反向传播
1. 定义
对于每一个训练样本传入网络, 直到输出层, 这个过程称为正向传播, 将其输出与标签进行比较, 计算误差, 根据误差, 从输出层到输入层逐级反向传播, 调整每个神经元的权重, 以减小误差, 这个过程就是反向传播.
2. 权重更新公式
w p q n e w = w p q o l d + Δ w p q w^{new}_{pq} = w^{old}_{pq}+ Δw_{pq} wpqnew=wpqold+Δwpq
3. 梯度下降更新权重
Δ w = η ⋅ δ q ⋅ o p Δw = η⋅δ_q⋅o_p Δw=η⋅δq⋅op
- 若q是输出层的神经元, 则
δ q = ( t q − o q ) f ′ ( z q ) δ_q = (t_q-o_q)f'(z_q) δq=(tq−oq)f′(zq)
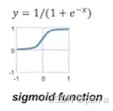
f ’ ( x ) = f ( x ) ⋅ ( 1 − f ( x ) ) [ s i g m o i d ] f’(x)=f(x)⋅(1−f(x)) [sigmoid] f’(x)=f(x)⋅(1−f(x))[sigmoid]
2.若q是隐藏层的神经元,则
δ q = f ′ ( z q ) ∑ i w q i δ i δ_q = f'(z_q)\sum_i w_{qi}δ_i δq=f′(zq)i∑wqiδi
i是q后面的神经元,p->q->i
4. 反向传播数学计算理解
transfer function
学习率η=0.9
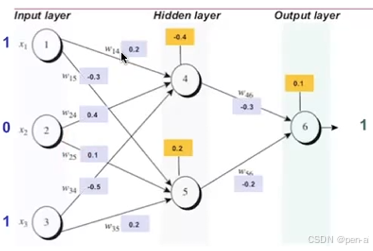
- 首先前向传播得到结果
z 4 = 1 ∗ 0.2 + 0 ∗ 0.4 + 1 ∗ ( − 0.5 ) − 0.4 = − 0.7 z_4 = 1*0.2 + 0*0.4 + 1*(-0.5) - 0.4 = -0.7 z4=1∗0.2+0∗0.4+1∗(−0.5)−0.4=−0.7 o 4 = 1 / ( 1 + e − x ) = 1 / ( 1 + e 0.7 ) = 0.332 o_4 = 1/(1+e^{-x}) = 1/(1+e^{0.7}) = 0.332 o4=1/(1+e−x)=1/(1+e0.7)=0.332
z 5 = 1 ∗ ( − 0.3 ) + 0 ∗ 0.1 + 1 ∗ 0.2 + 0.2 = 0.1 z_5 = 1*(-0.3) + 0*0.1 + 1*0.2 +0.2 = 0.1 z5=1∗(−0.3)+0∗0.1+1∗0.2+0.2=0.1 o 5 = 1 / ( 1 + e − x ) = 1 / ( 1 + e − 0.1 ) = 0.525 o_5 = 1/(1+e^{-x}) = 1/(1+e^{-0.1}) = 0.525 o5=1/(1+e−x)=1/(1+e−0.1)=0.525
z 6 = 0.332 ∗ ( − 0.3 ) + 0.525 ∗ ( − 0.2 ) + 0.1 = − 0.0996 − 0.105 + 0.1 = − 0.1046 z_6 = 0.332*(-0.3) + 0.525*(-0.2) +0.1 = -0.0996-0.105+0.1 = -0.1046 z6=0.332∗(−0.3)+0.525∗(−0.2)+0.1=−0.0996−0.105+0.1=−0.1046 o 6 = 1 / ( 1 + e − x ) = 1 / ( 1 + e 0.105 ) = 0.474 o_6 = 1/(1+e^{-x}) = 1/(1+e^{0.105}) = 0.474 o6=1/(1+e−x)=1/(1+e0.105)=0.474 - 接下来反向传播更新权重
δ 6 = ( t 6 − o 6 ) f ′ ( z 6 ) = ( t 6 − o 6 ) f ( z 6 ) ( 1 − f ( z 6 ) ) = ( 1 − 0.474 ) ∗ 0.474 ∗ ( 1 − 0.474 ) = 0.1311 δ_6 = (t_6-o_6)f'(z_6) = (t_6-o_6)f(z_6)(1-f(z_6)) = (1-0.474) * 0.474*(1-0.474) = 0.1311 δ6=(t6−o6)f′(z6)=(t6−o6)f(z6)(1−f(z6))=(1−0.474)∗0.474∗(1−0.474)=0.1311
Δ w 46 = η ∗ δ 6 ∗ o 4 Δw_{46} = η *δ_6 *o4 Δw46=η∗δ6∗o4
w 46 ( n e w ) = w 46 ( o l d ) + Δ w 46 w_{46}(new) = w_{46}(old)+Δw_{46} w46(new)=w46(old)+Δw46
b 6 ( n e w ) = b 6 ( o l d ) + Δ b 6 b_6(new) = b_6(old) + Δb_6 b6(new)=b6(old)+Δb6
5. 结构来带的问题
太多隐藏层会过拟合,太少会欠拟合
6. 介绍训练例子
- 对于每个epoch,选择排列好的训练例子。
- 多展示误差较大的例子,少展示误差较小的例子
- 不是一个一个地展示这些例子,而是以N个例子为批次,总结它们各自的错误,并在每批(min-batch)后更新
7. 学习率
学习率可以是固定的, 也可以随时间变化.
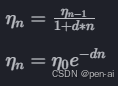
8. 动量 Momentum
动量, momentum, 通过在权重更新公式中引入一个额外的动量项, 使得当前的权重更新依赖于之前的更新, 从而减少振荡并允许使用更大的学习率
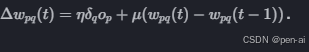
9. 权重初始化
- 标准的做法: 从-1到1之间选择小的随机数
- Xavier: 权重从一个正态分布中产生
σ = 2 N i n + N o u t σ = \sqrt{\frac{2}{N_{in}+N_{out}}} σ=Nin+Nout2
in 和 out 分别是当前层输入神经元数量和输出神经元数量。
10. 算法的进步
- 克服消失梯度问题
- Dropout以避免过拟合
- 新的初始化方法:使用自动编码器进行预训练
- 卷积和共享权重
11. 梯度消失问题
o非常小导致δ非常小,权重更新也非常小
- 特别是如果有许多隐藏层-递减梯度,收敛缓慢
- 即使输出层的激活不饱和,当我们将梯度从输出层反向传播到隐藏层时进行的重复乘法也可能导致梯度递减
- 输出到隐藏层可能会导致梯度递减
- 消失的梯度问题:权重变化为较低的水平都很小;这些层的学习速度比更高的隐藏层要慢
- 这一直是训练深度神经网络的一个主要问题
解决方法:使用其他激活功能(LReLu)