文章目录
一、进程地址空间
1.1 前言
在学习 C/C++ 的时候,我们知道内存会分为几个区域:栈区、堆区、全局/静态区、代码区、字符常量区 …
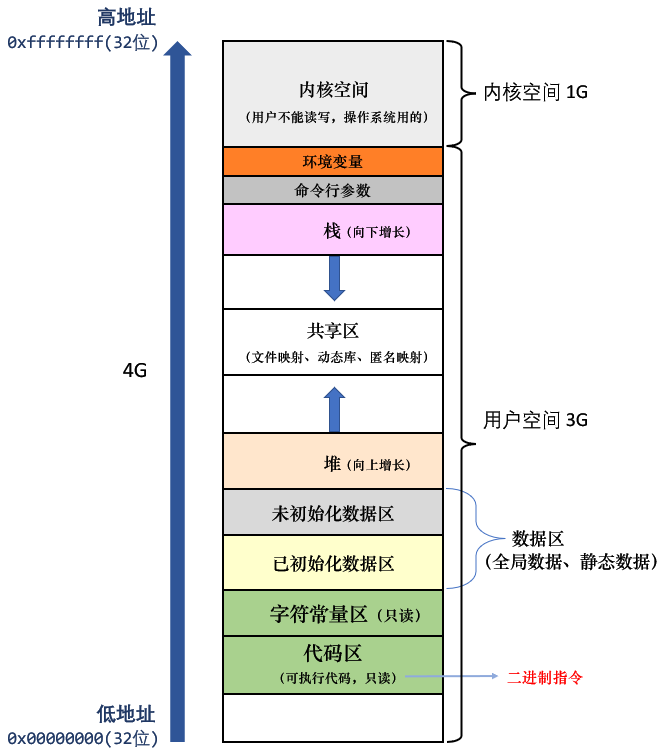
这只是语言层面的理解,是远远不够的,如下空间布局图,请问这是物理内存吗?—— 不是,是进程地址空间。
两点结论:
-
进程地址空间不是物理内存!
-
进程地址空间,会在进程的整个生命周期内一直存在,直到进程退出!
这也就解释了为什么全局/静态变量的生命周期是整个程序,因为全局/静态变量是随着进程一直存在的。
为了更好的学习进程地址空间,还需要理解如下四个问题:
- 验证地址空间的基本排布?
- 进程地址空间究竟是什么?
- 地址空间和物理内存之间的关系?
- 为什么要存在地址空间?
1.2 验证地址空间的基本排布(⭐)
代码如下:
/* checkarea.c */
#include<stdio.h>
#include<stdlib.h> // malloc
int g_unval; // 未初始化数据区
int g_val = 10; // 已初始化数据区
int main(int argc, char* argv[], char* env[])
{
printf("code addr : %p\n", main); // 代码区
printf("\n");
const char *p = "hello";
printf("read only : %p\n", p); // 字符常量区(只读)
printf("\n");
printf("global val : %p\n", &g_val); // 已初始化数据区
printf("global uninit val: %p\n", &g_unval); // 未初始化数据区
printf("\n");
char *phead = (char*)malloc(1);
printf("head addr : %p\n", phead); // 堆区(向上增长)
printf("\n");
printf("stack addr : %p\n", &p); // 栈区(向下增长)
printf("stack addr : %p\n", &phead); // 栈区
printf("\n");
printf("arguments addr : %p\n", argv[0]); // 命令行参数(第一个参数)
printf("arguments addr : %p\n", argv[argc - 1]); // 命令行参数(最后一个参数)
printf("\n");
printf("environ addr : %p\n", env[0]); // 环境变量
return 0;
}
运行结果:
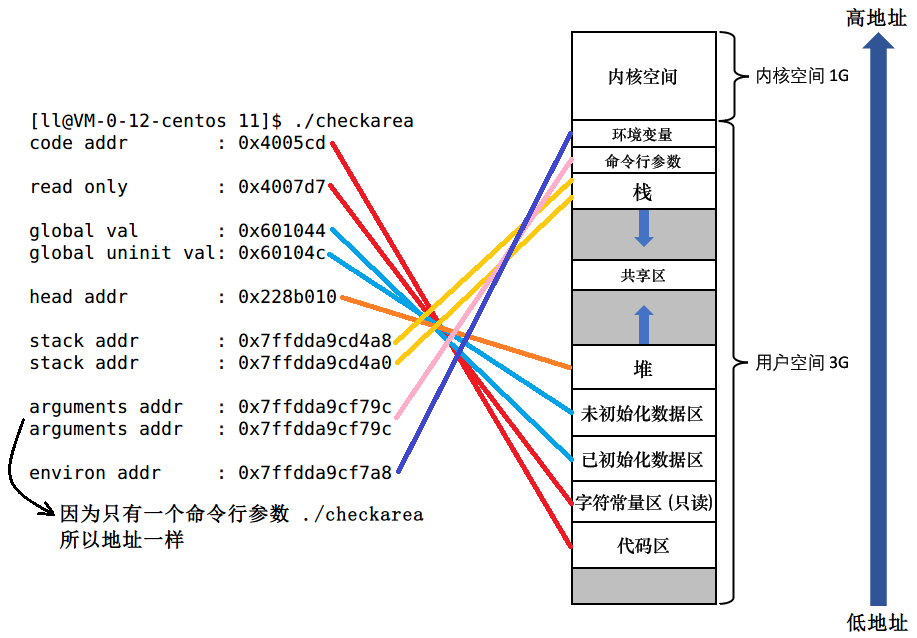
1.3 虚拟地址 & 物理地址
举例说明:
观察如下代码的运行结果:定义一个全局变量,然后创建子进程,父子进程分别打印出变量值和变量地址。
#include<stdio.h>
#include<sys/types.h> // getpid
#include<unistd.h> // getpid, fork
#include<stdlib.h> // perror
int g_val = 0; // 全局变量
int main()
{
printf("before creating a new process, g_val = %d\n", g_val);
pid_t ret = fork();
if (ret == 0) {
// child process
printf(" child - pid: %u, g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);
}
else if (ret > 0) {
// father process
printf("father - pid: %u, g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);
}
else {
perror("fork");
}
return 0;
}
运行结果:
before creating a new process, g_val = 0
father - pid: 23014, g_val: 0, &g_val: 0x601058
child - pid: 23015, g_val: 0, &g_val: 0x601058
观察发现,父子进程打印的变量值和变量地址都是一样的,因为创建子进程通常以父进程为模版,父子进程并没有对变量进行进行任何修改。如果将代码稍加改动:
#include<stdio.h>
#include<sys/types.h> // getpid
#include<unistd.h> // getpid, fork, sleep
#include<stdlib.h> // perror
int g_val = 0; // 全局变量
int main()
{
printf("before creating a new process, g_val = %d\n", g_val);
pid_t ret = fork();
if (ret == 0) {
// child process
g_val = 100; // 在子进程中对变量进行修改
printf(" child - pid: %u, g_val: %-3d, &g_val: %p\n", getpid(), g_val, &g_val);
}
else if (ret > 0) {
// father process
sleep(3); // 父进程休眠,子进程一定会先退出,让父进程读取变量值和变量地址
printf("father - pid: %u, g_val: %-3d, &g_val: %p\n", getpid(), g_val, &g_val);
}
else {
perror("fork");
}
return 0;
}
运行结果:
before creating a new process, g_val = 0
child - pid: 25270, g_val: 100, &g_val: 0x601058 # 子进程先退出
father - pid: 25269, g_val: 0 , &g_val: 0x601058 # 父进程休眠3s后退出
观察发现,父子进程,打印的变量值是不一样的,但是变量地址竟然是一样的!
我们知道,父子进程代码共享,数据各自私有一份(写时拷贝)。
思考1:运行结果中,变量值不一样,说明父子进程中的变量绝对不是同一个变量。
思考2:运行结果中,打印的变量地址,绝对不可能是物理地址,因为同一物理地址处,不可能读取出来两个不一样的值。
所以,可以得出如下结论:
- 我们曾经在 C/C++ 语言等其它语言中学到和看到的地址(比如取地址),全部都是「虚拟地址」,由操作系统统一管理。而物理地址,用户是一概看不到的。
- 注意:程序的代码和数据一定是存在物理内存上的!因为想要运行程序必须先将代码和数据加载到物理内存中。所以一定需要操作系统负责将「虚拟地址」转化成「物理地址」。
画图分析:
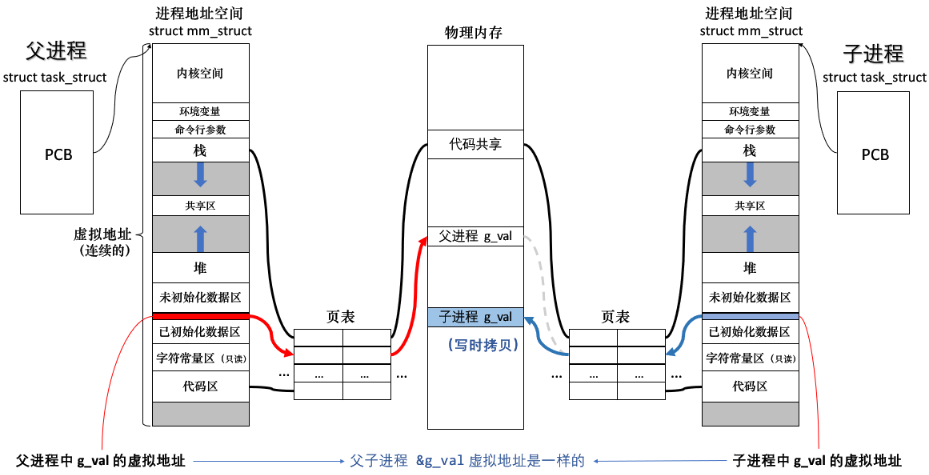
上图说明,同一个变量,打印的地址相同,其实是「虚拟地址」相同,内容不同其实是被映射到了不同的「物理地址」处。
👉 现在再来思考:进程和程序有什么区别呢?
1.4 通过一个小例子来理解地址空间
举个例子:
假设有一个富豪,他有 10 亿美元的家产,而这个富豪他有 10 个私生子,但这 10 个私生子彼此之间并不知道对方的存在,这个富豪对他的每个私生子都说过同一句话:儿子,这10亿的家产未来都是你的。
站在每个私生子的视角中,每个私生子都认为自己拥有 10 亿美元。
如果每个私生子都找父亲一次性要 10 个亿,这个富豪是拿不出来的,但实际上这是不可能的,每个私生子找父亲要钱,一般只会几千几万这样一点点去要,这个富豪只要有,就一定会给。如果私生子要的钱太多,富豪不给,私生子也只会认为是父亲不想给我。
换言之,这个富豪给每个私生子在大脑中建立一个「虚拟」的概念:都认为自己拥有 10 亿美元。
类比到计算机中:
富豪,称之为操作系统。
私生子,称之为进程。
富豪给私生子画的 10 亿家产,称之为进程的地址空间。
通过上述两个例子,得出结论:
-
操作系统默认会给每个进程构建一个地址空间的概念(比如32位下,把物理内存资源抽象成了从 0x00000000 ~ 0xFFFFFFFF 共 4G 的一个「线性的虚拟地址空间」)
假设系统中有 10 个进程,每个进程都会认为自己有 4G 的物理内存资源。(可以理解成 OS 在画大饼)
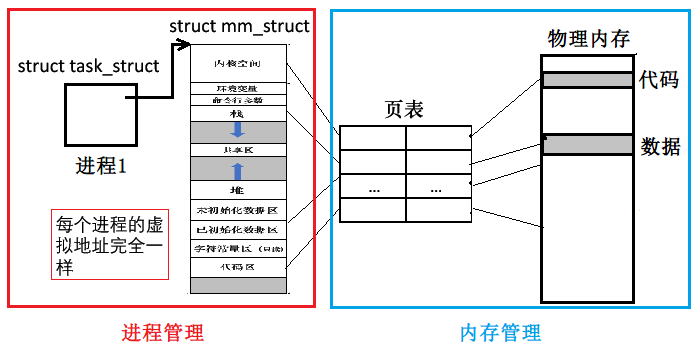
认识地址空间(⭐)
-
在 Linux 中,「地址空间其实是内核中的一种数据结构」。
-
在 Linux 中,OS 除了会为每个进程创建对应的 PCB(即
struct task_struct结构体),还会创建对应的进程地址空间,即内核中的struct mm_struct结构体。思考:
空间的本质无非就是多个区域(栈、堆 …)的集合。那么在
struct mm_struct结构体中,OS 是如何表述(划分)这些区域的呢?回答:
定义 start 和 end 变量来表示每个区域,起始和结束的虚拟地址。然后通过设置这些 start 和 end 的值,对抽象出的这个「线性的虚拟地址空间」(32位下,是从 0x00000000 ~ 0xFFFFFFFF 共 4G)进行区域划分。
struct mm_struct { // ... unsigned long code_start; // 代码区起始虚拟地址,比如 0x10000000h unsigned long code_end; // 代码区结束虚拟地址,比如 0x00001111h unsigned long init_start; // 已初始化数据区 unsigned long init_end; unsigned long uninit_start; // 未初始化数据区 unsigned long uninit_end; unsigned long heap_start; // 堆区 unsigned long heap_end; // ... };
1.5 地址空间究竟是什么(总结)(⭐)
进程地址空间:
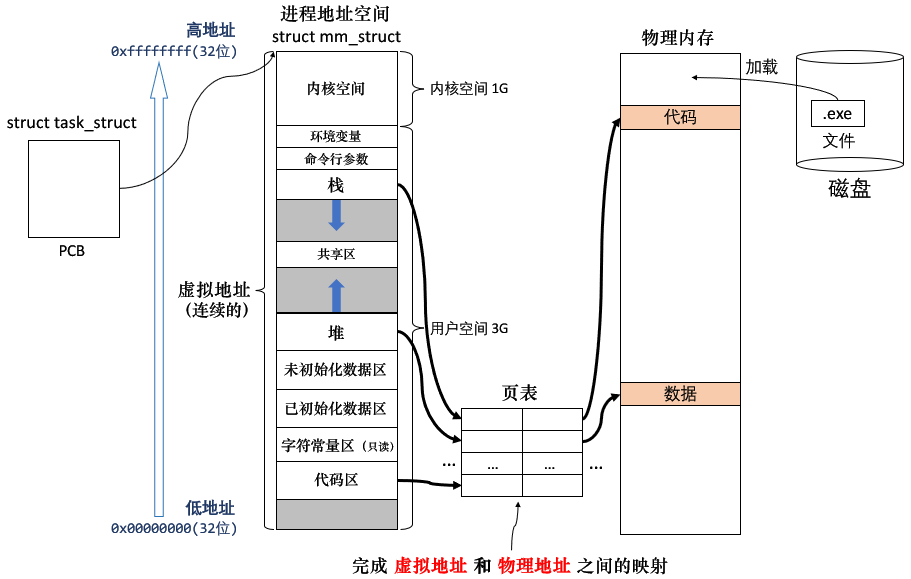
总结:地址空间究竟是什么?
-
地址空间的本质:操作系统让「进程看待物理内存的方式」,这是抽象出来的一个概念。地址空间是内核中的一种数据结构,即
struct mm_struct结构体。由 OS 给每个进程创建,这样每个进程都认为自己独占系统内存资源。 -
划分区域的本质:把「线性的地址空间」划分成了一个个的区域,通过设置结构体内的 start 和 end 的值,来表示区域的起始和结束。(比如栈区和堆区的增长)
为什么要进行区域划分呢?
- 可以通过 [start, end] 进行初步判断访问某个虚拟地址时,是否越界访问了。
- 因为可执行程序,在磁盘中是被划分成一个个的区域存储起来的,所以进程的地址空间才有了区域划分这样的概念,方便进程找到代码和数据。
-
虚拟地址的本质:每个区域 [start, end] 之间的各个地址就是虚拟地址,之间的虚拟地址是连续的。
1.6 地址空间 & 物理内存之间的关系
虚拟地址和物理地址之间是通过页表来完成映射的。
1.7 总结:为什么要存在地址空间(⭐)
思考:直接让进程去访问物理内存不就好了吗?为什么还要存在地址空间呢?
早期,操作系统是没有进程地址空间的,导致物理内存暴露,恶意程序可以直接通过物理地址,进行内存数据的读取,甚至篡改。
后来随着操作系统的发展迭代,有了进程地址空间(虚拟地址),由操作系统完成虚拟地址和物理地址之间的转化。
存在地址空间的理由:
-
保护物理内存,在进程内不能直接访问物理内存,也方便操作系统进行合法性检测。
-
通过划分区域中虚拟地址的起始和结束(即 start 和 end 的值),来判断当前访问的地址是否合法。
比如:如果用户想在某个虚拟地址处写入,但检测到该虚拟地址在字符常量区的 start 到 end 之间,而字符常量区是只读的,说明越界访问了,OS 直接终止进程。
char *str = "hello world"; *str = 'H'; // error -
还通过页表中的权限属性,来判断当前访问的地址是否合法。
页表完成了虚拟地址到物理地址之间的映射,而页表中除了有基本的映射关系之外,还可以进行读写等权限相关的管理。
比如:如果用户想在某个虚拟地址处写入,通过页表进行虚拟地址到物理地址的转换时,发现该地址处只有读权限,说明非法访问了,页表拒绝转换,OS 直接终止进程。
-
-
将「内存管理模块」和「进程管理模块」进行解耦。
操作系统的核心功能:内存管理、进程管理、文件管理、驱动管理。
-
没有进程地址空间时,内存管理必须得知道所有的进程的生命状态(创建、退出等),才能为每个进程分配和释放相关内存资源。所以「内存管理模块」和「进程管理模块」是强耦合的。
-
而现在有了进程地址空间,内存管理只需要知道哪些内存区域(page)是被页表映射的(已使用),哪些是没有被页表映射的(未使用),不需要知道每个进程的生命状态。当进程管理想要申请内存资源时,让内存管理通过页表建立映射即可;想要释放内存资源时,通过页表取消映射即可。所以将「内存管理模块」和「进程管理模块」进行解耦了。
【思考 & 拓展】:如果物理内存只有 4G,有一个游戏 16G,能运行吗?
- 可以的,CPU 运行不管多大的程序,都需要从头到尾一行一行指令的去执行,即使物理内存有 32G,也不会一次性把 16G 的程序加载进来(因为内存资源还需要分配给其它进程),而是采用延时加载,比如先加载 200M 进来,执行完了,再覆盖式的加载 200M 进来,然后执行。所以如果物理内存比较小,用户可能会感到游戏卡一卡的。
-
-
让每个进程,以同样的方式,来看待代码和数据。(这样对于进程的设计是非常好的)
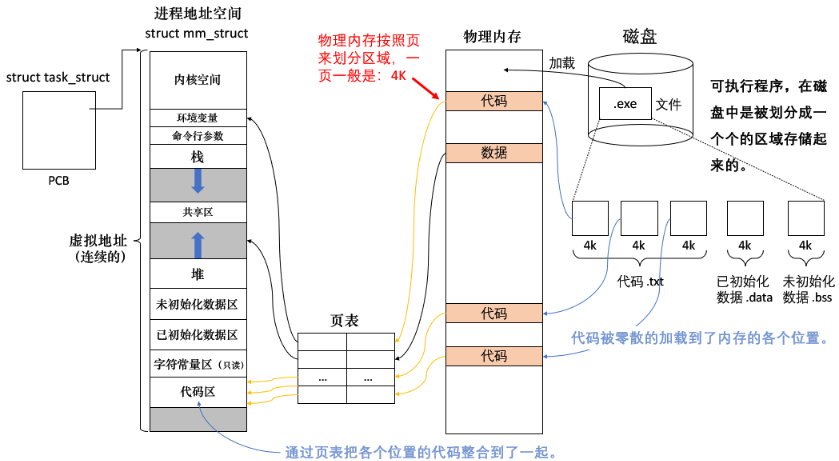
可执行程序,在磁盘中是被划分成一个个的区域存储起来的(比如代码 .txt、已初始化数据 .data、未初始化数据 .bss 等等)。
-
因为可执行程序形成时,有一个链接的过程,会把用户代码和库的代码合并在一起,把用户数据和库的数据合并在一起。否则可执行程序的代码和数据如果是混着存放在一起的,会导致链接过程变得很复杂。
-
所以进程的地址空间才有了区域划分这样的概念,方便进程找到代码和数据。
拓展 & 分析:
如图:代码被零散的加载到了内存的各个位置。如果直接让进程去找到代码是非常困难的,尤其是找到代码的起始和结束位置。所以我们在进程的地址空间中划分出一个个的区域,再通过页表把内存中各个位置的代码给整合到一起,使代码的物理地址变成「线性的虚拟地址」了。然后进程通过其对应地址空间中的代码区(区域中虚拟地址是连续的),可以很方便的找到代码。同时 CPU 也方便执行代码(虚拟地址是连续的,这样 PC 指针才能进行加 1 操作,得到下一条指今的地址,CPU 才能从上到下顺序执行指令)。好处:
-
不用在物理内存中找一块连续的区域了。
-
站在进程的角度,所有进程的代码(二进制指令)存放的区域,虚拟地址是连续的,可以被顺序执行。(即使物理内存上有可能不连续)
-