2.1 Mutex 和 RWMutex
1、Mutex 可以看做是锁,而 RWMutex 则是读写锁。 一般的用法是将 Mutex 或者 RWMutex 和需要被保住的资源封装在一个结构体内。
- 如果有多个 goroutine 同时读写的资源,就一定要保护起来;
- 如果多个 goroutine 只读某个资源,那就不需要保护。
- 使用锁的时候,优先使用 RWMutex
- RWMutex:核心就是四个方法,RLock、 RUnlock、Lock、Unlock
- Mutex:Lock 和 Unloc
package syncpg
import "sync"
// PublicResource 你永远不知道你的用户拿了它会干啥
// 即便不用 PublicResourceLock 你也毫无办法
// 如果用这个resource,一定要用锁
var PublicResource interface{}
var PublicResourceLock sync.Mutex
// privateResource 要好一点,祈祷用户会来看你的注释,知道要用锁
// 很多库都是这么写的,我也写了很多类似的代码=。=
var privateResource interface{}
var privateResourceLock sync.Mutex
// safeResource 很棒,所有的期望对资源的操作都只能通过定义在上 safeResource 上的方法来进行
type safeResource struct {
resource interface{}
lock sync.Mutex
}
func (s *safeResource) DoSomethingToResource() {
s.lock.Lock()
defer s.lock.Unlock()
}
复制代码**代码演示: **
(1) SafeMap 的 LoadOrStore 写法
- 例子:SafeMap 可以看做是 map 的一个线程安全的封装。我们为它增加一个 LoadOrStore 的方法
type SafeMap[K comparable, V any] struct {
m map[K]V
lock sync.RWMutex
}
// LoadOrStore loaded 代表是返回老的对象,还是返回了新的对象
// g1 (key1, 123) g2 (key1, 456)
func (s *SafeMap[K, V]) LoadOrStore(key K, newVal V) (val V, loaded bool) {
}
复制代码double-check 写法
- 使用 RWMutex 实现 double-check:
- 加读锁先检查一遍
- 释放读锁
- 加写锁
- 再检查一遍
- 所有操作结束释放写锁
import (
"errors"
"fmt"
"sync"
)
type SafeMap[K comparable, V any] struct {
m map[K]V
lock sync.RWMutex
zero V
}
func (s *SafeMap[K, V]) LoadOrStore(key K, val V) (V, bool) {
oldVal, ok := s.Get(key)
if ok {
return oldVal, true
}
s.lock.Lock()
defer s.lock.Unlock()
oldVal, ok = s.m[key] // double-check
if ok {
return oldVal, true
}
s.m[key] = val
return val, false
}
func (s *SafeMap[K, V]) Get(key K) (V, bool) {
s.lock.RLock()
defer s.lock.RUnlock()
val, ok := s.m[key]
return val, ok
}
func (s *SafeMap[K, V]) Put(key K, newVal V) (V, error) {
s.lock.Lock()
defer s.lock.Unlock()
_, ok := s.m[key]
if !ok {
exc := fmt.Sprintf("the key %v not exists", key)
return s.zero, errors.New(exc)
}
s.m[key] = newVal
return newVal, nil
}
func (s *SafeMap[K, V]) Delete(key K) error {
s.lock.Lock()
defer s.lock.Unlock()
_, ok := s.m[key]
if !ok {
exc := fmt.Sprintf("the key %v not exists", key)
return errors.New(exc)
}
delete(s.m, key)
return nil
}
复制代码(2) 实现一个线程安全的 ArrayList
- 例子:实现一个线程安全的 ArrayLis
- 思路:切片本身不是线程安全的,所以最简单的做法就是利用读写锁封装一 下。这也是典型的装饰器模式的应用;
- 如果考虑扩展性,那么需要预先定义一个 List 接口,后续可以有 ArrayList, LinkedList,锁实现的线程安全 List,以及无锁实现的线程安全 List;
- 任何非线程安全的类型、接口都可以利用读写锁 + 装饰器模式无侵入式地改 造为线程安全的类型、接口;
package syn
import (
"fmt"
"sync"
)
// List 接口
// 该接口只定义清楚各个方法的行为和表现
type List[T any] interface {
// Get 返回对应下标的元素,
// 在下标超出范围的情况下,返回错误
Get(index int) (T, error)
// Append 在末尾追加元素
Append(t T) error
// Add 在特定下标处增加一个新元素
// 如果下标超出范围,应该返回错误
Add(index int, t T) error
// Set 重置 index 位置的值
// 如果下标超出范围,应该返回错误
Set(index int, t T) error
// Delete 删除目标元素的位置,并且返回该位置的值
// 如果 index 超出下标,应该返回错误
Delete(index int) (T, error)
// Len 返回长度
Len() int
// Cap 返回容量
Cap() int
// Range 遍历 List 的所有元素
Range(fn func(index int, t T) error) error
// AsSlice 将 List 转化为一个切片
// 不允许返回nil,在没有元素的情况下,
// 必须返回一个长度和容量都为 0 的切片
// AsSlice 每次调用都必须返回一个全新的切片
AsSlice() []T
}
// newErrIndexOutOfRange 创建一个代表
func newErrIndexOutOfRange(length int, index int) error {
return fmt.Errorf("ekit: 下标超出范围,长度 %d, 下标 %d", length, index)
}
// ArrayList 基于切片的简单封装
type ArrayList[T any] struct {
vals []T
zero T
}
func (a *ArrayList[T]) Get(index int) (T, error) {
if index < 0 || index > len(a.vals) {
return a.zero, newErrIndexOutOfRange(len(a.vals), index)
}
res := a.vals[index]
return res, nil
}
// Add 在ArrayList下标为index的位置插入一个元素
// 当index等于ArrayList长度等同于append
func (a *ArrayList[T]) Add(index int, t T) error {
if index < 0 || index > len(a.vals) {
return newErrIndexOutOfRange(len(a.vals), index)
}
a.vals = append(a.vals, t)
copy(a.vals[index+1:], a.vals[index:])
a.vals[index] = t
return nil
}
func (a *ArrayList[T]) Append(t T) error {
// 复杂些可以考虑 维护一个size, 来判断是否需要处理扩容
a.vals = append(a.vals, t)
return nil
}
func (a *ArrayList[T]) Set(index int, t T) error {
if index < 0 || index > len(a.vals) {
return newErrIndexOutOfRange(len(a.vals), index)
}
a.vals[index] = t
return nil
}
func (a *ArrayList[T]) Delete(index int) (T, error) {
if index < 0 || index > len(a.vals) {
return a.zero, newErrIndexOutOfRange(len(a.vals), index)
}
res := a.vals[index]
a.vals = append(a.vals[:index], a.vals[index+1:]...)
return res, nil
}
func (a *ArrayList[T]) Cap() int {
return cap(a.vals)
}
func (a *ArrayList[T]) Len() int {
return len(a.vals)
}
func (a *ArrayList[T]) Range(fn func(index int, t T) error) error {
for key, value := range a.vals {
e := fn(key, value)
if e != nil {
return e
}
}
return nil
}
func (a *ArrayList[T]) AsSlice() []T {
slice := make([]T, len(a.vals))
copy(slice, a.vals)
return slice
}
func NewArrayList[T any](initCap int) *ArrayList[T] {
return &ArrayList[T]{
vals: make([]T, 0, initCap),
}
}
// NewArrayListOf 直接使用 ts,而不会执行复制
func NewArrayListOf[T any](ts []T) *ArrayList[T] {
return &ArrayList[T]{
vals: ts,
}
}
// 线程安全的 ArrayList
type SafeArrayList[T any] struct {
list List[T]
lock sync.RWMutex
}
func (a *SafeArrayList[T]) Get(index int) (T, error) {
a.lock.RLock()
defer a.lock.RUnlock()
return a.list.Get(index)
}
func (a *SafeArrayList[T]) Append(t T) error {
a.lock.Lock()
defer a.lock.Unlock()
return a.list.Append(t)
}
func (a *SafeArrayList[T]) Set(index int, t T) error {
a.lock.Lock()
defer a.lock.Unlock() // 尽量用defer解锁, 避免panic
return a.Set(index, t)
}
func NewSafeArrayList[T any](initCap int) *SafeArrayList[T] {
return &SafeArrayList[T]{
list: NewArrayList[T](initCap),
}
}
复制代码2、Mutex 细节
锁的一般实现都是依赖于:
- 自旋作为快路径;
- 自旋可以通过控制次数或者时间来退出循环。
- 等待队列作为慢路径;
- 慢路径:跟语言特性有关,有些依赖于操作系统线程调度,如 Java,有些是自己管,如 goroutine。

下面代码我称为锁实现模板,Mutex 的源码还是很难理解的;
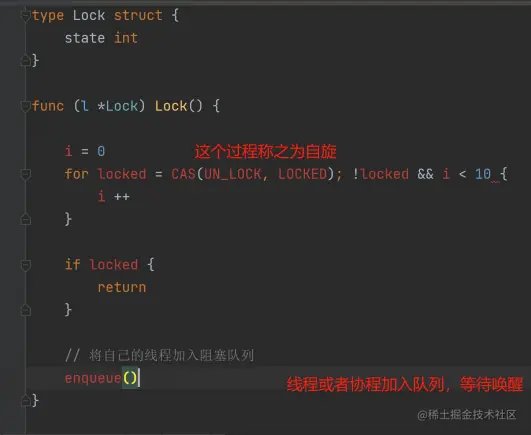
Go 的 Mutex 大致符合模板,但是做了针对性的优化。
理解关键点:
- state 就是用来控制锁状态的核心,所谓加锁,就是 把 state 修改为某个值,解锁也是类似;
- sema 是用来处理沉睡、唤醒的信号量,依赖于两 个 runtime 调用:
- runtime_Semacquire:sema 加 1 并且挂起 goroutine
- runtime_Semarelease:sema 减 1 并且唤醒 sema 上等待的一个 goroutine
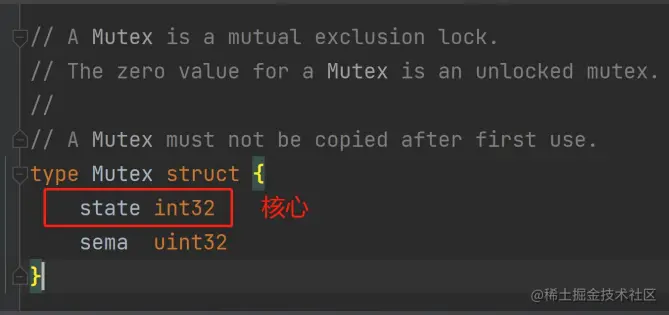
一把锁,如果没有人持有它,也没有人抢,那么一个 CAS 操作就能成功。 (一次性的自旋)
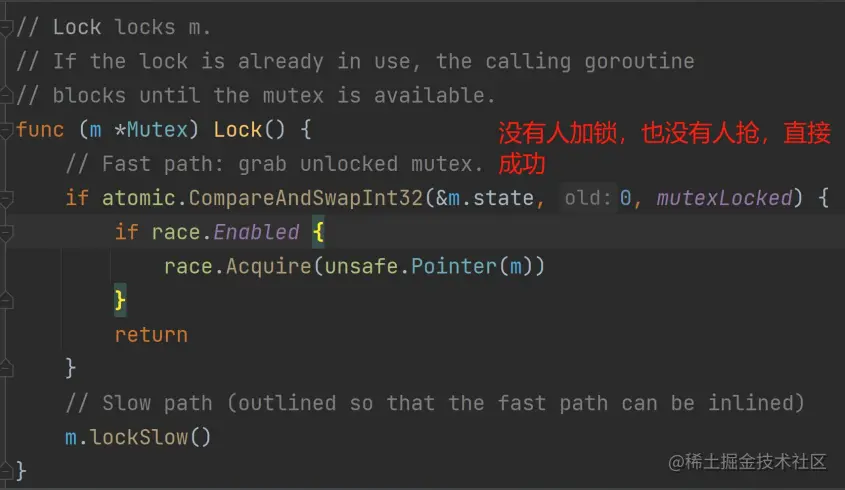
在锁实现模板里面,我们说自旋是快路径。Go 把这个归到了慢路径里面。实际上在这个片段里面,还是很快的,因为没有进入等待队列的环节。所以:理论上的自旋 = Go 的快路径 + Go 慢路径的
自旋部分, 源码:

后半部分的代码就是控制锁的两种模式,以及进队列,被唤醒的部分了。为什么 Go 的锁有所谓的两种模式?我们的锁实现模板里面根本就没有这种东西。
- 正常模式
- 饥饿模式
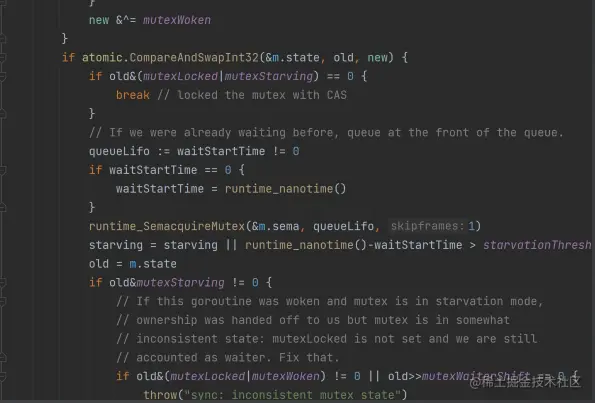
(1) 如果一个新的 goroutine 进来争夺锁,而且队列里面也有等待的 goroutine,你是设计者,你会把锁给谁?
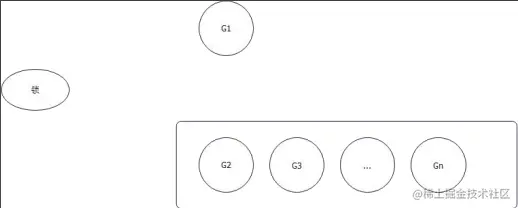
- 给 G2:毕竟我们要保证公平,先到先得是规矩,不能破坏;
- G1 和 G2 竞争:保证效率。G1 肯定已经占着了 CPU,所以大概率能够拿到锁; 所以正常模式的核心优势是避免 goroutine 调度,(所谓的正常模式,就是 G1 和 G2 竞争的模式) G1能获得锁。
(2) 那如果要是每次 G2 想要拿到锁的时候,都被新来的G1 给抢走了,那么 G2 和其它队列的不就是饥饿了吗?
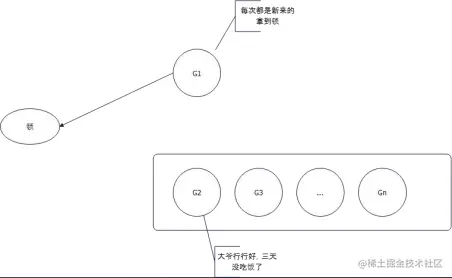
- G2 每次没抢到锁,都要退回去队列头;
- 所以如果等待时间超过 1ms,那么锁就会变成饥饿模式;
- 在饥饿模式下,锁会优先选择队列中的 goroutine。
因此对应的退出饥饿模式,要么队列中只剩下一个goroutine,要么 G2 的等待时间小于 1ms。
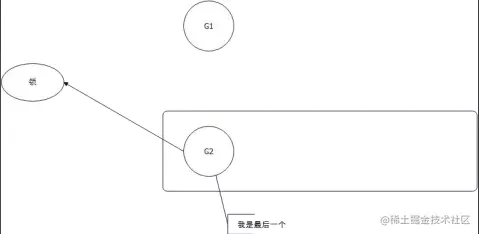
- 步骤总结:
- 先上来一个 CAS 操作,如果这把锁正空闲,并且 没人抢,那么就直接成功;
- 否则,自旋几次,如果这个时候成功了,也不用加 入队列;
- 否则,加入队列;
- 从队列中被唤醒: (1) 正常模式:和新来的一起抢锁,但是大概率失败; (2) 饥饿模式:肯定拿到锁。
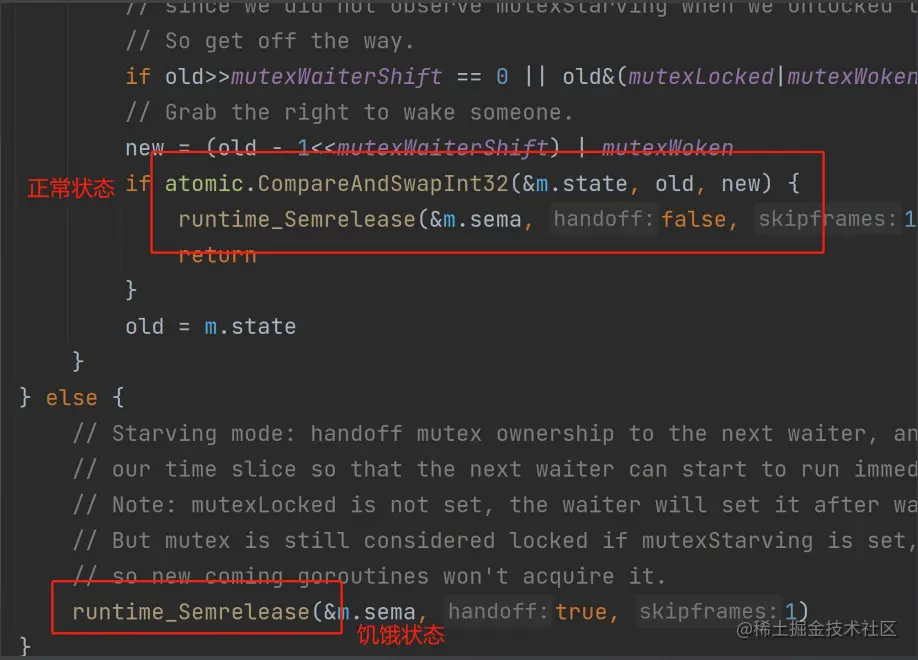
解锁:
- 上来就是一个 atomic 操作,解锁。理论上来说这 也应该是一个 CAS 操作,即必须是加锁状态才能解锁,Go 这种写法效果是一样的;
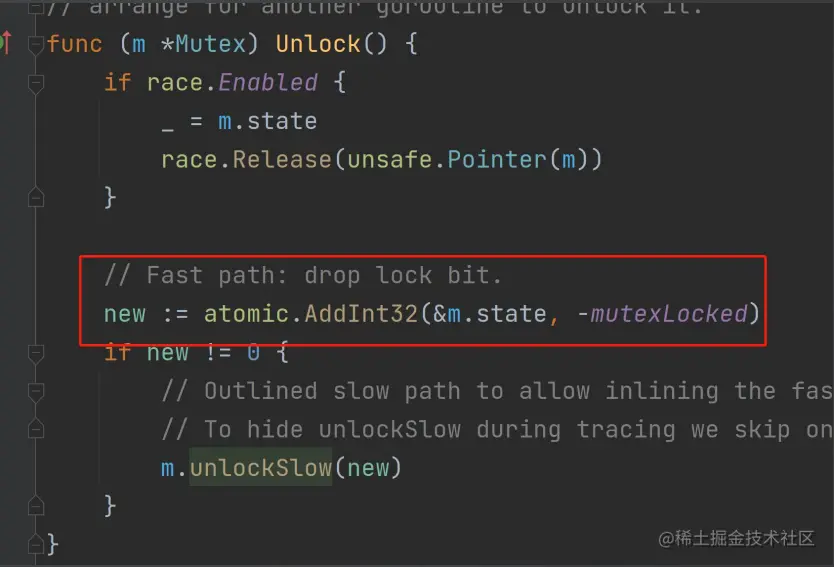
- 解锁失败则是步入慢路径(其实就是先把 locked 设置 为0,再释放一个信号量去唤醒阻塞的协程,阻塞协程被唤醒后将locked 设置为1),也就是要唤醒等待队列里面的 goroutine;
左边这里释放锁就会唤醒右边阻塞的 goroutine
3、Mutex 和 RWMutex 注意项
- RWMutex适合于读多写少的场景
- 写多读少不如直接加写锁
func (s *SafeMap[K, V]) WriteOrRead() {
s.lock.Lock()
defer s.lock.Unlock()
// 写多读少
}
func (s *SafeMap[K, V]) ReadOrWrite() {
s.lock.RLock()
// 读的操作 例如第一次检查
s.lock.RUnlock()
s.lock.Lock()
defer s.lock.Unlock()
}
复制代码- 可以考虑使用函数式写法,如延迟初始化
type valProvider[V any] func() V
func (s *SafeMap[K, V]) LoadOrStoreJHeavy(key K, p valProvider[V]) (val interface{}, loaded bool) {
oldVal, ok := s.Get(key)
if ok {
return oldVal, false
}
s.lock.Lock()
defer s.lock.Unlock()
val, ok = s.m[key]
if ok {
return val, true
}
newVal := p() // 延迟初始化
s.m[key] = newVal
return newVal, false
}
复制代码- Mutex 和 RWMutex 都是不可重入的
var l = sync.RWMutex{}
func RecursiveA() {
l.Lock()
defer l.Unlock()
RecursiveB()
}
func RecursiveB() {
RecursiveC()
}
func RecursiveC() {
l.Lock()
defer l.Unlock()
RecursiveA()
}
复制代码- 尽可能用 defer 来解锁,避免 panic
func (a *SafeArrayList[T]) Set(index int, t T) error {
a.lock.Lock()
defer a.lock.Unlock() // 尽量用defer解锁, 避免panic
return a.Set(index, t)
}
复制代码4、Mutex 面试要点
- Mutex 的公平性:Go 的锁是不公平锁。为什么它不设计为公平锁?
- Mutex 的两种模式,以及两种模式的切换时机:
- 正常模式
- 饥饿模式
- 为什么 Mutex 要设计出来这两种模式?这个问题基本等价于为什么它不设计为公平锁。
- 如果队列里面有 goroutine 在等待锁,那么新来的 goroutine 有可能拿到锁吗?当然,而且大概率。
- Mutex 是不是可重入的锁?显然不是。
- RWMutex 和 Mutex 有什么区别?如何选择这两个?几乎完全是写操作的选 Mutex,其它时候优先 选择RWMutex。
- Mutex 是怎么做到挂起 goroutine 的,以及是如何唤醒 goroutine 的?在这个语境下,只需要回答 sema 这个字段以及 runtime_Semacquire 和 runtime_Semrelease 两个调用就可以。
2.2 Once
sync.Once 一般就是用来确保某个动作至多执行一 次; 普遍用于初始化资源和单例模式。
type Singleton struct {
data string
}
var singleInstance *Singleton
var once sync.Once
func GetSingletonObj() *Singleton {
once.Do(func() { // 只执行一次实现单例模式
fmt.Println("Create Obj")
singleInstance = new(Singleton)
})
return singleInstance
}
复制代码1、Once 细节
源码如下:


这是一种 double-check 的变种。 没有直接利用读写锁,而是利用原子操作来扮演读锁的角色。 是值得学习的做法。
2.Once 例子:
- Beego 用 Once 来初始化 Web 模块
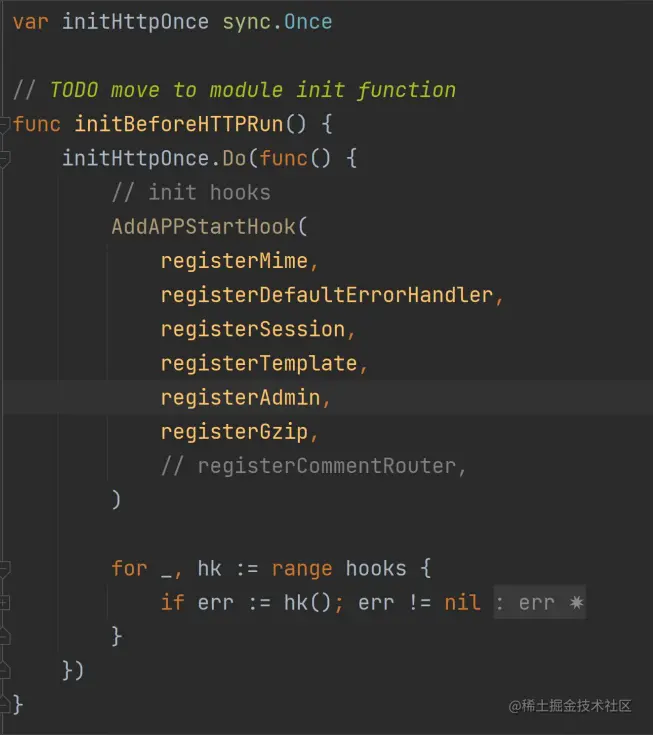
initBeforeHTTPRun 可能会在多个地方被调用,所 以需要使用 Once 来确保只会执行一次。
从 TODO 标记也可以看出来,在一些情况下, Once 可能暗示着代码可以放到包初始化方法 init 里面调用。
2.3 Pool
1、Pool 介绍
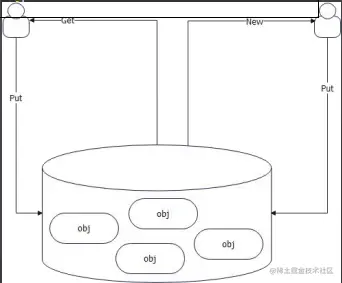
一般情况下,如果要考虑缓存资源,比如说创建好的对象,那么可以使用 sync.Pool。
-
- sync.Pool 会先查看自己是否有资源,有则直接返回, 没有则创建一个新的;
- sync.Pool 会在 GC 的时候释放缓存的资源;
一般是用 sync.Pool 都是为了复用内存:
- 它减少了内存分配,也减轻了 GC 压力(最主要)
- 减少消耗 CPU 资源(内存分配和 GC 都是 CPU 密集操作)
func TestPool(t *testing.T) {
p := sync.Pool{
// 创建函数,sync.Pool 会回调
New: func() interface{} {
return "111"
},
}
obj := p.Get()
fmt.Println(obj) // 111
// 在这里使用取出来的对象
// 用完再还回去
p.Put(obj)
}
复制代码func SyncPool() {
pool := &sync.Pool{
New: func() interface{} {
fmt.Println("create a new obj")
return 100
},
}
v := pool.Get().(int) // 对象没有则创建, 并将此对象返回弹出 sync.Pool
fmt.Println(v)
pool.Put(3) // 将 3 代替 100 put
runtime.GC() // GC 会清除 sync.Pool 中缓存的对象
v1, _ := pool.Get().(int)
fmt.Println(v1)
v2, _ := pool.Get().(int)
fmt.Println(v2)
}
复制代码2、Pool 细节 假如说要实现一个类似功能的Pool,可以考虑用什么方案?
最简单的方案,就是用队列,而且是并发安全的队列。队头取,队尾放回去。在队列为空的时候创建一个新的。
问题:队头和队尾都是竞争点,依赖于锁。
沿着这种思路,就可以用 channel来实现一个简单的连接池:
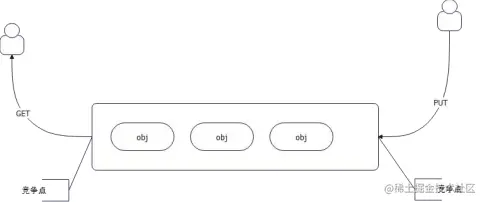
很显然,既然全局锁会成为瓶颈,我们就避免全局锁,逼不得已的时候再去尝试全局锁。 那么可以考虑的方案就是 TLB(thread-local-buffer)。每个线程自己搞一个队列,再来一个共享的队列。
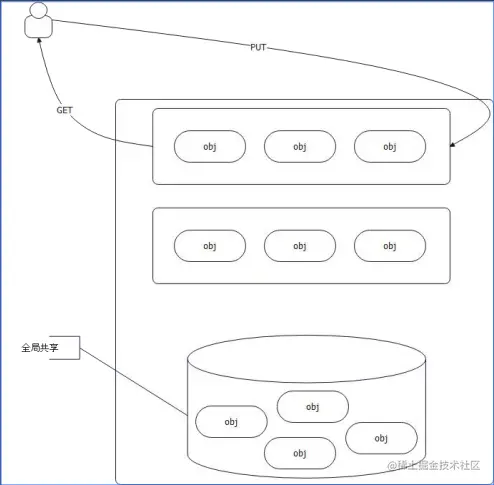
Go有更好的选择。Go本身的GMP调度模型,其中P是一个神奇的东西,代表的是处理器(Processor)。P的优点:任何数据绑定在P上,都不需要竞争,因为P同一时间只有一个G在运行。
同时,Go并没有采用全局共享队列的方案,而是采用了窃取的方案。
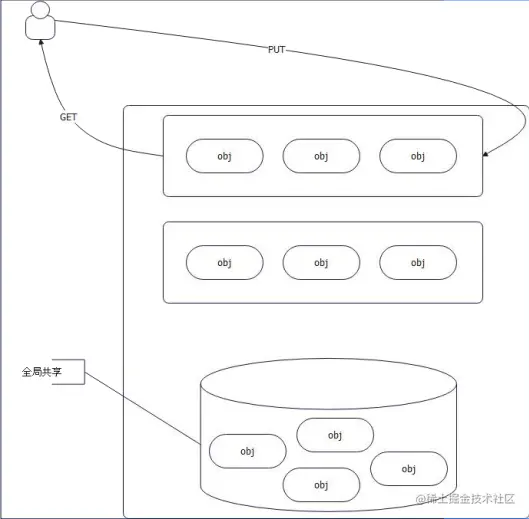
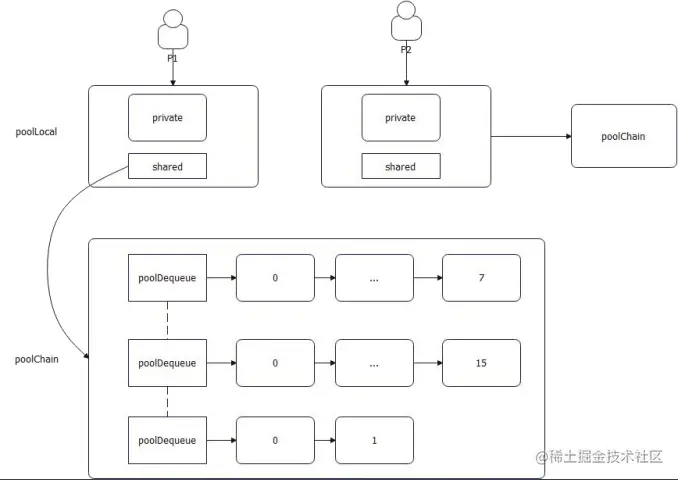
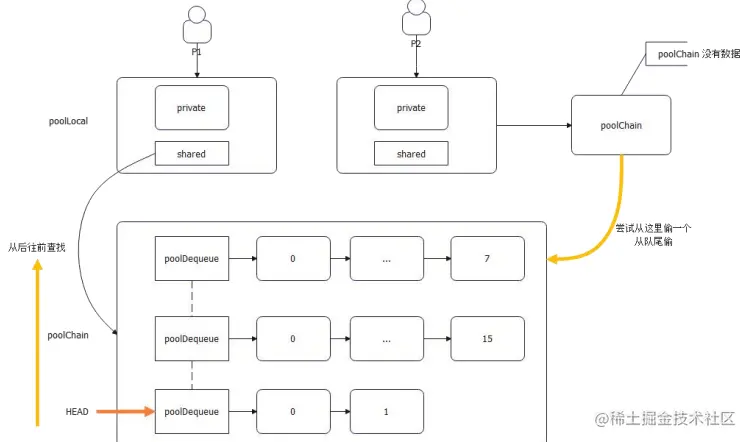
Go 的设计:
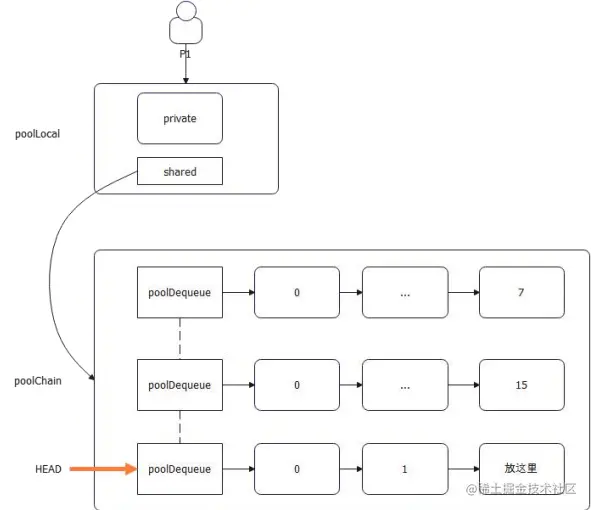
- 每个 P 一个 poolLocal 对象
- 每个 poolLocal 有一个 private 和 shared
- shared 指向的是一个 poolChain。poolChain 的数据会被别的 P 给偷走
- poolChain 是一个链表 + ring buffer 的双重结构
- 从整体上来说,它是一个双向链表
- 从单个节点来说,它指向了一个 ring buffer。后一个节点的 ring buffer 都是前一个节点的两倍
ring buffer 优势(实际上也可以说是数组的优势):
- 一次性分配好内存,循环利用
- 对缓存友好
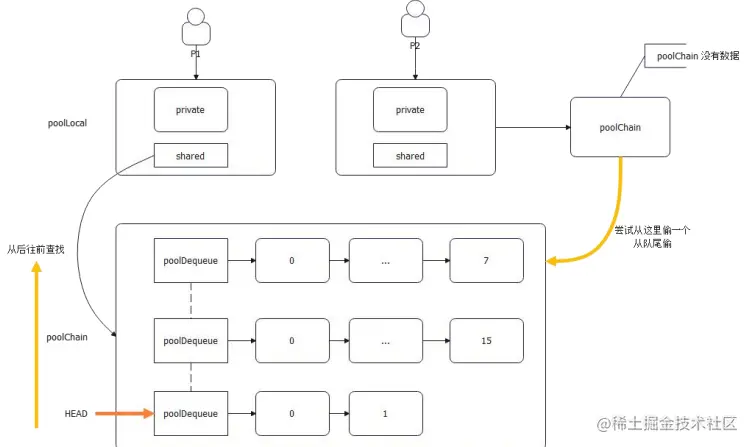
(1) Pool GET 步骤
所以,稍微思考一下就可以总结 Get 的步骤:
- 看 private 可不可用,可用就直接返回,
- 不可用则从自己的 poolChain 里面尝试获取一个;
- 从头开始找。注意,头指向的其实是最近创建的 ringbuffer;
- 从队头往队尾找;
- 找不到则尝试从别的 P 的 poolChain 里面偷一个出来。偷的过程就是全局并发,因为理论上来说,其它 P 都可能恰好一起来偷了;
- 偷是从队尾偷的
- 如果偷也偷不到,那么就会去找缓刑(victim)的;
- 连缓刑的也没有,那就去创建一个新的。
(2) Pool PUT 步骤
- private 要是没放东西,就直接放 private, 否则,准备放 poolChain;
- 如果 poolChain 的 HEAD 还没创建,就创建一个HEAD,然后创建一个 8 容量的 ring buffer,把数据丢过去;
- 如果 poolChain 的 HEAD 指向的 ring buffer 没满,则丢过去 ring buffer;
- 如果 poolChain 的 HEAD 指向的 ring buffer 已经满了,就创建一个新的节点,并且创建一个两倍容量的ring buffer,把数据丢过去;
3、Pool 与 GC
正常情况下,我们设计一个 Pool 都要考虑容量和淘汰问题(基本类似于缓存):
- 我们希望能够控制住 Pool 的内存消耗量
- 在这个前提下,我们要考虑淘汰的问题
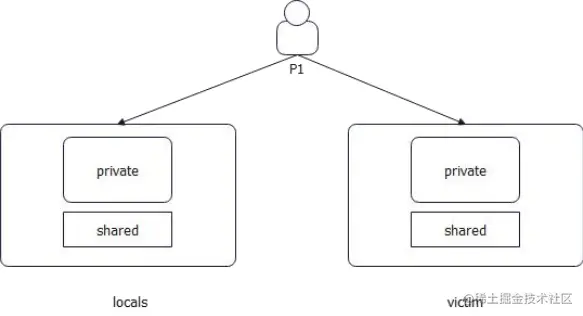
Go 的 sync.Pool 就不太一样。它纯粹依赖于 GC,用户完全没办法手工控制。 sync.Pool 的核心机制是依赖于两个:
- locals
- victim:缓刑
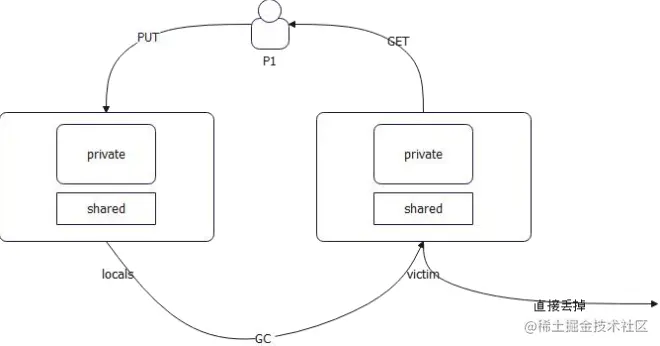
GC 的过程也很简单: - locals 会被挪过去变成 victim
- victim 会被直接回收掉
复活:如果 victim 的对象再次被使用,那么它就会被丢回去 locals,逃过了下一轮被 GC 回收掉的命运
优点:防止 GC 引起性能抖动
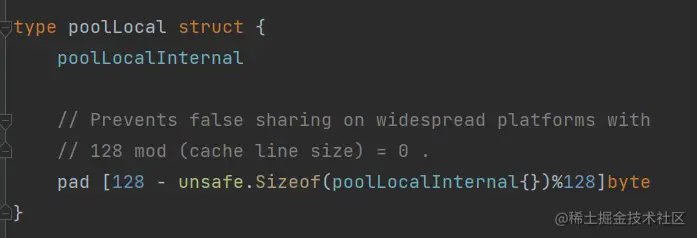
(1) poolLocal 和 false sharding
每一个 poolLocal 都有一个 pad 字段,是用于将poolLocal 所占用的内存补齐到 128 的整数倍。在并发下:所有的对齐基本上都是为了独占 CPU 高速缓存的 CacheLine。
(2) Pool 为什么最后采取找 victim 的
前面的步骤,有一个令人困惑的点是:偷不到别的 P时,再去找缓刑(victim)。
那么问题来了:偷是一个全局竞争的过程,但是找victim 不是,找 victim 和找正常的是一样的过程。显然先找 victim 会有更好的性能,那么为什么要偷一把呢?
因为 sync.Pool 希望 victime 里面的对象尽可能被回收掉。
4、代码演示
(1) 利用 Pool 实现简单的 buffer 池
Pool 还是比较简单的,大多数情况下都可以直接使用。但是在一些场景下,我们需要更加精细的控制,那么就会尝试自己封装一下 Pool。
要考虑:
- 如果一个 buffer 占据了很多内存,要不要放回去?
- 怎么控制整个池的内存使用量?因为依托于 GC 是比较不可控的:
- 控制单个 buffer 上限?
- 控制 buffer 数量?
- 控制总体内存?
type MyPool struct {
p sync.Pool
maxCnt int32
cnt int32
}
func (p *MyPool) Get() any {
return p.p.Get()
}
func (p *MyPool) Put(val any) {
// 大对象不放回去
if unsafe.Sizeof(val) > 1024 {
return
}
p.p.Put(val)
}
复制代码(2) 利用泛型封装 Pool
- 唯一要注意的点是这种封装带来的性能损耗。
- 本身也就是利用装饰器模式给 Pool 加上泛型的功能。
type BigObjHandler struct{}
func (h *BigObjHandler) DiscardBigObj(val any) any {
if unsafe.Sizeof(val) > 1024 {
return nil
}
return val
}
type MyPool[V any] struct {
BigObjHandler // 大对象处理装饰器
p sync.Pool
}
func (p *MyPool[V]) Get() V {
return p.p.Get()
}
func (p *MyPool[V]) Put(val V) {
v := p.DiscardBigObj(val)
if v == nil {
return
}
p.p.Put(v)
}
复制代码5、开源实例
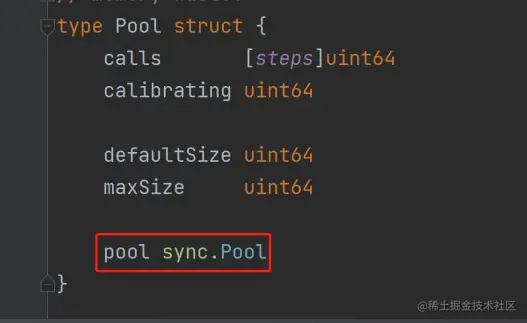
(1) bytebufferpool 实现要点
Github:github.com/valyala/byt…
- 也是依托于 sync.Pool 进行了二次封装
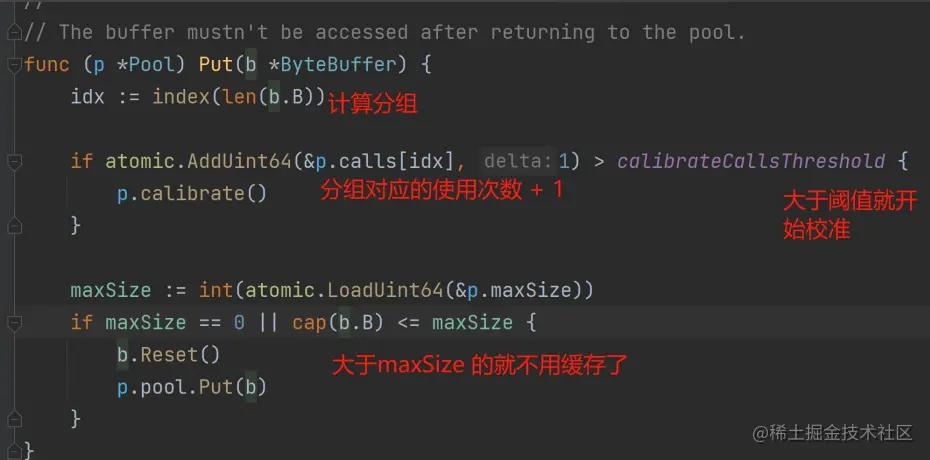
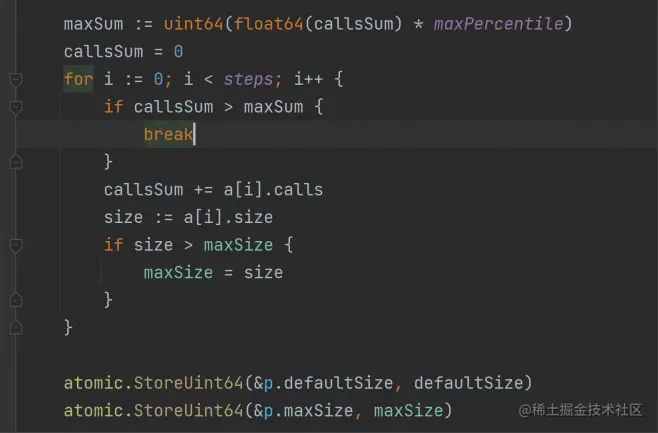
- defaultSize 是每次创建的 buffer 的默认大小,超过maxSize 的 buffer 就不会被放回去
- 统计不同大小的 buffer 的使用次数。例如 0-64bytes 的 buffer 被使用了多少次。这个我们称为分组统计使用次数
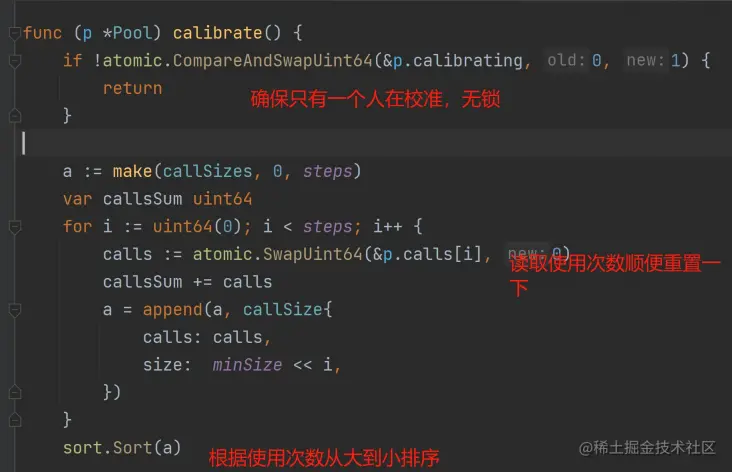
- 引入了所谓的校准机制,其实就是动态计算defaultSize 和 maxSize
我们搞 buffer 缓存,就是希望这些buffer 的 size 最好是恰好符合我们希望的。过小会扩容,过大不会浪费内存。所以 bytebufferpool 就根据使用次数来决定:
- 新创建的多大
- 超过多大的就没必要放回来
6、面试要点
基本上,sync.Pool 面试的热点就是两个:
- sync.Pool 和 GC 的关系:数据默认在 local 里面,GC 的时候会被挪过去 victim 里面。如果这时候有P 用了 victim 的数据,那么数据会被放回去 local 里面。
- poolChain 的设计:核心在于理解 poolChain 是一个双向链表加 ring buffer 的双重结构。
由这两个核心衍生出来的各种问题:
- 什么时候 P 会用 victim 的数据:偷都偷不到的时候。
- 为什么 Go 会设计这种结构?一个全局共享队列不好吗?这个问题要结合 TLB 来回答,TLB 解决全局锁竞争的方案,Go 结合自身 P 这么一个优势,设计出来的。
- 窃取:这个可以作为一个刷亮点的东西,结合 GMP 调度里面的工作窃取,原理都是一样的。
- 使用 sync.Pool 有什么注意点(缺点、优点)?高版本的 Go 里面的 sync.Pool 没特别大的缺点,硬要说就是内存使用量不可控,以及 GC 之后即便可以用 victim,Get 的速率还是要差点。
2.4 WaitGroup
WaitGroup 是用于同步多个 goroutine 之间工作的。常见场景是我们会把任务拆分给多个 goroutine 并行完成。在完成之后需要合并这些任务的结果,或者需要等到所有小任务都完成之后才能进入下一步。
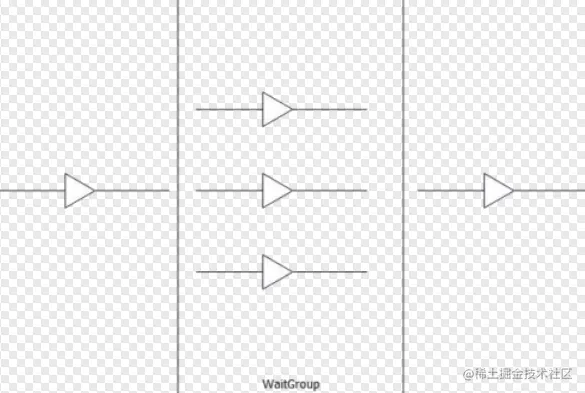
- 要在开启 goroutine 之前先加1
- 每一个小任务完成就减1
- 调用 Wait 方法来等待所有子任务完成
容易犯错的地方是 +1 和 -1 不匹配(非常不好测试):
- 加多了导致 Wait 一直阻塞,引起 goroutine 泄露
- 减多了直接就 panic
func waitGroup() {
wg := sync.WaitGroup{}
var res int64 = 0
for i := 0; i < 10; i++ {
wg.Add(1)
go func(delta int) {
atomic.AddInt64(&res, int64(delta))
defer wg.Done()
}(i)
}
wg.Wait()
fmt.Println(res)
}
复制代码1、WaitGroup 细节
WaitGroup 从使用方式来看,就知道要实现类似功能,至少需要:
- 记住当前有多少个任务还没完成
- 记住当前有多少 goroutine 调用了 wait 方法
- 然后需要一个东西来协调 goroutine 的行为
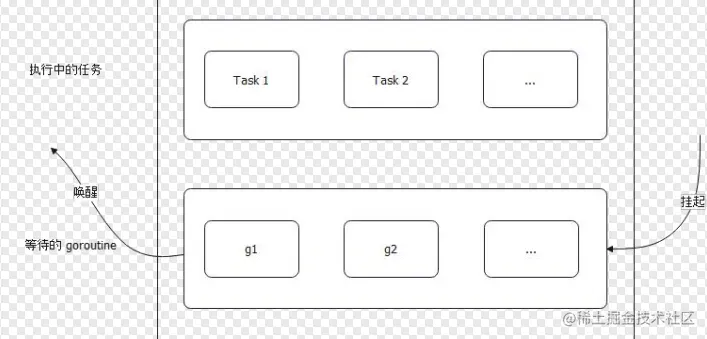
所以,按照道理来说,只需要设计三个字段来承载这个功能,然后搞个锁来维护这三个字段就可以了。
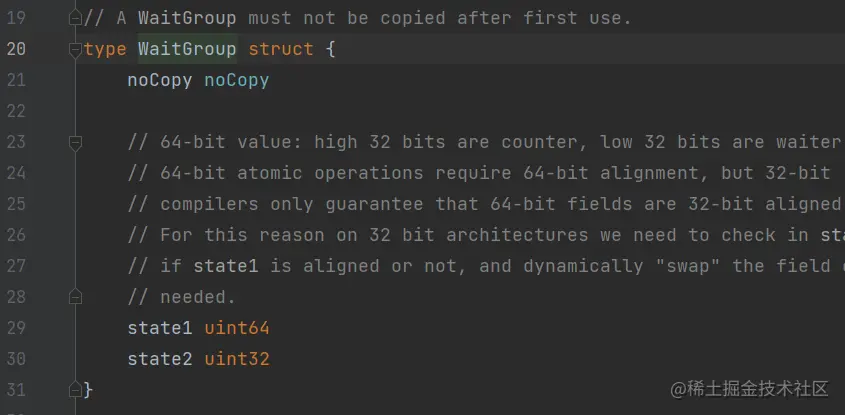
(1) WaitGroup 定义:
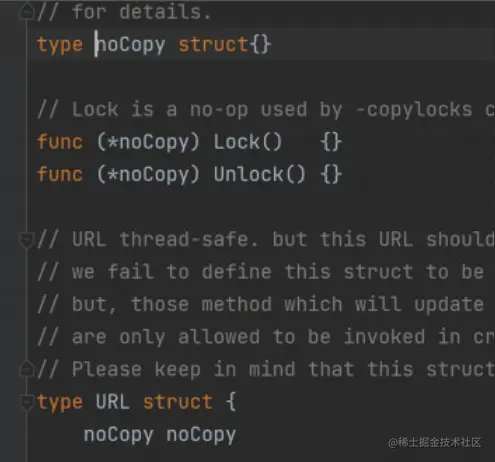
- noCopy:主要用于告诉编译器说这个东西不能复制。在 sync 包里面很多结构体有这个字段。我们也可以使用,比如说在 Dubbo-go 的URL 结构体使用了这个技巧。
- state1:在 64 位下,高 32 位记录了还有多少任务在运行;低 32 位记录了有多少 goroutine在等 Wait() 方法返回
- state2:信号量,用于挂起或者唤醒goroutine,约等于 Mutex 里面的 sema 字段(要注意横向对比)
- 本质上,WaitGroup 是一个无锁实现,严重依赖于 CAS 对 state1 的操作。
- 一大堆的注释就是解释 32 位对齐和 64 位对
齐,WaitGroup 要做一些处理。阅读源码的时
候不必纠结这个细节。
于 CAS 对 state1 的操作。
这是 Dubbo-go里面防止核心类URL 复制的做法
根据这两个字段我们可以进一步猜测 WaitGroup 的实现细节:
- Add:看上去就是 state1 的高 32 位自增 1,原子操作一把梭
- Done:看上去就是 state1 的高 32 位自减 1,原子操作一把梭,然后看看是不是要唤醒等待 goroutine,其实 Done 就相当于 Add(-1)
- Wait:看上去就是 state1 的低 32 位自增 1,同时利用 state2 和runtime_Semacquire调用把当前 goroutine 挂起
WaitGroup 代码难理解,就在于这些问题,要充分考虑各种并发场景。
(2) WaitGroup Add 方法
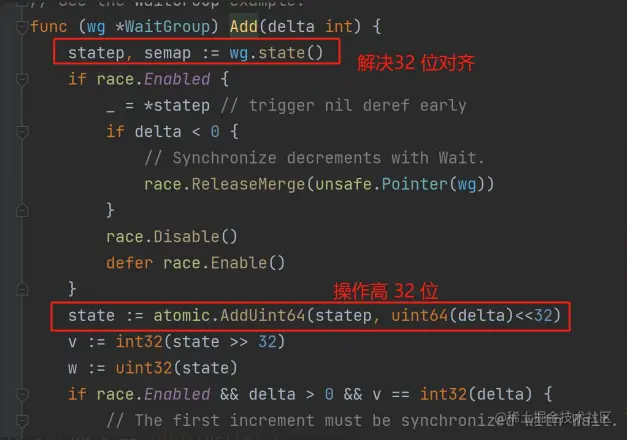
要唤醒等待的 goroutine 计数器 -1 ,直到为0
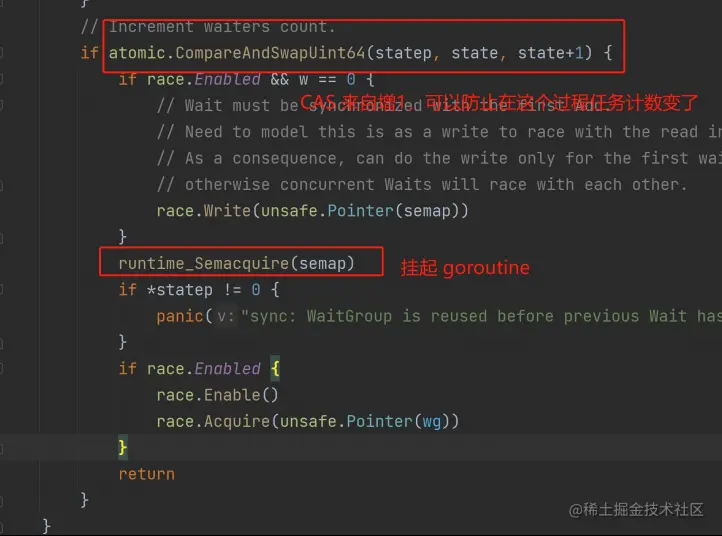
唯一要注意的就是这里并没有用原子操作,因为高 32 位可能也在操作。
而前面 Add 方法可以用原子操作,是因为 Add 方法不关心等待者的数量。只有在唤醒 goroutine 的时候才会考虑等待者数量,但是这个数量是从原子操作的返回值里面解析出来。
2、与 errgroup 对比 WaitGroup 和 errgroup.Group 是很相似的,可以认为 errgroup.Group 是对 WaitGroup 的封装。
- 首先需要引入 golang.org/x/sync 依赖
- errgroup.Group 会帮我们保持进行中任务计数
- 任何一个任务返回 error,Wait 方法就会返回error
func Errgroup() {
eg := errgroup.Group{}
var res int64 = 0
for i := 0; i < 10; i++ {
delta := i
eg.Go(func() error {
atomic.AddInt64(&res, int64(delta))
return nil
})
}
if err := eg.Wait(); err != nil {
panic(err)
}
fmt.Println(res)
}
复制代码3、WaitGroup 面试要点
- 面试官可能预设一个场景,比如说他问如何协调 goroutine 之间的工作,那么 WaitGroup 是可以的。
- WaitGroup 设计里面的 state1 的特点。
- WaitGroup 里面的 Wait 是怎么做到的?核心就是借助于 state2 这个字段,利用了runtime_Semaquire 和 runtime_Semrelease 两个调用。可以强调 Mutex 也是类似机制。