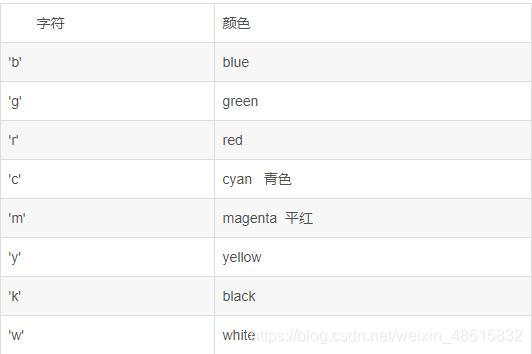
1.matplotlib模块
应用matplotlib模块绘制条形图,需要调用bar函数,关于该函数的语法和参数含义如下:
bar(x, height, width=0.8, bottom=None, color=None, edgecolor=None,
linewidth=None, tick_label=None, xerr=None, yerr=None,
label = None, ecolor=None, align, log=False, **kwargs)
- x:传递数值序列,指定条形图中x轴上的刻度值。
- height:传递数值序列,指定条形图y轴上的高度。
- width:指定条形图的宽度,默认为0.8。 bottom:用于绘制堆叠条形图。
- color:指定条形图的填充色。
- edgecolor:指定条形图的边框色。
- linewidth:指定条形图边框的宽度,如果指定为0,表示不绘制边框。
- tick_label:指定条形图的刻度标签。
- xerr:如果参数不为None,表示在条形图的基础上添加误差棒。
- yerr:参数含义同xerr。
- label:指定条形图的标签,一般用以添加图例。
- ecolor:指定条形图误差棒的颜色。
- align:指定x轴刻度标签的对齐方式,默认为center,表示刻度标签居中对齐,如果设置为edge,则表示在每个条形的左下角呈现刻度标签。
- log:bool类型参数,是否对坐标轴进行log变换,默认为False。
- **kwargs:关键字参数,用于对条形图进行其他设置,如透明度等。
bar函数的参数同样很多,希望读者能够认真地掌握每个参数的含义,以便使用时得心应手。下面将基于该函数绘制三类条形图,分别是单变量的垂直或水平条形图、堆叠条形图和水平交错条形图。
(1)垂直或水平条形图
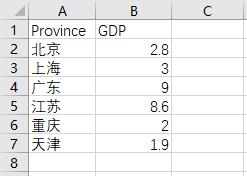
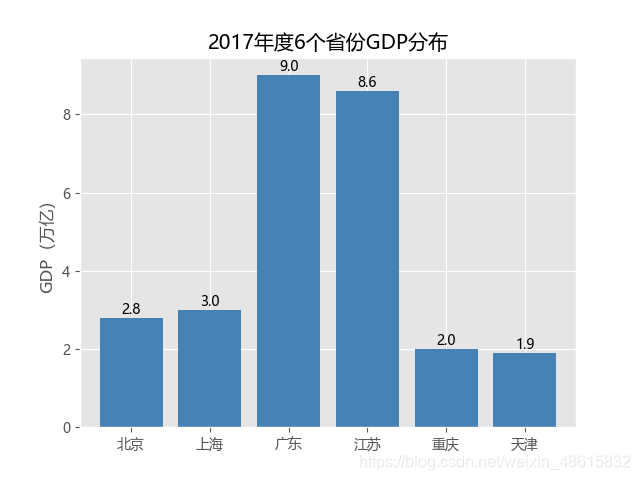
首先来绘制单个离散变量的垂直或水平条形图,数据来源于互联网,反映的是2017年中国六大省份的GDP:
垂直条形图
# 绘图 x= 起始位置, bottom= 水平条的底部(左侧), y轴, height 水平条的宽度, width 水平条的长度
p1 = plt.bar(x=0, bottom=y, height=0.5, width=x, orientation="horizontal")
绘图代码如下:
import matplotlib.pyplot as plt
import pandas as pd
GDP_data = pd.read_excel(r'GDP.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#绘制条形图
plt.bar(x = range(GDP_data.shape[0]), #指定条形图x轴的刻度值(有的是用left,有的要用x)
height = GDP_data.GDP, #指定条形图y轴的数值(python3.7不能用y,而应该用height)
tick_label = GDP_data.Province, #指定条形图x轴的刻度标签
color = 'steelblue', #指定条形图的填充色
)
#添加y轴的标签
plt.ylabel('GDP(万亿)')
#添加条形图的标题
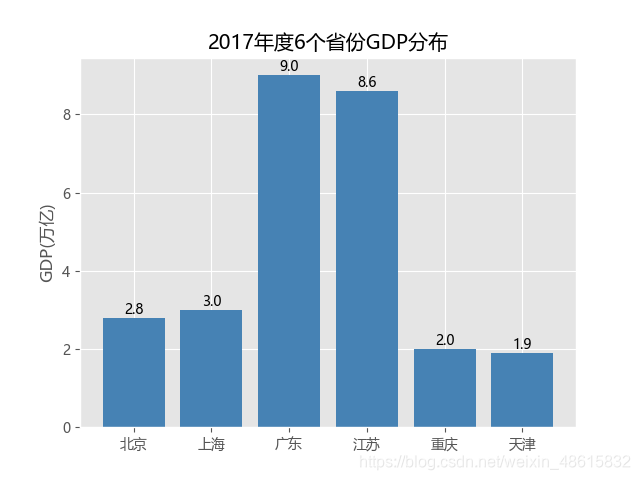
plt.title('2017年度6个省份GDP分布')
#为每个条形图添加数值标签
for x,y in enumerate(GDP_data.GDP):
plt.text(x,y+0.1,"%s"%round(y,1),ha='center') #round(y,1)是将y值四舍五入到一个小数位
#显示图形
plt.show()
如图6-5所示,该条形图比较清晰地反映了6个省份GDP的差异。针对如上代码需要做几点解释:
- 条形图中灰色网格的背景是通过代码plt.style.use(‘ggplot’)实现的,如果不添加该行代码,则条形图为白底背景。
- 如果添加图形的x轴或y轴标签,需要调用pyplot子模块中的xlab和ylab函数。
- 由于bar函数没有添加数值标签的参数,因此使用for循环对每一个柱体添加数值标签,使用的核心函数是pyplot子模块中的text。该函数的参数很简单,前两个参数用于定位字符在图形中的位置,第三个参数表示呈现的具体字符值,第四个参数为ha,表示字符的水平对齐方式为居中对齐。
水平条形图
水平条形图不再是bar函数,而是barh函数。
# 绘图 y= y轴, left= 水平条的底部, height 水平条的宽度, width 水平条的长度
p1 = plt.barh(y, left=0, height=0.5, width=x)
绘图代码:
import matplotlib.pyplot as plt
import pandas as pd
GDP_data = pd.read_excel(r'GDP.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#对读入的数据做升序排序
GDP_data.sort_values(by='GDP', inplace=True)
#绘制条形图
plt.barh(y = range(GDP_data.shape[0]), #指定条形图y轴的刻度值
width = GDP_data.GDP, #指定条形图x轴的数值
tick_label = GDP_data.Province, #指定条形图y轴的刻度标签
color = 'lightblue', #指定条形图的填充色
)
#添加x轴的标签
plt.xlabel('GDP(万亿)')
#添加条形图的标题
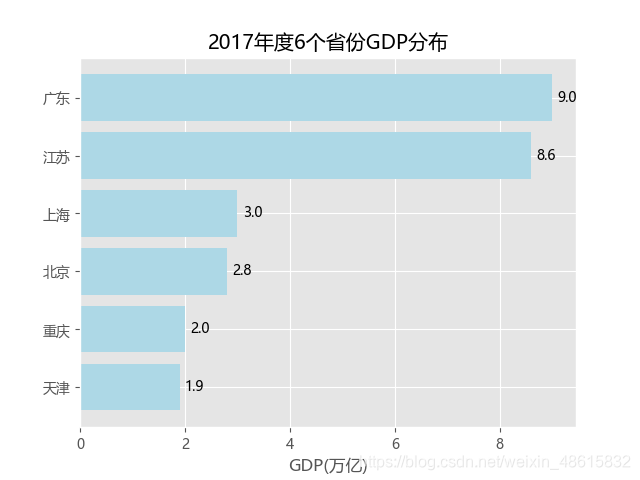
plt.title('2017年度6个省份GDP分布')
#为每个条形图添加数值标签
for y,x in enumerate(GDP_data.GDP):
plt.text(x+0.1,y,"%s"%round(x,1),va='center') #round(y,1)是将y值四舍五入到一个小数位
#显示图形
plt.show()
(2)堆叠条形图
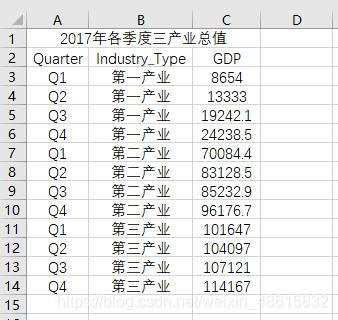
正如前文所介绍的,不管是垂直条形图还是水平条形图,都只是反映单个离散变量的统计图形,如果想通过条形图传递两个离散变量的信息该如何做到?相信读者一定见过堆叠条形图,该类型条形图的横坐标代表一个维度的离散变量,堆叠起来的“块”代表了另一个维度的离散变量。这样的条形图,最大的优点是可以方便比较累积和,那这种条形图该如何通过Python绘制呢?这里以2017年四个季度的产业值为例(数据来源于中国统计局):
绘制堆叠条形图,详细代码如下:
import matplotlib.pyplot as plt
import pandas as pd
Industry_GDP = pd.read_excel(r'2017年各季度三产业总值.xlsx',skiprows=1) #skiprows=1 :读取数据时,指定跳过的开始行数(这里我用它来跳过表头)
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#取出四个不同的季度标签,用作堆叠条形图x轴的刻度标签
Quarters = Industry_GDP.Quarter.unique() #unique()起去重的作用
#取出第一产业的四季度值
Industry1 = Industry_GDP.GDP[Industry_GDP.Industry_Type == '第一产业']
#重新设置行索引
Industry1.index = range(len(Quarters))
#取出第二产业的四季度值
Industry2 = Industry_GDP.GDP[Industry_GDP.Industry_Type == '第二产业']
#重新设置行索引
Industry2.index = range(len(Quarters))
#取出第三产业的四季度值
Industry3 = Industry_GDP.GDP[Industry_GDP.Industry_Type == '第三产业']
#重新设置行索引
Industry3.index = range(len(Quarters))
#绘制堆叠条形图
#各季度下第一产业的条形图
plt.bar(x = range(len(Quarters)), #指定条形图x轴的刻度值
height = Industry1, #指定条形图y轴的数值
bottom = 0, #用于绘制堆叠条形图,图形起始高度
tick_label = Quarters, #指定条形图y轴的刻度标签
color = 'steelblue', #指定条形图的填充色
label = '第一产业', #图形的标签
)
#各季度下第二产业的条形图
plt.bar(x = range(len(Quarters)), #指定条形图x轴的刻度值
height = Industry2, #指定条形图y轴的数值
bottom = Industry1,
tick_label = Quarters, #指定条形图y轴的刻度标签
color = 'green', #指定条形图的填充色
label = '第二产业', #图形的标签
)
#各季度下第三产业的条形图
plt.bar(x = range(len(Quarters)), #指定条形图x轴的刻度值
height = Industry3, #指定条形图y轴的数值
bottom = Industry1+Industry2,
tick_label = Quarters, #指定条形图y轴的刻度标签
color = 'red', #指定条形图的填充色
label = '第三产业', #图形的标签
)
#添加y轴的标签
plt.ylabel('GDP(亿)')
#添加图形标题
plt.title('2017年各季度三产业总值')
#显示各产业的图例
plt.legend()
#显示图形
plt.show()
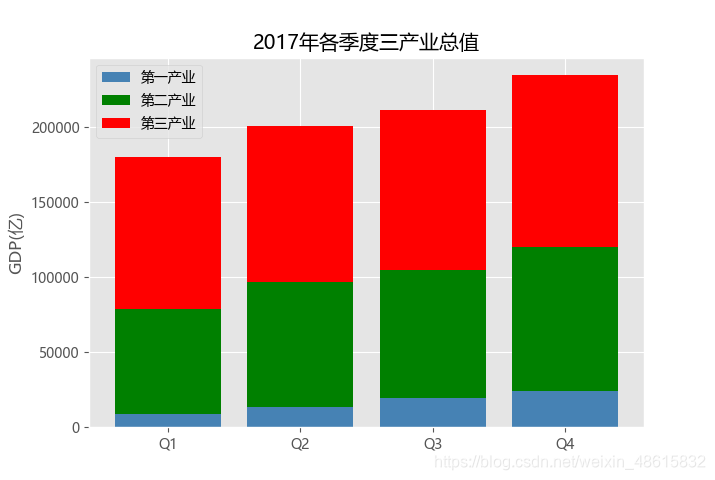
如上就是一个典型的堆叠条形图,虽然绘图的代码有些偏长,但是其思想还是比较简单的,就是分别针对三种产业的产值绘制三次条形图。需要注意的是,第二产业的条形图是在第一产业的基础上做了叠加,故需要将bottom参数设置为Industry1;而第三产业的条形图又是叠加在第一和第二产业之上,所以需要将bottom参数设置为Industry1+ Industry2。
读者可能疑惑,通过条件判断将三种产业的值(Industry1、Industry2、Industry3)分别取出来后,为什么还要重新设置行索引?那是因为各季度下每一种产业值前的行索引都不相同,这就导致无法进行Industry1+ Industry2的和计算(读者不妨试试不改变序列Industry1和Industry2的行索引的后果)。
(3)水平交错条形图
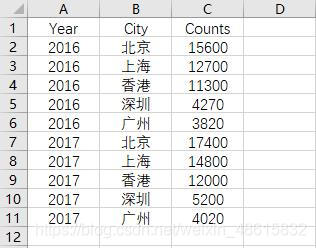
堆叠条形图可以包含两个离散变量的信息,而且可以比较各季度整体产值的高低水平,但是其缺点是不易区分“块”之间的差异,例如二、三季度的第三产业值差异就不是很明显,区分高低就相对困难。而交错条形图恰好就可以解决这个问题,该类型的条形图就是将堆叠的“块”水平排开,如想绘制这样的条形图,可以参考下方代码(数据来源于胡润财富榜,反映的是5个城市亿万资产超高净值家庭数):
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 读入数据
HuRun = pd.read_excel(r'亿万资产家庭数.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 取出城市名称
Cities = HuRun.City.unique()
# 取出2016年各城市亿万资产家庭数
Counts2016 = HuRun.Counts[HuRun.Year == 2016]
# 取出2017年各城市亿万资产家庭数
Counts2017 = HuRun.Counts[HuRun.Year == 2017]
# 绘制水平交错条形图
bar_width = 0.4
plt.bar(x = np.arange(len(Cities)), height = Counts2016, label = '2016', color = 'steelblue', width = bar_width)
plt.bar(x = np.arange(len(Cities))+bar_width, height = Counts2017, label = '2017', color = 'indianred', width = bar_width)
# 添加x轴刻度标签(向右偏移0.225)
plt.xticks(np.arange(5)+0.2, Cities)
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
# 添加图形标题
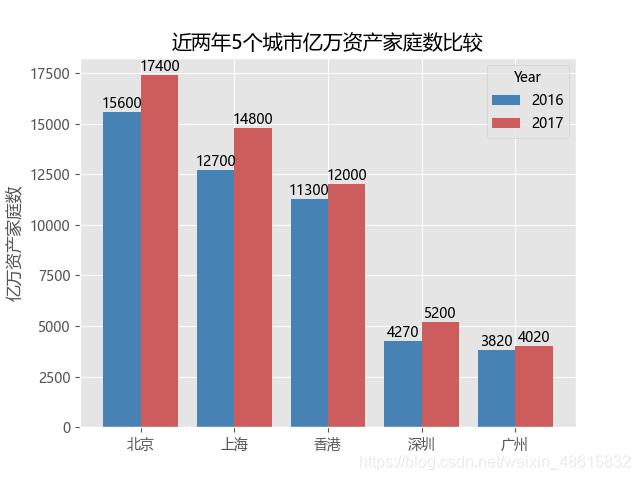
plt.title('近两年5个城市亿万资产家庭数比较')
# 添加图例
plt.legend()
# 显示图形
plt.show()
我们发现,这些图上面缺少数值标签,所以进行改进:
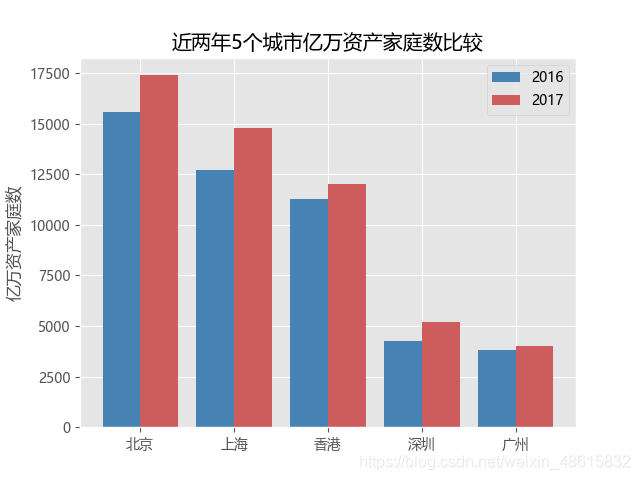
# 条形图的绘制--水平交错条形图
# 导入第三方模块
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 读入数据
HuRun = pd.read_excel(r'亿万资产家庭数.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 取出城市名称
Cities = HuRun.City.unique()
# 取出2016年各城市亿万资产家庭数
Counts2016 = HuRun.Counts[HuRun.Year == 2016]
# 取出2017年各城市亿万资产家庭数
Counts2017 = HuRun.Counts[HuRun.Year == 2017]
# 绘制水平交错条形图
bar_width = 0.4
plt.bar(x = np.arange(len(Cities)), height = Counts2016, label = '2016', color = 'steelblue', width = bar_width)
plt.bar(x = np.arange(len(Cities))+bar_width, height = Counts2017, label = '2017', color = 'indianred', width = bar_width)
# 添加x轴刻度标签(向右偏移0.225)
plt.xticks(np.arange(5)+0.2, Cities)
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
# 添加图形标题
plt.title('近两年5个城市亿万资产家庭数比较')
#为每个条形图添加数值标签
for x,y in enumerate(Counts2016):
plt.text(x,y+200,"%s"%round(y,1),ha='center') #round(y,1)是将y值四舍五入到一个小数位
for x,y in enumerate(Counts2017):
plt.text(x+bar_width,y+200,"%s"%round(y,1),ha='center')
# 添加图例
plt.legend()
# 显示图形
plt.show()
另外,再对如上的代码做三点解释,希望能够帮助读者解去疑惑:
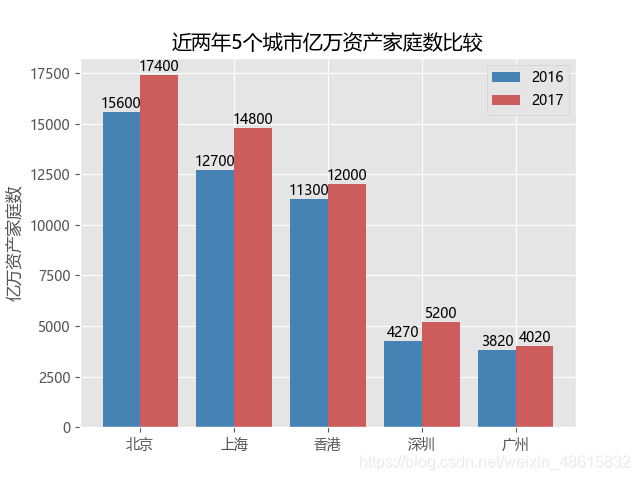
- 如上的水平交错条形图,其实质就是使用两次bar函数,所不同的是,第二次bar函数使得条形图往右偏了0.4个单位(left=np.arange(len(Cities))+bar_width),进而形成水平交错条形图的效果。
- 每一个bar函数,都必须控制条形图的宽度(width=bar_width),否则会导致条形图的重叠。
- 如果利用bar函数的tick_label参数添加条形图x轴上的刻度标签,会发现标签并不是居中对齐在两个条形图之间,为了克服这个问题,使用了pyplot子模块中的xticks函数,并且使刻度标签的位置向右移0.2个单位。
2.pandas模块
通过pandas模块绘制条形图仍然使用plot方法,该“方法”的语法和参数含义在之前已经详细介绍过,但是plot方法存在一点瑕疵,那就是无法绘制堆叠条形图。下面通过该模块的plot方法绘制单个离散变量的垂直条形图或水平条形图以及两个离散变量的水平交错条形图。
(1)垂直或水平条形图
代码如下:
import matplotlib.pyplot as plt
import pandas as pd
GDP_data = pd.read_excel(r'GDP.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 绘图
GDP_data.GDP.plot(kind = 'bar', width = 0.8, rot = 0, color = 'steelblue', title = '2017年度6个省份GDP分布')
# 添加y轴标签
plt.ylabel('GDP(万亿)')
# 添加x轴刻度标签
plt.xticks(range(len(GDP_data.Province)), #指定刻度标签的位置
GDP_data.Province # 指出具体的刻度标签值
)
# 为每个条形图添加数值标签
for x,y in enumerate(GDP_data.GDP):
plt.text(x,y+0.1,'%s' %round(y,1),ha='center')
# 显示图形
plt.show()
只要掌握matplotlib模块绘制单个离散变量的条形图方法,就可以套用到pandas模块中的plot方法,两者是相通的。
(2)水平交错条形图
import matplotlib.pyplot as plt
import pandas as pd
# 读入数据
HuRun = pd.read_excel(r'亿万资产家庭数.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# Pandas模块之水平交错条形图
HuRun_reshape = HuRun.pivot_table(index = 'City', columns='Year', values='Counts').reset_index()
# 对数据集降序排序
HuRun_reshape.sort_values(by = 2016, ascending = False, inplace = True)
HuRun_reshape.plot(x = 'City', y = [2016,2017], kind = 'bar', color = ['steelblue', 'indianred'],
rot = 0, # 用于旋转x轴刻度标签的角度,0表示水平显示刻度标签
width = 0.8, title = '近两年5个城市亿万资产家庭数比较')
# 取出2016年各城市亿万资产家庭数
Counts2016 = HuRun.Counts[HuRun.Year == 2016]
# 取出2017年各城市亿万资产家庭数
Counts2017 = HuRun.Counts[HuRun.Year == 2017]
#为每个条形图添加数值标签
for x,y in enumerate(Counts2016):
plt.text(x-0.2,y+200,"%s"%round(y,1),ha='center')
for x,y in enumerate(Counts2017):
plt.text(x+0.2,y+200,"%s"%round(y,1),ha='center')
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
plt.xlabel('')
#plt.axis([-0.8,4.8,0,20000]) #用这个可以控制横纵坐标的值域
plt.show()
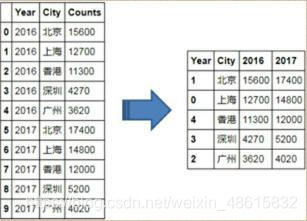
如上代码所示,应用plot方法绘制水平交错条形图,必须更改原始数据集的形状,即将两个离散型变量的水平值分别布置到行与列中(代码中采用透视表的方法实现),最终形成的表格变换下图所示:
针对变换后的数据,可以使用plot方法实现水平交错条形图的绘制,从代码量来看,要比使用matplotlib模块简短一些,得到的条形图如下图所示:
3.seaborn模块绘制条形图
seaborn模块是一款专门用于绘制统计图形的利器,通过该模块写出来的代码也是非常通俗易懂的。下面就简单介绍一下如何通过该模块完成条形图的绘制(同样无法绘制堆叠条形图)。
(1)垂直或水平条形图
垂直条形图:
代码:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
GDP_data = pd.read_excel(r'GDP.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理
#seaborn模块之水平条形图
sns.barplot(x = 'Province', #指定条形图x轴的数据
y = 'GDP', #指定条形图y轴的数据
data = GDP_data, #指定需要绘图的数据集
color = 'steelblue', #指定条形图的填充色
orient = 'v', #将条形图竖直显示
)
#为每个条形图添加数值标签
for x,y in enumerate(GDP_data.GDP):
plt.text(x,y+0.1,"%s"%round(y,1),ha='center')
# 添加y轴标签
plt.ylabel('GDP(万亿)')
plt.xlabel('')
#添加条形图的标题
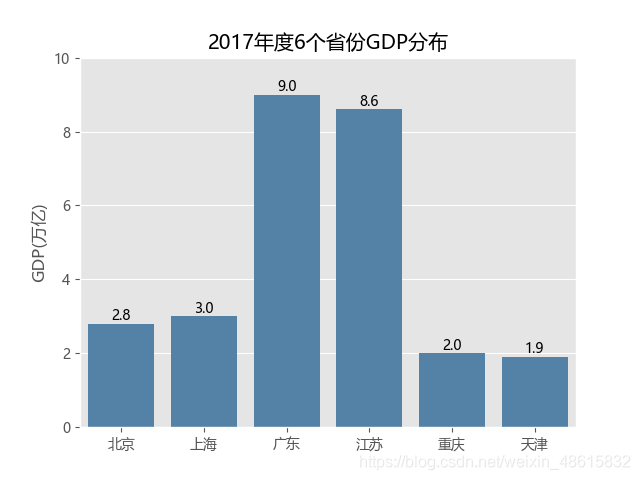
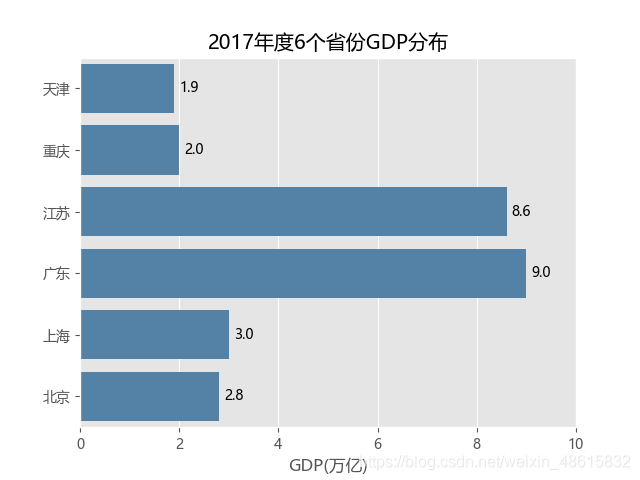
plt.title('2017年度6个省份GDP分布')
plt.axis([-0.5,5.5,0,10]) #用这个可以控制横纵坐标的值域
plt.show()
运行结果:
水平条形图:
代码:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
GDP_data = pd.read_excel(r'GDP.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理
#seaborn模块之水平条形图
sns.barplot(x = 'GDP', #指定条形图x轴的数据
y = 'Province', #指定条形图y轴的数据
data = GDP_data, #指定需要绘图的数据集
color = 'steelblue', #指定条形图的填充色
orient = 'h', #将条形图水平显示
)
#为每个条形图添加数值标签
for y,x in enumerate(GDP_data.GDP):
plt.text(x+0.1,y,"%s"%round(x,1),va='center')
# 添加y轴标签
plt.xlabel('GDP(万亿)')
plt.ylabel('')
#添加条形图的标题
plt.title('2017年度6个省份GDP分布')
plt.axis([0,10,-0.5,5.5]) #用这个可以控制横纵坐标的值域
plt.show()
运行结果:
如上代码就是通过seaborn模块中的barplot函数实现单个离散变量的条形图。
除此之外,seaborn模块中的barplot函数还可以绘制两个离散变量的水平交错条形图,所以有必要介绍一下该函数**[barplot]**的用法及重要参数含义:
sns.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
ci=95, n_boot=1000, orient=None, color=None, palette=None,
saturation=0.75, errcolor='.26', errwidth=None, dodge=True, ax=None, **kwargs)
- x:指定条形图的x轴数据。
- y:指定条形图的y轴数据。
- hue:指定用于分组的另一个离散变量。
- data:指定用于绘图的数据集。
- order:传递一个字符串列表,用于分类变量的排序。
- hur_order:传递一个字符串列表,用于分类变量hue值的排序。
- ci:用于绘制条形图的误差棒(置信区间)。
- n_boot:当指定ci参数时,可以通过n_boot参数控制自助抽样的迭代次数。
- orient:指定水平或垂直条形图。
- color:指定所有条形图所属的一种填充色。
- palette:指定hue变量中各水平的颜色。
- saturation:指定颜色的透明度。
- errcolor:指定误差棒的颜色。
- errwidth:指定误差棒的线宽。
- capsize:指定误差棒两端线条的长度。
- dodge:bool类型参数,当使用hue参数时,是否绘制水平交错条形图,默认为True。
- ax:用于控制子图的位置。
- **kwagrs:关键字参数,可以调用plt.bar函数中的其他参数。
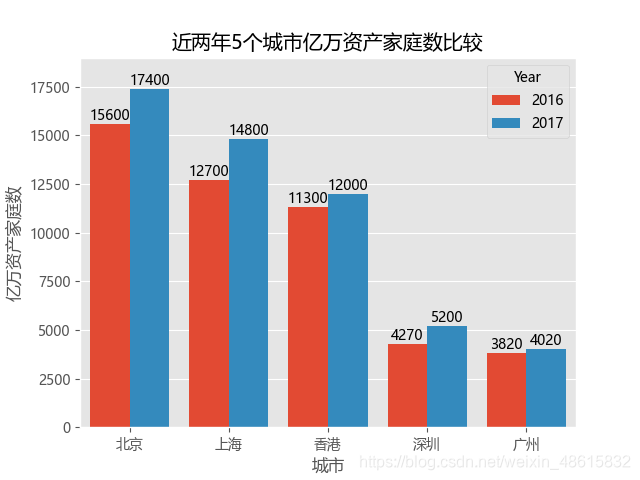
先拿表格《近两年5个城市亿万资产家庭数比较》试试手
代码如下:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
HuRun = pd.read_excel(r'亿万资产家庭数.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理
#seaborn模块之水平条形图
sns.barplot(x = 'City', #指定条形图x轴的数据
y = 'Counts', #指定条形图y轴的数据
hue = 'Year', #指定分组数据
data = HuRun, #指定需要绘图的数据集
palette = 'RdBu', #指定分组数据即时间的不同颜色
saturation = 1, #指定颜色的透明度,这里设置为无透明度
orient = 'v', #将条形图竖直显示
)
# 取出2016年各城市亿万资产家庭数
Counts2016 = HuRun.Counts[HuRun.Year == 2016]
# 取出2017年各城市亿万资产家庭数
Counts2017 = HuRun.Counts[HuRun.Year == 2017]
#为每个条形图添加数值标签
for x,y in enumerate(Counts2016):
plt.text(x-0.2,y+200,"%s"%round(y,1),ha='center',fontsize=10) #round(y,1)是将y值四舍五入到一个小数位
for x,y in enumerate(Counts2017):
plt.text(x+0.2,y+200,"%s"%round(y,1),ha='center',fontsize=10) #fontsize是调节字体大小的函数,默认数值是12
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
plt.xlabel('城市')
#添加条形图的标题
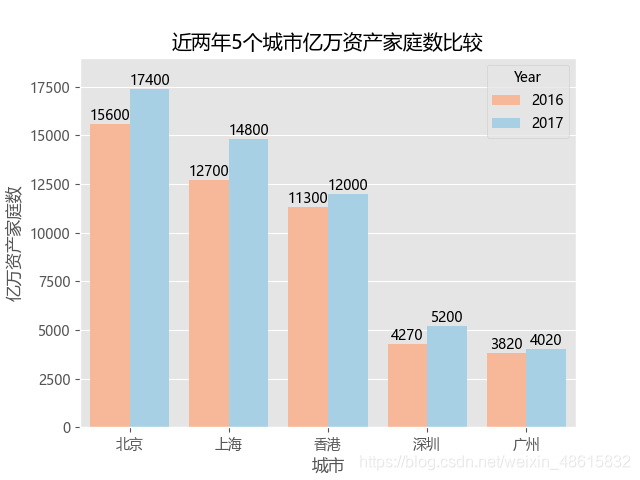
plt.title('近两年5个城市亿万资产家庭数比较')
plt.axis([-0.5,4.5,0,19000]) #用这个可以控制横纵坐标的值域
plt.show()
关于条形图颜色,palette函数,中文意思调色板,颜料。具体的讲解可见下面的链接:
Seaborn库 手册翻译(二)——颜色控制
超详细Seaborn绘图 ——(一)barplot
运行上面的程序的结果:
palette的默认颜色为浅色,Rd是红色的缩写,Bu是蓝色的缩写
当我注释掉palette后,运行结果如下:
拿一个新的数据表格做实验:
下面的表格数据是泰坦尼克号的乘客数据,截屏了一部分。
其中各字段含义为:
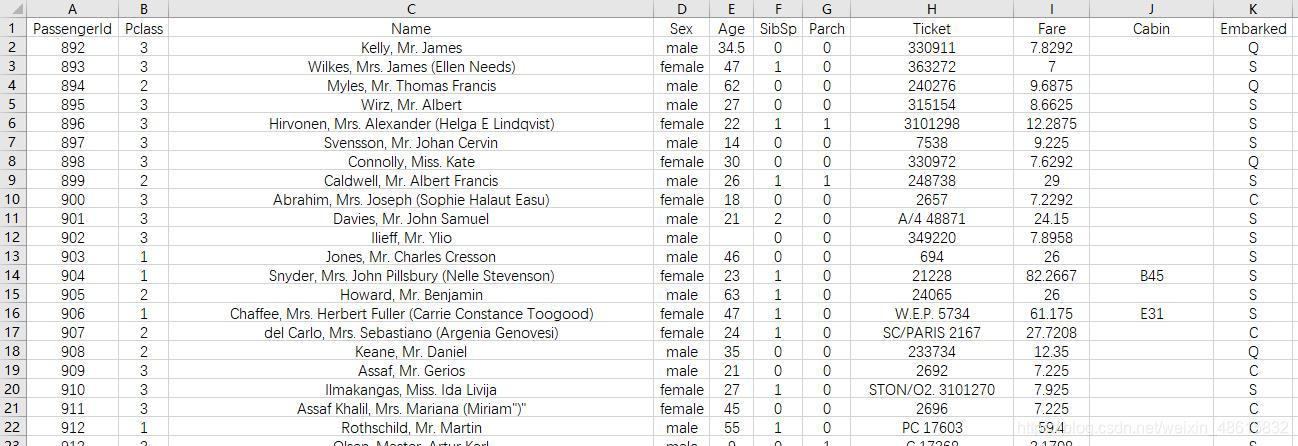
- PassengerId ,乘客的id号,这个我觉得对生存率没影响。因为一个人的id号不会影响我是否生存下来吧。
- Survived ,生存的标号,上面图的数值1表示这个人很幸运,生存了下来。数值0,则表示遗憾。
- Pclass ,船舱等级,就是我们坐船有等级之分,像高铁,飞机都有。这个属性会对生产率有影响。因为一般有钱人,权贵才会住头等舱的。
- Name ,名字。
- Sex , 性别。
- Age , 年龄。
- SibSp ,兄弟姐妹,就是有些人和兄弟姐妹一起上船的。这个会有影响,因为有可能因为救他们而导致自己没有上救生船船。保留这列
- Parch , 父母和小孩。就是有些人会带着父母小孩上船的。这个也可能因为要救父母小孩耽误上救生船。
- Ticket , 票的编号。
- Fare , 费用。这个和Pclass有相同的道理,有钱人和权贵比较有势力和影响力。
- Cabin ,舱号。
- Embarked ,上船的地方
这里以泰坦尼克号数据集为例,绘制水平交错条形图,代码如下:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
Titanic = pd.read_excel(r'泰坦尼克号乘客年龄分布.xlsx')
#由于年龄那一列有的人的数据存在缺失,这些缺失值是怎么处理的呢?一般是三种处理方法:不处理/丢弃/填充。
#像Age这样的重要变量,有20%左右的缺失值,我们可以考虑用中位值来填补。-- 填补缺失值
#这里就有两个索引,分别是舱位和性别,我们可以看到,随着舱位的下降,它的年龄也是在下降的。用我们的话理解就是,年轻人普遍比年长的穷啊,年龄大一点的人积累的财富也多一点。
#分组计算不同舱位男女年龄的中位数,得到一个Series数据,索引为Pclass,Sex
age_median = Titanic.groupby(['Pclass','Sex']).Age.median()
#设置Pclass,Sex为索引,inplace=True表示在原数据Titanic上直接进行修改
Titanic.set_index(['Pclass','Sex'],inplace=True)
#使用fillna填充缺失值,根据索引值填充
Titanic.Age.fillna(age_median,inplace=True)
#横向最多显示多少个字符, 一般80不适合横向的屏幕,平时多用200
pd.set_option('display.width', 200)
#显示所有列
pd.set_option('display.max_columns',None)
#显示所有行
pd.set_option('display.max_rows', None)
#数据输出,查看Age列的统计值
print(Titanic.head(n=420)) #不写n=多少的时候,head()函数默认是n=5
# 读入数据
Titanic = pd.read_excel(r'泰坦尼克号乘客年龄分布.xlsx')
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理
#seaborn模块之水平条形图
sns.barplot(x = 'Pclass', #指定条形图x轴的数据
y = 'Age', #指定条形图y轴的数据
hue = 'Sex', #指定分组数据
data = Titanic, #指定需要绘图的数据集
palette = 'RdBu', #指定分组数据即性别的不同颜色
errcolor = 'blue', #指定误差棒的颜色
errwidth = 2, #指定误差棒的线宽
saturation = 1, #指定颜色的透明度,这里设置为无透明度
capsize = 0.05, #指定误差棒两端线条的宽度
orient = 'v', #将条形图竖直显示
)
# seaborn.barplot()不用额外添加横纵坐标的标签
# plt.ylabel('Age')
# plt.xlabel('Pclass')
#添加条形图的标题
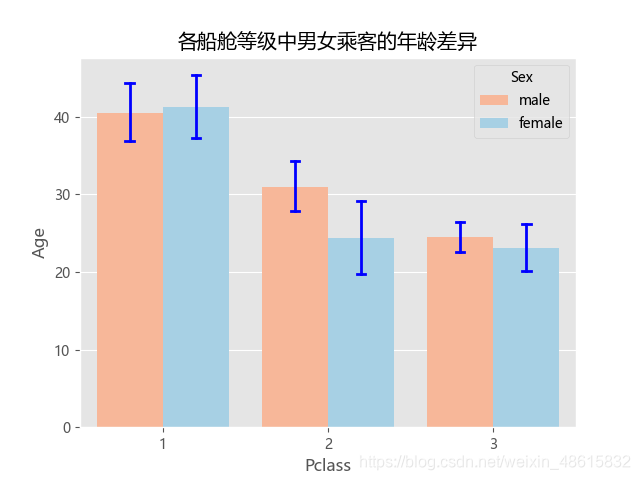
plt.title('各船舱等级中男女乘客的年龄差异')
plt.show()
运行结果:
PassengerID Name Age
Pclass Sex
3 male 1 Kelly, Mr. James 34.50
female 2 Wilkes, Mrs. James (Ellen Needs) 47.00
2 male 3 Myles, Mr. Thomas Francis 62.00
3 male 4 Wirz, Mr. Albert 27.00
female 5 Hirvonen, Mrs. Alexander (Helga E Lindqvist) 22.00
male 6 Svensson, Mr. Johan Cervin 14.00
female 7 Connolly, Miss. Kate 30.00
2 male 8 Caldwell, Mr. Albert Francis 26.00
3 female 9 Abrahim, Mrs. Joseph (Sophie Halaut Easu) 18.00
male 10 Davies, Mr. John Samuel 21.00
male 11 Ilieff, Mr. Ylio 24.00
1 male 12 Jones, Mr. Charles Cresson 46.00
female 13 Snyder, Mrs. John Pillsbury (Nelle Stevenson) 23.00
2 male 14 Howard, Mr. Benjamin 63.00
1 female 15 Chaffee, Mrs. Herbert Fuller (Carrie Constance... 47.00
2 female 16 del Carlo, Mrs. Sebastiano (Argenia Genovesi) 24.00
male 17 Keane, Mr. Daniel 35.00
3 male 18 Assaf, Mr. Gerios 21.00
female 19 Ilmakangas, Miss. Ida Livija 27.00
female 20 Assaf Khalil, Mrs. Mariana (Miriam")" 45.00
#....................................................................................(省略大部分数据)
male 400 Conlon, Mr. Thomas Henry 31.00
1 female 401 Bonnell, Miss. Caroline 30.00
2 male 402 Gale, Mr. Harry 38.00
1 female 403 Gibson, Miss. Dorothy Winifred 22.00
male 404 Carrau, Mr. Jose Pedro 17.00
male 405 Frauenthal, Mr. Isaac Gerald 43.00
2 male 406 Nourney, Mr. Alfred (Baron von Drachstedt")" 20.00
male 407 Ware, Mr. William Jeffery 23.00
1 male 408 Widener, Mr. George Dunton 50.00
3 female 409 Riordan, Miss. Johanna Hannah"" 22.00
female 410 Peacock, Miss. Treasteall 3.00
female 411 Naughton, Miss. Hannah 22.00
1 female 412 Minahan, Mrs. William Edward (Lillian E Thorpe) 37.00
3 female 413 Henriksson, Miss. Jenny Lovisa 28.00
male 414 Spector, Mr. Woolf 24.00
1 female 415 Oliva y Ocana, Dona. Fermina 39.00
3 male 416 Saether, Mr. Simon Sivertsen 38.50
male 417 Ware, Mr. Frederick 24.00
male 418 Peter, Master. Michael J 24.00
如图上图所示,绘制的每一个条形图中都含有一条竖线,该竖线就是条形图的误差棒,即各组别下年龄的标准差大小。从上图可知,三等舱的男性乘客年龄是最为接近的,因为标准差最小。
需要注意的是,数据集Titanic并非汇总好的数据,是不可以直接应用到matplotlib模块中的bar函数与pandas模块中的plot方法。如需使用,必须先对数据集进行分组聚合。