1. 完成将server和client端的mysql配置默认字符集为utf8mb4;
向/etc/my.cnf中添加:
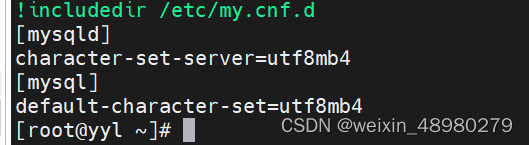
重启mysql:systemctl restart mysqld.service
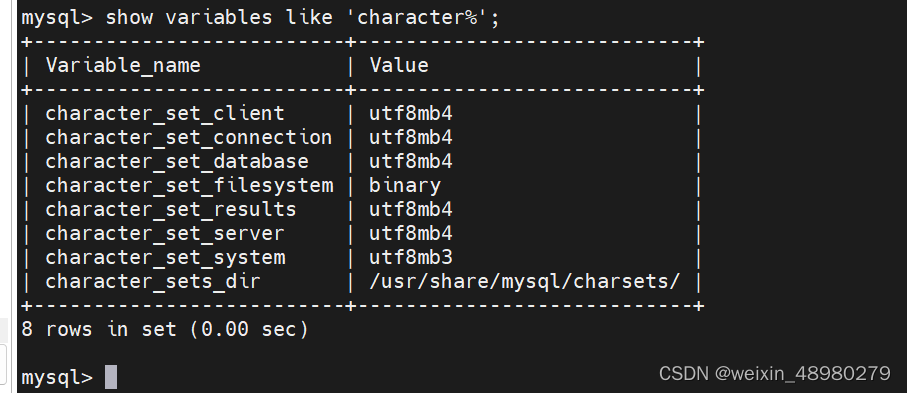
2. 掌握如何获取SQL命令的帮助,基于帮助完成添加testdb库,字符集utf8, 排序集合utf8_bin
help xxx
create database tsetdb character set utf8 collate utf8_bin;
3.总结mysql常见的数据类型。
整数型:
tinyint,1字节,一个字节8位,占一个符号位的话,剩下七位为数值,取值范围为-128到127,加上修饰符unsigned,变成无符号,取值翻倍变成0-255
smallint,两字节
mediumint,三字节
int,四字节
bigint,8字节
对于int(1),int(4)括号里面的只代表显示宽度,实际存储是不影响的,int还是存4字节。对于具体的场景应该根据实际情况来选择数据类型,从而节约存储空间
bool,boolean:布尔型,zero值为假,非zero为真
浮点型(就是取近似值):
比如一些计算过程得出的小数位数太长,可以用浮点数来截取
float(m,d)单精度
double(m,d),双精度
m是总个数,d是小数,float(4,2)就是存4位,其中保留两位小数
定点型
decimal(m,d)
字符串型:
char(n),固定长度,最多255字符,这里的字符意思是数字字母汉字都代表一个字符
varchar(n),可变长,最多65535字符,此处可变长开销比定长的char多1,但是又比char灵活,具体场景适用于此列数据忽长忽短的
tinytext,变长,最多255
text,变长,最多65535
时间型:
适合给表记录加上时间戳
timestamp
date
time
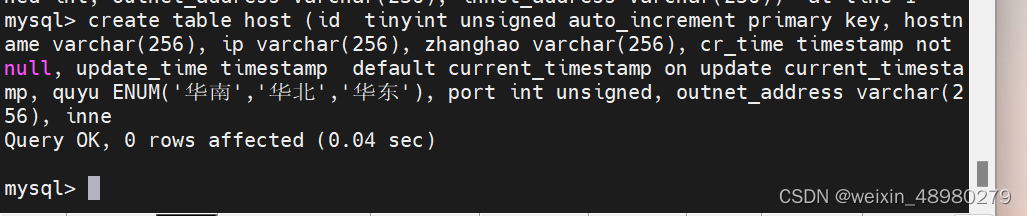
4. 创建一个主机表host,放在testdb中,要求字段 1) 主键自增id 无符号, tinyint. 2) hostname可变字符长度256,可为空。。3)ip 可变字符长度256,可为空。4)账号,可变字符长度256,可为空。5)密码,可变字符长度256,可为空。6)创建时间,时间类型,非空。7)更新时间,时间类型,默认当前时间。8)区域,只能在华南,华北,华东,三个区域之一。9)端口,无符号整数,可为空。10)外网地址,可变字符长度256,可为空。11)内网地址,可变字符长度256,可为空。
5. 给testdb.host表中添加多条数据。
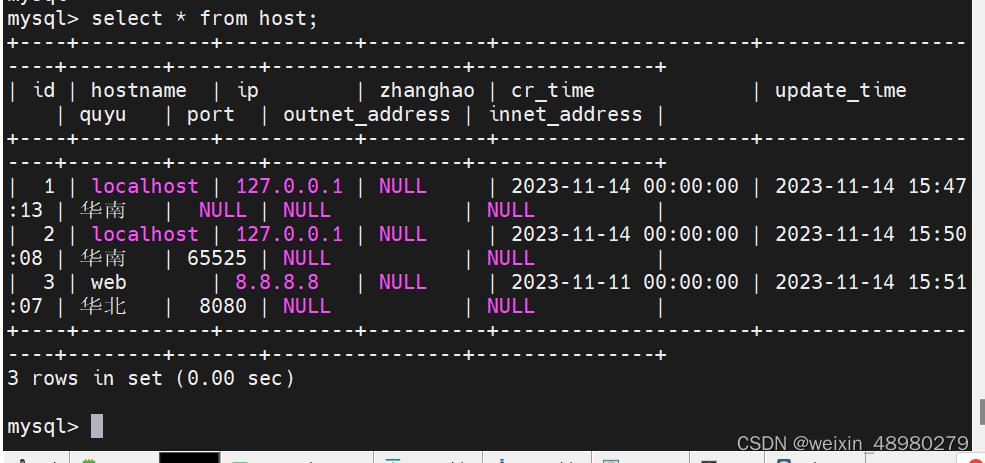
6. 根据表扩展出几个语句,完成总结DDL, DML的用法,并配上示例。
DDL(Data Definition Language):数据定义语言,有CREATE、ALTER、DROP等
创建表,创建数据库
create database testdb;
create table host (id int,hostname varchar(256));
ALTER用来修改表,增加列等
ALTER TABLE name ADD COLUMN department VARCHAR(50);
drop用于删除表数据库
drop table host;
DML(Data Manipulation Language):对具体数据的增删改(操纵),SELECT、INSERT、UPDATE、DELETE
insert into host(name,ip) values('local','127.0.0.1');
update host set ip = '127.0.0.1' where id = 3;
delete from host where id = 3;
7. 导入hellodb库,总结DQL, alias, where子句,gruop by, order by, limit, having使用示例。
mysql < hellodb.sql
select id from students;
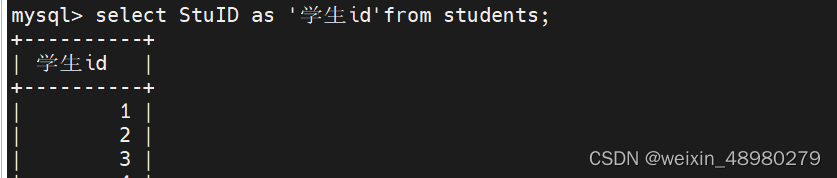
alias:字段可以做成别名
where:就是加上约束条件,where id = 1 where name like ‘%aaa%’
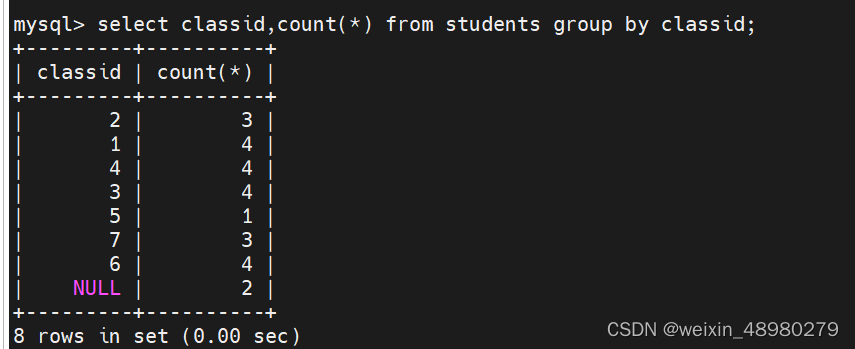
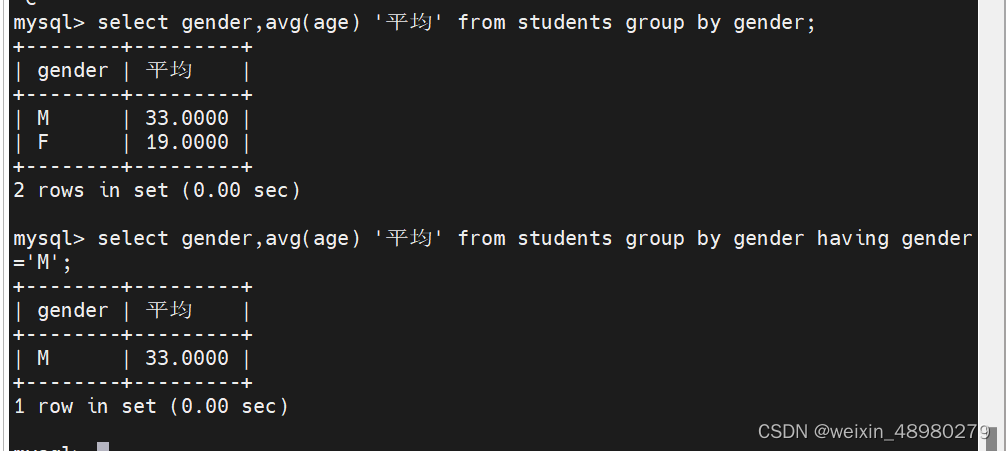
group by :GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组,group by classid 就是对classid相同的化成一组,count统计个数的时候就分组分别统计,不加group by 就统计查询的所有值
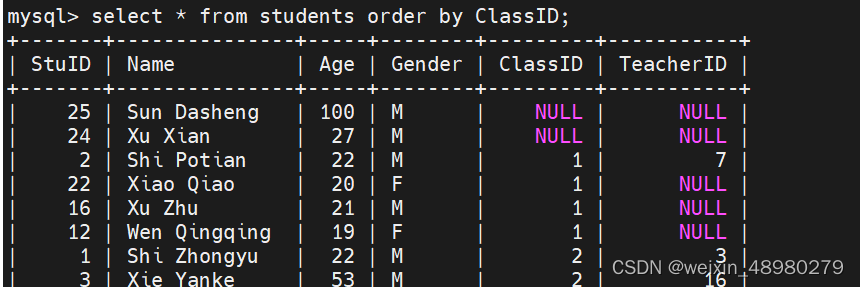
order by :根据哪一个字段进行排序,加desc就是逆序,后面多个字段就第一个字段相同比较第二个
limit,限制输出行数
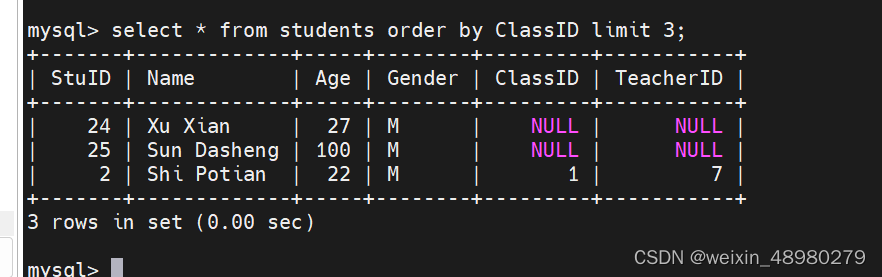
having
从分组后再过滤要使用having
分组前过滤就用where
8. 基于hellodb 库, 总结子查询,关联查询 ,交叉连接,内连接,左连接,右连接,完全连接,自连接。
子查询:查询套查询

子查询效率没有连接查询快
联合查询:
union,需要保证字段数一致,第一个查询两个字段的话,第二个也是两个字段
相当于将两个查询结果给纵向合并了
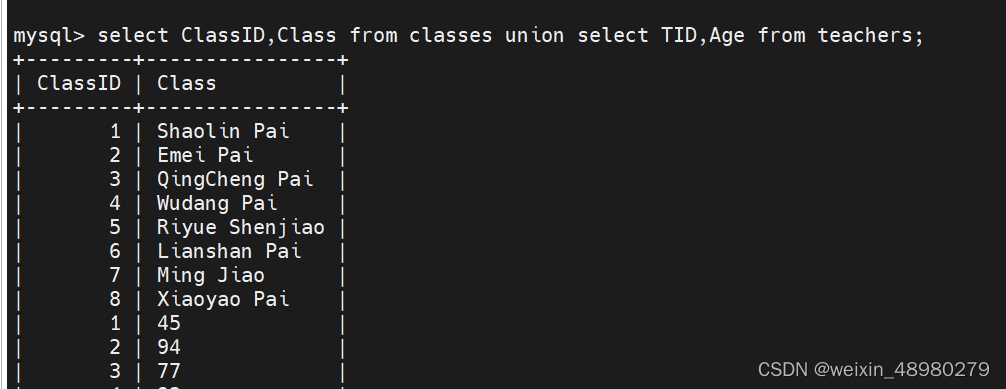
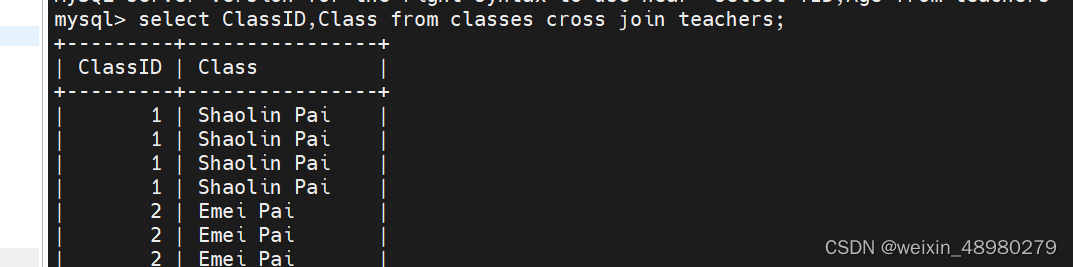
交叉连接
多表记录做笛卡尔积,慎用,比如两个10行10列的表做笛卡尔积后就变成了100行100列
关键字:cross join
内连接
取多表之间的交集,关键字,inner join xxx on
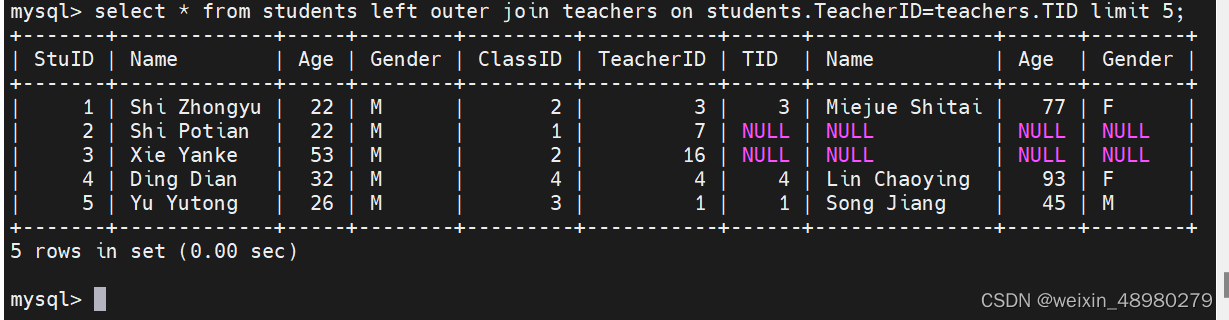
例:下图中就是查询两个表中TeacherID等于TID时候的记录,然后给他横向合并

左连接
左表为主查询右表数据,是以左表为基础,根据ON后给出的两表的条件将两表连接起来。结果会将左表所有的查询信息列出,而右表只列出ON后条件与左表满足的部分。左连接全称为左外连接
如下图,左表查询结果全部列出了,右表只列出了满足on后面条件的部分,不满足条件的就用null填充
右连接
右表为主查询左表数据,与左连接反过来,掌握一个即可,使用的时候将table1与table2交换位置。
完全连接
可以一次左连接加一次右连接,使用union去重
自连接
自己连自己,table分别取两个别名,table1与table2,然后对table1与table2来进行连接查询
9. 总结select语句处理顺序。

10. 总结mysql事件管理,用户管理,权限管理。
事件管理
类似于linux的crontab计划任务,但是mysql的定时任务可以精确到秒,他需要开启一个调度器event_scheduler
用户管理
mysql的用户需要结合host来,‘user’@‘hostname’
如root@‘localhost’,这种就只能本地登录,远程登录可以结合%来指明一个网段的可以登
命令:创建用户:create user abc@‘10.10.10.%’ identified by 1234546;
删除用户:drop abc@‘10.10.10.%’
修改用户密码:alter user abc@‘10.10.10.%’ identified by 12345467;
权限管理
授权:创建用户后需要给用户赋予权限,不然用户光登进来啥也干不了,一般授权也遵循最小权限,比如zabbix用户就只能访问zabbix数据库,其他数据库就没有权限。对数据库的权限还有细分的多种,为了方便就直接all,
grant all on 库名.表名 to abc@‘10.10.10.10’;
11. 基于apache, php, mysql搭建wordpress站点。
大致步骤,先搭建lamp环境,然后去wordpress官网下载包,下载后解压到/var/www/html下,这里需要对这个目录及以下的授权,然后web打开界面,如果能弹出wordpress的界面就说明成功了
12. 总结mysql架构原理
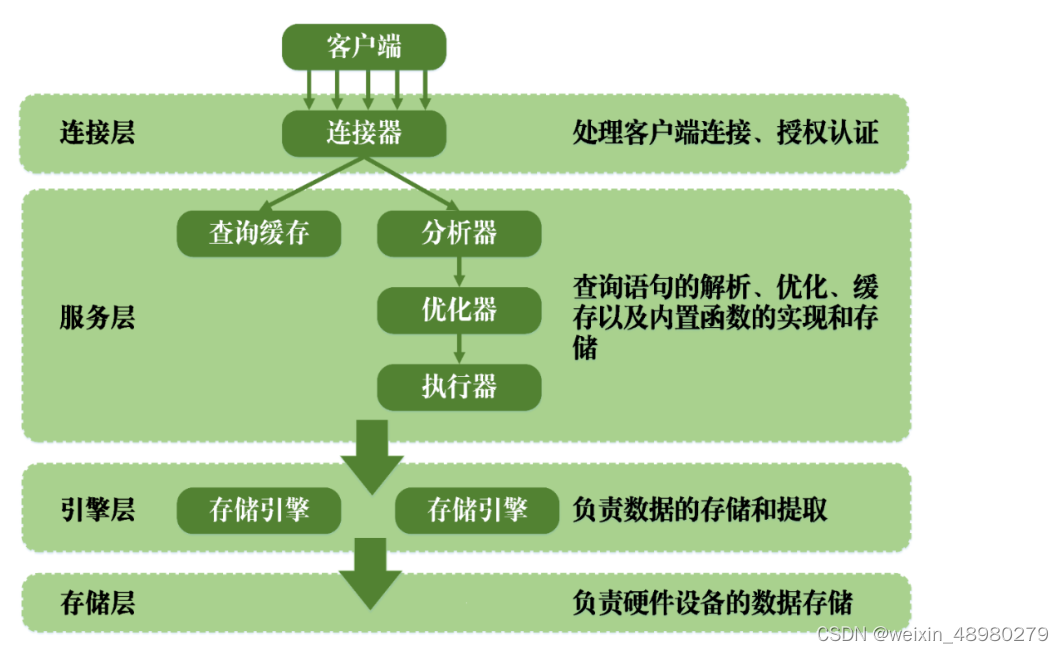
连接层: 负责处理客户端的连接以及权限的认证。
服务层: 定义有许多不同的模块,包括权限判断,SQL接口,SQL解析,SQL分析优化, 缓存查询的处理以及部分内置函数执行等。MySQL的查询语句在服务层内进行解析、优化、缓存以及内置函数的实现和存储。
引擎层: 负责MySQL中数据的存储和提取。MySQL中的服务器层不管理事务,事务是由存储引擎实现的。其中使用最为广泛的存储引擎为InnoDB,其它的引擎都不支持事务。
存储层: 负责将数据存储与设备的文件系统中。
13. 总结myisam和Innodb存储引擎的区别。
| myisam | innodb |
| 不支持事务 | 支持事务 |
| 表级锁 | 行级锁 |
| 读写互相阻塞 | 读写阻塞与事务隔离级别相关 |
| 只缓存索引 | 缓存数据和索引 |
| 不支持外键约束 | 支持外键约束 |
14. 总结mysql索引作用,同时总结哪些查询不到索引。
数据库类比成书籍,索引就是目录,比如某某数据在多少页,根据目录就可以直接翻到,没有目录的话只能一页一页翻,索引原理也是相似的。可以减少io次数,优化查询速度
15. 总结事务ACID事务特性
A:atomicity,原子性,在事务中的操作,要么全部成功,要么全部撤销,作为一个整体,不可部分执行
C:consistency,一致性,在事务开始之前和事务结束以后,数据库的完整性没有被破坏,从一致性转变到另一个一致性。
I,isolation,隔离性,一个事务在提交之前是1不被其他事务所见的,比如我在事务中添加了一个字段,只要我没有commit提交,就没有真正的执行下去,这里与华为NE系列交换机的配置功能相似,配置了一堆命令,实际没有生效,只有真正提交了才生效。
D.durability持久性,一旦事务提交,就会永久保存到数据库中
16. 总结事务日志工作原理。
1.事务日志,大小固定,循环写
MySQL 事务日志是一种二进制文件,用于记录 MySQL 数据库中的每个事务操作。当一个事务被提交时,其相关的修改操作将被记录到事务日志中。在数据库崩溃或系统故障等情况下,事务日志可以用来恢复丢失的数据。
MySQL 事务日志采用了 Write Ahead Logging (WAL) 技术,也就是说,在执行数据修改操作之前,先将修改操作写入到事务日志中,然后再将修改操作应用到数据库中。这样做的好处是,可以保证在数据库崩溃或系统故障的情况下,事务日志中已经记录的操作可以用来恢复数据。
MySQL 的事务日志主要包括两种,分别是 redo log(重做日志)和 undo log(回滚日志)。
- Redo Log(重做日志)
Redo Log 是 InnoDB 存储引擎特有的事务日志,在事务进行过程中,所有修改操作都会先被记录到 redo log 中,然后才会被写入到磁盘。
Redo Log 的作用是重做,通过重做日志,InnoDB 存储引擎可以在崩溃后进行数据恢复,保证数据的一致性和完整性。
- Undo Log(回滚日志)
Undo Log 也是 InnoDB 存储引擎特有的事务日志,主要用于进行事务的回滚操作。
在事务进行时,如果发生了回滚操作,则会通过 undo log 将对数据的修改操作逆向执行,恢复到事务操作前的状态。
Undo Log 的另一个作用是为了 MySQL 实现多版本并发控制(MVCC)。MySQL 的 MVCC 功能是通过在每次事务修改数据时,将修改前的数据记录到 undo log 中,然后其他事务如果需要访问该数据,就可以通过读取 undo log 来获取该数据在该事务操作前的状态。
综上,Redo Log 和 Undo Log 都是 InnoDB 存储引擎的重要组成部分,对 MySQL 数据库的事务管理和数据一致性起着关键作用。
17. 总结mysql日志类型,并说明如何启动日志。
日志类型有:
事务日志
错误日志
中继日志
通用日志
开启方式:general_log=ON
慢查询日志
开启方式:slow_query_log=ON
二进制日志
开启方式:
server-id=1
binlog_format="ROW"
log_bin=/usr/local/mysql-8.0/mysql_bin
18. 总结二进制日志的不同格式的使用场景。
二进制日志有三种格式:
基于语句型的,记录sql语句,日志量小,如数据不与时间挂钩的可以用这个。存在问题:如果存在sql语句中写了一条将当前时间插入到表中,如果用此二进制日志还原,会出现与原数据不一致的结果。
基于行型的,记录数据,直接记录修改过的一行行数据,日志量大,但是更安全。
混合模式,由系统判断,哪些该用语句型记录,哪些该用行记录。
19. 总结mysql备份类型,并基于mysqldump, xtrabackup完成数据库备份与恢复验证。
备份类型有:全量备份,增量备份,差异备份
mysqldump:
完全备份和还原:
1.开启二进制
在配置文件下[mysqld],添加
server-id=1
binlog_format="ROW"
log_bin=/usr/local/mysql-8.0/mysql_bin
2,备份
这里root用户免密,所以没有写账号密码

3.删除hellodb中的表
4. 停止二进制,source导入备份的文件,然后在开启。最后查看hellodb中,删除的表已经恢复了
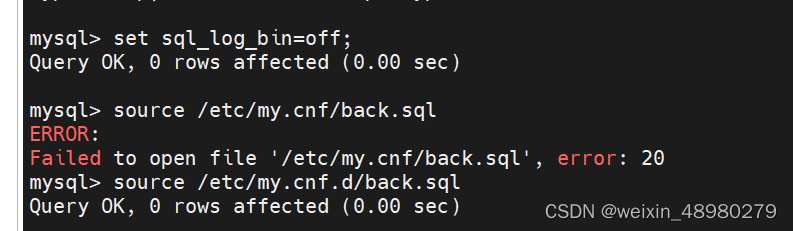
mysqldump数据恢复(利用全量备份与后面更新的binlog文件):
在前面全量备份的基础上,如果后面又有数据更新的话,那么binlog文件也会继续增长,此时还原最新状态就需要把binlog也还原进去。可以先grep查看当时全量备份的时候是备份到了binlog的那一点。记录下来,将此位置之后的binlog给存档
查看全量备份中的位置grep '\-\-\ CHANGE MASTER TO' ./mysql/mysql_bin. 位置在002日志的157这里
mysqlbinlog mysql/mysql_bin.000002 --start-position=157 > inc.sql
报错

查询报错信息后,解决方案:进配置文件先将他注释了
。最终,进入mysql ,先关闭sql_log_bin=0,
source all-2023-12-20.sql(全量备份)
source inc.sql (全量备份后的二进制日志)
可以做一步看一下数据的变化,他先恢复到全量时候的数据,再更新到备份二进制日志的位置
xtrabackup
开源且可以对innodb进行热备的工具
先在官网进行下载
1,备份
xtrabackup --backup --target-dir=/data/xtrabackupdir
2.预准备,这里需要将/var/lib/mysql给清空,数据库也停掉‘
xtrabackup --prepare --target-dir=/data/xtrabackupdir
xtrabackup --copy-back --target-dir=/data/xtrabackupdir
chown -R mysql. /var/lib/mysql
最后启动数据库
systemctl restart mysqld
可以登录进去看看数据是否还原了
xterabackup增量备份:
先全量备份(xtrabackup --backup --target-dir=/data/xtrabackupdir)
先添加个数据,然后增量复制
xtrabackup --backup --target-dir=/backup/ic1 --incremental-basedir=/data/xtrabackupdir
再添加个数据,然增量复制
xtrabackup --backup --target-dir=/backup/ic2 --incremental-basedir=/backup/ic1
还原数据(相当于把之前增量的部分逐个给加到全量备份里,最后只还原做好的全量就好了)
把原来的var/lib/mysql下面的数据先删了,停止服务
xtrabackup --prepare --apply-log-only --target-dir=/data/xtrabackupdir
xtrabackup --prepare --apply-log-only --target-dir=/data/xtrabackupdir --incremental-dir=/backup/ic1
xtrabackup --prepare --target-dir=/data/xtrabackupdir --incremental-dir=/backup/ic2
xtrabackup --cpoy-back --target-dir=/data/xtrabackupdir
20. 编写crontab,每天按表备份所有mysql数据。将备份数据放在以天为时间的目录下。
思路:在分库备份的基础上,再嵌套一层循环,来查询库里面的表,
1 1 * * * bash /etc/mysqlback.sh
cat mysqlback.sh
#!/bin/bash
TIME=`date +%F`
DIR=/backup
#PASS=123456
[ -d "$DIR" ] || mkdir $DIR
for DB in `mysql -uroot -p123456 -e 'show databases'|grep -Ev "^Database|.*schema$"`
do
for TABLE in `mysql -uroot -p123456 -e "use $DB;show tables"|grep -v 'Table'`
do
mkdir -p $DIR/$TIME
mysqldump -uroot -p123456 -F --single-transaction --source-data=2 -q $DB $TABLE > $DIR/$TIME/${DB}.$TABLE.sql
done
done
21. 编写crontab, 基于xtrabackup,每周1,周5进行完全备份,周2到周4进行增量备份。
1 1 * * 1 bash /etc/mysqlbackall.sh
1 1 * * 2 bash /etc/mysqlbackinc1.sh
1 1 * * 3 bash /etc/mysqlbackinc2.sh
1 1 * * 4 bash /etc/mysqlbackinc3.sh
1 1 * * 5 bash /etc/mysqlbackall.sh
1 1 * * 6 bash /etc/mysqlbackinc1.sh
1 1 * * 0 bash /etc/mysqlbackinc2.sh
cat /etc/mysqlbackall.sh
#!/bin/bash
xtrabackup --backup --target-dir=/data/xtrabackupdir
##其中data需要先创建cat /etc/mysqlbackinc1.sh
#!/bin/bash
xtrabackup --backup --target-dir=/backup/ic1 --incremental-basedir=/data/xtrabackupdircat /etc/mysqlbackinc2.sh
#!/bin/bash
xtrabackup --backup --target-dir=/backup/ic2 --incremental-basedir=/backup/ic1增量备份是基于上一次来做的,所以这里basedir都是写的上一次的,如果一直都写最开始全量备份,那就叫差量备份。
22. 总结mysql主从复制原理。
主要就是基于通过bin-log文件同步进一步来修改从库的数据。mysql是先写入到日志里,再进行数据库的更改(写入日志是顺序写,写道数据库的磁盘是随机的)
主节点:启动一个dump线程,用于给从节点的I/O线程发送bin-log
从节点:I/O线程,从主节点中请求bin-log,并存放到中继日志里
SQL 线程,从中继日志里读取日志文件,在本地完成重放(在从节点中,本身有中继日志就可以完成功能,不需要再开启从节点的binlog了)
23. 实现mysql主从复制,主主复制,半同步复制,过滤复制
1.主从复制:
主节点:
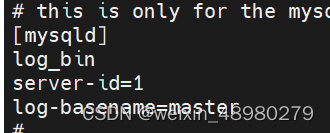
重启服务
grant replication slave on *.* to 'repluser'@'192.168.174.%' identified by '123456';
从节点:
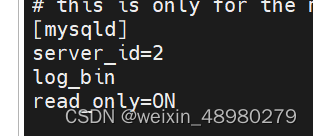
重启服务
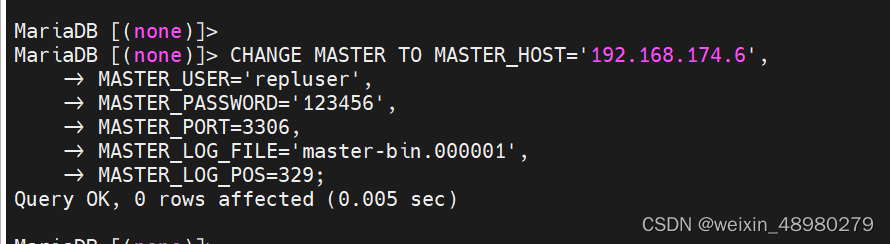
然后start slave;
查看show slave status\G;
然后可以在主节点修改数据,查看从节点是否会更新
2.主主复制:
原理:互相指定对方是从节点,都会把自己的数据更新同步给对方。这里注意,例如主键自增长id,需要给他奇偶分开,不然就冲突了
第一个主
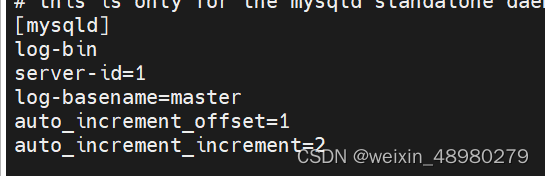
第二个主:
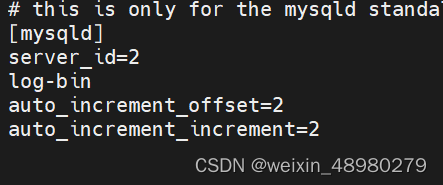
这里是在主从基础上改的,注意bin-log的文件名,一个前缀是master,一个没有前缀就是localhost
都重启mariadb。
这里是主从改的,只需要在原来主节点的基础上,添加之前从的操作就行
注意文件名与位置,账户在原来从节点也设了一个repluser

半同步复制:
默认mysql是异步复制的,我主节点只把日志发送给你就结束,不会等着从节点更新完毕返回确认才完成。可能出现主节点或从节点故障时,bin-log并没有被从节点接收到,最终导致数据的不一致。
半同步复制就是至少需要等待一个从库给ack确认。然后其余从库可以从已经更新的来拷贝,主库不必等待所有从库更新完成。
主节点:
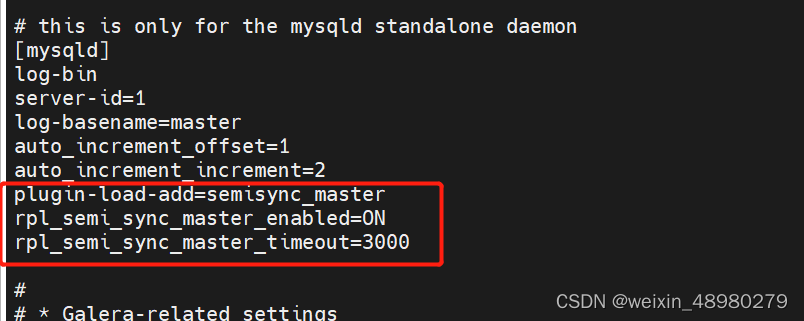
重启mariadb
从节点:
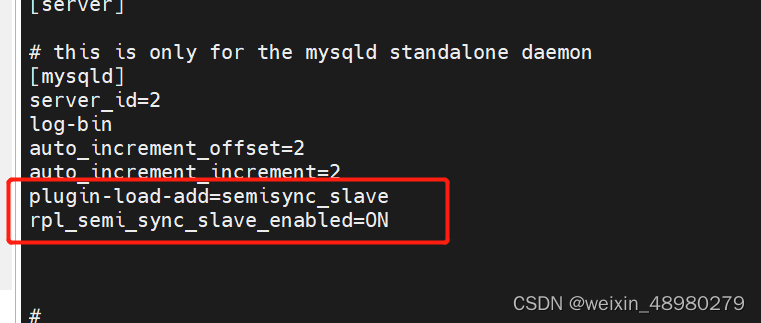
重启mariadb
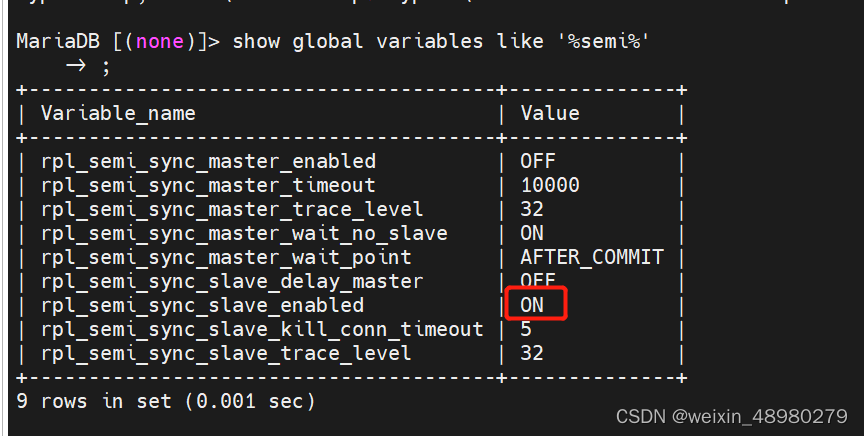
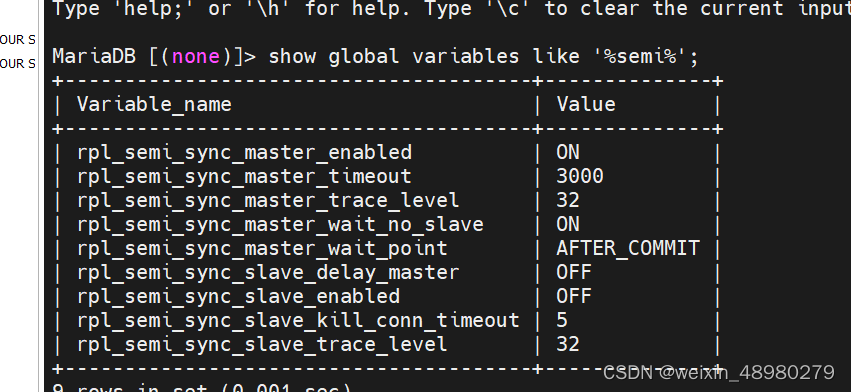
验证:
在主上创建数据库,立即成功。在从节点关闭stop slave后,主节点创建数据库需要3秒钟,就是之前设置的超时时间。
过滤复制:
就是从节点只能同步指定的库或者表。
24. 总结GTID复制原理,并完成GTID复制集群。
GTID,全局事务标识符。GTID可以看作position方式的延伸
mariadb默认开启gtid。所以在从节点执行change master这串命令时,只要保证执行前两边数据是一直的,那就可以不指定bin-log的位置

25. 总结主从复制不一致的原因,如何解决不一致,如何避免不一致
1.主节点bin-log格式为statement,建议改成row记录。
2.主库修改数据前,把binlog功能关了,不记录binlog,那从库也不会更新。做好账号权限把控,禁止此行为。
3.从节点没有设置read—only,误写入数据,配置文件中开启只读。
4.主从版本不一致,主高从低。一般版本升级都是向下兼容格式。建议从节点为高,那么可以兼容主节点低版本的日志格式。建议主从版本保持一致
5.主从的sql_mode不一致
26. 总结数据库水平拆分和垂直拆分
垂直拆分:
就是将不同的表拆到不同的数据库或者主机上,减轻单个库的访问压力
水平拆分:
将一张表的比如3000条记录,拆成三张表,一张表一千条。
27. 基于mycat实现读写分离
mycat,可以看作一个数据库的代理。支持故障自动切换,读写分离。
前提,先配置好一个mysql主从同步,新开一个虚拟机安装mycat作为代理
安装java:yum install -y java

把mycat的路径添加到PATH环境变量里面,记得source
mycat start
启动后查看端口,8066端口就是mycat的端口,查看日志,已经启动成功

修改 vim /apps/mycat/conf/server.xml
vim /apps/mycat/conf/schema.xml
开启后,停止从节点,查看是否会将读请求转到主节点上
28. 总结mysql高可用方案及高可用级别,搭建MHA集群和galera cluster,尝试搭建TIDB集群。
单副本
主主结构
MHA
galera cluster
PXC
29. 总结mysql配置最佳实践。
1.使用innodb存储引擎,支持事务,行级锁,性能更好
2.用UTF8MB4,这个才是真正的uft8编码
3.表中的字段定义,表的功能,最好加上注释
4.不使用存储过程,触发器,视图。这里意思是不在mysql内开这个功能,因为数据库压力本身比较大,可以将外部应用能实现的功能都交给外部应用去做
5.不存储大文件或大照片。大文件存在文件系统里更合适
30. 总结openvpn原理,并完成1键安装不同版本vpn脚本,可以适配rocky, ubuntu, centos主机。同时支持添加账号,注销账号。
vpn就是在公共网络中搭建一条加密通道。可以看作是虚拟的专线。
31. 配置LAMP要求 域名使用主从dns, dns解析到2个apache节点,apache和php在同一个节点, mariadb使用mycat读写分离并且要求后端为MHA集群。 架构规划图及解析一次请求和响应的流程和实践过程。
环境:
dns1:192.168.22.5
dns2:192.168.22.6
mysqlproxy:192.168.22.7
mysqlmaster:192.168.22.8
mysqlslave1:192.168.22.9
mysqlslave2:192.168.22.10
mha-manage:192.168.22.11
dns:
1.两台dns,先安装bind,yum install bind -y
dns主:
修改配置文件/etc/named.conf
监听地址和允许别人查询,直接注释。
添加自定义的zone文件,可以cp一个旁边的cp -p /var/named/named.localhost /var/named/yyll.zone,然后添加记录
[root@dns1 named]# cat yyll.zone
$TTL 1D
@ IN SOA master admin.yyl. (
333 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
NS master
NS slave
master A 192.168.174.8
slave A 192.168.174.9
mysqlproxy A 192.168.174.10
修改name.rfc文件
zone "yyl" IN {
type master;
file "yyll.zone";
};
使用named-checkconf和named-checkzone yyl /var/named/yyll.zone检测配置是否有问题
然后rndc reload重新加载dns
使用dig mysqlprox.yyl查询是否有记录
dns从节点设置:
在主节点的zone里添加一条
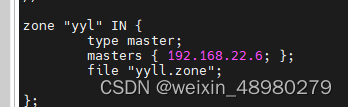
从节点:
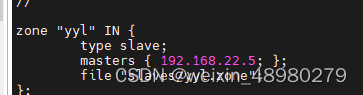
两边都重启,使用dig来验证
mycat安装:
把mycat的压缩包拷贝到/apps
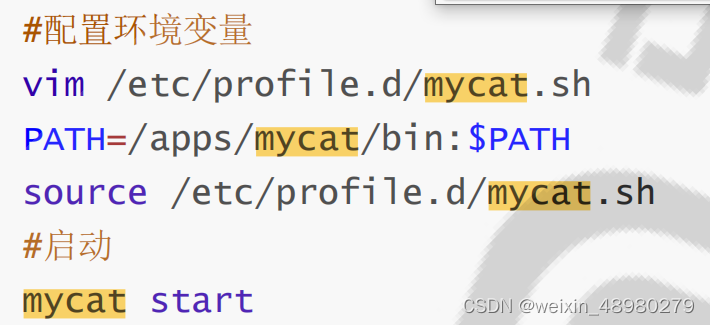
mycat status
mysql -uroot -p123456 -h 127.0.0.1 -P8066
这里连接的是mycat模拟的库
后续待完成