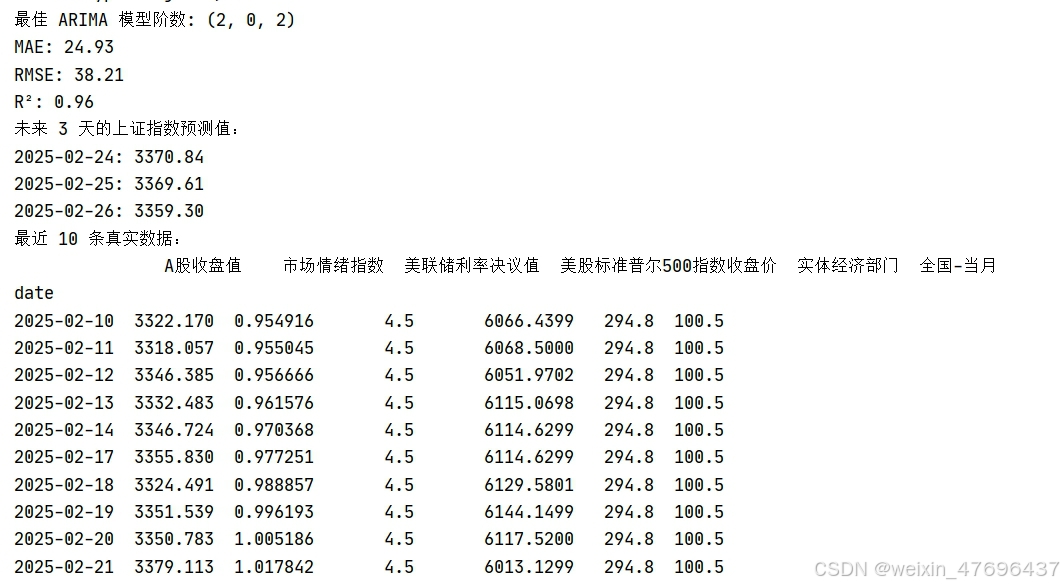
print(f"最佳 ARIMA 模型阶数: {best_order}")
in_sample_forecast = best_model.predict(start=df_index.index[0], end=df_index.index[-1])
if in_sample_forecast[0] == 0:
non_zero_index = (in_sample_forecast != 0).argmax()
if non_zero_index > 0:
in_sample_forecast[0] = in_sample_forecast[non_zero_index]
errors = df_combined['A股收盘值'] - in_sample_forecast
mae = mean_absolute_error(df_combined['A股收盘值'], in_sample_forecast)
rmse = np.sqrt(mean_squared_error(df_combined['A股收盘值'], in_sample_forecast))
r2 = r2_score(df_combined['A股收盘值'], in_sample_forecast)
print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"R²: {r2:.2f}")
confidence_interval = 1.96 * np.std(errors)
upper_bound = in_sample_forecast + confidence_interval
lower_bound = in_sample_forecast - confidence_interval