一、redis简介
简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。
二、为什么要用 redis/为什么要用缓存?
主要从“高性能”和“高并发”这两点来看待这个问题。
高性能:
假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。如果该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存是直接操作内存,所以速度相对硬盘要快很多。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
redis适合少写多读,符合缓存的适用要求。
官方数据表示Redis读的速度是十几万次/s,写的速度是八万次左右/s 。单机redis支撑万级,如果十万以上建议用redis replication模式,也就是集群模式;
三、redis 常见数据结构(5种)
String(字符串)、Hash(哈希)、List(列表)、Set(集合)、zset(有序集合)
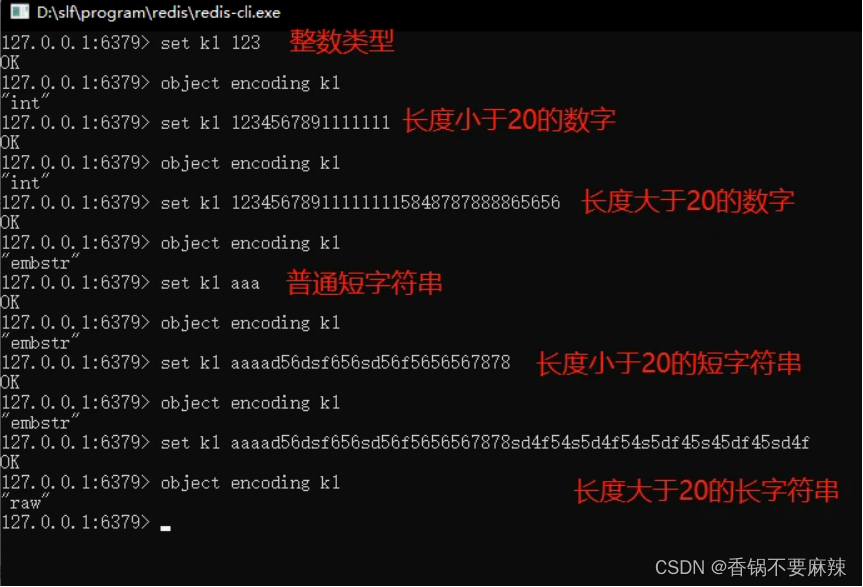
String(字符串)
Redis的String类型,其实底层是由三种数据结构组成的:
1)int: 整数且小于二十位整数以下的数字数据才会使用这个类型
2)embstr (embedded string,表示嵌入式的String):代表embstr格式的SDS(Simple Dynamic String 简单动态字符串),保存长度小于44字节的字符串。
3)raw :保存长度大于44的字符串
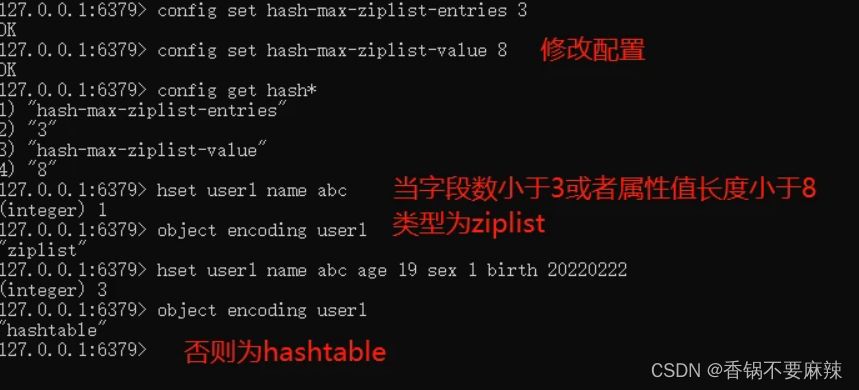
Hash(哈希)
hash-max-ziplist-entries:使用压缩列表保存哈希集合中的最大元素个数。
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度。
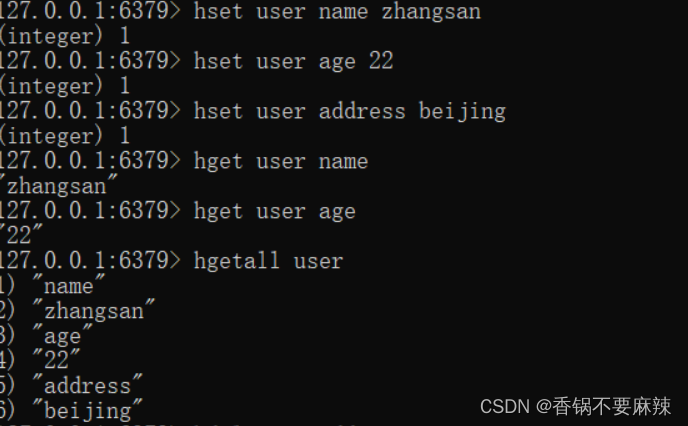
- 添加/修改数据
hset key field value
- 获取数据
hget key field
hgetall key
- 删除数据
hdel key field1 [field2]
- 添加/修改多个数据
hmset key field1 value1 field2 calue2
- 获取多个数据
hmget key field1 field2 …
- 获取哈希表中字段的数量
hlen key
-
获取哈希表中是否存在指定的字段
-
设置指定字段的数值数据增加指定范围的值
hincrby key field increment //指定数值增长指定的数
hincrbyfloat key field increment
- 获取哈希表中所有的字段名和字段值
hkeys key //字段名
hvals key //字段值
hexists key field
- 创建数据,如果有则不再创建,如果没有则创建
hsetnx key field value
Hash数据类型也和String有相似之处,到达了一定的阈值之后就会对数据结构进行升级。
数据结构:
1)hashtable 就是和java当中使用的hashtable一样,是一个数组+链表的结构。
2)ziplist 压缩链表
ziplist是一种比较紧凑的编码格式,设计思路是用时间换取空间,因此ziplist适用于字段个数少,且字段值也较小的场景。压缩列表内存利用率高的原因与其连续性内存特性是分不开的。
当一个hash对象,只包含少量的键,且每个键值对的值都是小数据,那么ziplist就适合做为底层实现。
ziplist的结构:
它是一个经过特殊编码的双向链表,它虽然是双向链表,但它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点的长度和当前节点的长度,通过牺牲部分读写性能,来换取高空间利用率。
为什么有链表了,redis还要整出一个压缩链表?
1)普通的双向链表会有两个前后指针,在存储数据很小的情况下,我们存储的实际数据大小可能还没有指针占用的内存大。而ziplist是一个特殊的双向链表,并没有维护前后指针这两个字段,而是存储上一个entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获取高效的空间利用率,因为(简短KV键值对)存储指针比存储entry长度更费内存,这是典型的时间换空间。
2)链表是不连续的,遍历比较慢,而ziplist却可以解决这个问题,ziplist将一些必要的偏移量信息都记录在了每一个节点里,使之能跳到上一个节点或者尾节点节点。
3)头节点里有头结点同时还有一个参数len,和SDS类型类似,这就是用来记录链表长度的。因此获取链表长度时不再遍历整个链表,直接拿到len值就可以了,获取长度的时间复杂度是O(1)。
遍历过程:
通过指向表尾节点的位置指针zltail,减去节点的previous_entry_length,得到前一个节点的起始地址的指针。如此循环,从表尾节点遍历到表头节点。
List(列表)
数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
需要的存储数据:一个存储空间保存多个数据,且通过数据可以体现进入顺序
list类型:保存多个数据,底层使用双向链表存储结构实现
- 添加/修改数据
lpush key value1 [value2] …
rpush key value1 [value2] …
- 获取数据
lrange key start stop //获取从左数第start到stop个元素,从0开始
lindex key index //查询第i个元素
llen key //list的长度
获取并移除数据
lpop key //获取并删除左边第一个元素
rpop key //获取并删除右边第一个元素
- list 类型数组扩展操作
规定时间内获取并移除数据
blpop key1 [key2] timeout
brpop key1 [key2] timeout
- 移除指定数据
lrem key count value //count为移除的数量,value为移除哪个值
ziplist压缩配置 :list-compress-depth 0
表示一个quicklist两端不被压缩的节点个数,这里的quicklist(下文会解释)是指quickList双向链表的节点,而不是指ziplist里面的数据项个数。
quicklist结构介绍:
list用quicklist来存储,quicklist存储了一个双向链表,每一个节点都是一个ziplist。
Set(集合)
- 新的存储需求:存储大量的数据,在查询方面提供更高的效率
- 需要的存储结构:能够保存大量的数据,搞笑的内部存储机制,便于查询
- set类型:与hash存储结构完全相同,仅存储键,不存储值(nil),并且值式不允许重复的。也就是只有键没有值的hash
添加数据
sadd key menber1 [member2]
获取全部数据
smembers key
删除数据
srem key member1 [member2]
获取集合数据总量
scard key
判断集合中是否包含指定数据
sismember key member
- 随机获取集合中指定数量的数据
srandmember key [count]
- 随机获取集合中的某个数据并将该数据移出集合
spop key
- 求两个集合的交、并、差集
sinter key1 [key2] //交集
sunion key1 [key2] //并集
sdiff key1 [key2] //差集(key1有但是key2没有的)
- 求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sdiffstore destination key1 [key2]
- 将指定数据从原始集合移动到目标集合中
smove source destination member
set的单个元素的添加流程。
如果set已经是hashtable的编码,那么走hashtable的添加流程。
如果原来是intset:
1)能转化为int对象,就用intset保存。
2)如果长度超过设置,就用hashtable保存
3)其它情况统一用hashtable保存。
zset(有序集合)
-
新的存储需求:根据排序有利于数据的有效显示,需要提供一种可以根据自身特征进行排序的方式。
-
需要的存储结构:新的存储模型,可以保存可排序的数据。
-
sorted_set类型:在set的存储结构基础上添加可排序字段。
-
添加数据
zadd key score1 member1 [score2 member2]
- 获取全部数据
zrange key start stop [WITHSCORES]//按照从小到大的顺序,加上WITHSCORES,就会带上scores一起显示
zrevrange key start stop [WITHSCORES]//按照从大到小的顺序
- 删除数据
zrem key member [member …]
- 按条件获取数据
//查询scores在某个范围内的值
zrangebyscore key min max [WITHSCORES] [LIMIT]
//查询key某个索引范围内的值
zrevrangebyscore key max min [WITHSCORES]
- 获取集合数据总量
zcard key //获取总量
zcount key min max //获取某一个范围的总量
- 集合交、并存储操作
zinterstore destination numkeys key [key …] //求和
zunionstore destination numkeys key [key …]
- 获取数据对应的索引(排名)
zrank key member //正数第几位
zrevrank key member //倒数第几位
- score 值获取与修改
zscore key member //获取
zincrby key increment member //score递增 increment
当有序集合中包含的元素数量超过服务器属性 zset_max_ziplist_entries 的值(默认值为 128 ),
或者有序集合中新添加元素的 member 的长度大于服务器属性zset_max_ziplist_value 的值(默认值为 64 )时,redis会使用跳跃表作为有序集合的底层实现。
skiplist(跳表)是什么:
跳表是一种以空间换取时间的结构。
由于链表是无法进行二分查找的,因此借鉴了数据库索引的思想,提取出链表中关键节点(索引),现在关键节点上进行查找,再进入链表进行查找。
提取了很多关键节点,就形成了跳表。
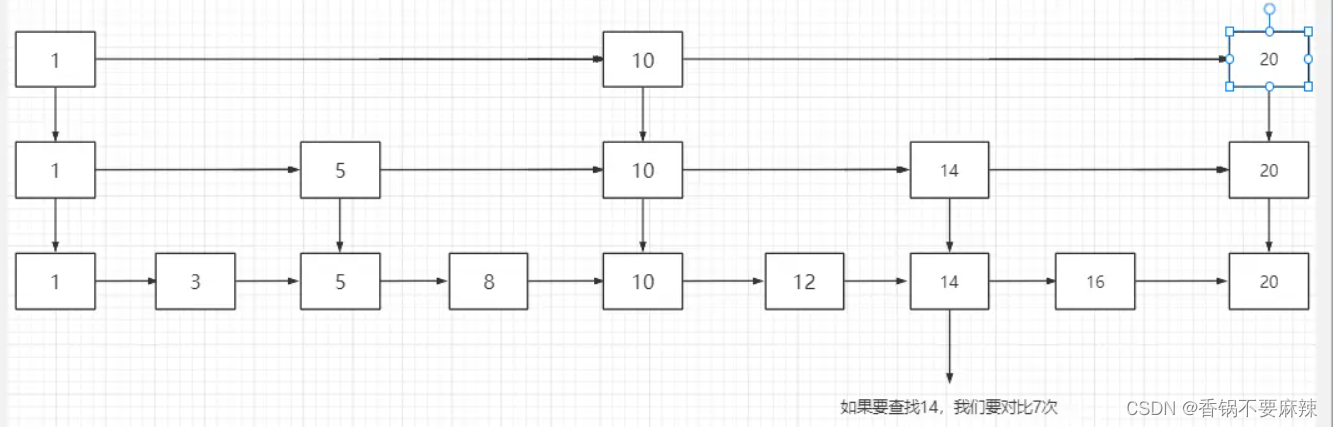
因为跳表是以一种跳跃式的数据存在,当我们查询‘14’这个数据的时候,可以跳过很多无用的数据,减少遍历的次数。
跳表是一个典型的空间换时间的解决方案,而且只有在**数据量较大的情况下才能体现出来优势。还是要读多写少的情况才适合使用,所以它的适用范围还是比较有限的,**新增或者删除的时候要把所有数据都更新一遍。
多路复用器工作原理
select
select多路复用器是采用轮询方式,一直在轮询所有的相关内核进程,查看他们的进程状态。若已经就绪,则马上将该内核进程放入到就绪队列。否则,继续查看下一个内核进程状态。在处理内核进程事务之前,app进程首先会从内核空间中将用户连接请求相关数据复制到用户空间。
缺陷:
1.对所有内核进程采用轮询方式效率会很低。因为对于大多数情况下,内核进程都不属于就绪状态,只有少部分才会是就绪态。所以这种轮询结果大多数是毫无意义的。
2.由于就绪队列底层由数组实现,所以其所能处理的内核进程数量是由限制的,即其能够处理的最大并发连接数是有限制的。
3.从内核空间到用户空间的复制,系统开销大。
poll
poll工作原理与select几乎相同,不同的是由于其就绪队列由链表实现,所以其对于要处理的内核进程数量理论上是没有限制的,即其能够处理的最大并发连接数是没有限制的(要受制于当前系统中进程可以打开的最大文件描述符数ulimit)。
epoll
epoll采用回调方式实现对内核进程状态的获取,一旦内核进程就绪,其就会回调epoll多路复用器,进入到多路复用器的就绪队列(由链表实现),所以epoll多路复用模型也称为epoll事件驱动模型。
应用程序所使用的数据不再从内核空间复制到用户空间了,而是使用mmap零拷贝机制,大大降低了系统开销。
当内核进程就绪信息通知了epoll多路复用器后,多路复用器就会马上对其进行处理,将其马上存放到就绪队列了吗?不是的,根据处理方式的不同,可以分为两种处理模式:LT模式与ET模式。
LT模式
LT,Level Triggered,水平触发模式。只要内核进程的就绪通知由于某种原因暂时没有被epoll处理,则该内核进程就会定时将其就绪信息通知epoll,直到epoll将其写入到就绪队列,或由于某种原因该内核进程又不再就绪而不再通知,其支持两种通讯方式:BIO与NIO。
ET模式
ET,Edge Triggered,边缘触发模式,仅支持NIO通讯方式。
内核进程的就绪信息仅会通知一次epoll,无论epoll是否处理该通知。明显该方式的效率要高于LT模式,但其有可能会出现就绪通知被忽视的情况,即连接请求丢失的情况。
Redis持久化分类
redis的持久化分为两类:RDB持久化、AOF持久化。但在使用时会有三种使用方式:RDB持久化方式、AOF持久化方式和RDB&AOF混合持久化方式。
RDB持久化方式
RDB持久化的逻辑
RDB持久化即可以手动执行也可以根据服务器配置选项定期的执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中,这个文件其实是一个二进制的文件,通过这个文件可以还原到生成RDB文件时的数据库状态。
RDB文件的创建
有两个生成redis的RDB文件的命令,一个是SAVE,一个是BGSAVE。SAVE命令是使用服务器进程来生成RDB文件,在生成RDB文件的时候,会阻塞所有的读写操作,服务器不能处理任何命令请求。BGSAVE命令是通过服务器进程派生出来一个子进程,然后由子进程负责创建RBD文件,服务器进程可以继续处理命令请求。
其实创建RDB文件的工作都是通过rdbsave函数实现的,只不过上面两种命令以不同的方式调用这个函数。
- SAVE命令执行时的服务器状态
我们上面已经提到过SAVE命令会阻塞一切请求,当然也包括BGSAVE请求,所以在执行SAVE期间,再次执行BGSAVE命令会被直接拒绝。
- BGSAVE命令执行时的服务器状态
我们知道BGSAVE命令是服务器的子进程来完成的,服务器进程可以继续接收和执行命令,但是在BGSAVE命令执行期间服务器处理SAVE、BGSAVE、BGREWRITEAOF三个命令的方式和平时有所不同,主要有以下几种情形:
1.在BGSAVE命令执行期间,客户端发起的SAVE命令会被服务器拒绝。服务器禁止SAVE命令和BGDAVE命令同时执行是为了避免父进程和子进程同时执行两个rdbsave调用,防止产生竞争条件。
2.在BGSAVE命令执行期间客户端发起BGSAVE命令会被服务器拒绝,因为同时执行两个BGSAVE命令也会产生竞争条件
3.在BGSAVE命令执行期间,客户端发起BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行
4.在BGREWRITEAOF命令执行期间,客户端发起BGSAVE命令会被服务器直接拒绝,主要是因为BGREWRITEAOF和BGSAVE命令都是由子进程来完成的,禁止它们同时执行只是一个性能方面的考虑,因为并发两个子进程,并且这两个子进程同时进行大量的磁盘写入操作,并不是什么好事情。
RDB文件的载入
对于RDB文件的载入就相对简单了,RDB文件的载入工作是在服务器启动的时候自动执行的,并且在服务器载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
RDB自动间歇性保存
上面我们讲了如何创建RDB文件,但是如何间歇性创建RBD文件呢?
有两种方式创建RDB文件:一是手动的执行命令,二是通过配置让服务器自动来创建RDB文件。我们可以在redis的配置文件中通过以下配置来实现:
save 900 1
save 300 10
save 60 10000
默认保存
是1分钟内改了1万次,
或5分钟内改了10次,
或15分钟内改了1次。
用户可以通过save选项设置多个保存条件(可以超过三个了,十个八个都可以,因为这些保存条件其实是保存在一个数组中的),但是只要其实任意一个条件满足,服务器就会执行BGSAVE命令。而上面的三条保存配置其实也是在我们开启了RDB持久化但是没有配置相关保存条件下时服务器给的默认的配置。
用户可以通过save选项设置多个保存条件(可以超过三个了,十个八个都可以,因为这些保存条件其实是保存在一个数组中的),但是只要其实任意一个条件满足,服务器就会执行BGSAVE命令。而上面的三条保存配置其实也是在我们开启了RDB持久化但是没有配置相关保存条件下时服务器给的默认的配置。
如何自动触发生成RDB文件的配置条件的呢?
其实服务器除了通过一个数组存储我们的保存条件外,还会维持一个dirty的计数器,以及一个lastsave属性,其中dirty计数器用来统计距离上一次成功执行SAVE命令或者BGSAVE命令后服务器对数据库状态进行了多少次修改(包括写入,删除,更新等操作),而lastsave属性是一个UNIX的时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间。这两个值都会在成功执行完BGSAVE命令后重置:dirty重置成0,lastsave更新为当前时间。
而对于条件的判断则是Redis服务器会周期性的操作函数serverCron默认每隔100毫秒执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否满足,如果满足则执行BGSAVE命令。必须同时满足如下条件:
距离上一次成功执行保存的时间超过设置的时间
数据库状态的修改次数超过设置的修改次数
RDB的文件结构
暂略
AOF持久化方式
AOF持久化的逻辑
与RBD持久化通过保存数据库中的键值对来记录数据库状态不同,AOF持久化是通过保存redis服务器所执行的写命令来记录数据库状态的。
被写入到AOF文件的命令都是以Redis的命令请求协议格式保存的,因为Redis的命令请求协议是纯文本的,所以我们可以直接打开一个AOF文件,观察里面的内容,里面保存的基本都是我们执行的命令,但是会有一些SELECT命令,SELECT命令是用于指定数据库的,此命令是服务器自动添加的。
AOF持久化的过程
AOF持久化过程的实现可以分为命令追加、文件写入、文件同步三个步骤。
-
命令追加:当AOF功能打开的时候,服务器执行一条命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾,但是aof_buf缓冲区的命令什么时候写入aof文件要根据我们的appendfsync的相关配置来决定
-
文件写入和同步:为了提高文件的写入效率,在现代的操作系统中,当用户调用write函数,将一些数据写入到文件时,操作系统通常会将写入数据暂时存放到一个内存缓冲区里面,此时并没有真正的把数据持久化到磁盘上,需要等等到缓冲区满了或者超过了执行的时限之后,才调用fsync函数真正的将缓冲区中的数据写入到磁盘里。这样做虽然提高了效率,但也为写入数据都带来了安全问题,因为如果计算机发生停机,那么保存在操作系统内存缓冲区里的数据将会丢失。简单的理解,写入操作其实只是将数据写入到了操作系统的内存缓冲区;而同步操作才真正的将数据写入到磁盘文件中,同步操作(fsync函数的调用)的执行频率可以通过配置控制,下面会详细讲到。
我们需要注意的是,Redis的服务器进程就是一个事件循环,这个循环中的文件事件负责接收客户端的命令请求,以及向客户端发送命令回复,而时间事件则负责执行像serverCron函数这样的需要定时运行的函数。
因为服务器在处理文件事件时可能会执行写命令,使得一些内容被追加到aof_buf缓冲区里面,所以在服务器每次结束一个事件循环之前,都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里面。flushAppendOnlyFile函数的行为是由服务器配置文件的appendfsync选项的值来决定的,appendfsync的值有三种:
- always
服务器在每个事件循环都要将aof_buf缓冲区中的所有数据写入到AOF文件,并且同步AOF文件,所以效率是appendfsync三个选项中最低的,但从安全性来说,这种设置是最安全的,即便机器出现故障,也只是会丢失一个事件循环中所产生的命令数据
- everysec
将aof_buf缓冲区的所有内容写入到AOF文件(此时并没有同步达到磁盘上),如果上次同步AOF文件的时间距离现在超过1s,那么再次对AOF文件进行同步,并且这个同步操作有一个线程专门完成。这种设置,服务器在每个事件循环中都要将aof_buf缓冲区中的所有内容写入到Aof文件,并且每隔1s就要在子线程中对AOF文件进行一次同步。从效率上来讲everysec模式足够快,并且就算出现故障停机,数据库也只丢失一秒钟的命令数据。
no
在服务器的每个事件循环中都要将aof缓冲区中的所有内容写入到AOF文件,但不对AOF文件进行同步,何时同步由操作系统来决定,所以这种设置是如果服务器停机,将会丢掉上次AOF文件同步后的所有写命令数据。
AOF文件的载入和数据还原
因为AOF文件中包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍AOF文件里面保存的写命令,就可以还原服务器关闭之前的数据状态。
AOF重写
为什么要进行AOF重写能?
因为AOF持久化是通过保存被执行的写命令来记录数据库状态的,所以随着时间的流逝,AOF文件内容会越来越多,文件体积也会越来越大,如果不加以控制的话,体积过大的AOF文件很可能对Redis服务器甚至宿主机造成影响,并且AOF文件的体积越大,在使用AOF文件来进行数据还原所需的时间就越长。对于数据恢复来说,AOF文件中会有很多冗余的命令,比如对某个key操作了八次,AOF文件中会记录八条写命令,但其实我们只关心最后一次命令执行后的数据状态,为了解决AOF文件体积膨胀问题,Redis提供了AOF文件重写功能。
什么是AOF重写?
将生成新的AOF文件替换旧的AOF文件的功能叫做AOF文件重写,但是实际上AOF文件重写并没有对旧的AOF文件进行任何读取、分析或者写入的操作,只是对AOF重写时候的数据状态转成写命令保存起来,也就是说重写后的AOF文件中保存着能够还原重写时数据库状态所必须的命令,这样就可以大大的减小文件的体积了。
AOF重写的触发方式
- 通过配置自动触发
要想使用自动触发方式进行AOF重写,需要进行类似如下:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
假如做了如上配置,其释义如下。
当AOF文件大于64MB时,并且AOF文件当前大小比基准大小增长了100%时会触发一次AOF重写。那么基准大小如何确定呢?
起始的基准大小为Redis重启并加载完AOF文件之后,aof-buf的大小。当执行完一次AOF重写之后,基准大小相应更新为重写之后AOF文件的大小。
假如做了如上配置,其释义如下。
当AOF文件大于64MB时,并且AOF文件当前大小比基准大小增长了100%时会触发一次AOF重写。那么基准大小如何确定呢?
起始的基准大小为Redis重启并加载完AOF文件之后,aof-buf的大小。当执行完一次AOF重写之后,基准大小相应更新为重写之后AOF文件的大小。
- 手动执行bgrewriteaof命令显示触发。
通过客户端输入bgrewriteaof命令,该命令调用bgrewriteaofCommand,然后创建管道,fork进程,子进程调用rewriteAppendOnlyFile执行AOF重写操作,父进程记录一些统计指标后继续进入主循环处理客户端请求。当子进程执行完毕后,父进程调用回调函数做一些后续的处理操作。
我们知道RDB保存的是一个时间点的快照,但是AOF故障时最少可以只丢失一条命令。子进程执行重写时可能会有成千上万条命令继续在父进程中执行,那么如何保证重写完成后的文件也包括这些命令呢?
首先需要在父进程中将重写过程中执行的命令进行保存,其次需要将这些命令在重写后的文件中进行回放。Redis为了尽量减少主进程的阻塞时间,通过管道按批次将父进程累积的命令发送给子进程,由子进程重写完成后进行回放。因此子进程退出后只会有少量的命令还累积在父进程中,父进程只需回放这些命令即可。
AOF重写的过程
在了解AOF重写过程之前,我们先了解一个概念:AOF重写缓冲区(aof_rewrite_buf_blocks),这是一个list类型的缓冲区,每个节点中保存一个aofrwblock类型的数据,该结构体中会保存10MB大小的缓冲区内容,并且有缓冲区使用和空闲长度的记录。当一个节点缓冲区写满之后,会开辟一个新的节点继续保存执行过的命令。
因为Reids是单线程的,为了不使AOF重写时阻塞服务器的正常运行,redis决定将AOF重写放到一个子进程中进行,这样做有两个好处:
-
子进程进行AOF重写期间,服务器进程(父进程)可以继续处理命令请求
-
子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据得安全性
我们要注意,在子进程进行AOF重写期间,父进程还需要继续处理命令请求,Redis用AOF重写缓冲区来保存AOF重写期间执行的命令,由上可知,在子进程AOF重写期间,服务器进程会进行三个工作:
- 执行客户端发来得命令
- 将执行后的写命令追加得AOF缓冲区
- 将执行后得写命令追加得AOF重写缓冲区
这样做的好处是可以保证:
- AOF缓冲区的内容会定期被写入和同步到AOF文件,对现在AOF文件的处理工作会如常进行
- 从创建子进程开始,服务器执行的所有写命令都会被记录到AOF重写缓冲区里面
当子进程完成AOF重写后,会向服务器进程发一个信号,并调用一个信号处理函数执行以下工作:
- 将AOF重写缓冲区中的所有内容写入到新得AOF文件中,这时新AOF文件所保存得数据库状态将和服务器当前得数据库状态保持一致
- 对新的AOF文件进行改名,原子的覆盖现在的AOF文件,完成新旧文件的交替
在整个AOF后台重写过程中,只有信号处理的时候会对服务器进程(父进程)造成阻塞,其他时候AOF后台重写都不会阻塞父进程,这将AOF重写对服务器造成的影响降到了最低。
需要注意的是:在重写程序中处理列表、哈希表、集合、有序集合这四种可能会带有多个元素的键时,会先检查包含元素的数量,如果数量超过了设置的常量值(这个值不同版本是不一样的),就会用多条命令来记录这个键,而不单单使用一条命令。
AOF&RDB混合持久化方式
混合持久化指进行AOF重写时子进程将当前时间点的数据快照保存为RDB文件格式,而后将父进程累积命令保存为AOF格式。
加载时,首先会识别AOF文件是否以REDIS字符串开头,如果是,就按RDB格式加载,加载完RDB后继续按AOF格式加载剩余部分。
开启混合持久化的配置:
aof-user-rdb-preamble yes
RDB持久化和AOF持久化的对比
RDB优劣势
优势
RDB只代表某个时间点上的数据快照,所以适用于备份与全量复制,如一天进行备份一次。
Redis在加载RDB文件恢复数据远快于AOF文件
性能上考虑RDB优于AOF,因为我们保存RDB文件只需fork一次子进程进行保存操作,父进程没有对磁盘I/O
劣势
RDB没办法做到实时的持久化数据,因为fork是重量级别的操作,频繁执行成本过高。
RDB需要经常fork子进程来保存数据集到磁盘,当数据集比较大的时候,fork的过程是比较耗时的,可能会导致redis在一些毫秒级不能响应客服端请求。
老版本的Redis无法兼容新版本的RDB文件。
AOF优劣势
优势
通过配置同步策略基本能够达到实时持久化数据,如配置为everysec,则每秒同步一次AOF文件,也就是说最多丢失一秒钟的数据,兼顾了性能与数据的安全性
AOF文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek ,即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
劣势
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
与AOF相比,在恢复大的数据的时候,RDB方式更快一些。
进行保存操作,父进程没有对磁盘I/O
劣势
RDB没办法做到实时的持久化数据,因为fork是重量级别的操作,频繁执行成本过高。
RDB需要经常fork子进程来保存数据集到磁盘,当数据集比较大的时候,fork的过程是比较耗时的,可能会导致redis在一些毫秒级不能响应客服端请求。
老版本的Redis无法兼容新版本的RDB文件。
AOF优劣势
优势
通过配置同步策略基本能够达到实时持久化数据,如配置为everysec,则每秒同步一次AOF文件,也就是说最多丢失一秒钟的数据,兼顾了性能与数据的安全性
AOF文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek ,即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
劣势
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
与AOF相比,在恢复大的数据的时候,RDB方式更快一些。
Java【spring】使用注解 加缓存、清缓存、缓存相关 的使用
缓存注解有以下三个:
@Cacheable @CacheEvict @CachePut
@Cacheable
// 示例
@Cacheable(cacheNames = "getCategoryInfoCoupon", key = "#tenantId + ':' + #categoryId + ':' + #page.current")
public IPage<CouponProdsDto> getCategoryInfoCoupon(Page<CouponProdsDto> page, Long categoryId, String tenantId, String userId) {}
@Cacheable可以标记在一个类上,也可以标记在一个方法上。标记在一个类上,则表明该类的所有方法都是支持缓存的。Spring在缓存方法的返回值都是以键值对进行缓存的,值就是方法的返回结果,至于key的话,Spring支持两种策略,默认策略和自定义策略。
注意:当一个支持缓存的方法在对象内部被调用是不会触发缓存功能的。
@Cacheable可以指定三个属性,value、key和condition
@CacheEvict
@CacheEvict清除指定下所有缓存
// 示例
@CacheEvict(cacheNames = "parts:grid",allEntries = true)
此注解会清除part:grid下所有缓存,用法和@Cacheable等一样,清除指定key的缓存
@CacheEvict要求指定一个或多个缓存,使之都受影响。此外,还提供了一个额外的参数allEntries 。表示是否需要清除缓存中的所有元素。默认为false,表示不需要。
当指定了allEntries为true时,Spring Cache将忽略指定的key。有的时候我们需要Cache一下清除所有的元素。
allEntries属性: 是否清空所有缓存内容
beforeInvocation属性: 是否在方法执行前就清空
@CachePut
// 示例
@CachePut(value="accountCache",key="#account.getName()")// 更新accountCache 缓存
public Account updateAccount(Account account) {
return updateDB(account);
}
@CachePut标注的方法在执行前不会去检查缓存中是否存在之前执行过的结果,而是每次都会执行该方法,并将执行结果以键值对的形式存入指定的缓存中。
以key作为键,返回值作为值,进行缓存。