目录
2.3.2.1.2 熔断降级规则 (DegradeRule)
2.3.2.1.4 访问控制规则 (AuthorityRule)
2.3.2.1.5 热点规则 (ParamFlowRule)
2.6.2.2 远程feign接口配置熔断/降级后的本地实现
1 熔断降级限流
1.1 什么是熔断
A 服务调用 B 服务的某个功能,由于网络不稳定问题,或者 B 服务卡机,导致功能时间超长。 如果这样子的次数太多。 我们就可以直接将 B 断路了(A 不再请求 B 接口),凡是调用 B 的直接返回降级数据,不必等待 B 的超长执行。这样 B 的故障问题,就不会级联影响到 A。
1.2 什么是降级
整个网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级[停止服务,所有的调用直接返回降级数据]。 以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的相应。
异同点:
(1)相同点:
1、为了保证集群大部分服务的可用性和可靠性,防止崩溃,牺牲小我;
2、用户最终都是体验到某个功能不可用。
(2)不同点:
1、熔断是被调用方故障,触发的系统主动规则;
2、降级是基于全局考虑,停止一些正常服务,释放资源。
1.3 什么是限流
对打入服务的请求流量进行控制,使服务能够承担不超过自己能力的流量压力。
2 Sentinel
2.1 简介
官方文档: https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D
api-gateway-flow-control | Sentinel
项目地址: https://github.com/alibaba/Sentinel
随着微服务的流行, 服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、 熔断降级、 系统负载保护等多个维度保护服务的稳定性。
2.1.1 特征
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景, 例如秒杀(即突发流量控制在系统容量可以承受的范围) 、 消息削峰填谷、 集群流量控制、 实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。 您可以在控制台中看到接入应用的单台机器秒级数据, 甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块, 例如:与 Spring Cloud、 Dubbo、 gRPC 的整合。 您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、 完善的 SPI 扩展接口。 您可以通过实现扩展接口来快速地定制逻辑。 例如定制规则管理、 适配动态数据源等。
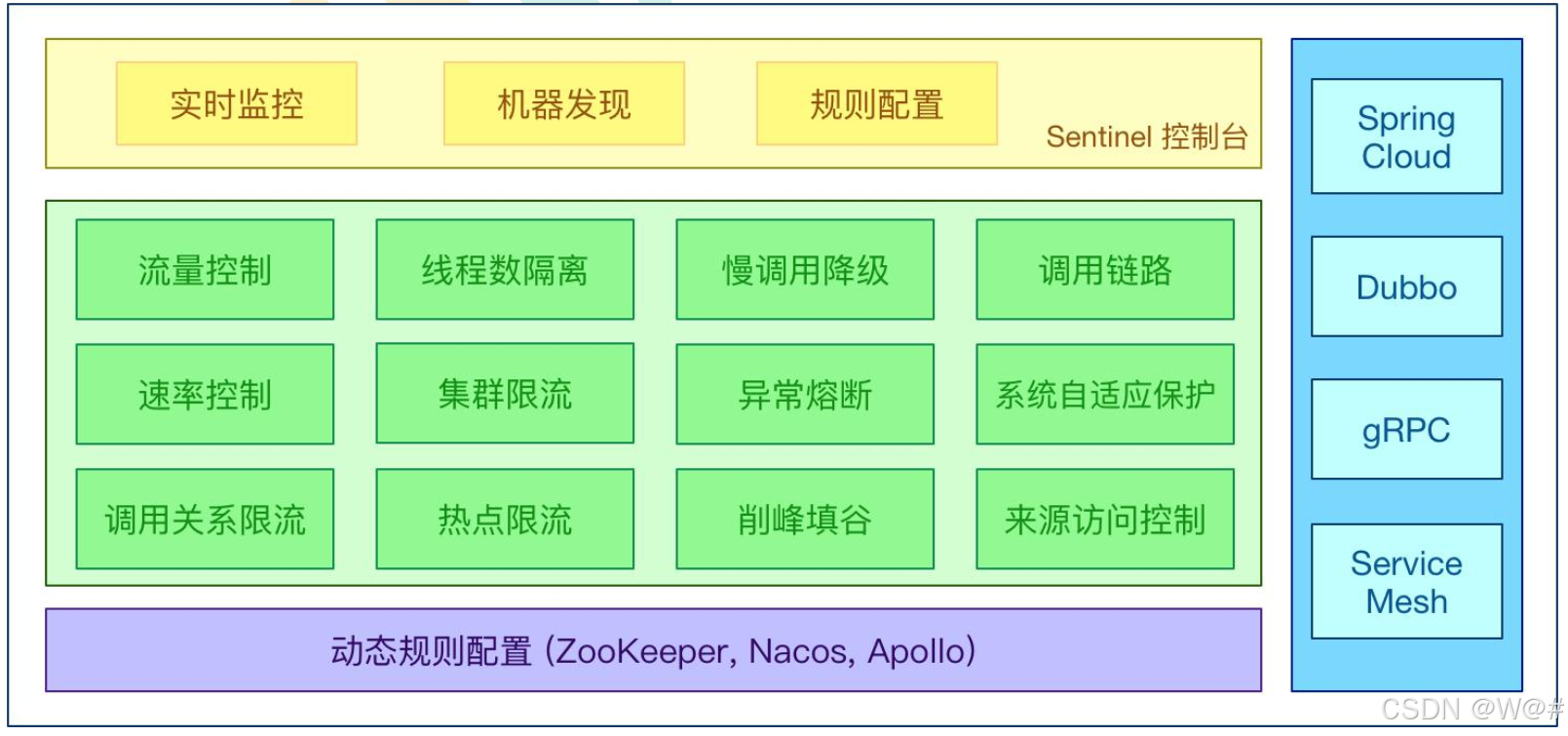
2.1.2 Sentinel分为两部分
Sentinel 可以简单的分为 Sentinel 核心库和 Dashboard。核心库不依赖 Dashboard,但是结合 Dashboard 可以取得最好的效果。
- 核心库(Java 客户端):不依赖任何框架/库, 能够运行于所有 Java 运行时环境, 同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台( Dashboard):基于 Spring Boot 开发, 打包后可以直接运行, 不需要额外的 Tomcat 等应用容器。
2.1.3 Sentinel基本概念
- 资源
资源是 Sentinel 的关键概念。 它可以是 Java 应用程序中的任何内容, 例如, 由应用程序提供的服务, 或由应用程序调用的其它应用提供的服务, 甚至可以是一段代码。 在接下来的文档中, 我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码, 就是资源, 能够被 Sentinel 保护起来。 大部分情况下,可以使用方法签名, URL, 甚至服务名称作为资源名来标示资源。
- 规则
围绕资源的实时状态设定的规则, 可以包括流量控制规则、 熔断降级规则以及系统保护规则。 所有规则可以动态实时调整。
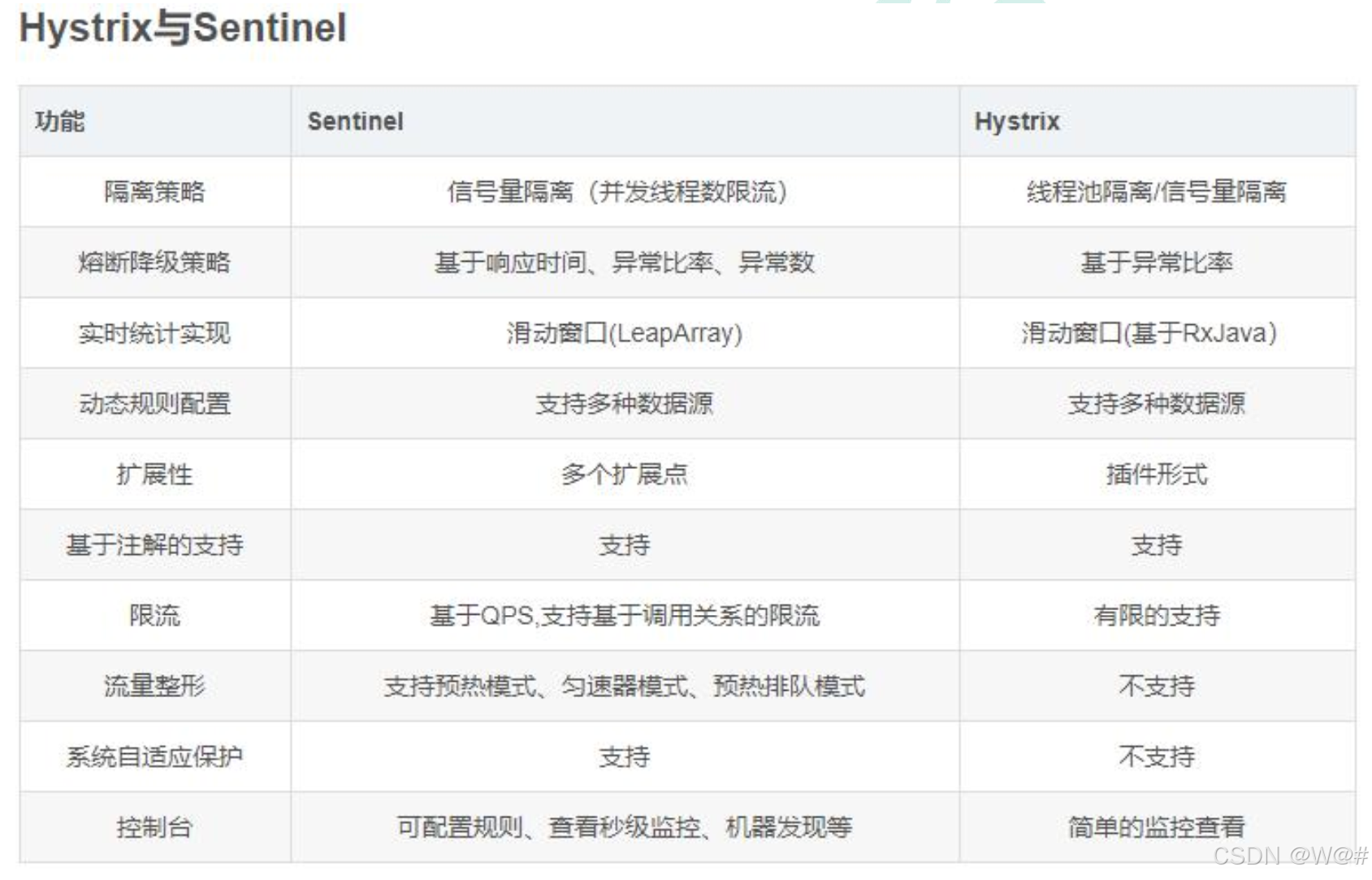
2.2 Hystrix 与 Sentinel比较
2.3 基本使用 - 资源与规则
Sentinel 可以简单的分为 Sentinel 核心库和 Dashboard。核心库不依赖 Dashboard,但是结合 Dashboard 可以取得最好的效果。
这篇文章主要介绍 Sentinel 核心库的使用。如果希望有一个最快最直接的了解,可以参考新手指南 来获取一个最直观的感受。
我们说的资源,可以是任何东西,服务,服务里的方法,甚至是一段代码。使用 Sentinel 来进行资源保护,主要分为几个步骤:
- 定义资源
- 定义规则
- 检验规则是否生效
先把可能需要保护的资源定义好,之后再配置规则。也可以理解为,只要有了资源,我们就可以在任何时候灵活地定义各种流量控制规则。在编码的时候,只需要考虑这个代码是否需要保护,如果需要保护,就将之定义为一个资源。
对于主流的框架,我们提供适配,只需要按照适配中的说明配置,Sentinel 就会默认定义提供的服务,方法等为资源。
2.3.1 定义资源
多用方式【一、二、四】
方式一:主流框架的默认适配
为了减少开发的复杂程度,我们对大部分的主流框架,例如 Web Servlet、Dubbo、Spring Cloud、gRPC、Spring WebFlux、Reactor 等都做了适配。您只需要引入对应的依赖即可方便地整合 Sentinel。可以参见:主流框架的适配。
方式二:抛出异常的方式定义资源
SphU 包含了 try-catch 风格的 API。用这种方式,当资源发生了限流之后会抛出 BlockException这个时候可以捕捉异常,进行限流之后的逻辑处理。示例代码如下:
// 1.5.0 版本开始可以利用 try-with-resources 特性
// 资源名可使用任意有业务语义的字符串,比如方法名、接口名或其它可唯一标识的字符串。
try (Entry entry = SphU.entry("resourceName")) {
// 被保护的业务逻辑
// do something here...
} catch (BlockException ex) {
// 资源访问阻止,被限流或被降级
// 在此处进行相应的处理操作
}特别地,若 entry 的时候传入了热点参数,那么 exit 的时候也一定要带上对应的参数(exit(count, args)),否则可能会有统计错误。这个时候不能使用 try-with-resources 的方式。另外通过 Tracer.trace(ex) 来统计异常信息时,由于 try-with-resources 语法中 catch 调用顺序的问题,会导致无法正确统计异常数,因此统计异常信息时也不能在 try-with-resources 的 catch 块中调用 Tracer.trace(ex)。
1.5.0 之前的版本的示例:
Entry entry = null;
// 务必保证finally会被执行
try {
// 资源名可使用任意有业务语义的字符串
entry = SphU.entry("自定义资源名");
// 被保护的业务逻辑
// do something...
} catch (BlockException e1) {
// 资源访问阻止,被限流或被降级
// 进行相应的处理操作
} finally {
if (entry != null) {
entry.exit();
}
}注意: SphU.entry(xxx) 需要与 entry.exit() 方法成对出现,匹配调用,否则会导致调用链记录异常,抛出 ErrorEntryFreeException 异常。
方式三:返回布尔值方式定义资源
SphO 提供 if-else 风格的 API。用这种方式,当资源发生了限流之后会返回 false,这个时候可以根据返回值,进行限流之后的逻辑处理。示例代码如下:
// 资源名可使用任意有业务语义的字符串
if (SphO.entry("自定义资源名")) {
// 务必保证finally会被执行
try {
/**
* 被保护的业务逻辑
*/
} finally {
SphO.exit();
}
} else {
// 资源访问阻止,被限流或被降级
// 进行相应的处理操作
}方式四:注解方式定义资源
Sentinel 支持通过 @SentinelResource 注解定义资源并配置 blockHandler 和 fallback 函数来进行限流之后的处理。示例:
// 原本的业务方法.
@SentinelResource(blockHandler = "blockHandlerForGetUser")
public User getUserById(String id) {
throw new RuntimeException("getUserById command failed");
}
// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用
public User blockHandlerForGetUser(String id, BlockException ex) {
return new User("admin");
}注意 blockHandler 函数会在原方法被限流/降级/系统保护的时候调用,而 fallback 函数会针对所有类型的异常。请注意 blockHandler 和 fallback 函数的形式要求,更多指引可以参见 Sentinel 注解支持文档。
方式五:异步调用支持
Sentinel 支持异步调用链路的统计。在异步调用中,需要通过 SphU.asyncEntry(xxx) 方法定义资源,并通常需要在异步的回调函数中调用 exit 方法。以下是一个简单的示例:
try {
AsyncEntry entry = SphU.asyncEntry(resourceName);
// 异步调用.
doAsync(userId, result -> {
try {
// 在此处处理异步调用的结果.
} finally {
// 在回调结束后 exit.
entry.exit();
}
});
} catch (BlockException ex) {
// Request blocked.
// Handle the exception (e.g. retry or fallback).
}SphU.asyncEntry(xxx) 不会影响当前(调用线程)的 Context,因此以下两个 entry 在调用链上是平级关系(处于同一层),而不是嵌套关系:
// 调用链类似于:
// -parent
// ---asyncResource
// ---syncResource
asyncEntry = SphU.asyncEntry(asyncResource);
entry = SphU.entry(normalResource);若在异步回调中需要嵌套其它的资源调用(无论是 entry 还是 asyncEntry),只需要借助 Sentinel 提供的上下文切换功能,在对应的地方通过 ContextUtil.runOnContext(context, f) 进行 Context 变换,将对应资源调用处的 Context 切换为生成的异步 Context,即可维持正确的调用链路关系。示例如下:
public void handleResult(String result) {
Entry entry = null;
try {
entry = SphU.entry("handleResultForAsync");
// Handle your result here.
} catch (BlockException ex) {
// Blocked for the result handler.
} finally {
if (entry != null) {
entry.exit();
}
}
}
public void someAsync() {
try {
AsyncEntry entry = SphU.asyncEntry(resourceName);
// Asynchronous invocation.
doAsync(userId, result -> {
// 在异步回调中进行上下文变换,通过 AsyncEntry 的 getAsyncContext 方法获取异步 Context
ContextUtil.runOnContext(entry.getAsyncContext(), () -> {
try {
// 此处嵌套正常的资源调用.
handleResult(result);
} finally {
entry.exit();
}
});
});
} catch (BlockException ex) {
// Request blocked.
// Handle the exception (e.g. retry or fallback).
}
}此时的调用链就类似于:
-parent
---asyncInvocation
-----handleResultForAsync更详细的示例可以参考 Demo 中的 AsyncEntryDemo,里面包含了普通资源与异步资源之间的各种嵌套示例。
2.3.2 定义规则
2.3.2.1 规则的种类
Sentinel 的所有规则都可以在内存态中动态地查询及修改,修改之后立即生效。同时 Sentinel 也提供相关 API,供您来定制自己的规则策略。
Sentinel 支持以下几种规则:流量控制规则、熔断降级规则、系统保护规则、来源访问控制规则 和 热点参数规则。
2.3.2.1.1 流量控制规则(FlowRule)
流量规则的定义
重要属性:
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,资源名是限流规则的作用对象 | |
| count | 限流阈值 | |
| grade | 限流阈值类型,QPS 或线程数模式 | QPS 模式 |
| limitApp | 流控针对的调用来源 | default, 代表不区分调用来源 |
| strategy | 调用关系限流策略:直接、链路、关联 | 根据资源本身(直接) |
| controlBehavior | 流控效果(直接拒绝 / 排队等待 / 慢启动模式),不支持按调用关系限流 | 直接拒绝 |
同一个资源可以同时有多个限流规则。
通过代码定义流量控制规则
理解上面规则的定义之后,我们可以通过调用 FlowRuleManager.loadRules() 方法来用硬编码的方式定义流量控制规则,比如:
private static void initFlowQpsRule() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule1 = new FlowRule();
rule1.setResource(resource);
// Set max qps to 20
rule1.setCount(20);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule1.setLimitApp("default");
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}更多详细内容可以参考 流量控制。
2.3.2.1.2 熔断降级规则 (DegradeRule)
熔断降级规则包含下面几个重要的属性:
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,即规则的作用对象 | |
| grade | 熔断策略,支持慢调用比例/异常比例/异常数策略 | 慢调用比例 |
| count | 慢调用比例模式下为慢调用临界 RT(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值 | |
| timeWindow | 熔断时长,单位为 s | |
| minRequestAmount | 熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断(1.7.0 引入) | 5 |
| statIntervalMs | 统计时长(单位为 ms),如 60*1000 代表分钟级(1.8.0 引入) | 1000 ms |
| slowRatioThreshold | 慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入) |
同一个资源可以同时有多个降级规则。
理解上面规则的定义之后,我们可以通过调用 DegradeRuleManager.loadRules() 方法来用硬编码的方式定义流量控制规则。
private static void initDegradeRule() {
List<DegradeRule> rules = new ArrayList<>();
DegradeRule rule = new DegradeRule(resource);
.setGrade(CircuitBreakerStrategy.ERROR_RATIO.getType());
.setCount(0.7); // Threshold is 70% error ratio
.setMinRequestAmount(100)
.setStatIntervalMs(30000) // 30s
.setTimeWindow(10);
rules.add(rule);
DegradeRuleManager.loadRules(rules);
}更多详情可以参考 熔断降级。
2.3.2.1.3 系统保护规则 (SystemRule)
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统规则包含下面几个重要的属性:
| Field | 说明 | 默认值 |
|---|---|---|
| highestSystemLoad | load1 触发值,用于触发自适应控制阶段 | -1 (不生效) |
| avgRt | 所有入口流量的平均响应时间 | -1 (不生效) |
| maxThread | 入口流量的最大并发数 | -1 (不生效) |
| qps | 所有入口资源的 QPS | -1 (不生效) |
| highestCpuUsage | 当前系统的 CPU 使用率(0.0-1.0) | -1 (不生效) |
理解上面规则的定义之后,我们可以通过调用 SystemRuleManager.loadRules() 方法来用硬编码的方式定义流量控制规则:
private void initSystemProtectionRule() {
List<SystemRule> rules = new ArrayList<>();
SystemRule rule = new SystemRule();
rule.setHighestSystemLoad(10);
rules.add(rule);
SystemRuleManager.loadRules(rules);
}更多详情可以参考 系统自适应保护。
2.3.2.1.4 访问控制规则 (AuthorityRule)
很多时候,我们需要根据调用方来限制资源是否通过,这时候可以使用 Sentinel 的访问控制(黑白名单)的功能。黑白名单根据资源的请求来源(origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。
授权规则,即黑白名单规则(AuthorityRule)非常简单,主要有以下配置项:
resource:资源名,即限流规则的作用对象limitApp:对应的黑名单/白名单,不同 origin 用,分隔,如appA,appBstrategy:限制模式,AUTHORITY_WHITE为白名单模式,AUTHORITY_BLACK为黑名单模式,默认为白名单模式
更多详情可以参考 来源访问控制。
2.3.2.1.5 热点规则 (ParamFlowRule)
详情可以参考 热点参数限流。
2.3.2.2 查询更改规则
引入了 transport 模块后,可以通过以下的 HTTP API 来获取所有已加载的规则:
其中,type=flow 以 JSON 格式返回现有的限流规则,degrade 返回现有生效的降级规则列表,system 则返回系统保护规则。
获取所有热点规则:
其中,type 可以输入 flow、degrade 等方式来制定更改的规则种类,data 则是对应的 JSON 格式的规则。
2.3.2.3 定制自己的持久化规则
上面的规则配置,都是存在内存中的。即如果应用重启,这个规则就会失效。因此我们提供了开放的接口,您可以通过实现 DataSource 接口的方式,来自定义规则的存储数据源。通常我们的建议有:
- 整合动态配置系统,如 ZooKeeper、Nacos 等,动态地实时刷新配置规则
- 结合 RDBMS、NoSQL、VCS 等来实现该规则
- 配合 Sentinel Dashboard 使用
更多详情请参考 动态规则配置。
2.3.2.4 规则生效的效果
2.3.2.4.1 判断限流降级异常
通过以下方法判断是否为 Sentinel 的流控降级异常:
BlockException.isBlockException(Throwable t);
除了在业务代码逻辑上看到规则生效,我们也可以通过下面简单的方法,来校验规则生效的效果:
- 暴露的 HTTP 接口:通过运行下面命令
curl http://localhost:8719/cnode?id=<资源名称>,观察返回的数据。如果规则生效,在返回的数据栏中的block以及block(m)中会有显示 - 日志:Sentinel 提供秒级的资源运行日志以及限流日志,详情可以参考 日志文档
2.3.2.4.2 block事件
Sentinel 提供以下扩展接口,可以通过 StatisticSlotCallbackRegistry 向 StatisticSlot 注册回调函数:
ProcessorSlotEntryCallback: callback when resource entry passed (onPass) or blocked (onBlocked)ProcessorSlotExitCallback: callback when resource entry successfully completed (onExit)
可以利用这些回调接口来实现报警等功能,实时的监控信息可以从 ClusterNode 中实时获取。
2.4 控制台Dashboard
2.5 Sentinel整合SpringBoot
官方参考文档:Sentinel-开源框架适配
官方参考文档:Sentinel-与SpringBoot/SpringCloud的整合
2.5.1 引入依赖
在公共服务gulimall-common导入依赖,监控所有模块。
gulimall-common/pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>2.5.2 下载控制台Dashboard
查看导入的sentinel-core架包版本,下载对应版本的Dashboard。
下载链接:Dashboard下载
2.5.3 启动sentinel-dashboard
sentinel-dashboard默认使用8080端口,启动时指定端口。
java -jar sentinel-dashboard-1.8.5.jar --server.port=8333浏览器访问:http://localhost:8333
账号密码都是 sentinel

登录成功后,
懒加载,只有访问才会加载;
默认所有的流控设置保存在内存中,重启失效。

2.5.4 配置控制台信息
gulimall-seckill/src/main/resources/application.yml
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8333
port: 8719注意:这里的 spring.cloud.sentinel.transport.port 端口配置会在应用对应的机器上启动一个 Http Server,该 Server 会与 Sentinel 控制台做交互。比如 Sentinel 控制台添加了一个限流规则,会把规则数据 push 给这个 Http Server 接收,Http Server 再将规则注册到 Sentinel 中。
2.5.5 实时监控显示
未进行配置前,实时监控没有数据
2.5.5.1 为需要监控的服务引入Actuator依赖
gulimall-seckill/pom.xml
<!-- actuator健康监控,提供给sentinel使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>2.5.5.2 添加配置
指定想要暴露的端点,这里暴露所有的端点。
gulimall-seckill/src/main/resources/application.yml
management:
endpoints:
web:
exposure:
include: '*'2.5.5.3 添加流控规则
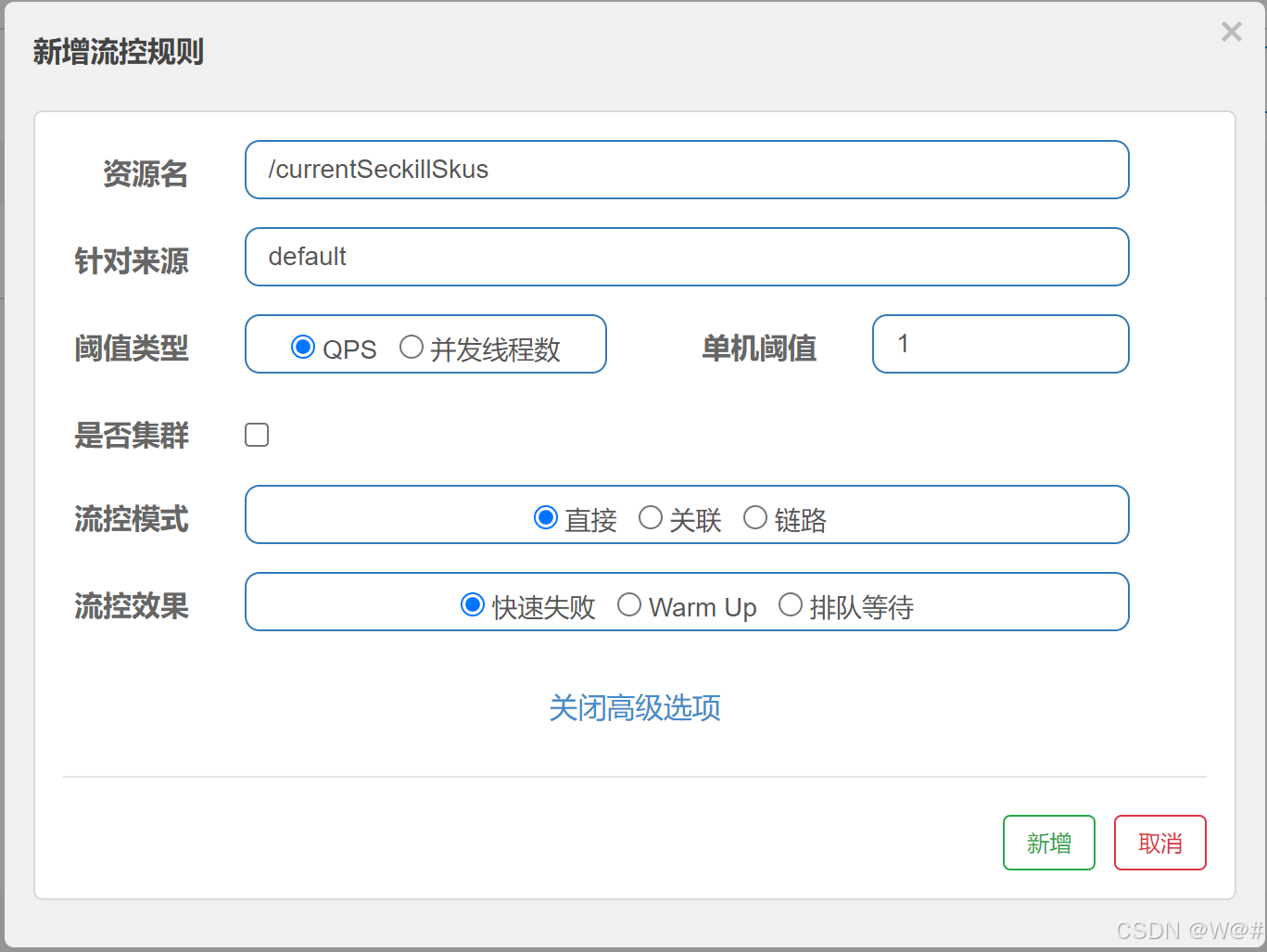
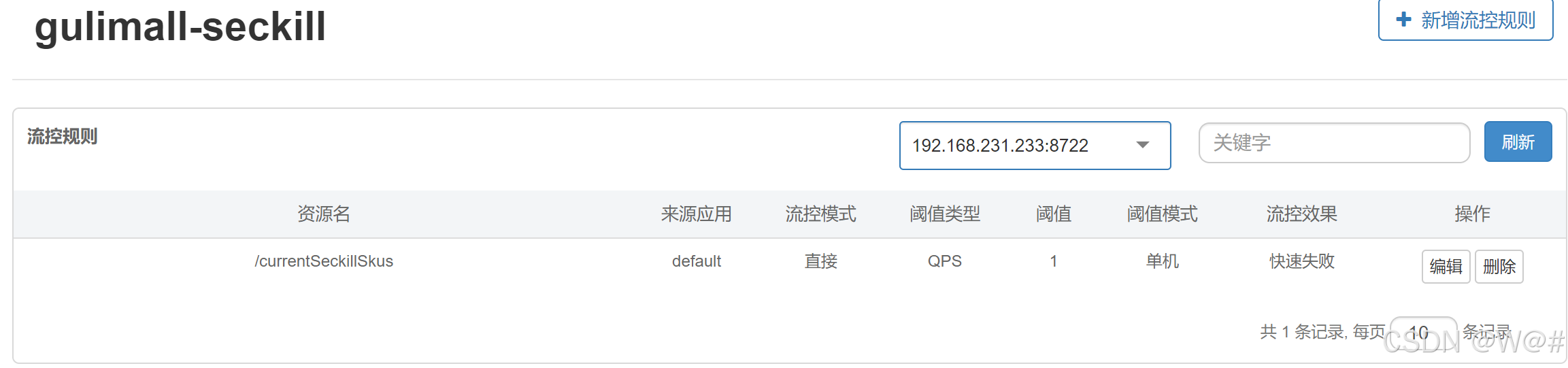
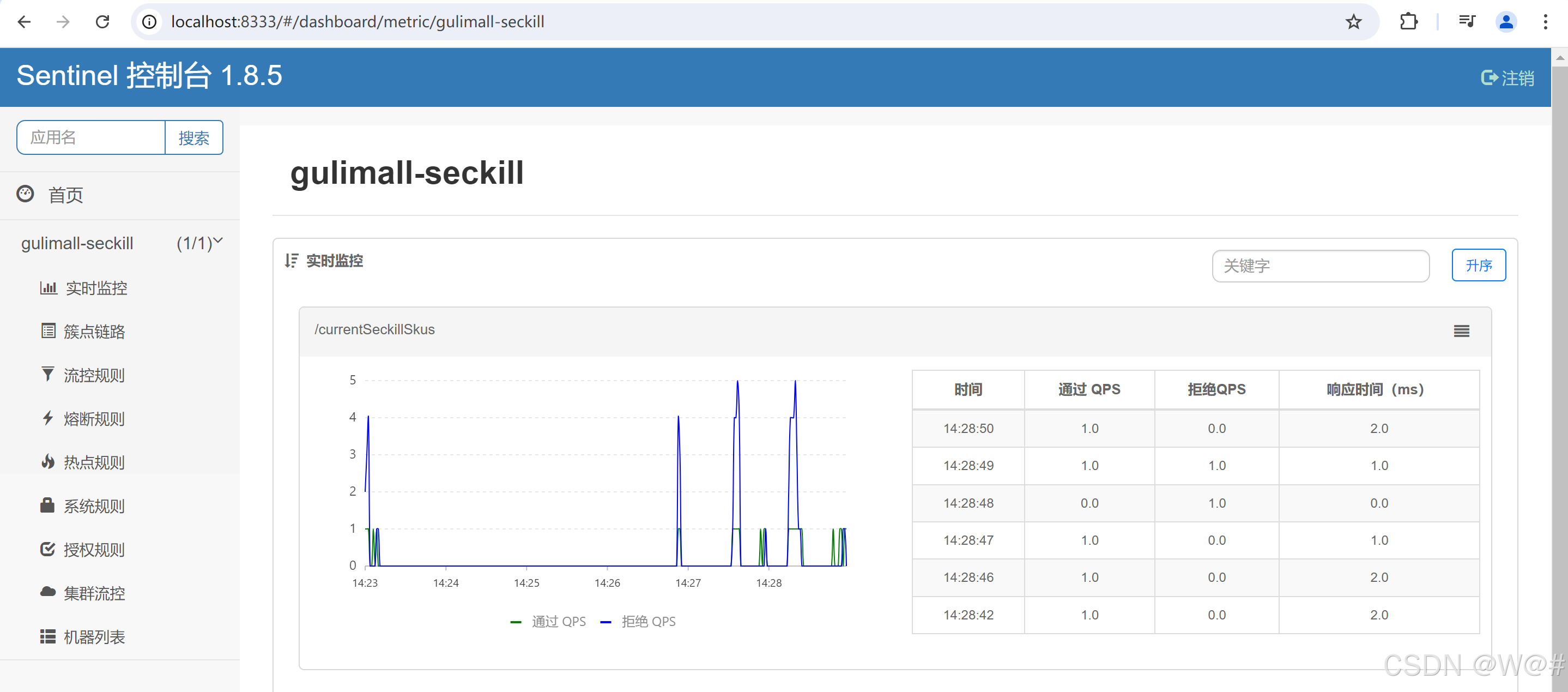
每秒请求数阈值为1,访问被流控的资源,效果如下:

2.5.6 流控模式与效果
2.5.6.1 流控模式
(1)直接
(2)关联
A关联B,对A进行限流,当B流量大时对A进行限制,否则不限制。
(3)链路
入口限流。调用链路中,从指定入口开始请求,流量才会被限制。例如:链路 A->B->C,流控规则中指定A为入口资源,想要C被流控,只有从A请求到C,C才会被限流,其他调用链C不会被限制。
2.5.6.2 流控效果
阈值以500为例:
(1)快速失败
假设此时有700个请求过来,阈值500,有200个快速失败抛出异常。
(2)Warm Up
冷启动/预热启动,假设预热时长是10s,不会一次性放500个请求过来,而是10s内将请求增加至阈值500。
(3)排队等待
假设阈值为500,设置超时时间为3000ms,此时有700个请求过来,500个请求直接放行,剩下200个请求排队,如果3s内剩下的200中得不到处理的直接失败。
快速失败的效果,如下:
2.5.6.3 自定义流控响应
老师使用的sentinel-core:1.6.3版本,视频中使用WebCallbackManager.setUrlBlockHandler(urlBlockHandler)自定义限流处理逻辑;我这里使用是sentinel-core:1.8.5版本,通过实现BlockExceptionHandler接口,重写handle()方法进行自定义限流处理。如下:
gulimall-seckill/src/main/java/com/wen/gulimall/seckill/handler/SeckillSentinelUrlBlockHandler.java
/**
* 自定义流控处理逻辑
* @author w
* @date 2024/08/28
*/
@Component
public class SeckillSentinelUrlBlockHandler implements BlockExceptionHandler {
/**
* 自定义流控返回信息
* @param request
* @param response
* @param e
* @throws Exception
*/
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
R error = R.error(BizCodeEnum.TOO_MANY_REQUEST.getCode(), BizCodeEnum.TOO_MANY_REQUEST.getMsg());
PrintWriter writer = response.getWriter();
writer.write(JSON.toJSONString(error));
}
}自定义限流处理成功,但存在中文乱码问题,如下:
设置字符编码和响应格式,重启测试。
@Component
public class SeckillSentinelUrlBlockHandler implements BlockExceptionHandler {
/**
* 自定义流控返回信息
* @param request
* @param response
* @param e
* @throws Exception
*/
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
R error = R.error(BizCodeEnum.TOO_MANY_REQUEST.getCode(), BizCodeEnum.TOO_MANY_REQUEST.getMsg());
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json");
PrintWriter writer = response.getWriter();
writer.write(JSON.toJSONString(error));
}
}测试结果,如下:
2.6 熔断降级
慢调用比例:设置允许慢调用的最大响应时间RT,请求响应时间大于该值则统计为慢调用
2.6.1 打开Sentinel对feign的支持
开启feign的熔断功能
gulimall-product/src/main/resources/application.yml
# 开启feign的熔断功能
feign:
sentinel:
enabled: true控制台能看到簇点链路信息,如下:

2.6.2 在服务的调用方指定降级策略
2.6.2.1 编写fallback实现
熔断或降级方法的具体实现
gulimall-product/src/main/java/com/wen/gulimall/product/feign/fallback/SeckillFeignServiceFallback.java
@Slf4j
@Component
public class SeckillFeignServiceFallback implements SeckillFeignService {
@Override
public R getSkuSeckillInfo(Long skuId) {
log.info("熔断方法getSkuSeckillInfo调用...");
return R.error(BizCodeEnum.TOO_MANY_REQUEST.getCode(), BizCodeEnum.TOO_MANY_REQUEST.getMsg());
}
}2.6.2.2 远程feign接口配置熔断/降级后的本地实现
指定fallback具体实现类
gulimall-product/src/main/java/com/wen/gulimall/product/feign/SeckillFeignService.java
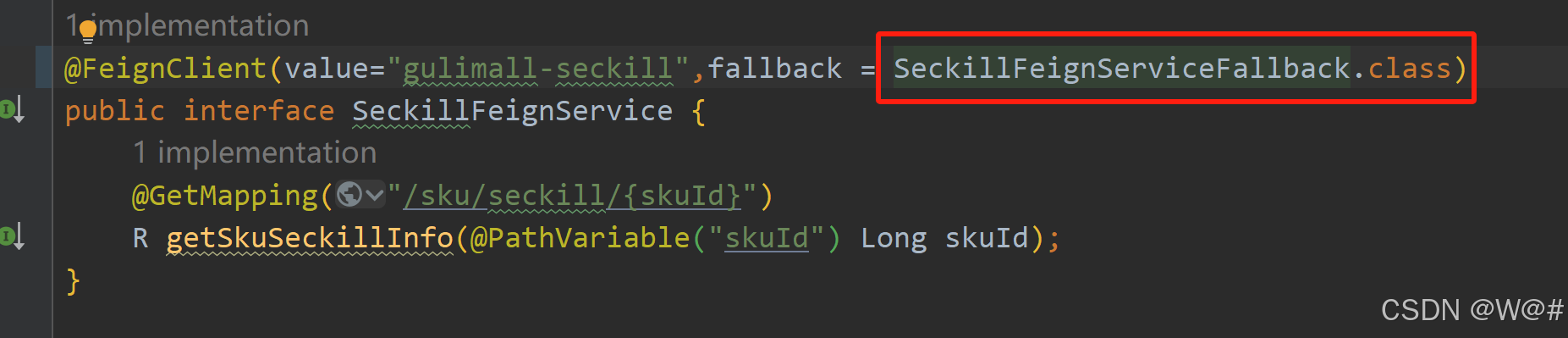
@FeignClient(value="gulimall-seckill",fallback = SeckillFeignServiceFallback.class)
public interface SeckillFeignService {
@GetMapping("/sku/seckill/{skuId}")
R getSkuSeckillInfo(@PathVariable("skuId") Long skuId);
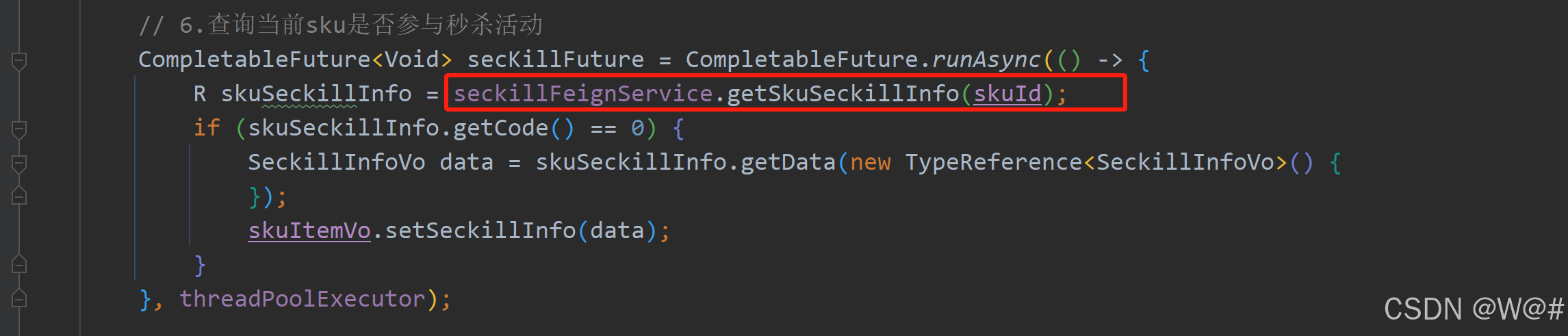
}注意:详情接口中如果查询当前sku是否参与秒杀活动达到了熔断条件不会在进行远程调用,直接调用熔断方法。
2.6.2.3 调用方手动指定远程服务的降级策略
熔断降级策略官方文档:熔断策略
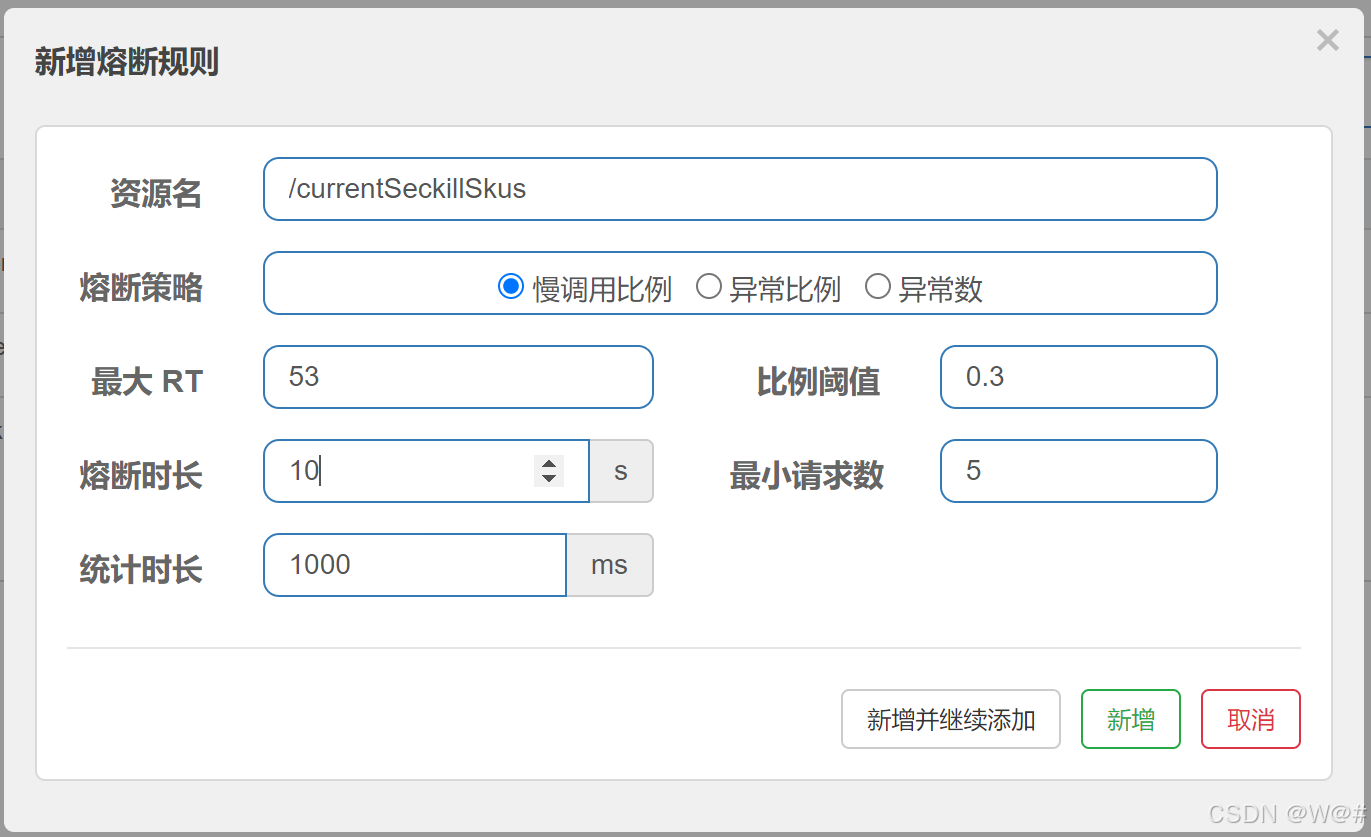
1、熔断策略:慢调用比例
慢调用比例 (
SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
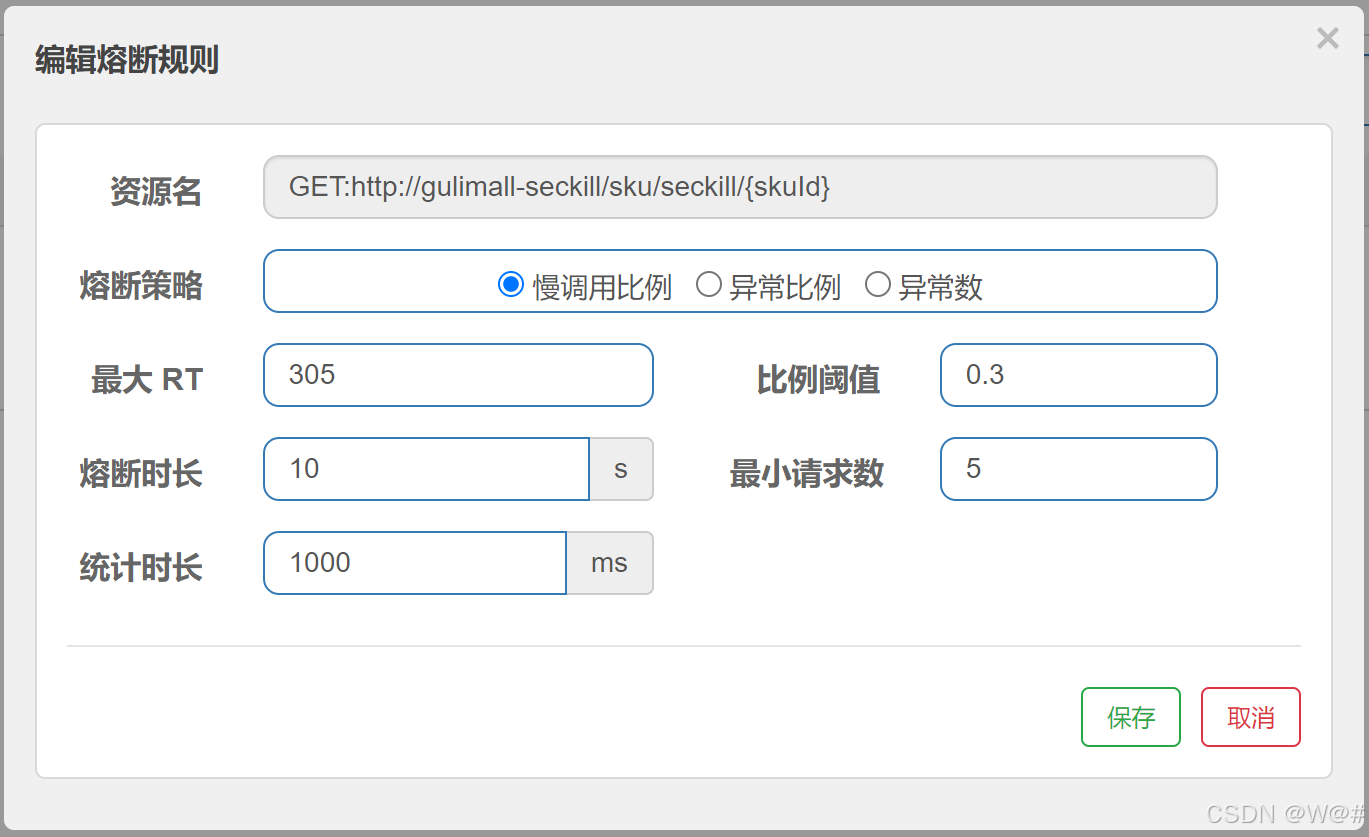
设置说明:1s内的请求数量大于5,且有30%的请求响应时间大于300ms,服务熔断10s中后进入HALF-OPEN状态,如果下一个请求的响应时间超过300ms则服务会再次被熔断。
2.6.2.4 测试熔断
2.6.2.4.1 让秒杀服务的相关接口睡300ms再执行
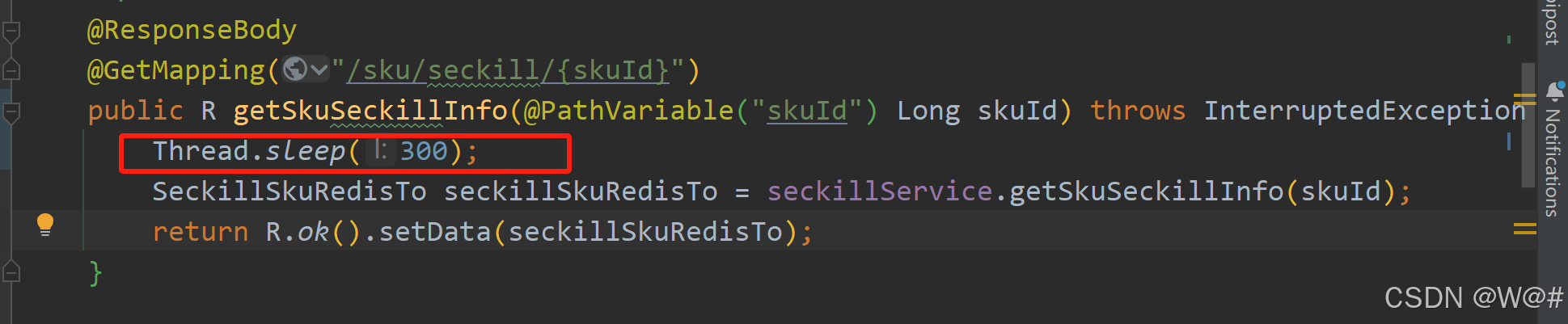
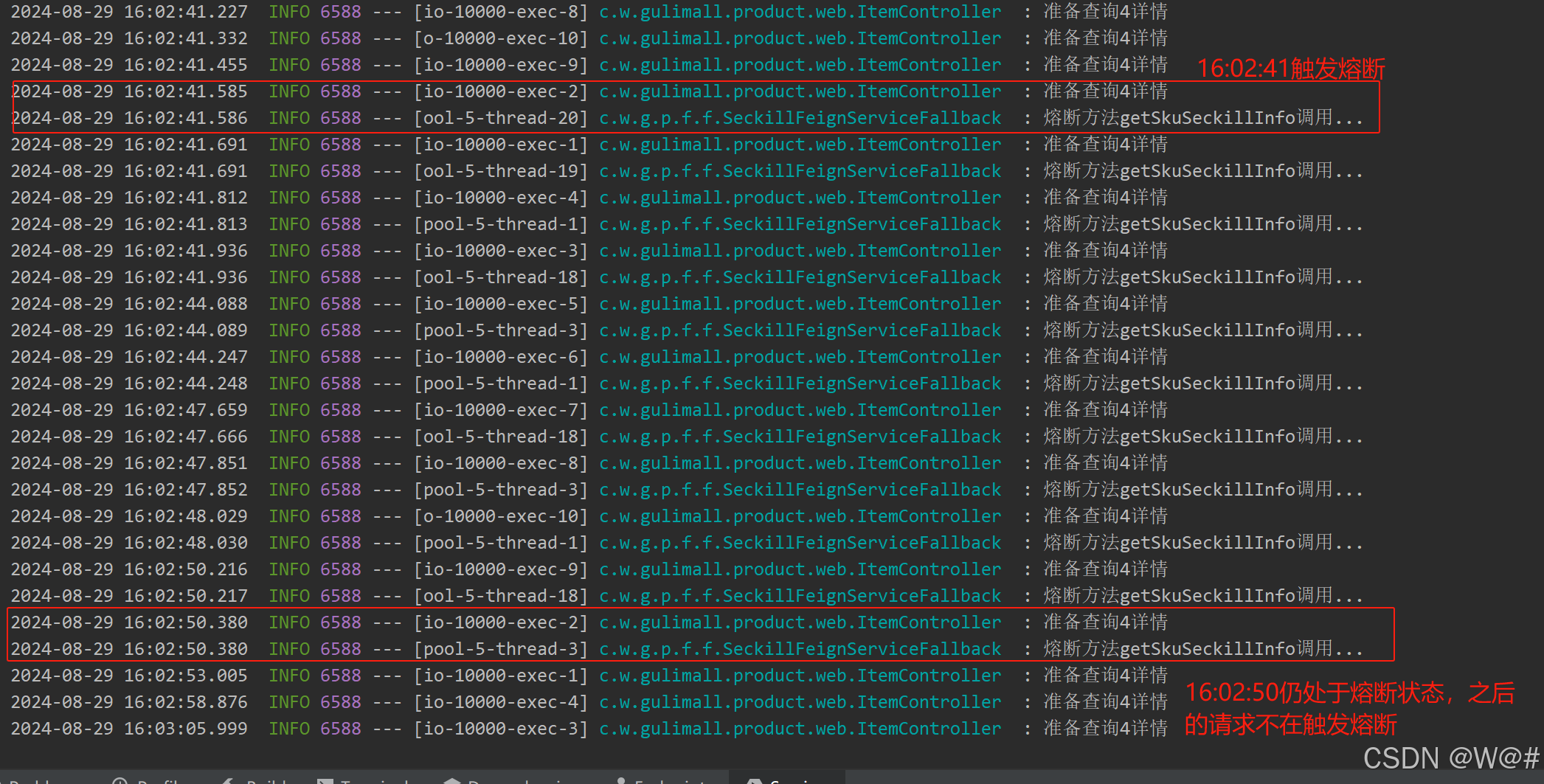
2.6.2.4.2 测试
狂刷商品详情页模拟高并发,直至控制台打印熔断日志
2.6.3 在服务的提供方指定降级策略
超大浏览的时候,必须牺牲一些远程服务。在服务的提供方(远程服务)指定降级策略; 提供方是在运行,但是不运行自己的业务逻辑,返回的是默认的降级数据(限流的数据)。
2.6.3.1 服务方指定降级策略
让当前接口睡50ms在执行便于测试。
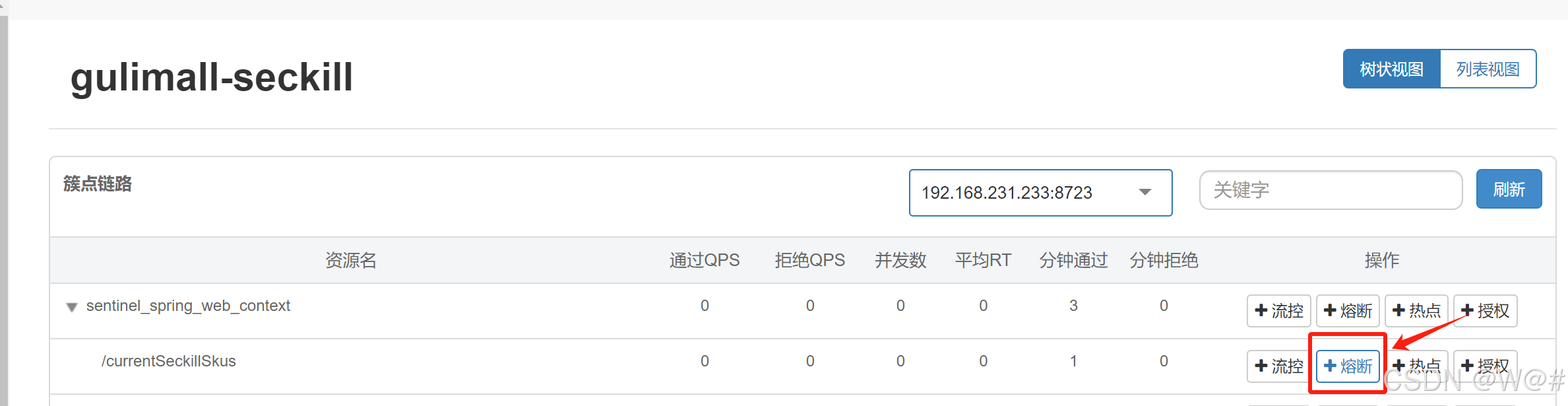
2.6.3.2 自定义降级策略(流控响应)
之前自定义的流控响应,阻塞处理都是一样的。
gulimall-seckill/src/main/java/com/wen/gulimall/seckill/handler/SeckillSentinelUrlBlockHandler.java
/**
* 自定义流控/熔断处理逻辑
* @author w
* @date 2024/08/28 13:46
*/
@Component
public class SeckillSentinelUrlBlockHandler implements BlockExceptionHandler {
/**
* 自定义流控/熔断返回信息
* @param request
* @param response
* @param e
* @throws Exception
*/
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
R error = R.error(BizCodeEnum.TOO_MANY_REQUEST.getCode(), BizCodeEnum.TOO_MANY_REQUEST.getMsg());
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json");
PrintWriter writer = response.getWriter();
writer.write(JSON.toJSONString(error));
}
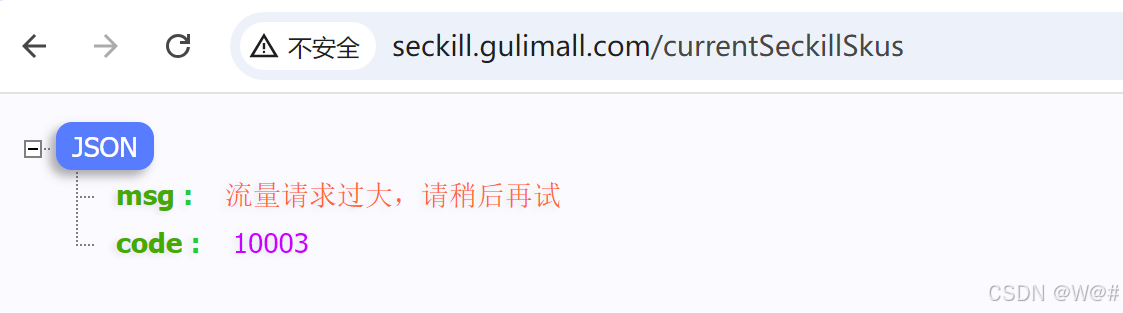
}2.6.3.3 测试
狂刷,模拟大量请求进来,直至返回降级效果。
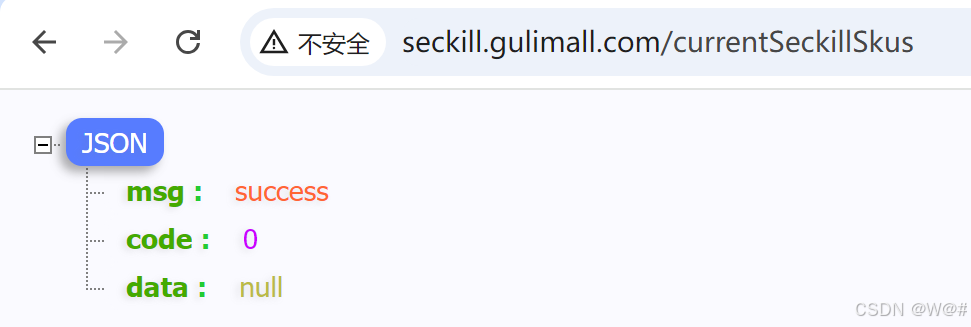
10内熔断降级状态;10s后,刷新请求,可正常访问。
2.6.4 熔断和降级的区别
降级是主动的,提供方可以正常访问,在系统流量高峰期时,主动降级一些低流量服务;
熔断是被动的,提供方宕机或出现异常时熔断,避免拖垮其他级联服务。
2.7 自定义受保护的资源
官方参考文档:定义资源
2.7.1 主流框架的默认适配
Spring Cloud Alibaba 默认为 Sentinel 整合了 Servlet、RestTemplate、FeignClient 和 Spring WebFlux。Sentinel 在 Spring Cloud 生态中,不仅补全了 Hystrix 在 Servlet 和 RestTemplate 这一块的空白,而且还完全兼容了 Hystrix 在 FeignClient 中限流降级的用法,并且支持运行时灵活地配置和调整限流降级规则。
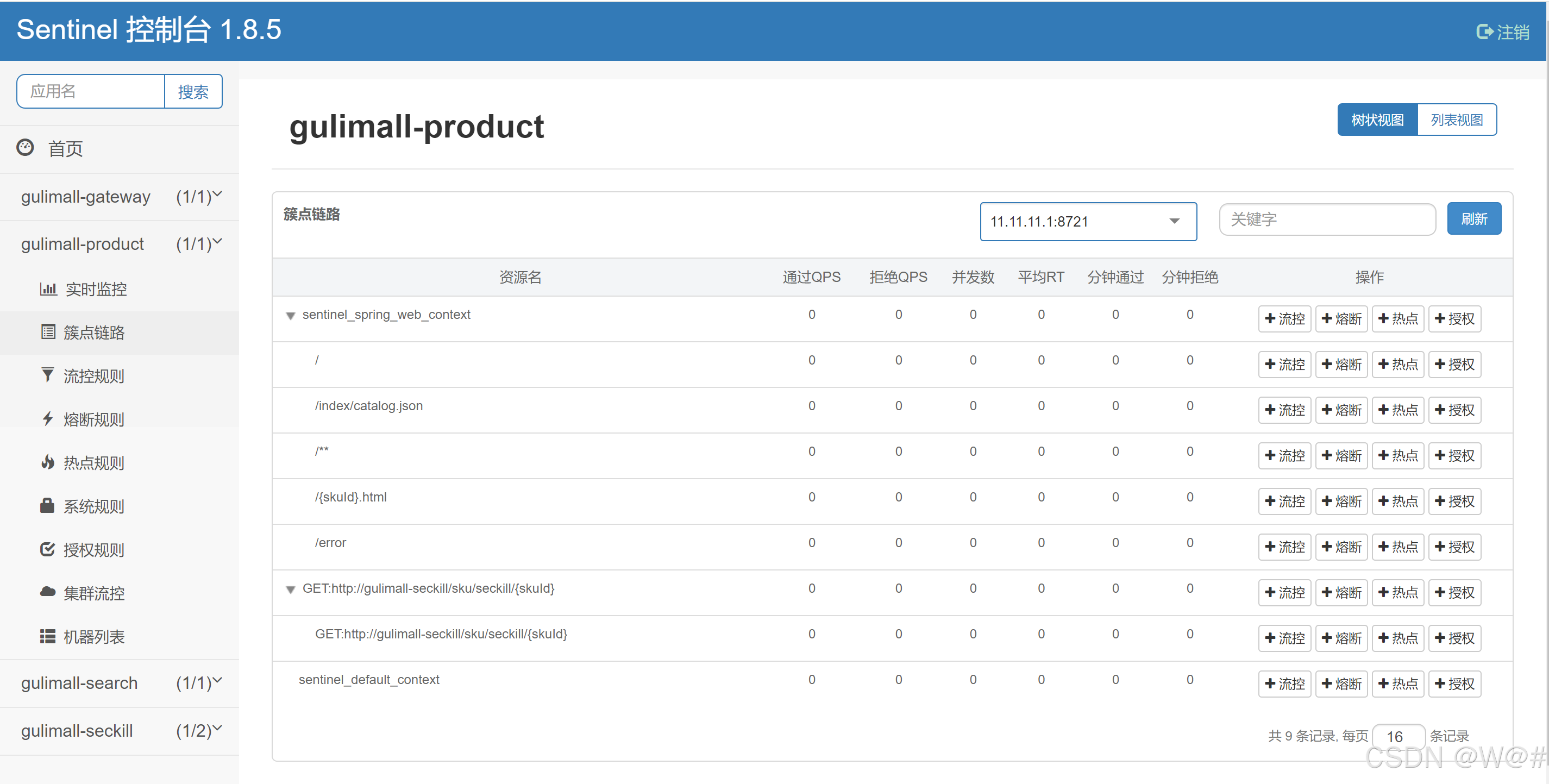
sentinel 懒加载,请求后默认适配的资源,如下,我们没有定义:
2.7.2 抛出异常的方式定义资源
官方示例代码如下:
// 1.5.0 版本开始可以利用 try-with-resources 特性
// 资源名可使用任意有业务语义的字符串,比如方法名、接口名或其它可唯一标识的字符串。
try (Entry entry = SphU.entry("resourceName")) {
// 被保护的业务逻辑
// do something here...
} catch (BlockException ex) {
// 资源访问阻止,被限流或被降级
// 在此处进行相应的处理操作
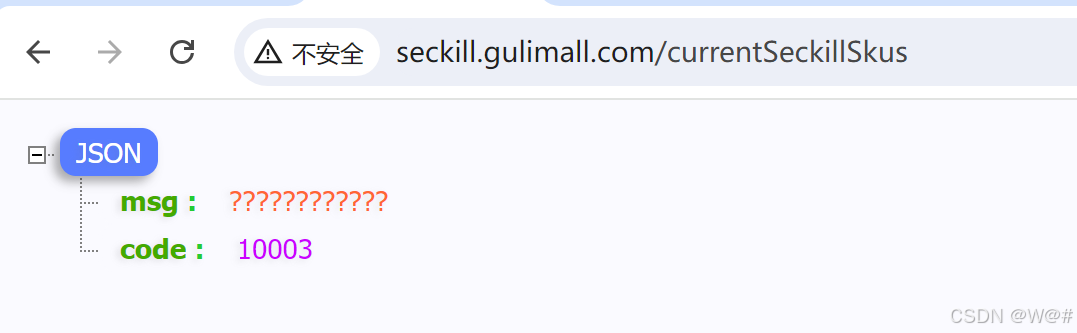
}测试如下:
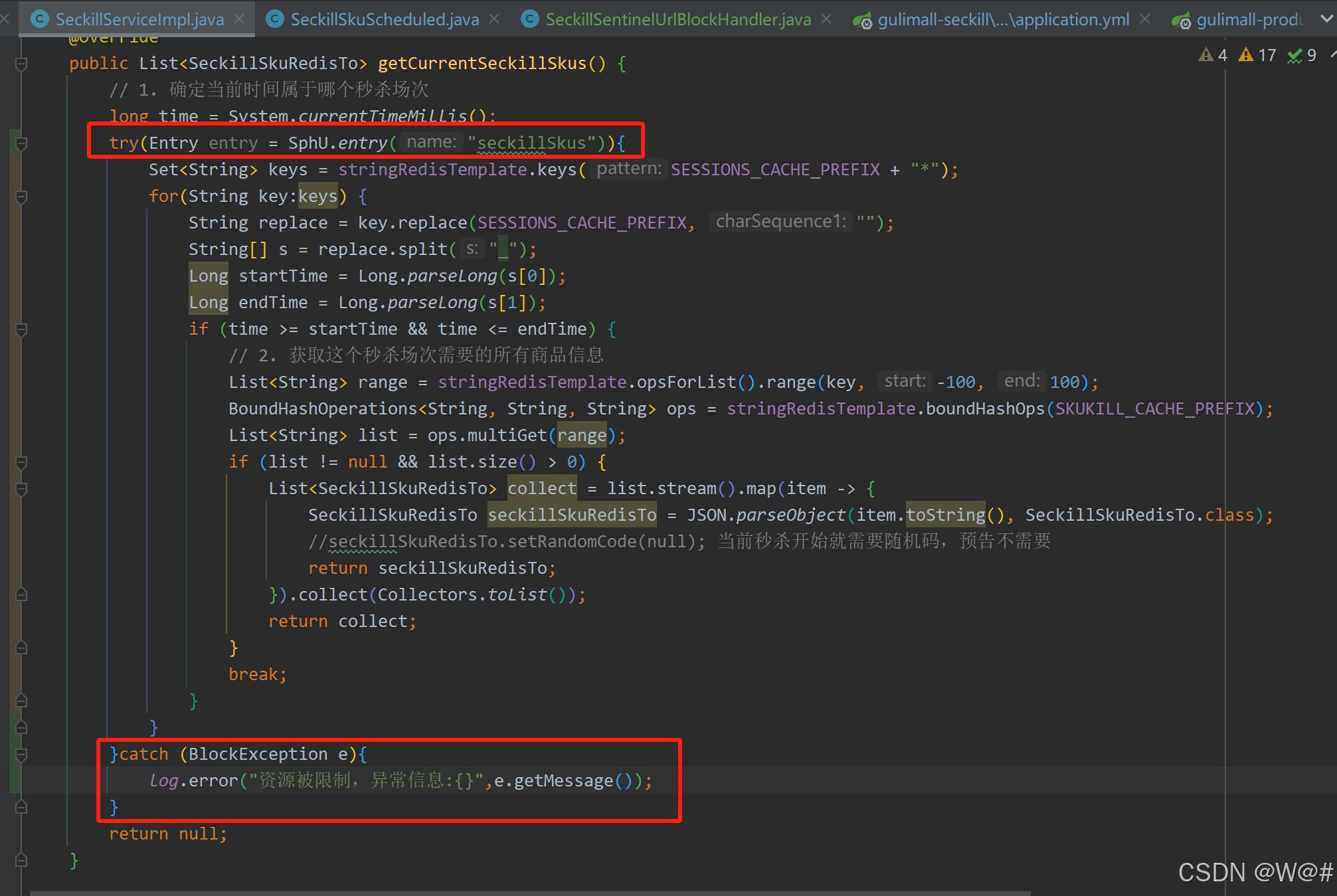
重启秒杀服务,浏览器访问http://seckill.gulimall.com/currentSeckillSkus,控制台展示出自定义的受保护资源,如下:
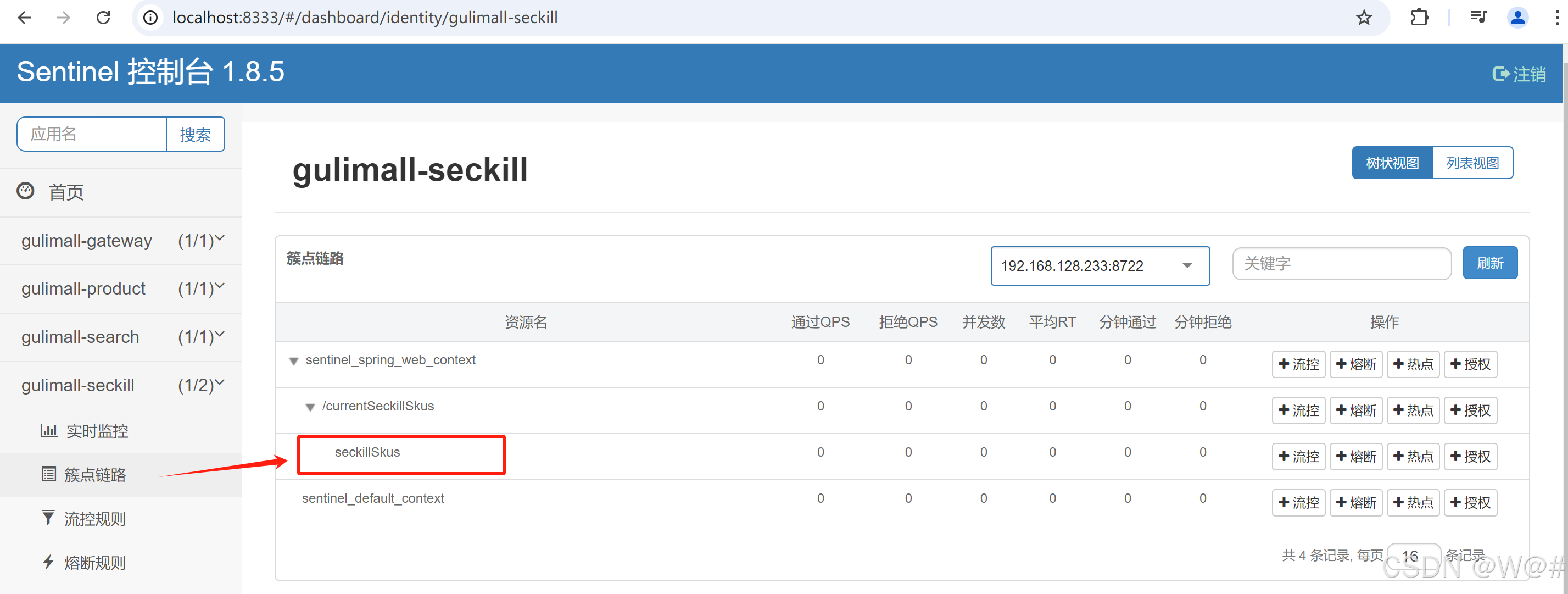
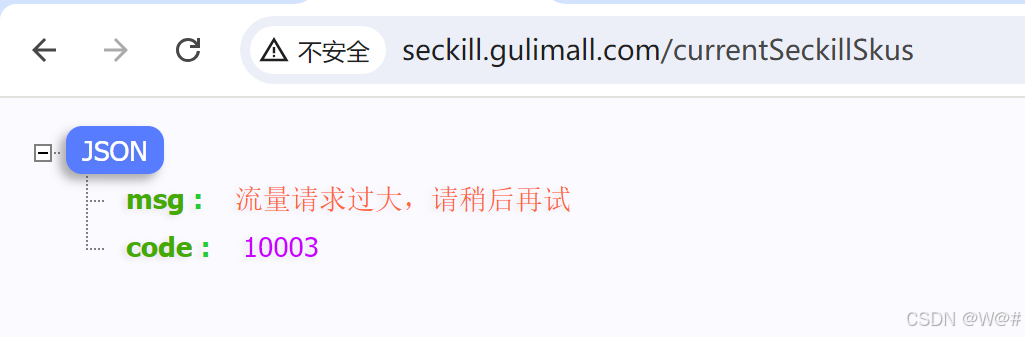
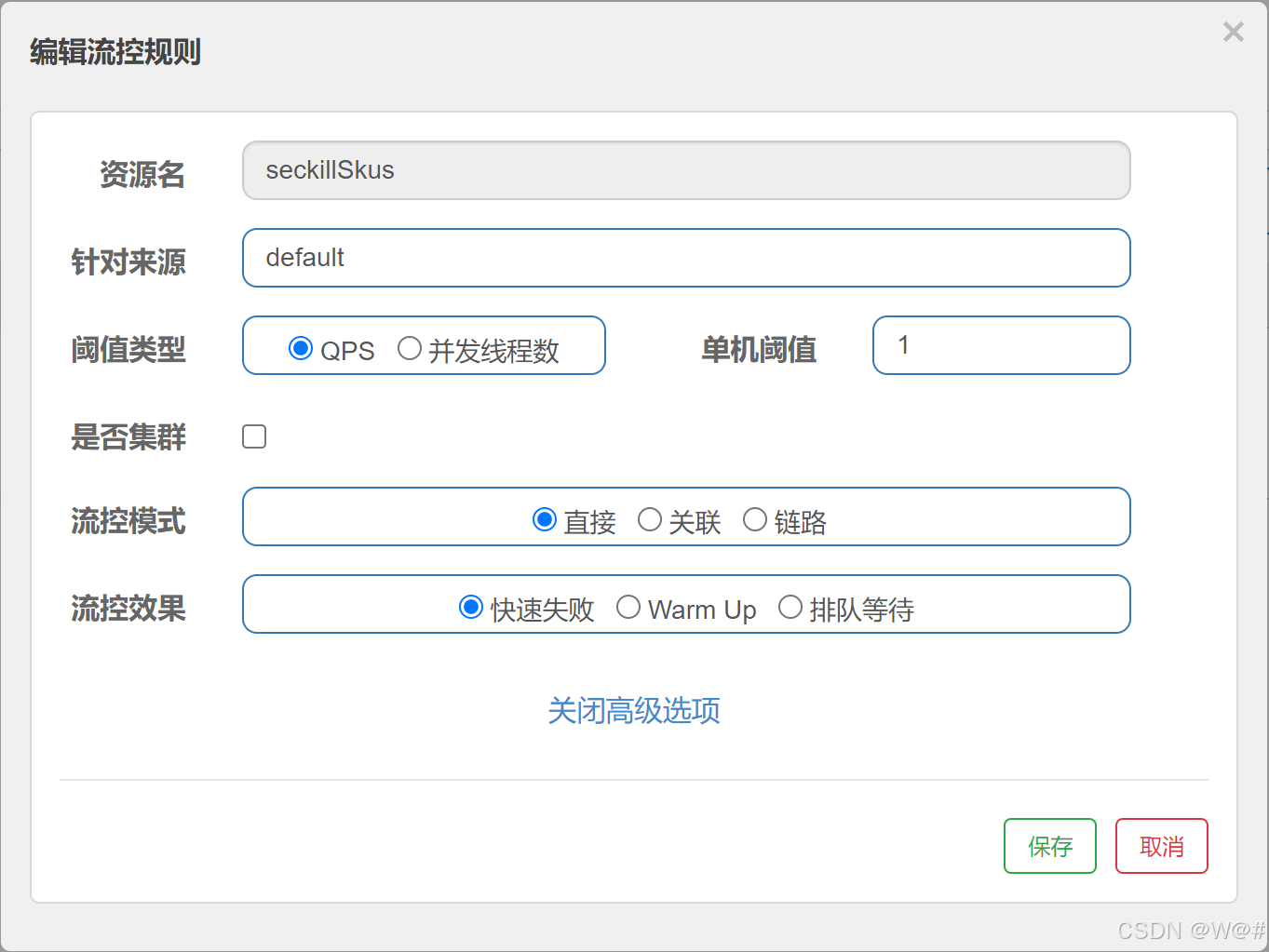
添加流控规则(每秒请求数阈值为1) ,狂刷测试如下:

2.7.3 注解的方式定义资源
Sentinel 支持通过 @SentinelResource 注解定义资源并配置 blockHandler 和 fallback 函数来进行限流之后的处理。示例:
// 原本的业务方法.
@SentinelResource(blockHandler = "blockHandlerForGetUser")
public User getUserById(String id) {
throw new RuntimeException("getUserById command failed");
}
// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用
public User blockHandlerForGetUser(String id, BlockException ex) {
return new User("admin");
}注意:blockHandler 函数会在原方法被限流/降级/系统保护的时候调用,而 fallback 函数会针对所有类型的异常。请注意 blockHandler 和 fallback 函数的形式要求,更多指引可以参见 Sentinel 注解支持文档。
2.7.3.1 @SentinelResource注解
注意:注解方式埋点不支持private方法。
@SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项@SentinelResource 注解包含以下属性:
- value:资源名称,必需项(不能为空)
- entryType:entry 类型,可选项(默认为 EntryType.OUT)
- blockHandler / blockHandlerClass: blockHandler 对应处理 BlockException 的函数名称,可选项。blockHandler 函数访问范围需要是 public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为 BlockException。blockHandler 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 blockHandlerClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。
- fallback:fallback 函数名称,可选项,用于在抛出异常的时候提供 fallback 处理逻辑。fallback 函数可以针对所有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。fallback 函数签名和位置要求:返回值类型必须与原函数返回值类型一致; 方法参数列表需要和原函数一致,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常。 fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。
- defaultFallback(since 1.6.0):默认的 fallback 函数名称,可选项,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)。默认 fallback 函数可以针对所以类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效。defaultFallback 函数签名要求:返回值类型必须与原函数返回值类型一致; 方法参数列表需要为空,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常。 defaultFallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。
- exceptionsToIgnore(since 1.6.0):用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出。
注意:1.6.0之前的版本 fallback 函数只针对降级异常(DegradeException)进行处理,不能针对业务异常进行处理。
特别地,若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出 BlockException 时只会进入 blockHandler 处理逻辑。若未配置 blockHandler、fallback 和 defaultFallback,则被限流降级时会将 BlockException 直接抛出。
示例:
public class TestService {
// 对应的 `handleException` 函数需要位于 `ExceptionUtil` 类中,并且必须为 static 函数.
@SentinelResource(value = "test", blockHandler = "handleException", blockHandlerClass = {ExceptionUtil.class})
public void test() {
System.out.println("Test");
}
// 原函数
@SentinelResource(value = "hello", blockHandler = "exceptionHandler", fallback = "helloFallback")
public String hello(long s) {
return String.format("Hello at %d", s);
}
// Fallback 函数,函数签名与原函数一致或加一个 Throwable 类型的参数.
public String helloFallback(long s) {
return String.format("Halooooo %d", s);
}
// Block 异常处理函数,参数最后多一个 BlockException,其余与原函数一致.
public String exceptionHandler(long s, BlockException ex) {
// Do some log here.
ex.printStackTrace();
return "Oops, error occurred at " + s;
}
}从 1.4.0 版本开始,注解方式定义资源支持自动统计业务异常,无需手动调用 Tracer.trace(ex) 来记录业务异常。Sentinel 1.4.0 以前的版本需要自行调用 Tracer.trace(ex) 来记录业务异常。
2.7.3.2 测试
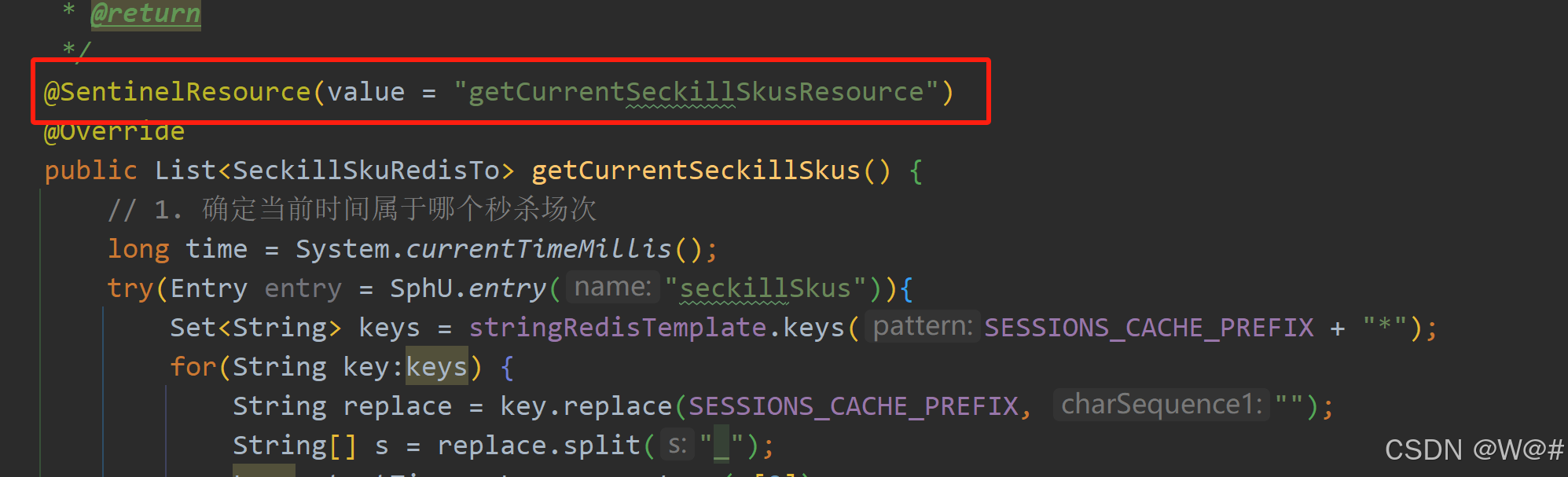
加上注解@SentinelResource,重启访问控制台就能看到
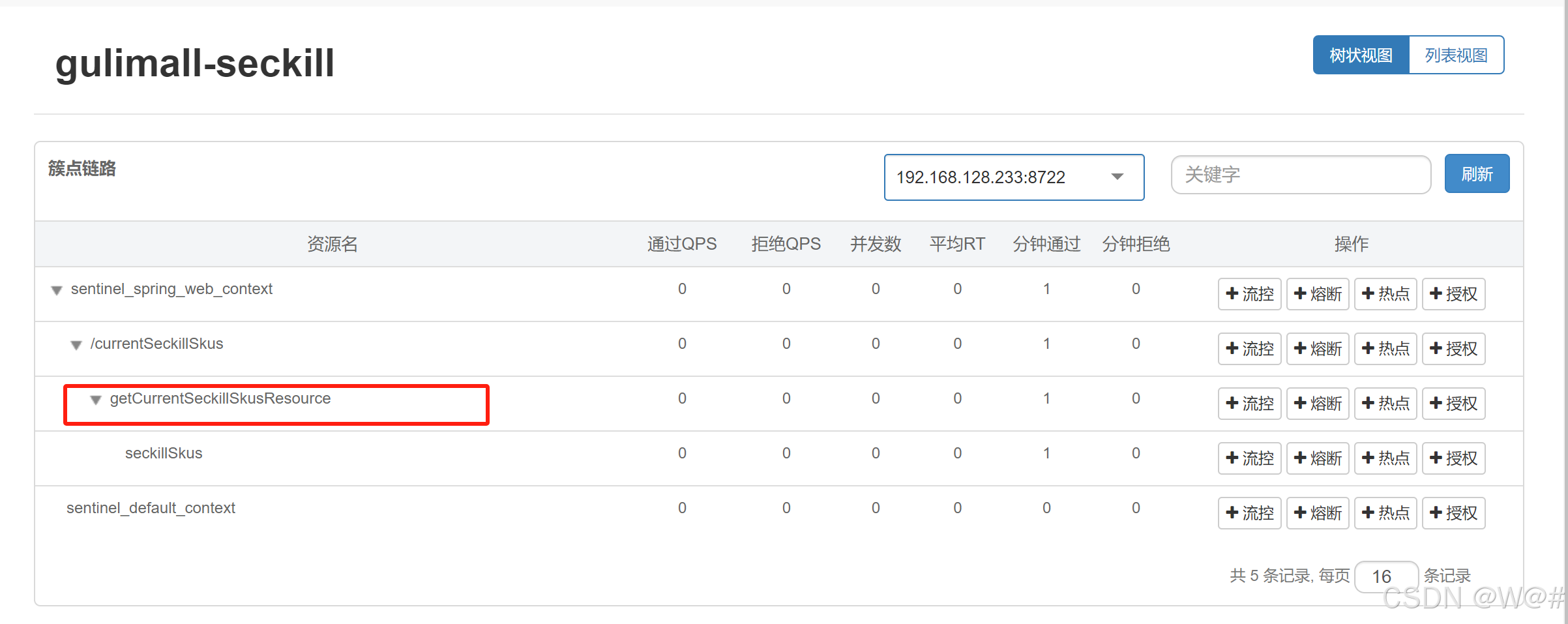
添加流控规则,狂刷测试,如下:
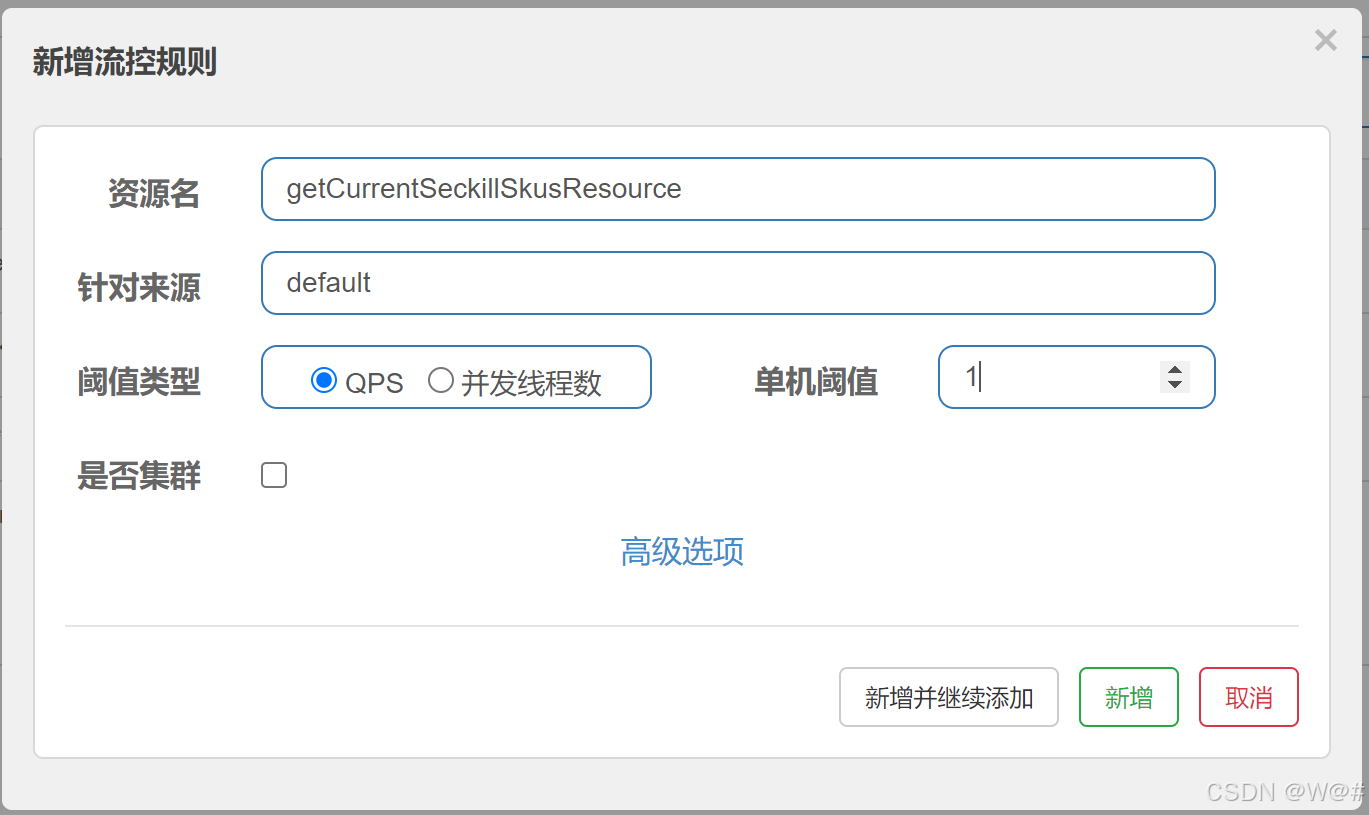
未设置处理逻辑,会报一下错误。
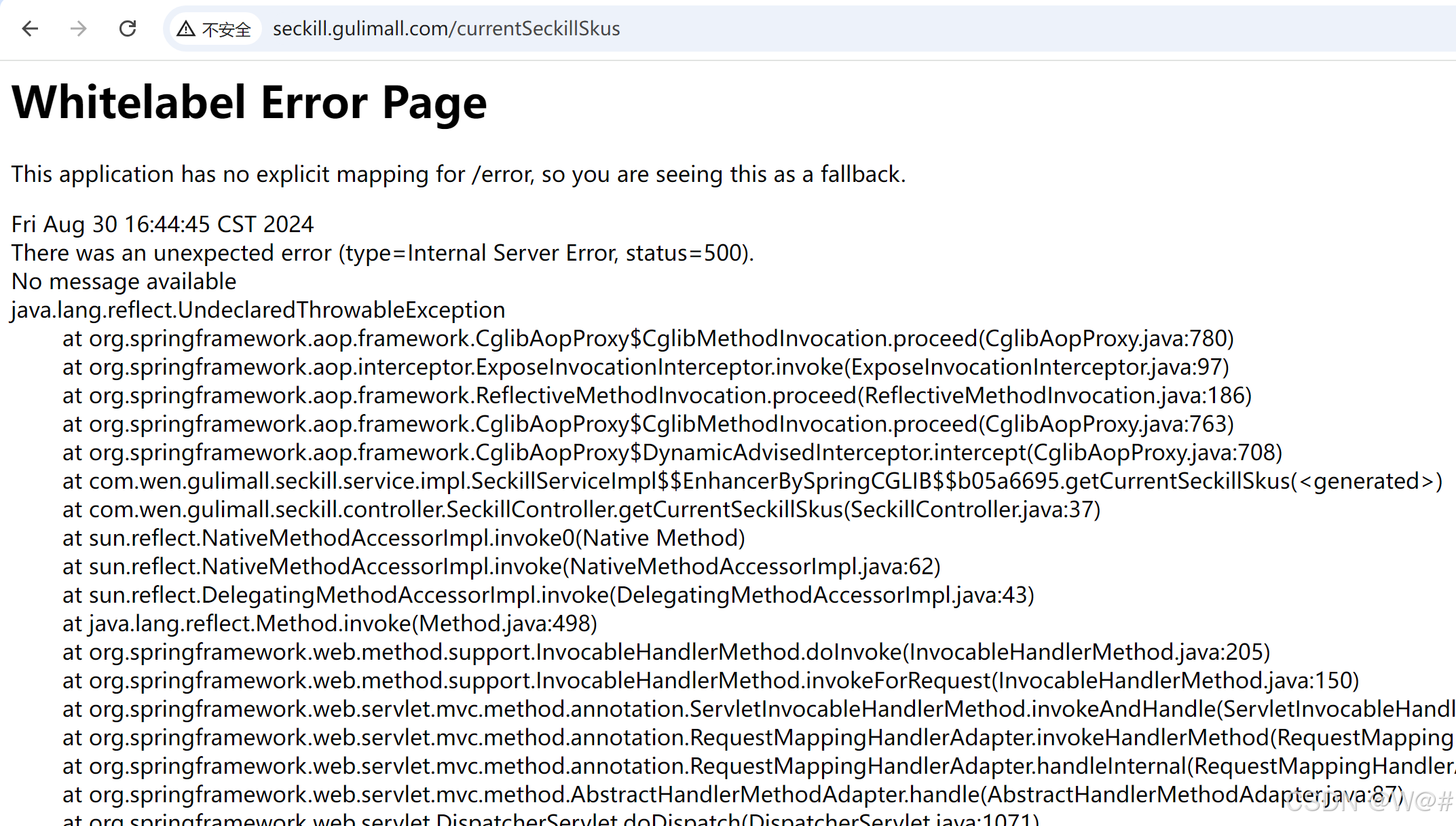
指定blockHandler,处理BlockException异常,解决以上报错问题。
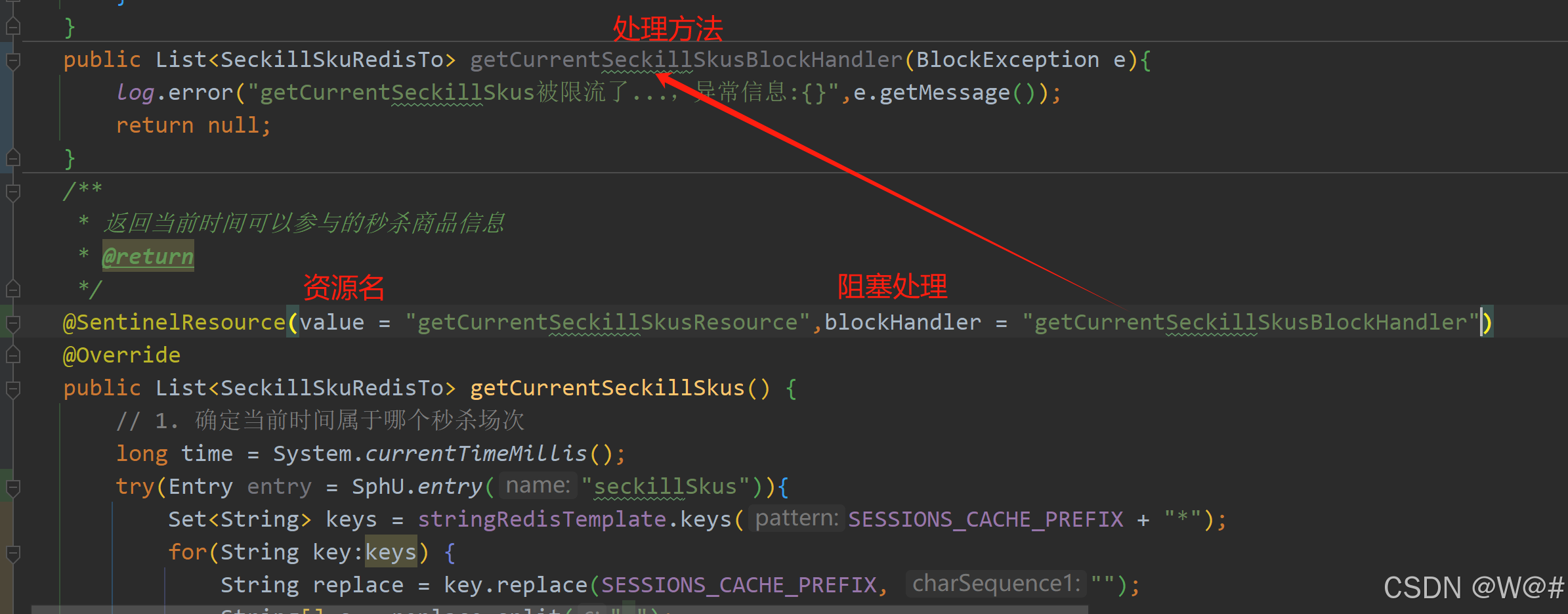
重新配置流控规则,狂刷进行限流测试,结果如下:

2.7.4 总结
无论是何种定义资源的方式,都一定要配置限流/熔断降级后的返回。
1、主流框架的默认适配(url请求)的方式可以设置统一的限制处理(implements BlockExceptionHandler),可见 2.5.6.3 或 2.6.3.2。
2、抛出异常或注解方式定义资源限流处理可参考官方文档:定义资源
2.8 网关流控
官方文档:网关流量控制
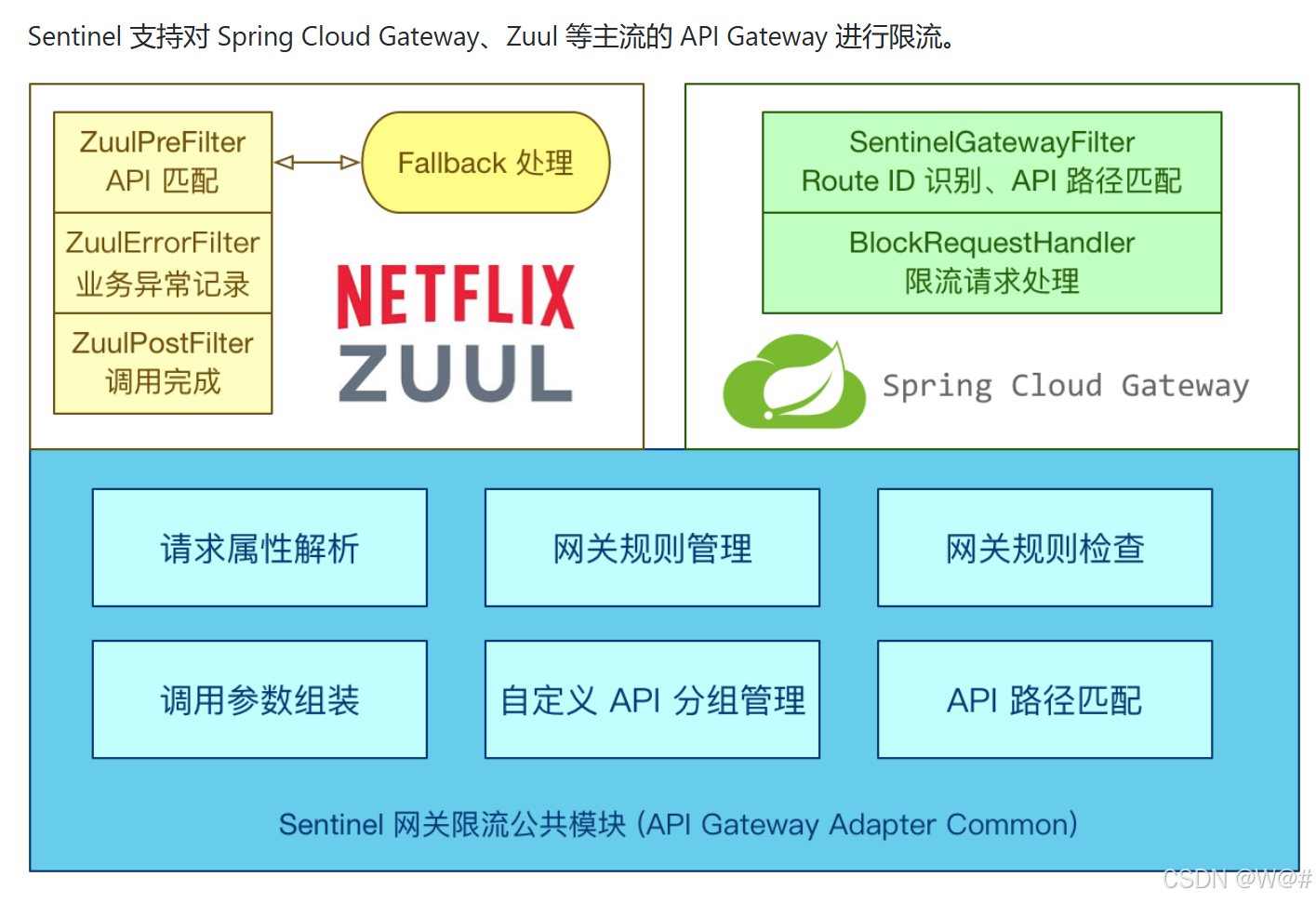
2.8.1 使用网关流控的意义
之前请求到业务服务才会进行流控,可以在网关层进行流控不用在转发到具体的业务服务,减轻业务服务的压力。
2.8.2 引入依赖
与公共模块的alibaba微服务版本保持一致
gulimall-gateway/pom.xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId>
<version>2021.0.4.0</version>
</dependency>重启网关服务、控制台服务,进入Sentinel控制台,可以看到网关的目录区别于其他微服务目录,如下图:
2.8.4 新增网关流控规则
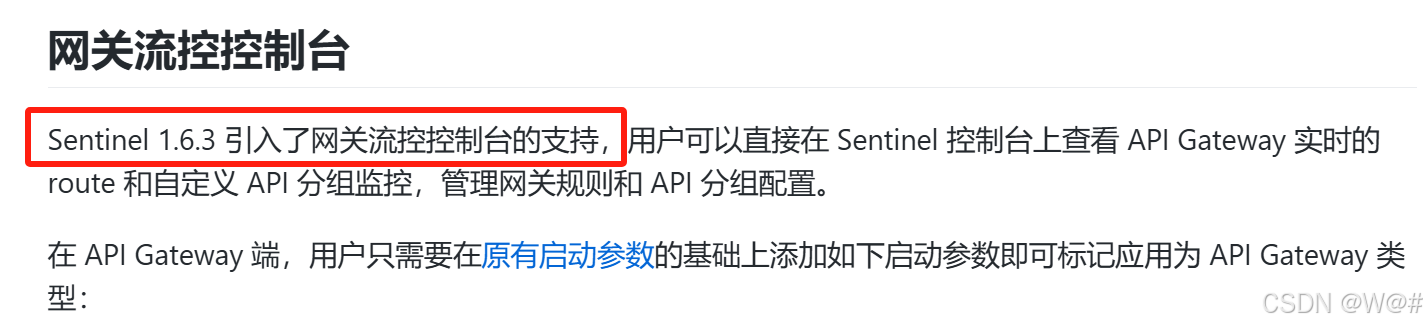
注意:Sentinel支持网关流控的版本,老师使用的是1.7.1版本的控制台,我这里使用的是1.8.5版本。
2.8.4.1 根据Route ID进行限流
对gulimall_seckill_route进行限制。
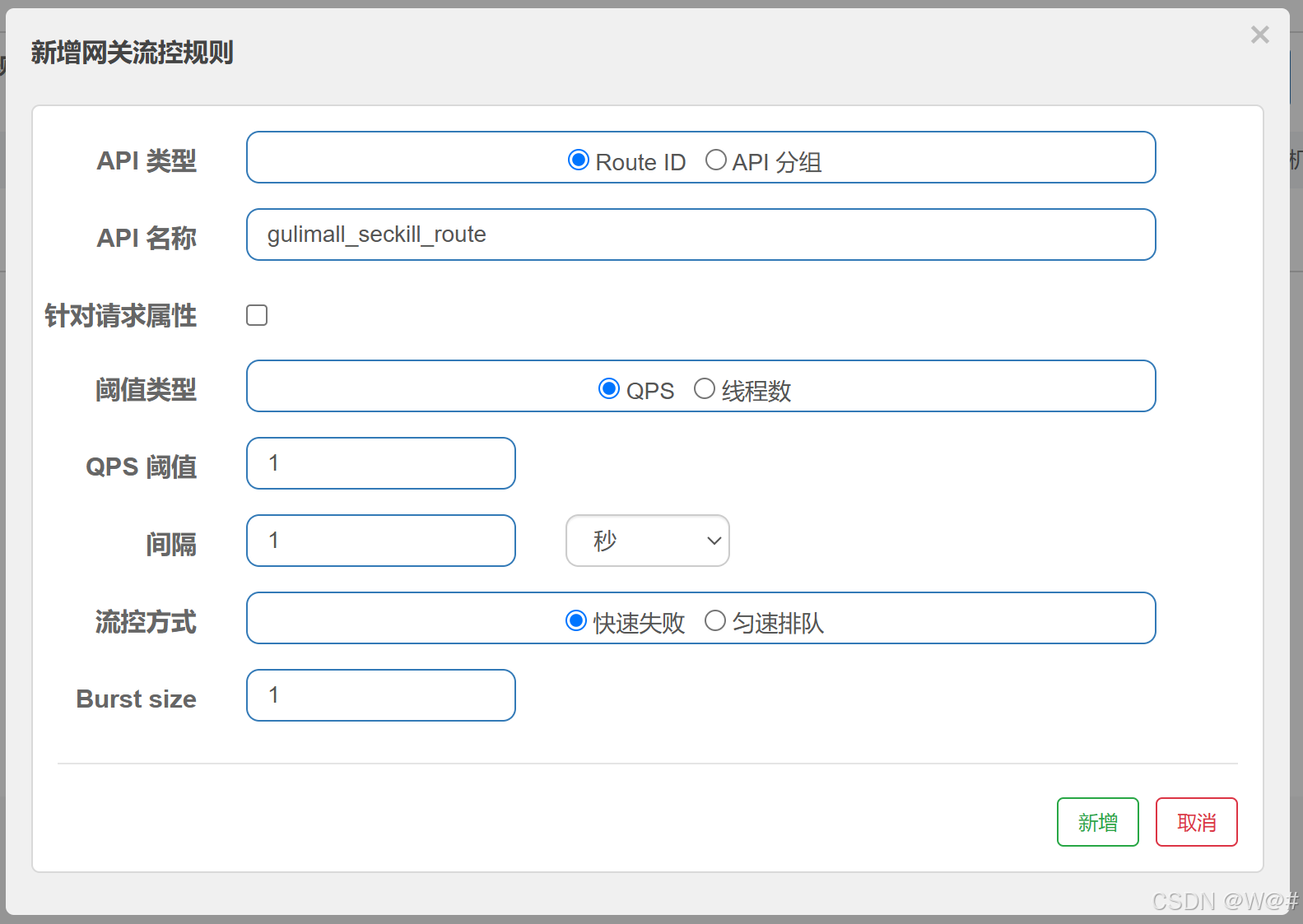
http://seckill.gulimall.com/currentSeckillSkus
快速刷新,模拟测试,结果如下:
2.8.4.2 针对请求属性进行限流
针对请求属性进行限制。
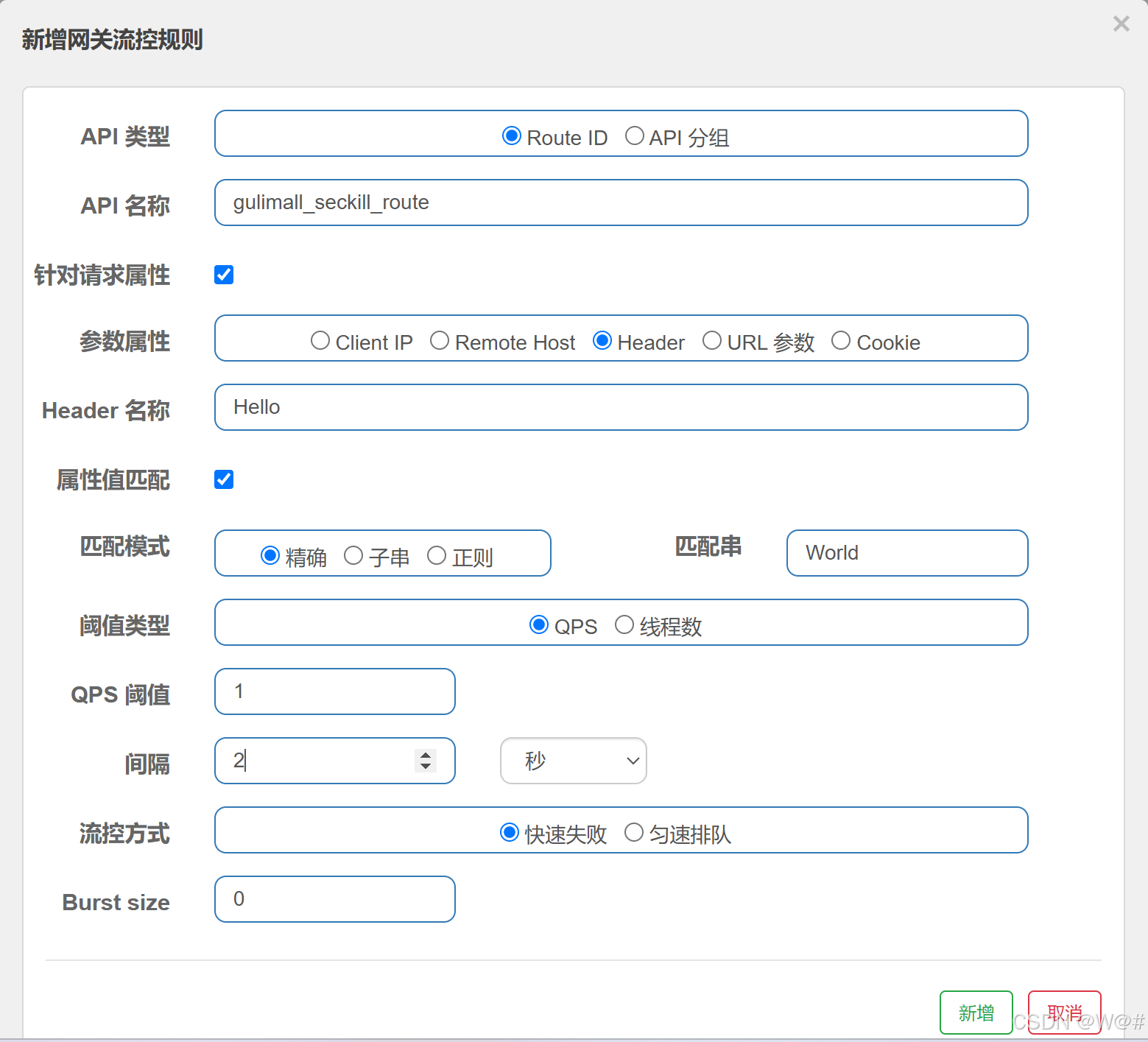
使用浏览器在没有请求头的情况下不会进行限制,使用Postman进行测试,如下:
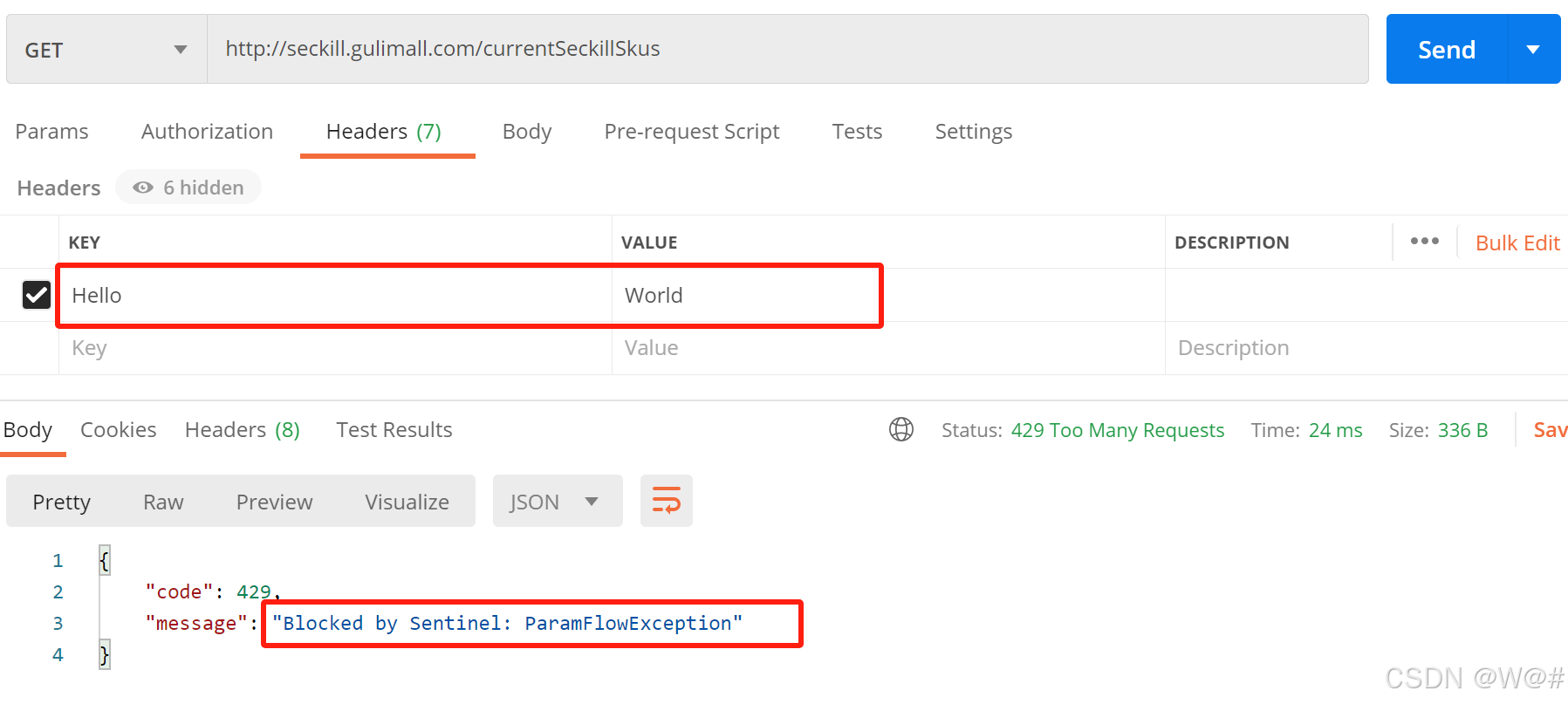
2.8.5 API分组流控
这里不做演示,可参考官方文档:网关流量控制-API分组
2.8.6 定制网关流控返回
老师使用的sentinel-core:1.6.3版本,视频中使用GatewayCallbackManager.setBlockHandler(BlockRequestHandler)自定义限流处理逻辑;我这里使用是sentinel-core:1.8.5版本,通过实现BlockRequestHandler接口,重写handleRequest()方法进行自定义限流处理。如下:
/**
* 自定义网关流控处理
*
* @author w
*/
@Component
public class GatewayBlockRequestHandler implements BlockRequestHandler {
/**
* 网关限流了请求,就会调用此回调 Mono Flux[响应式编程]
* @param serverWebExchange
* @param throwable
* @return
*/
// TODO 响应式编程
@Override
public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange, Throwable throwable) {
R error = R.error(BizCodeEnum.TOO_MANY_REQUEST.getCode(), BizCodeEnum.TOO_MANY_REQUEST.getMsg());
String errJson = JSON.toJSONString(error);
Mono<ServerResponse> body = ServerResponse.ok().body(Mono.just(errJson), String.class);
return body;
}
}添加网关流控规则,快速刷新模拟测试,结果如下:
3 Sleuth+Zipkin 服务链路追踪
Sleuth官方文档:Spring Cloud Sleuth
3.1 为什么使用
微服务架构是一个分布式架构, 它按业务划分服务单元, 一个分布式系统往往有很多个服务 单元。 由于服务单元数量众多, 业务的复杂性, 如果出现了错误和异常, 很难去定位。 主要体现在, 一个请求可能需要调用很多个服务, 而内部服务的调用复杂性, 决定了问题难以定位。 所以微服务架构中, 必须实现分布式链路追踪, 去跟进一个请求到底有哪些服务参与, 参与的顺序又是怎样的, 从而达到每个请求的步骤清晰可见, 出了问题, 很快定位。
链路追踪组件有 Google 的 Dapper, Twitter 的 Zipkin, 以及阿里的 Eagleeye (鹰眼) 等, 它 们都是非常优秀的链路追踪开源组件。
3.2 基本术语
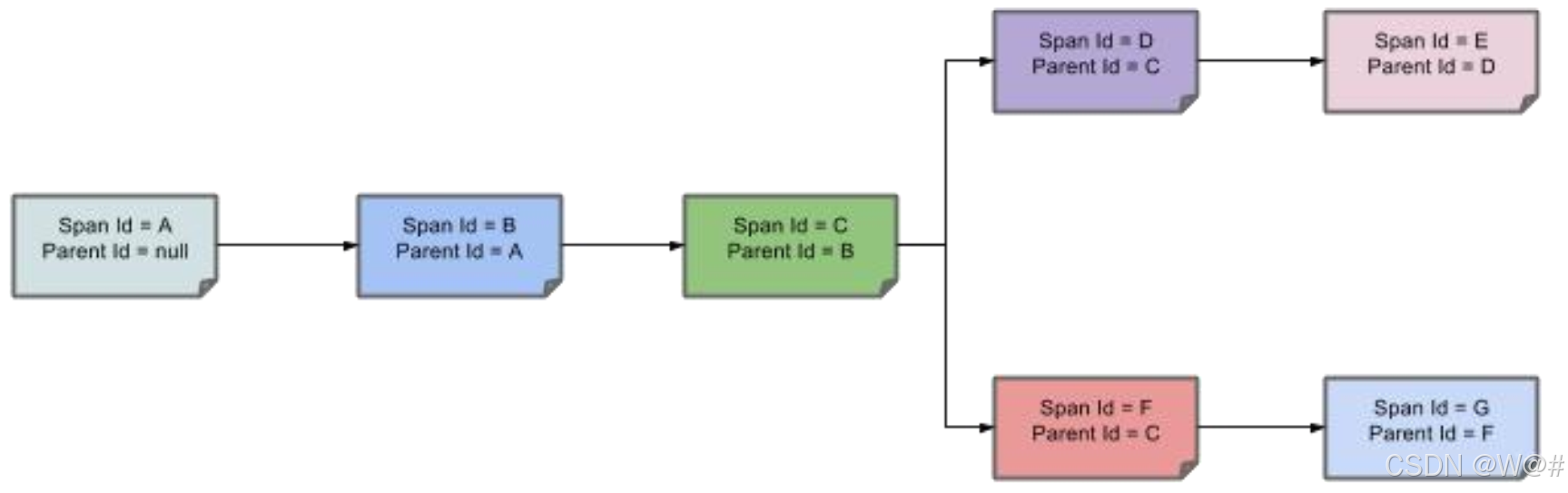
- Span(跨度) : 基本工作单元, 发送一个远程调度任务 就会产生一个 Span, Span 是一 个 64 位 ID 唯一标识的, Trace 是用另一个 64 位 ID 唯一标识的, Span 还有其他数据信 息, 比如摘要、 时间戳事件、 Span 的 ID、 以及进度 ID。
- Trace(跟踪) : 一系列 Span 组成的一个树状结构。 请求一个微服务系统的 API 接口, 这个 API 接口, 需要调用多个微服务, 调用每个微服务都会产生一个新的 Span, 所有 由这个请求产生的 Span 组成了这个 Trace。
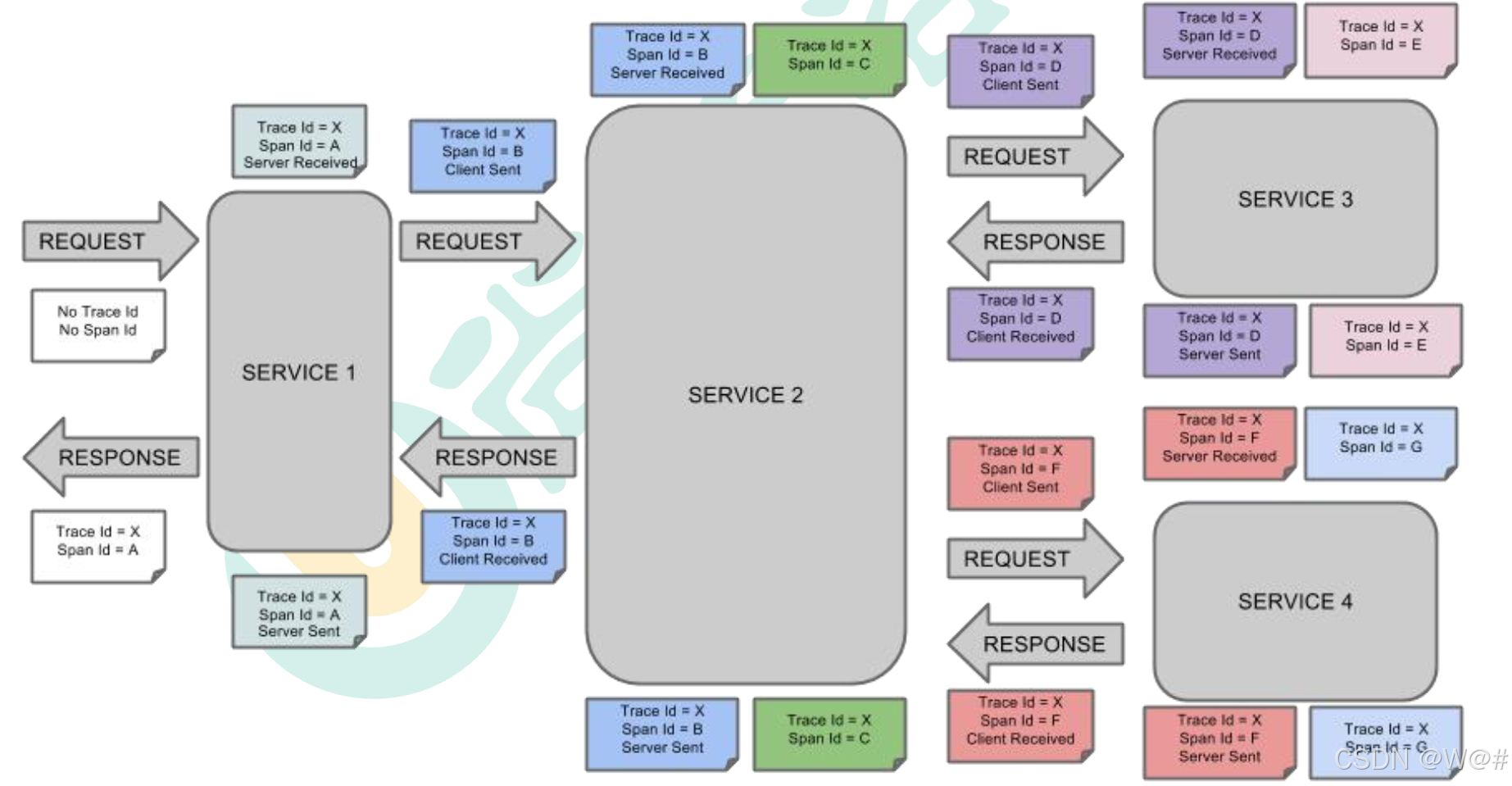
- Annotation(标注) : 用来及时记录一个事件的, 一些核心注解用来定义一个请求的开 始和结束 。 这些注解包括以下:
- cs - Client Sent -客户端发送一个请求, 这个注解描述了这个 Span 的开始。
- sr - Server Received -服务端获得请求并准备开始处理它, 如果将其 sr 减去 cs 时间戳 便可得到网络传输的时间。
- ss - Server Sent (服务端发送响应) –该注解表明请求处理的完成(当请求返回客户 端), 如果 ss 的时间戳减去 sr 时间戳, 就可以得到服务器请求的时间。
- cr - Client Received (客户端接收响应) -此时 Span 的结束, 如果 cr 的时间戳减去 cs 时间戳便可以得到整个请求所消耗的时间。
如果服务调用顺序如下:

那么用以上概念完整的表示出来如下:
Span之间的父子关系如下:
3.3 整合Sleuth
3.3.1 引入依赖
服务提供者与消费者导入依赖,放在公共模块方便使用
gulimall-common/pom.xml
<!-- 链路追踪 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>3.3.2 打开debug日志
打开gulimall-product、gulimall-seckill的日志
gulimall-product/src/main/resources/application.yml
gulimall-seckill/src/main/resources/application.yml
logging:
level:
# 打开链路追踪日志
org.springframework.cloud.openfeign: debug
org.springframework.cloud.sleuth: debug3.3.3 发起一次远程调用,观察控制台
DEBUG [user-service,541450f08573fff5,541450f08573fff5,false]
user-service: 服务名
541450f08573fff5: 是 TranceId, 一条链路中, 只有一个 TranceId
541450f08573fff5: 是 spanId, 链路中的基本工作单元 id
false: 表示是否将数据输出到其他服务, true 则会把信息输出到其他可视化的服务上观察
浏览器访问:http://item.gulimall.com/4.html ,日志如下:

3.4 整合Zipkin可视化观察
3.4.1 安装zipkin服务器
注意:docker镜像拉不下来,我这里在windows下运行zipkin服务。
- docker 安装
docker run --restart=always -d -p 9411:9411 openzipkin/zipkin- windows运行
zipkin的jar下载地址:Central Repository: io/zipkin/zipkin-server
运行命令如下:
java -jar zipkin-server-2.23.2-exec.jar
3.4.2 引入依赖
zipkin依赖也同时包含了sleuth,可以省略sleuth的引用。
gulimall-common/pom.xml
<!-- 链路追踪 -->
<!-- <dependency>-->
<!-- <groupId>org.springframework.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter-sleuth</artifactId>-->
<!-- </dependency>-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>3.4.3 添加 zipkin+sleuth 相关配置
所有需要链路追踪的服务都需要配置以下内容。
spring:
zipkin:
base-url: http://localhost:9411/ # zipkin服务器地址
# 关闭服务发现,否则SpringCloud会把zipkin的url当做服务名称
discovery-client-enabled: false
sender:
type: web # 设置使用http的方式传输数据
sleuth:
sampler:
probability: 1 # 设置抽样采集率为100%,默认为0.1,即10%3.4.4 访问zipkin
3.4.5 从商城首页跑一遍流程
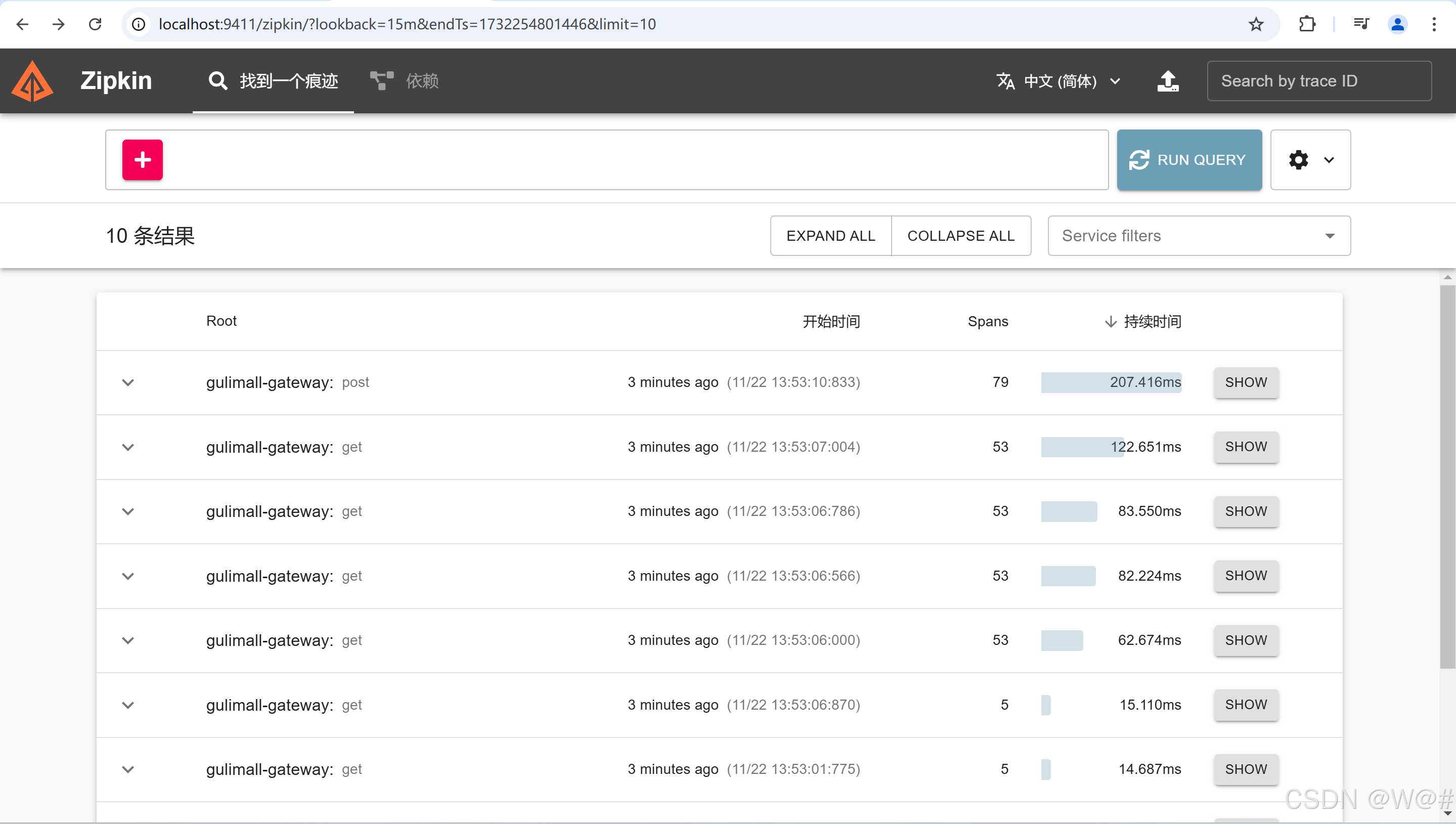
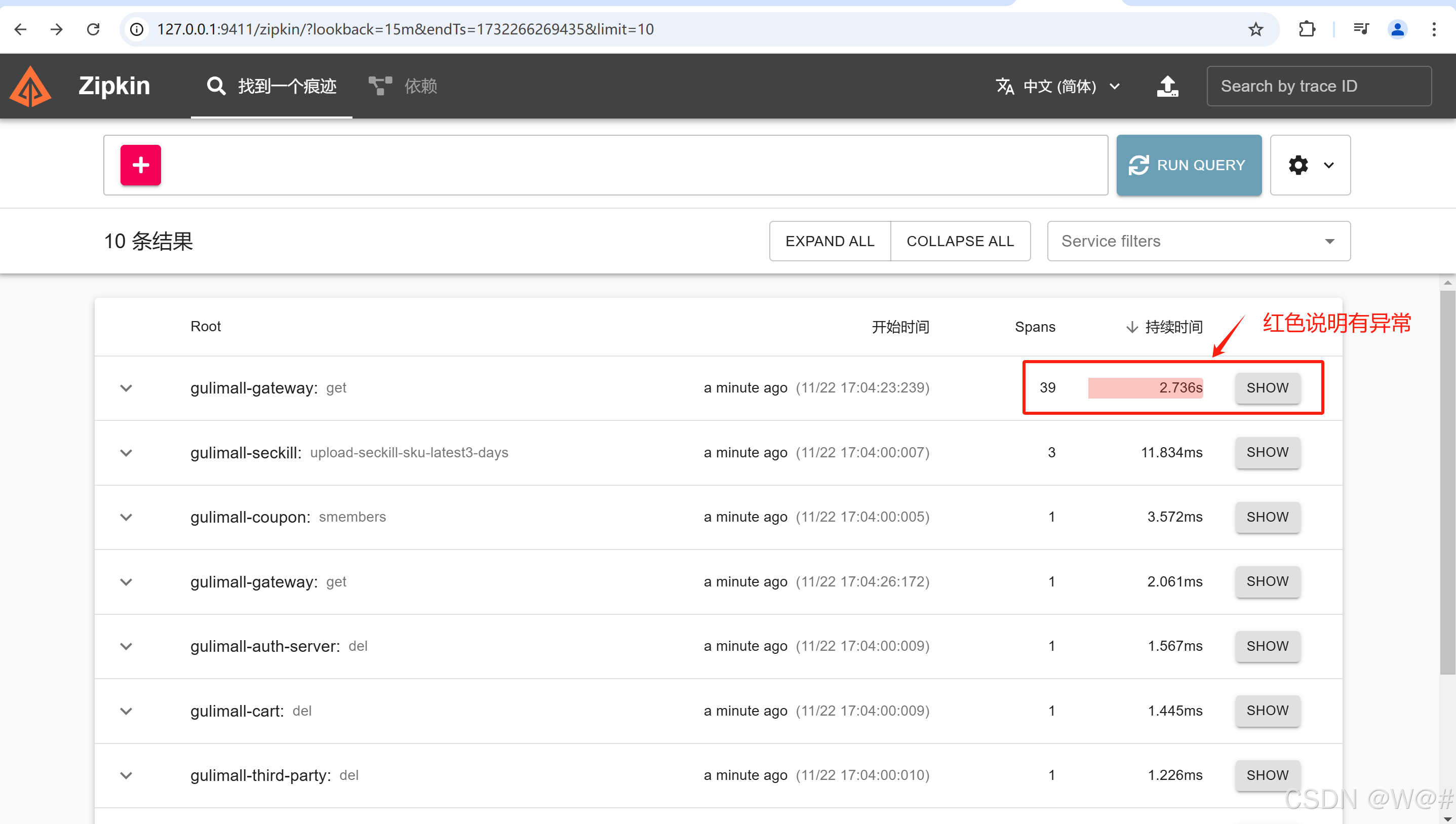
商城流程跑一边,点击RUN QUERY,出现如下画面:
点击SHOW查看对应得细节信息,如下:
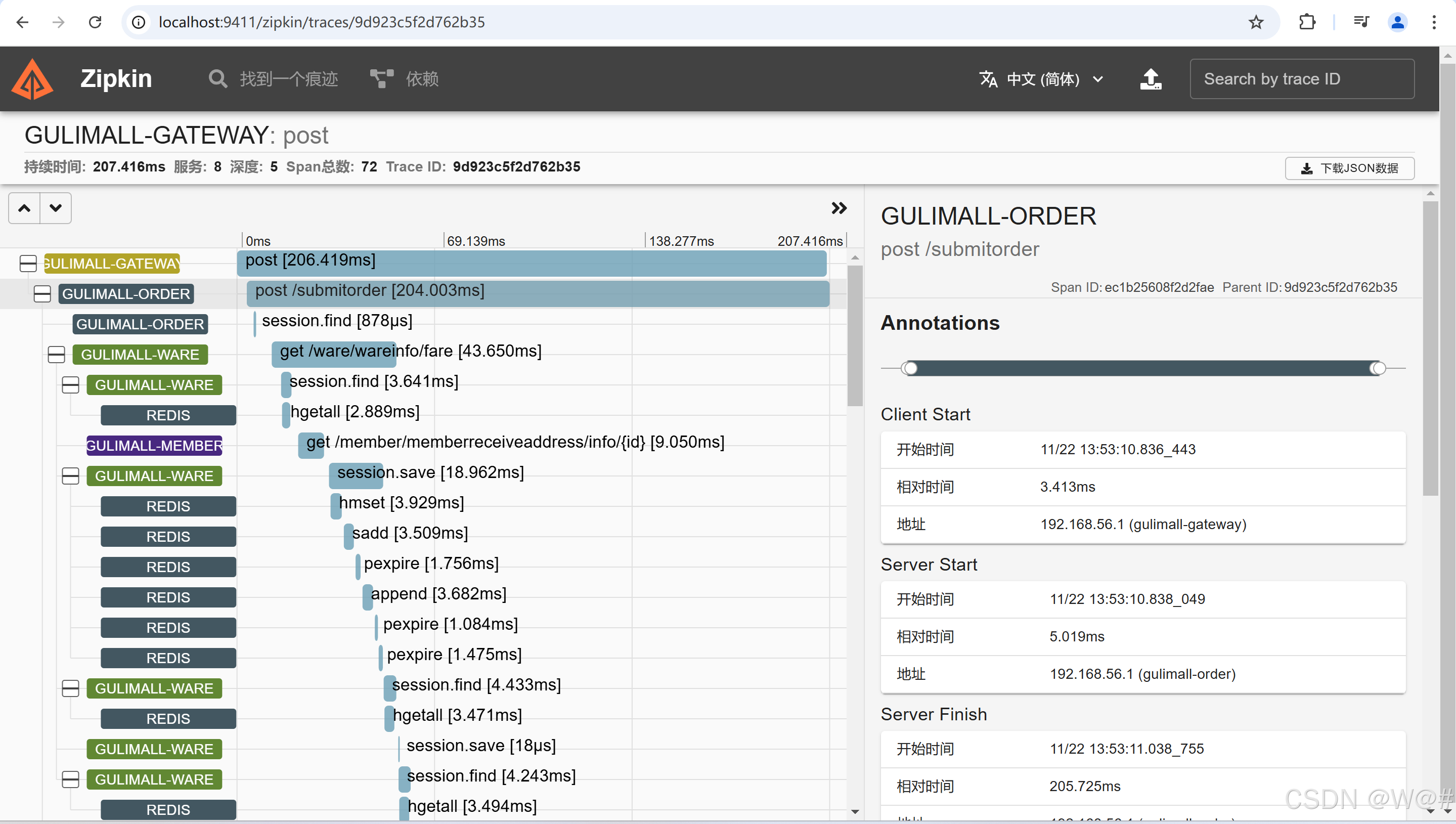
查找超过100ms的请求,看是否可以优化。
根据zipkin找到慢请求,结合sentinel进行限流、降级。
3.4.6 zipkin数据持久化
Zipkin 默认是将监控数据存储在内存的, 如果 Zipkin 挂掉或重启的话, 那么监控数据就会丢 失。 所以如果想要搭建生产可用的 Zipkin, 就需要实现监控数据的持久化。 而想要实现数据 持久化, 自然就是得将数据存储至数据库。 好在 Zipkin 支持将数据存储至:
- 内存(默认)
- MySQL
- Elasticsearch
- Cassandra
Zipkin 数据持久化相关的官方文档地址如下:
https://github.com/openzipkin/zipkin#storage-component
Zipkin 支持的这几种存储方式中, 内存显然是不适用于生产的, 这一点开始也说了。 而使用 MySQL 的话, 当数据量大时, 查询较为缓慢, 也不建议使用。 Twitter 官方使用的是 Cassandra 作为 Zipkin 的存储数据库, 但国内大规模用 Cassandra 的公司较少, 而且 Cassandra 相关文 档也不多。
综上, 故采用 Elasticsearch 是个比较好的选择, 关于使用 Elasticsearch 作为 Zipkin 的存储数 据库的官方文档如下:
elasticsearch-storage:
zipkin/zipkin-server at master · openzipkin/zipkin · GitHub
zipkin-storage/elasticsearch:zipkin/zipkin-storage/elasticsearch at master · openzipkin/zipkin · GitHub
持久到elasticsearch的命令如下:
1. windows下
java -jar zipkin-server-2.23.16-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=localhost:9200 --ES_HTTP_LOGGING=BASIC --ES_USERNAME=root --ES_PASSWORD=123456
2. docker下
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200
openzipkin/zipkin-dependencies3.5 Zipkin界面分析
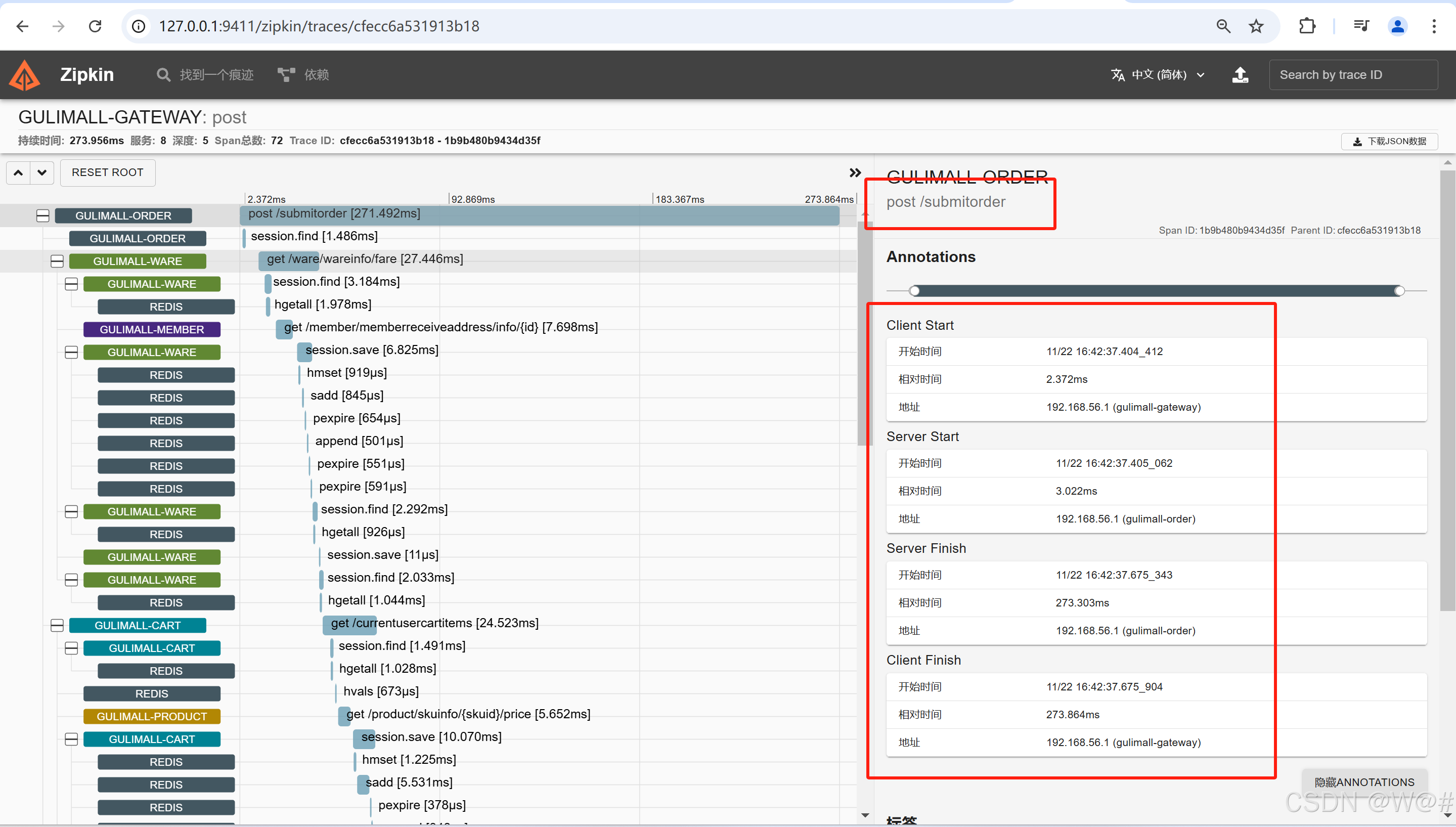
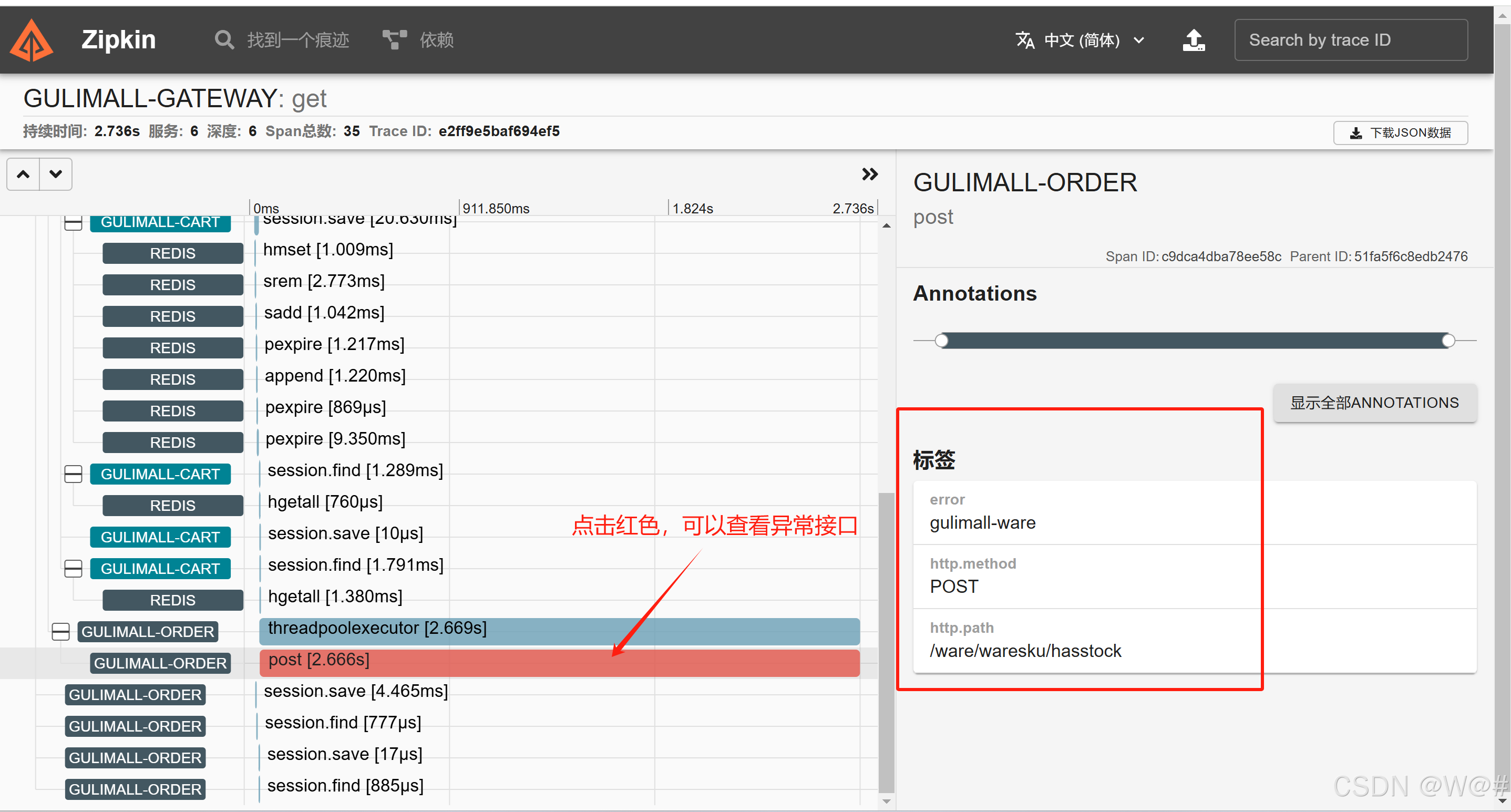
1. 以下单接口为例,如下:
gateway->order的网络传输时间=ss-cs=3.022-2.372=0.65ms;
order服务处理时间=sf-ss=273.303-3.022=270.281ms;
order->gateway的网络传输时间=cf-sf=273.864-273.303=0.561ms。
2. 停掉gulimall-ware服务,模拟库存服务宕机,如下:
4 分布式高级篇总结
- Seata不适用于高并发场景,使用柔性事务方式RabbitMQ达到最终一致性。可靠消息的保证(发送端确认和接收端确认),系统监听消息来改变数据,达到最终一致。
- 高并发中缓存是很重要的,但是缓存要考虑击穿、穿透、雪崩问题,使用分布式锁让一个线程去缓存查询不存在,再去数据库查询放到缓存,其他线程直接查询缓存。
- 定时任务使用分布式锁保证只执行一次,比如:商品定时上架有一台服务执行,其他服务不在执行。
- ElasticSearch检索引擎,分类检索、属性检索、文字检索等。
- 高并发异步是必要的,所有的异步线程通过new Thread()会导致资源耗尽,所以要使用线程池来控制资源。异步有顺序使用异步编排CompletableFuture。
- 登录。社交登录、单点登录。相同域名下一处登录,处处登录通过SpringSession实现。使用SpringSession解决了分布式系统Session不一致问题。
- 商城业务。商品上架、商品检索、商品详情(缓存到Redis/SpringCache解决缓存不一致问题)、下单、秒杀。
- 分布式事务最终一致RabbitMQ是一个必要的工具。
- 秒杀使用RabbitMQ进行流量削峰处理,后台慢慢进行消费。
- 使用RabbitMQ进行应用解耦。
- 关单使用RabbitMQ的死信队列。
- SpringCloud的组件都要掌握。
- Sentinel和Sleuth+Zipkin搭配使用。Sleuth追踪服务的运行情况,挑出异常问题使用Sentinel进行限流降级来保护服务。
- 高并发有三宝:缓存、异步、排队好。