概述
在现代信息检索领域,检索增强生成(Retrieval-Augmented Generation, RAG)模型结合了信息检索与生成式人工智能的优点,从而在特定场景下提供更为精准和相关的答案。在特定场景下,例如法律等领域,用户通常需要精确且相关的信息来支持决策。传统生成模型虽然在自然语言理解和生成方面表现良好,但在专业知识的准确性上可能有所不足。RAG模型通过将检索与生成相结合,能有效提升回答的准确性和上下文相关性。本方案以人工智能平台PAI为基础产品,为您介绍面向法律场景的大模型RAG检索增强解决方案。
1. 使用PAI-Designer构建知识库
您可以参照数据格式要求准备,使用PAI-Designer构建相应的检索知识库。
2. 使用PAI-LangStudio进行模版构建
您在LangStudio中使用预置的RAG模版进行定制化,创建适合具体应用的模板。
3. 使用PAI-Langstudio构建在线应用
LangStudio提供了用户友好的界面,使用户能够轻松提交查询并获取答案。您可以使用创建好的模板构建符合业务需求的在线应用。
一、前置准备
在开始执行操作前,请确认您已完成以下准备工作:
-
已开通PAI后付费,并创建默认工作空间,详情请参见开通PAI并创建默认工作空间。
-
已创建OSS存储空间(Bucket),用于存储训练数据。关于如何创建存储空间,详情请参见控制台创建存储空间。
-
已开通Milvus数据库,用于构建知识库的向量存储,详情请参见快速创建milvus实例
准备数据集
在使用PAI-Designer构建知识库的过程中,您首先需要根据法律领域的需求,准备并整理好适合的数据集。这些数据往往涉及到该领域的专业内容,需确保数据的准确性和完整性。PAI-Designer提供了一套便捷的工具和接口,帮助用户轻松导入和管理这些数据。在本解决方案中,我们以法律为例,展示使用PDF作为原始数据,使用PAI-Designer构建知识库的的步骤。
您需要确保数据格式符合PAI-Designer的要求,例如PDF格式。可以通过对领域文档进行预处理和格式化,提取其中的关键信息。
数据示例
以下给出法律领域的数据的示例,格式为pdf,主要内容为国家法律法规数据库中的法律条文,用户可以根据需要准备自己的数据:


该示例数据集已经放置于公开的oss bucket中,可以使用wget下载,下载后请用户将数据上传到自己的oss bucket中,以供下一步使用:
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/solutions/rag/data/%E6%B3%95%E5%BE%8B%E6%96%B0%E9%97%BBpdf.zip
部署LLM和Embedding模型
1. 前往快速开始 > ModelGallery,分别按场景选择大语言模型及Embedding分类,并部署指定的模型。本文以通义千问2.5-7B-Instruct和bge-large-zh-v1.5 通用向量模型为例进行部署。请务必选择使用指令微调的大语言模型(名称中包含“Chat”或是“Instruct”的模型),Base模型无法正确遵循用户指令回答问题。
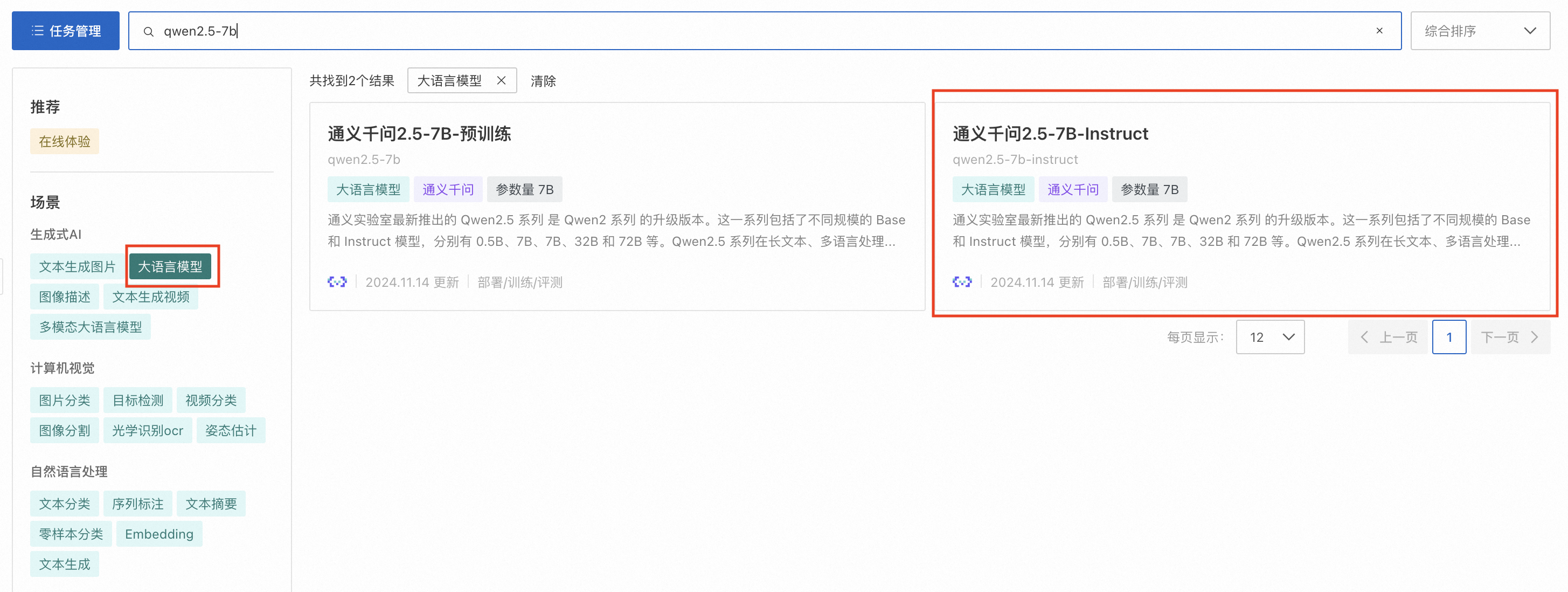
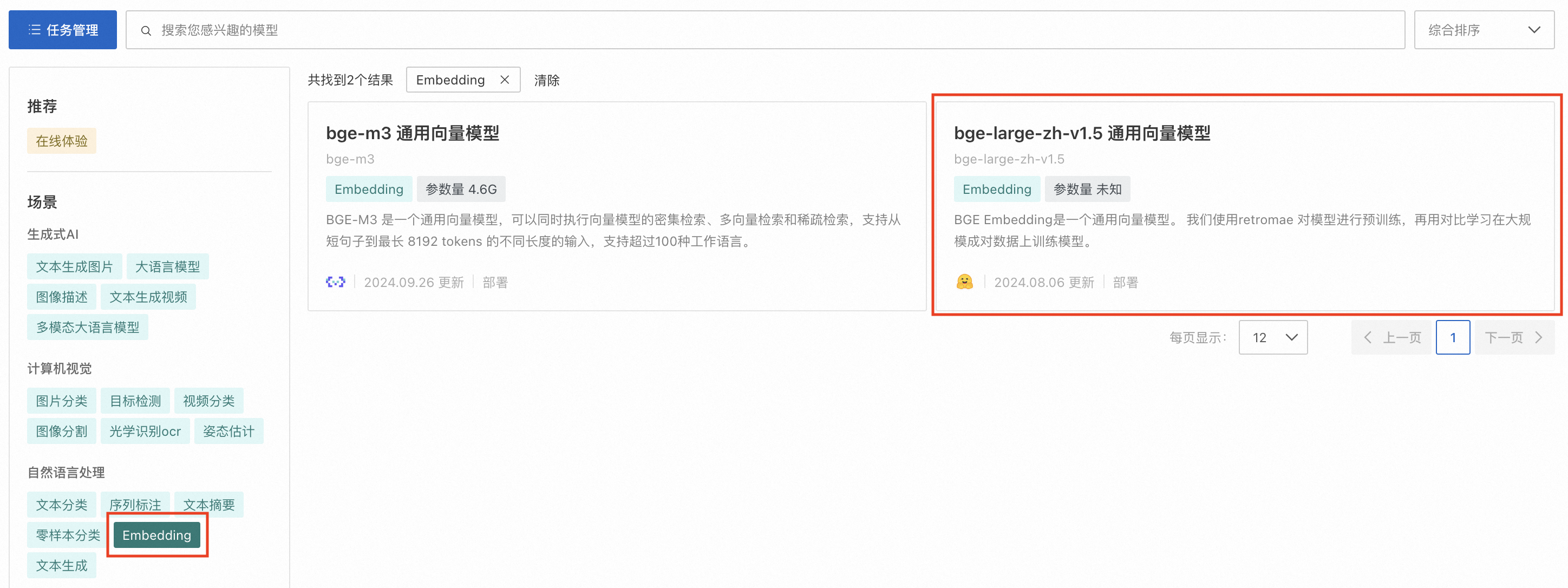
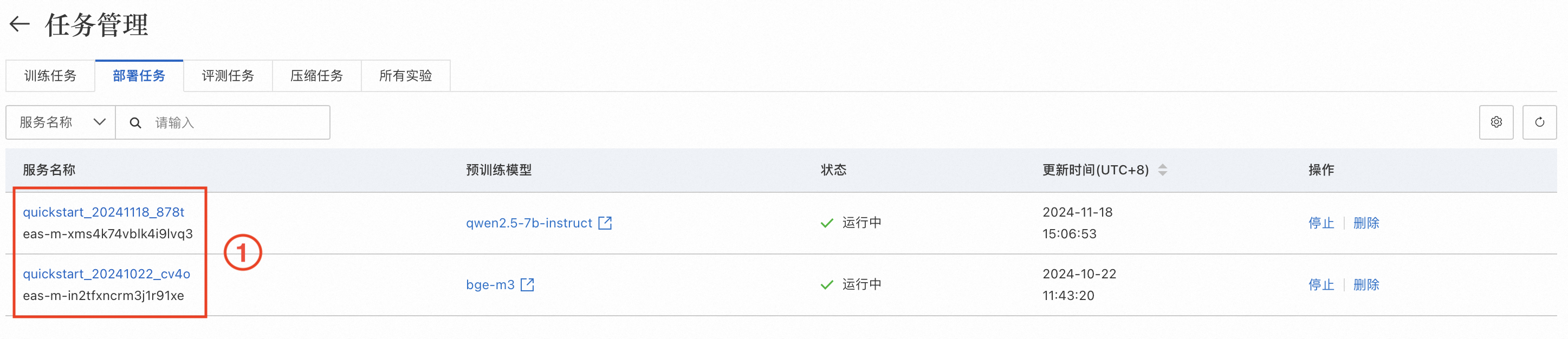
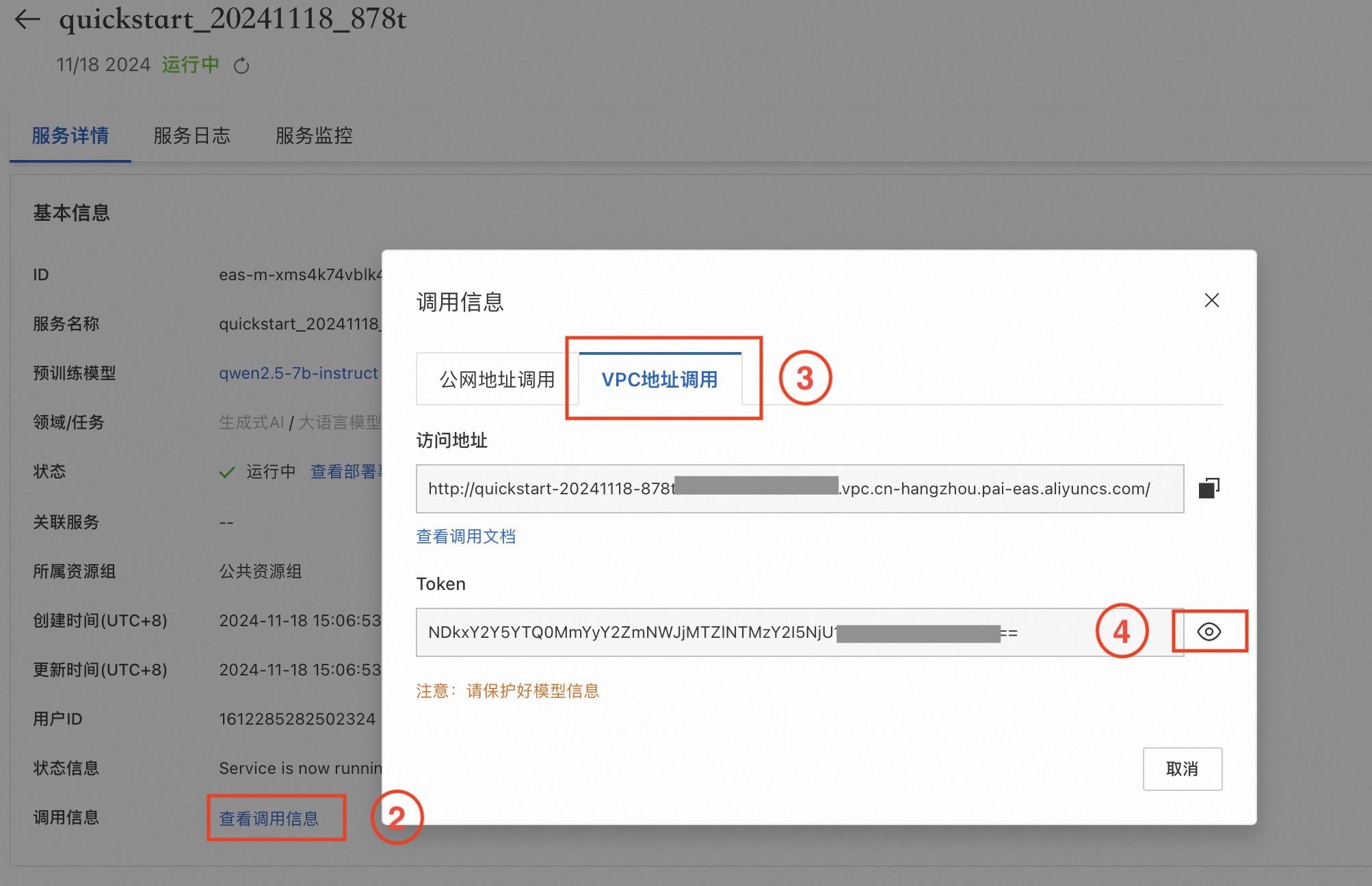
2. 前往任务管理,单击已部署的服务名称,在服务详情页签下单击查看调用信息,分别获取前面部署的LLM和Embedding模型服务的VPC访问地址和Token,供后续创建连接时使用。
创建LLM链接
-
进入LangStudio,选择工作空间后,在连接管理页签下单击新建连接,进入应用流创建页面。
-
创建通用LLM模型服务连接。其中base_url和api_key分别对应1. 部署LLM和Embedding模型中LLM的VPC访问地址和Token。
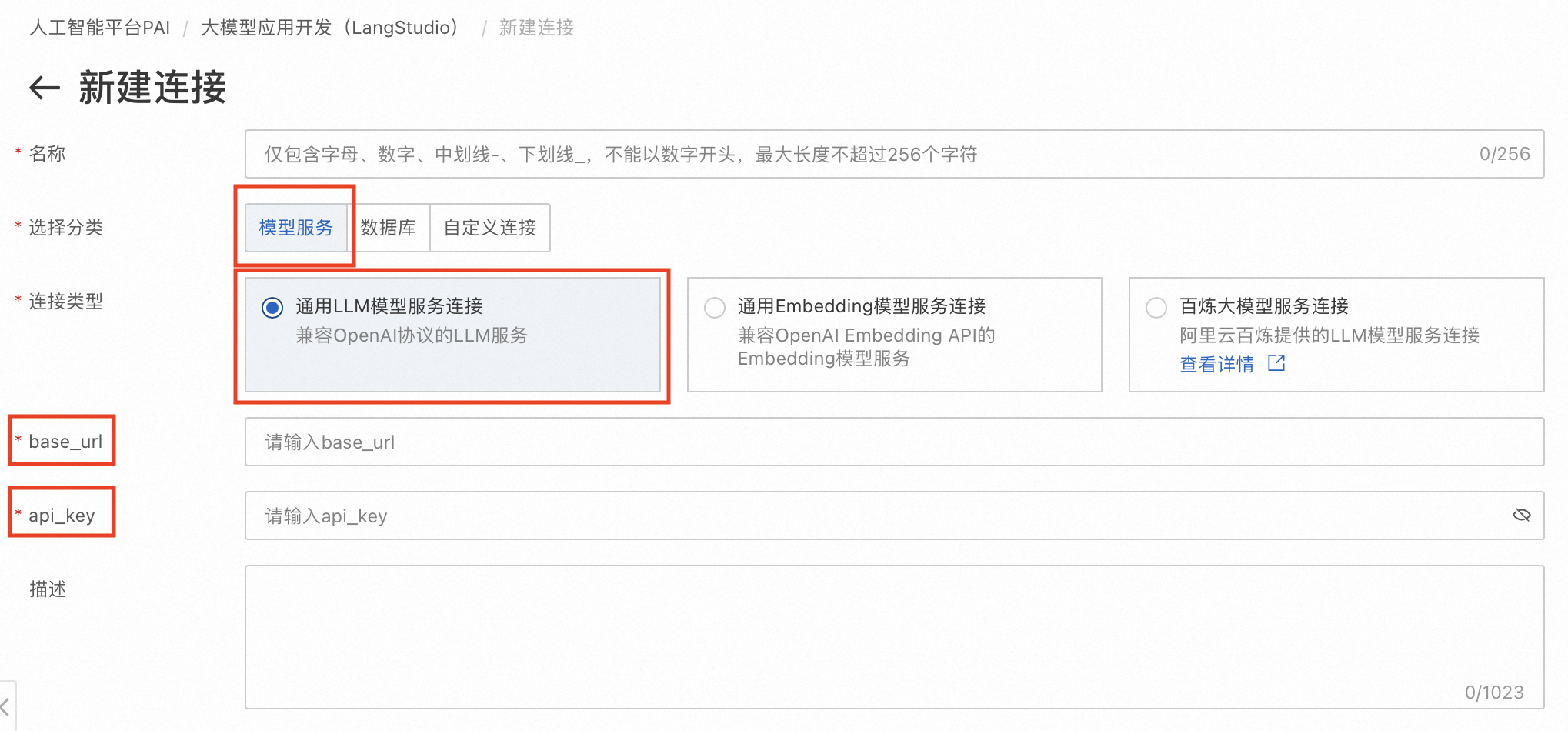
创建Embedding模型服务连接
同3. 创建LLM链接,创建通用Embedding模型服务连接。其中base_url和api_key分别对应2. 部署LLM和Embedding模型中Embedding模型的VPC访问地址和Token。
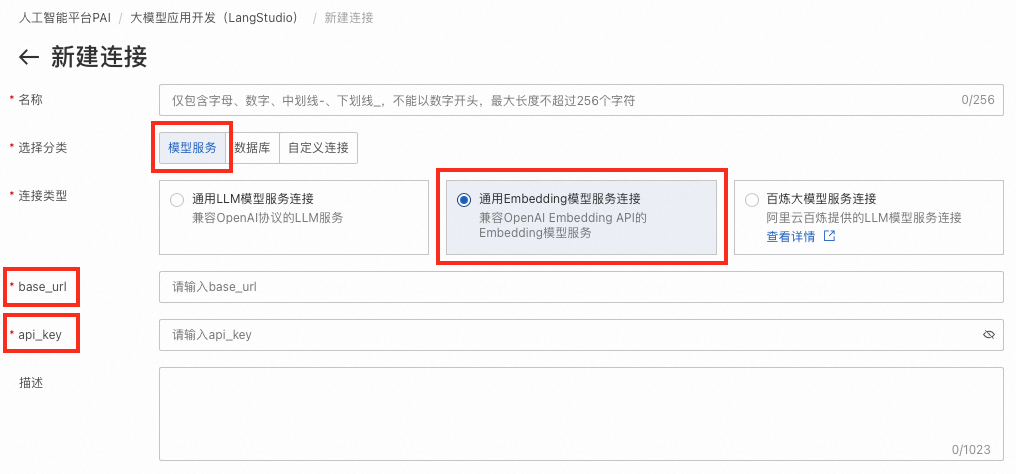
创建向量数据库连接
同3. 创建LLM链接,创建Milvus数据库连接。
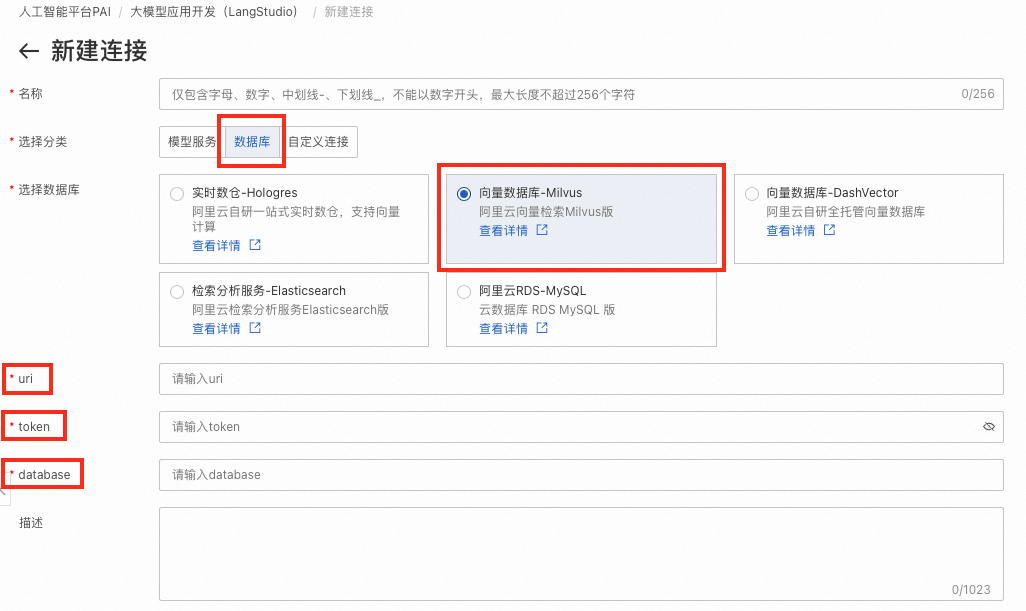
关键参数说明:
-
uri:Milvus实例的访问地址,即
http://<Milvus内网访问地址>,Milvus内网访问地址如下:
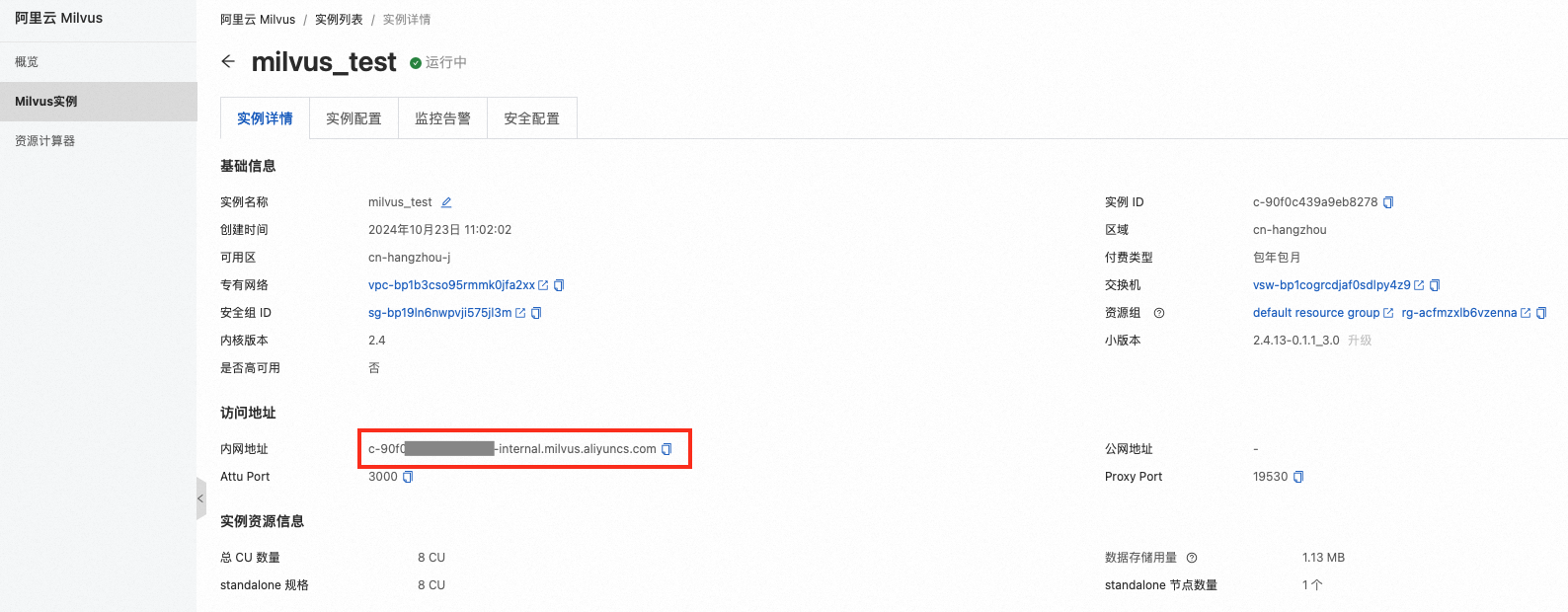
则uri为http://c-b1c5222fba****-internal.milvus.aliyuncs.com。
-
token:登录Milvus实例的用户名和密码,即
<yourUsername>:<yourPassword>。 -
database:数据库名称,本文使用默认数据库
default。
二、使用PAI-Designer构建知识库
使用PAI-Designer构建知识库索引工作流主要包含以下几个步骤:
-
使用数据源读取组件,读取OSS中的数据。
-
使用文本解析分块组件,对文本进行分块。
-
使用向量生成组件,对分块后的文本进行向量化。
-
使用索引存储组件,将向量化后的文本存储到向量数据库。
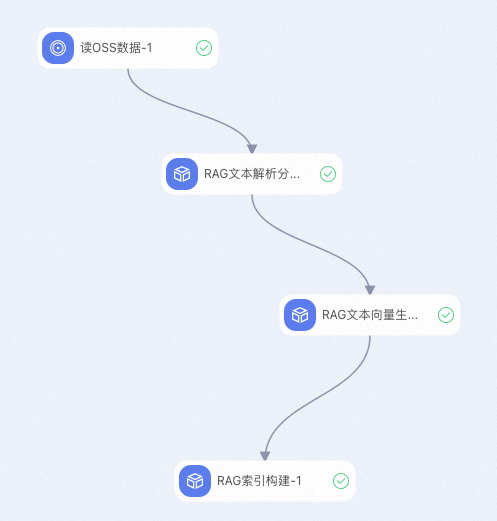
PAI-Designer工作流串联示例
您可以打开PAI-Designer,选择LLM大语言模型中的检索增强生成构建自己的知识库。
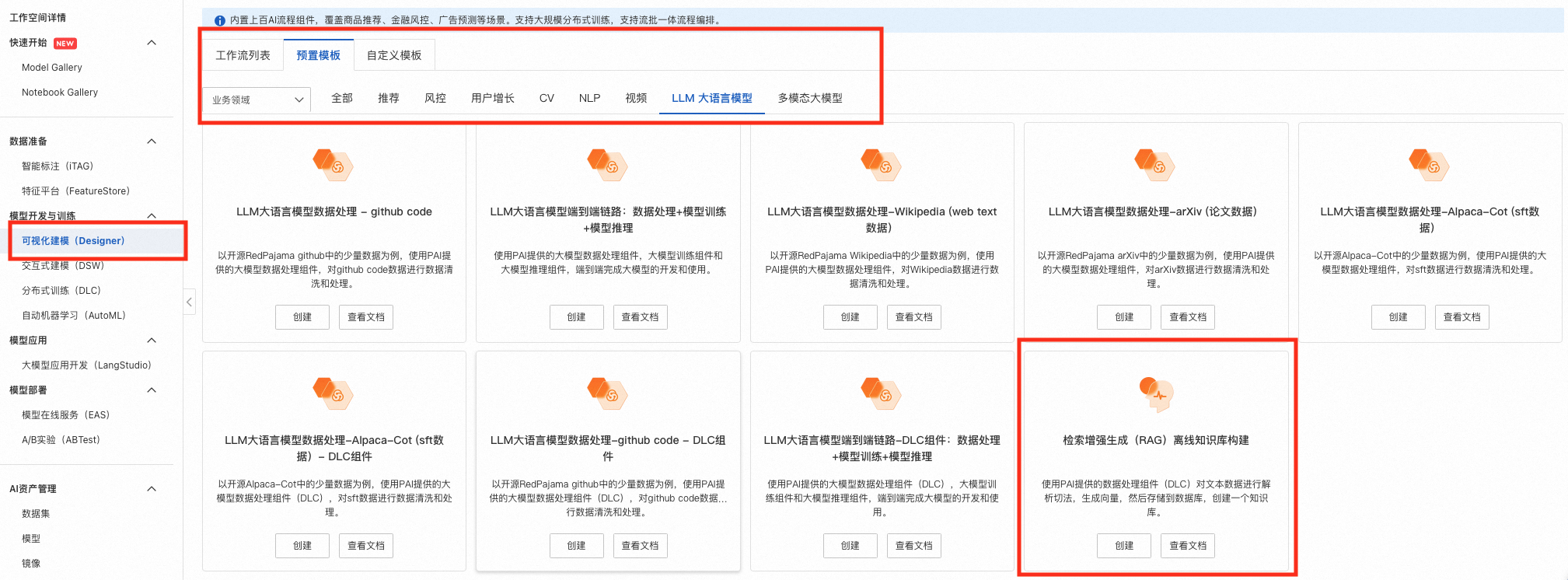
进入工作流后,您会看到下面的工作流,接下来依次介绍各个模块的作用以及需要填写的参数。
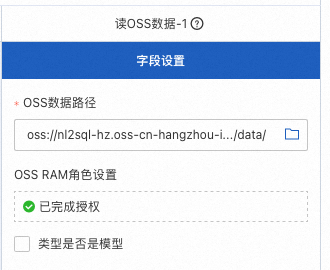
RAG读取OSS数据
选择存储数据的OSS Bucket,确保Bucket中已经保存好相关的文档数据(可以为pdf/csv格式)。
RAG文本解析分块
对输入的文件进行分块处理,填入块大小和块重叠大小的参数,并选择OSS Bucket保存分块完成的数据。
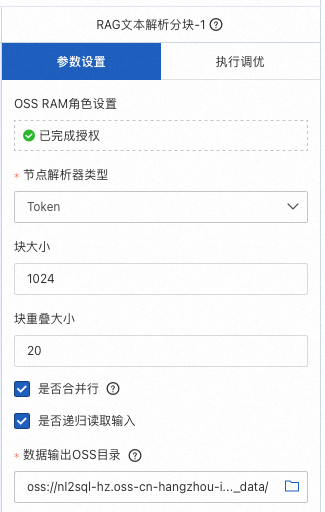
RAG文本向量生成
使用embedding模型,对分块完成的数据进行向量化并存储,便于后续的检索操作。
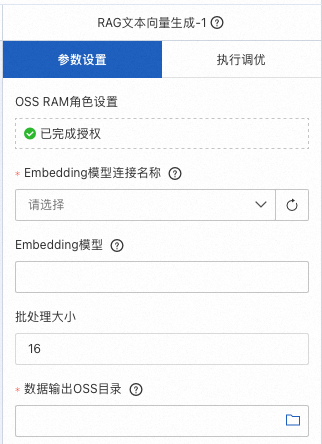
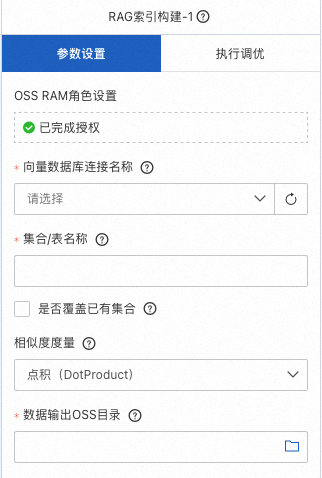
RAG索引构建
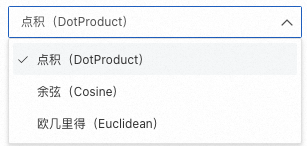
使用先前创建的milvus数据库,存储已经生成的文档向量。其中向量数据库选择自己创建的数据库,为存储的文档向量取一个名称,填入集合/表名称中;相似度度量可以选择点积、余弦、欧几里得的方式;并选择一个OSS Bucket保存RAG的索引。
三、使用PAI-LangStudio进行模版构建
PAI-LangStudio是一个人工智能应用的开发平台,采用直观的交互式环境,简化了企业级大模型应用的开发流程。在开发和设计大模型应用时,可以使用PAI-LangStudio进行模版构建。此外,PAI-LangStudio配合一键部署EAS,使得高质量应用得以迅速、无缝地部署至生产环境。以下介绍使用PAI-LangStudio进行模版构建的过程
新建应用流
-
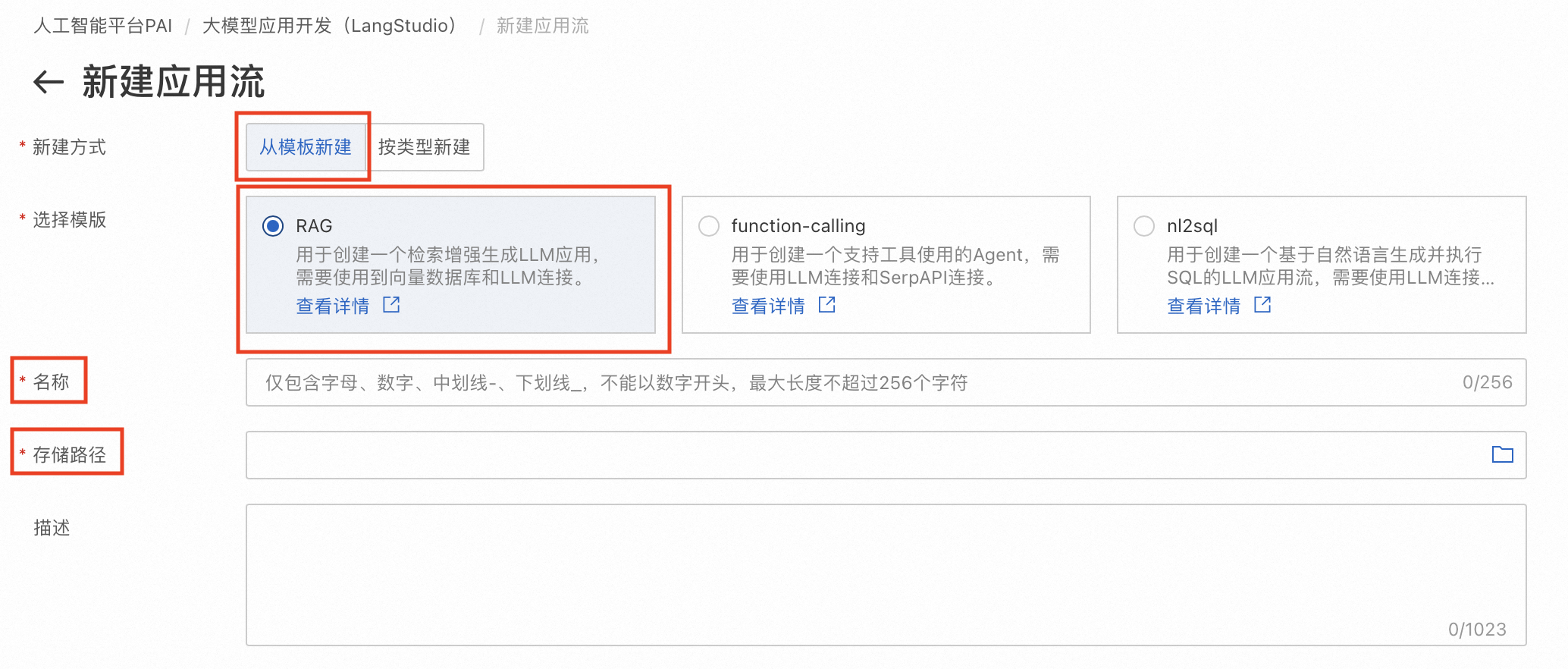
进入LangStudio,选择工作空间后,在应用流页签下单击新建应用流,进入应用流创建页面。
-
选择从模板新建,并在选择RAG模板后填入应用流名称,在OSS Bucket中选择存储应用流的路径。
-
配置应用流
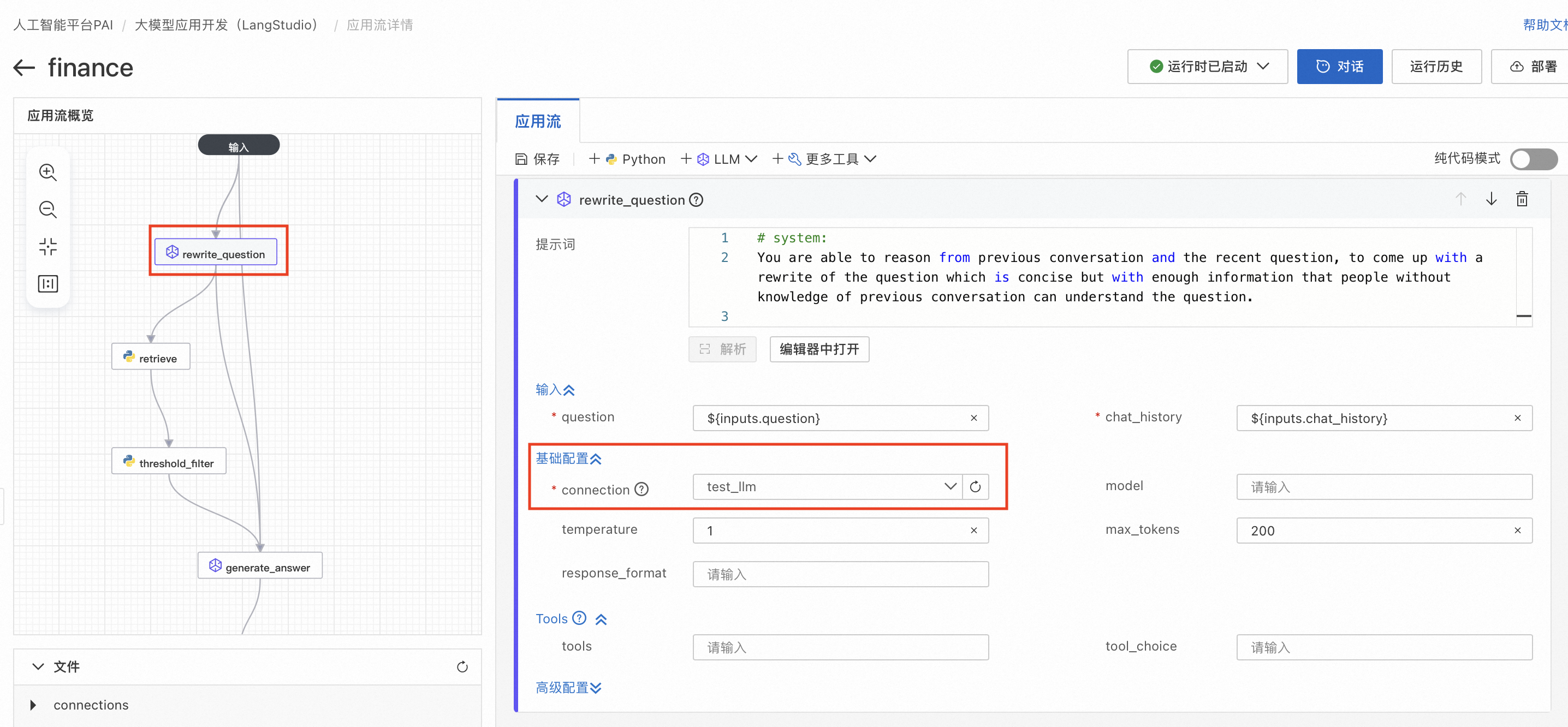
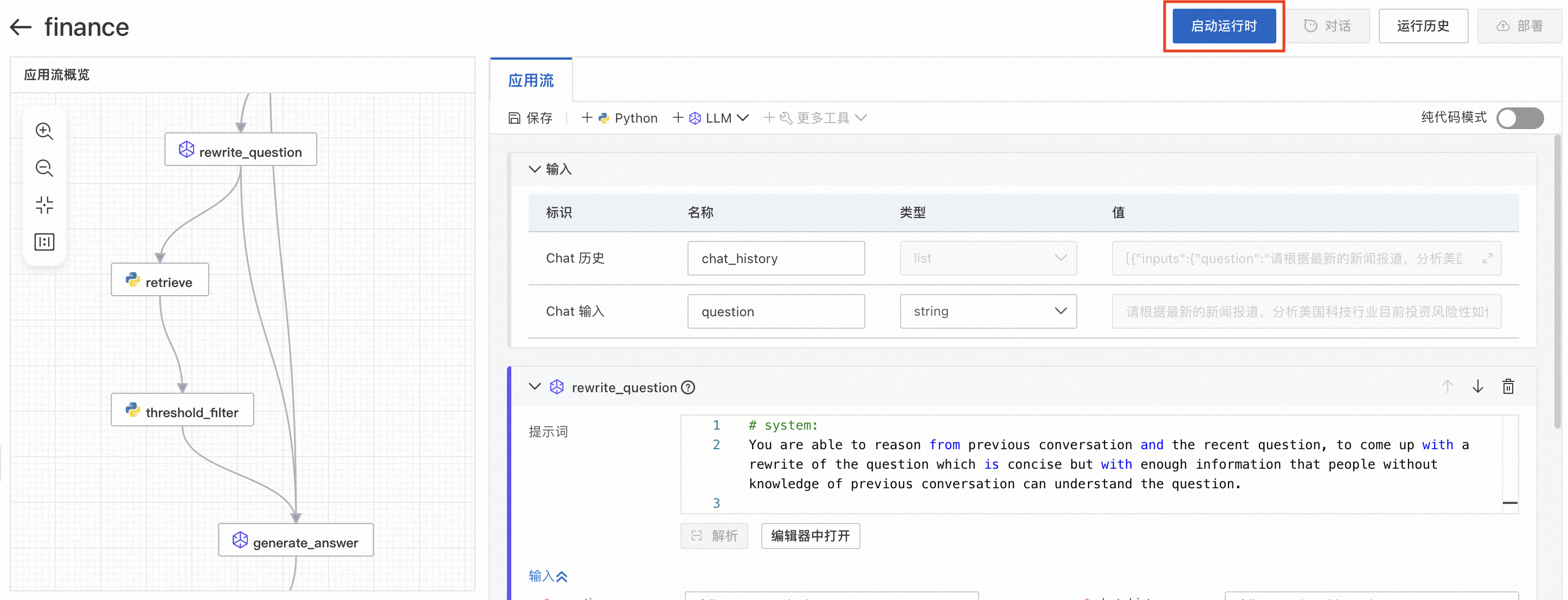
创建应用流后会进入应用流详情界面,左图中有四个节点,分别对应了不同的功能。
1. rewrite_question节点通过对用户问题的重写以提升问题质量,其中需要用户在基础配置中选择connection为前置准备3. 创建LLM连接中创建好的连接。
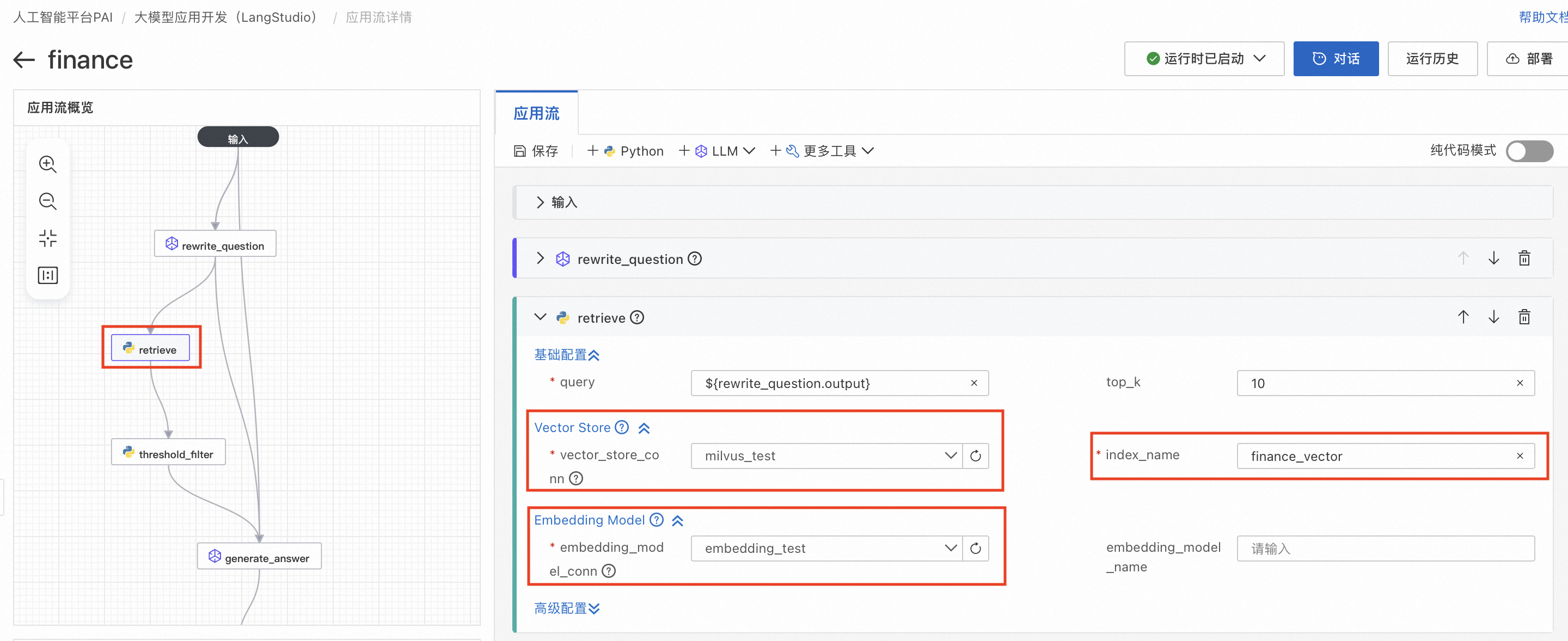
2. retrieve节点通过向量数据库召回和问题相关的文档内容,Vector Store需要用户选择前置准备5. 创建向量数据库中创建好的数据库以及在index_name中填入使用PAI-Designer构建知识库-RAG索引构建中填入的集合/表名;Embedding Model中需要用户选择前置准备4. 创建Embedding模型服务连接中创建的连接。
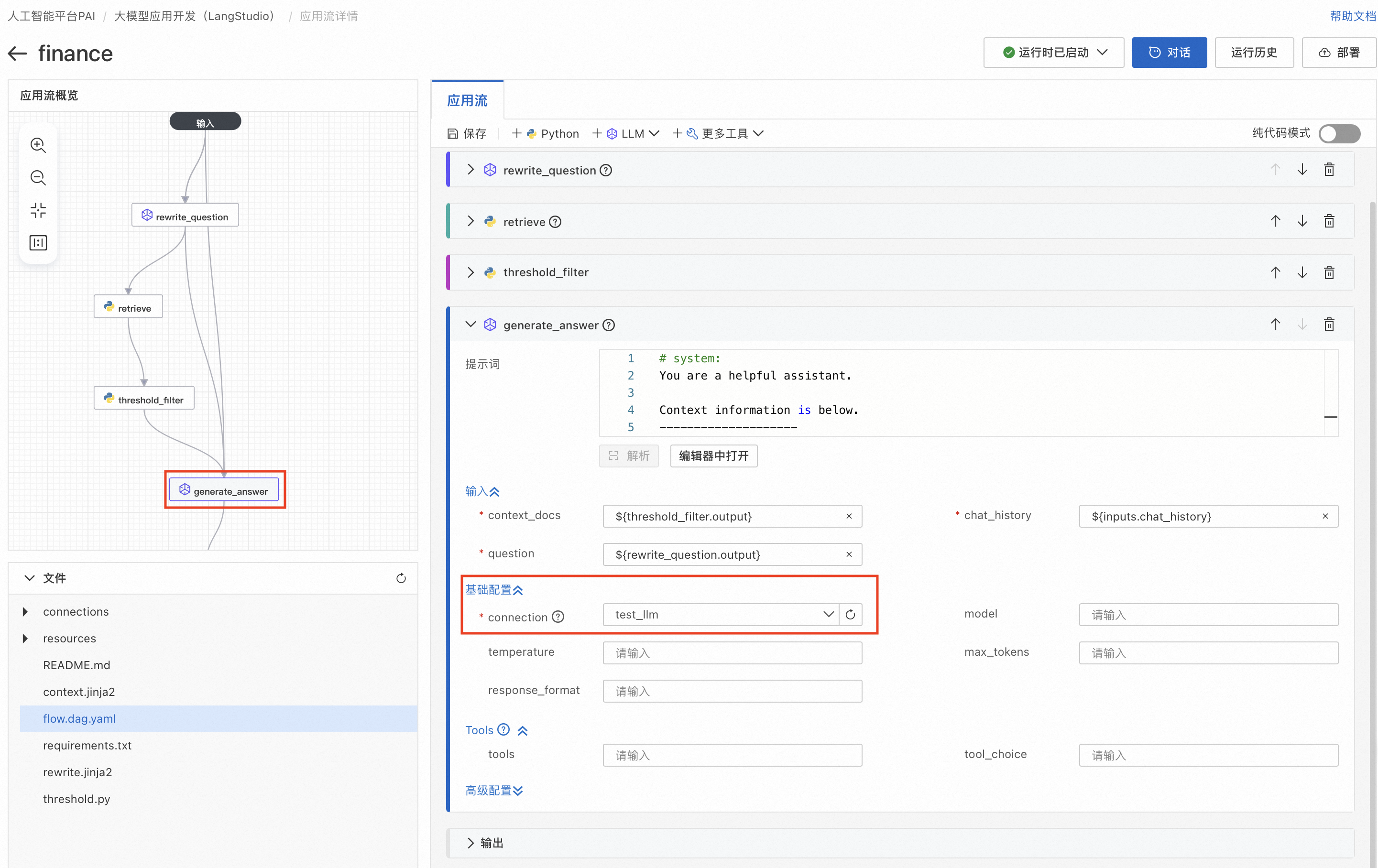
3. threshold_filter节点对retrieve节点召回的文档进行过滤,填入的threshold值是对召回文档和查询问题相似度过滤的条件,threshold越大,则过滤掉越多召回的相似度低的文档。

4. generate_answer节点根据召回和过滤后的文档,回答问题。用户需要在基础配置中选择前置准备3. 创建LLM连接中创建好的LLM连接。
四、使用PAI-Langstudio构建在线应用
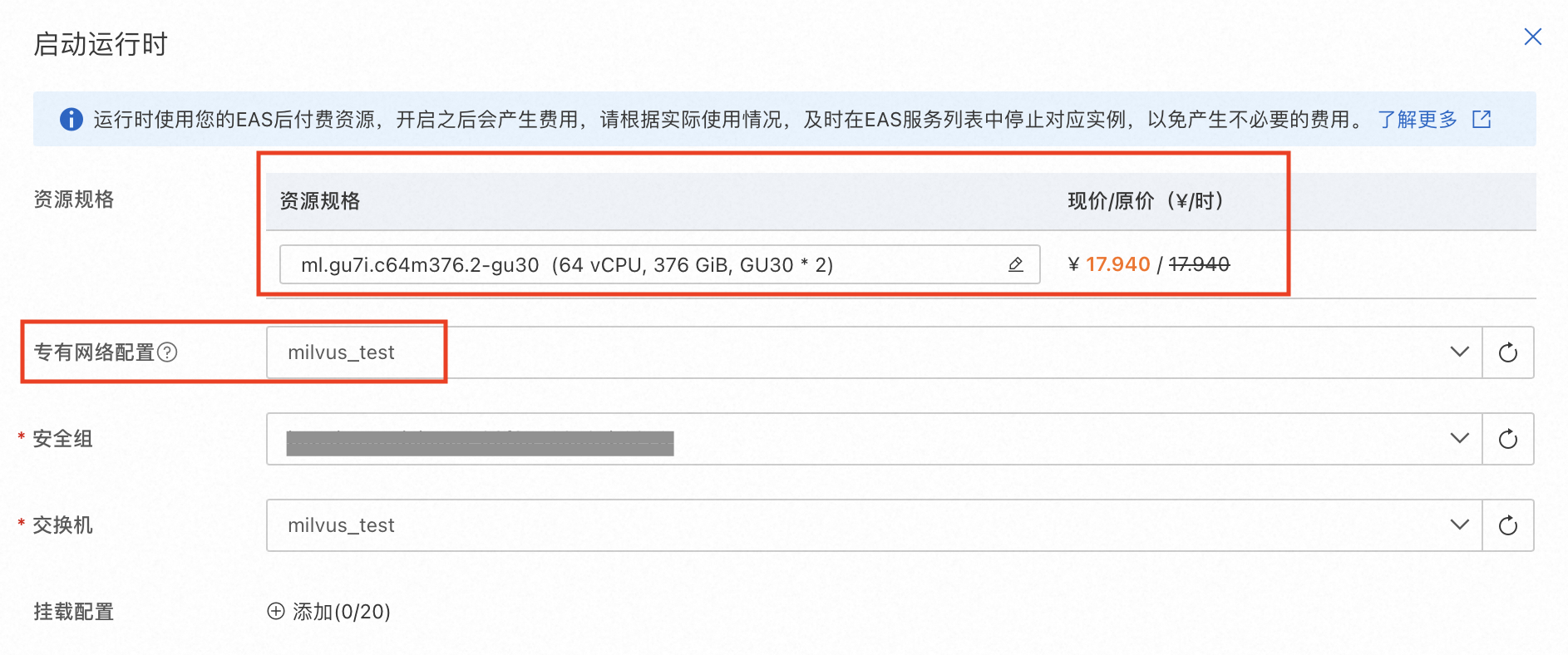
1. 配置完上述流程后,点击启动运行时,并选择机型,配置专有网络链接,部署RAG应用。
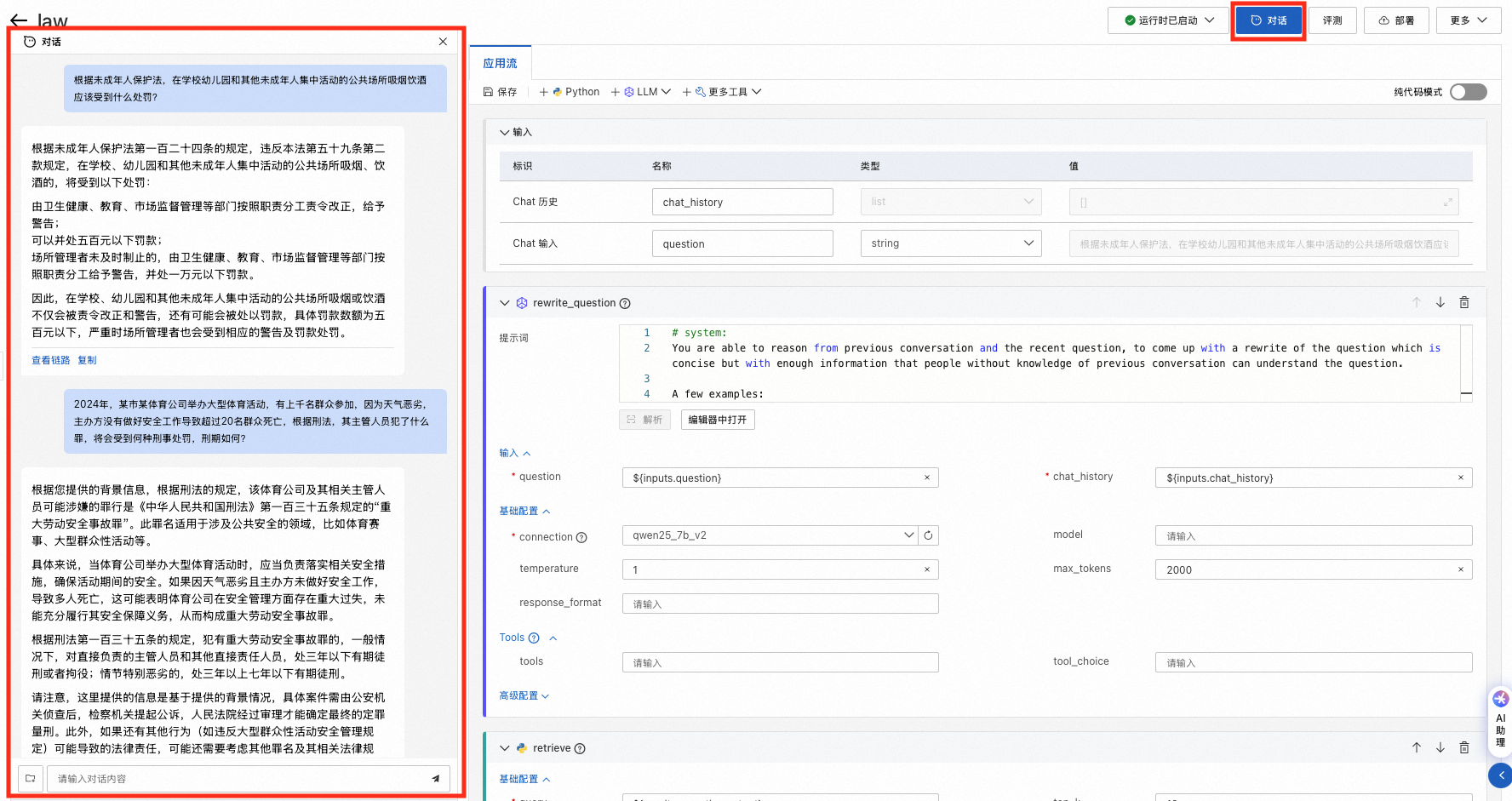
2. 运行时启动后,点击对话按钮,在左侧对话框中输入想问的问题,与大语言模型开始交流对话。
五、案例对比
以下给出在法律领域,使用和不使用RAG解决特定任务的案例对比。红色部分表示大模型回答有事实性错误,或者不够具体精确,绿色部分表示使用RAG得到的对应正确回复。
任务一:法律信息检索和问答
问题:根据未成年人保护法,在学校幼儿园和其他未成年人集中活动的公共场所吸烟饮酒应该受到什么处罚?

任务二:法律案例预测
问题:2024年,某市某体育公司举办大型体育活动,有上千名群众参加,因为天气恶劣,主办方没有做好安全工作导致超过20名群众死亡,根据刑法,其主管人员犯了什么罪,将会受到何种刑事处罚,刑期如何?
