1. 总结 哨兵机制实现原理,并搭建主从哨兵集群。
哨兵集群中的每个节点都会启动三个定时任务
- 第一个定时任务: 每个sentinel节点每隔1s向所有的master、slaver、别的sentinel节点发送一个PING命令,作用:心跳检测
- 第二个定时任务: 每个sentinel每隔2s都会向master的__sentinel__:hello这个channel中发送自己掌握的集群信息和自己的一些信息(比如host,ip,run id),这个是利用redis的pub/sub功能,每个sentinel节点都会订阅这个channel,也就是说,每个sentinel节点都可以知道别的sentinel节点掌握的集群信息,作用:信息交换,了解别的sentinel的信息和他们对于主节点的判断
- 第三个定时任务: 每个sentinel节点每隔10s都会向master和slaver发送INFO命令,作用:发现最新的集群拓扑结构
主观下线
这个就是上面介绍的第一个定时任务做的事情,当sentinel节点向master发送一个PING命令,如果超过own-after-milliseconds(默认是30s,这个在sentinel的配置文件中可以自己配置)时间都没有收到有效回复,不好意思,我就认为你挂了,就是说为的主观下线(SDOWN),修改其flags状态为SRI_S_DOWN
-
超过半数的哨兵认为此节点都down了,就会重新选举一个主出来,此故障迁移的过程会对redis的配置文件进行修改,重新指向新的主
哨兵集群:
先搭建主从集群(这里一主两从)
主:192.168.174.4
从1:192.168.174.5
从2:192.168.174.6
所有主从节点:
配置文件修改:

从节点:
echo "replicaof 192.168.174.4 6379" >> /etc/redis.conf
所有节点:
systemctl enable --now redis
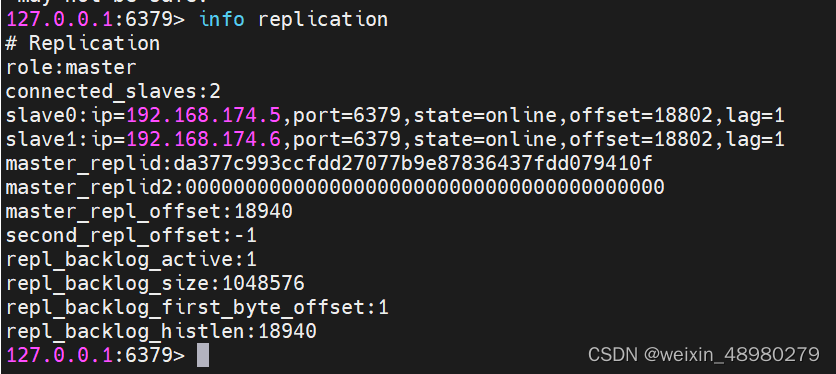
主节点查看:
登录:redis-cli -a 123456
修改sentinel的配置文件:
[root@master ~]# cat /etc/redis-sentinel.conf |grep -Ev "^$|^#"
bind 0.0.0.0
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel.pid"
logfile "/var/log/redis/sentinel.log"
dir "/var/lib/redis"
sentinel myid dbc3973f06f2c684fb6a5b67c81d8739a1b07ced
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 192.168.174.5 6379 2
sentinel auth-pass mymaster 123456
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
protected-mode no
supervised systemd
sentinel known-replica mymaster 192.168.174.4 6379
sentinel known-replica mymaster 192.168.174.6 6379
sentinel known-sentinel mymaster 192.168.174.5 26379 654c9a380be3b43692f4e62f79f43f605c283fda
sentinel known-sentinel mymaster 192.168.174.6 26379 dfc68c7f27d845d988298858ff29fc8f370daae1
sentinel current-epoch 1
[root@master ~]#
三个文件都保持相同,然后启动redis-sentinel:
然后killall redis-server
查看sentinel的日志,最终会主会切换到其他地方

配置文件也会自动修改

2. 总结redis cluster工作原理,并搭建集群实现扩缩容。
cluster模式解决了哨兵模式中单一主节点的性能瓶颈问题。无中心架构的cluster,cluster至少需要三个主节点,由hash槽的方式来分担业务,redis cluster有0-16383的槽,每一个key存储时先通过哈希计算和与16384取余得到一个数,这个数在谁的区间里就存给谁,并不是第一次就可以命中,第一次如果没有命中,会告诉你这个slot应该存哪。也符合集群能扩容的功能,不管扩不扩容,key计算出来的slot值是不变的,slot该归谁存又集群决定。
集群搭建:
环境:
版本redis5.0
192.168.174.4(M)
192.168.174.5(M)
192.168.174.6(M)
192.168.174.7(S)
192.168.174.8(S)
192.168.174.9(S)
所有节点:
dnf install redis -y
然后修改redis.conf文件
bind 0.0.0.0
masterauth 123456
requirepass 123456
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-require-full-coverage no
所有节点启动redis:
systemctl enable --now redis
第一个节点输入:
redis-cli -a 123456 --cluster create 192.168.174.4:6379 192.168.174.5:6379 192.168.174.6:6379 192.168.174.7:6379 192.168.174.8:6379 192.168.174.9:6379 --cluster-replicas 1先查看主从状态:
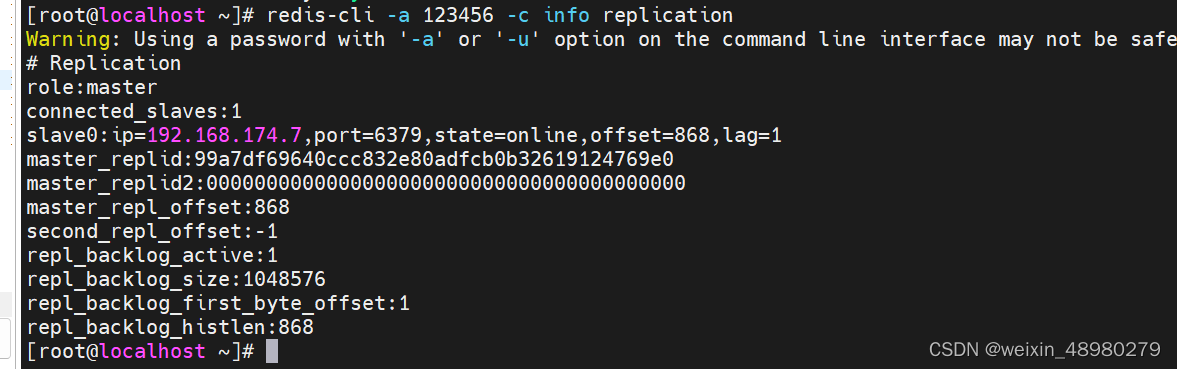
这里看相当于有三个主从
再查看cluster的状态:
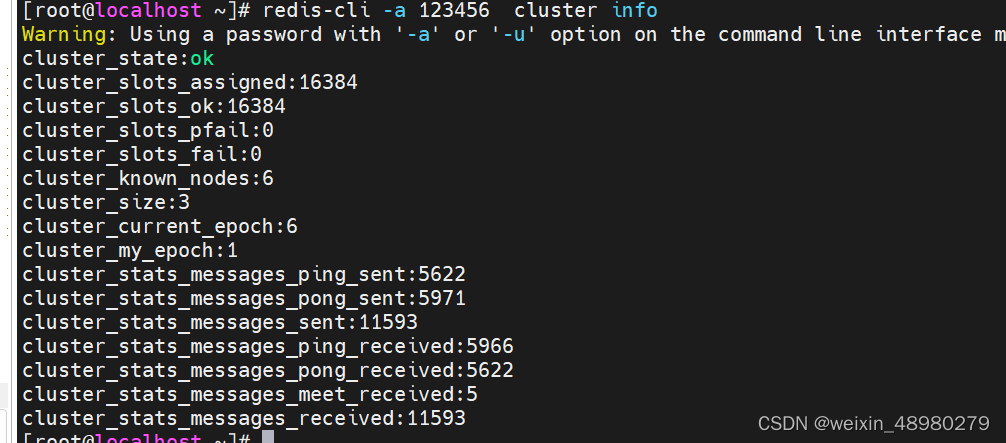
缩容:
输入下命令调整slots的分配,正常均分,考虑到redis服务器可能性能有差异,可以给性能高的多分配一点。
redis-cli -a 123456 --cluster reshard 192.168.174.4:6379
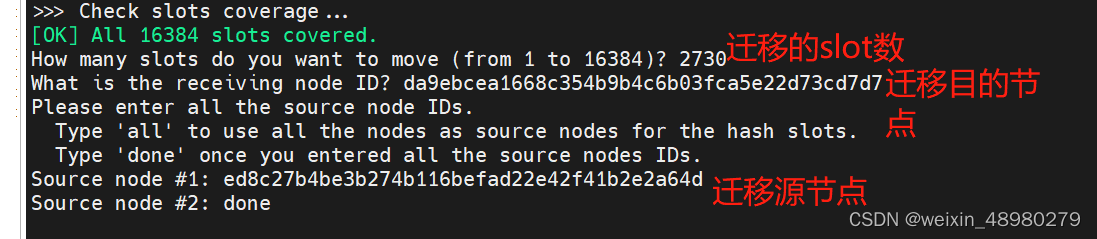
通过此命令先将192.168.174.6的5461个slot一半一半迁到172.4与174.5上
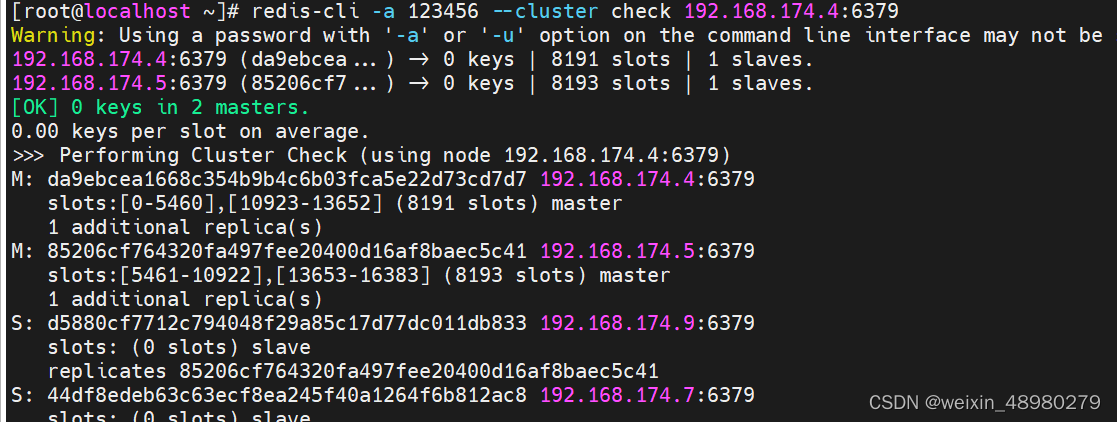
保证要删除的174.6上没有slot:

删除空的174.6节点和174.8节点,都是用此命令,用不同的node id:

最终结果:
扩容:
在缩容的基础上,再次将174.6,174.8两个节点添加回去
174.6与174.8:
killall redis-server
rm -f /var/lib/redis/*
systemctl restart redis
然后在集群中的一个节点执行(把6与8节点添加回去):

可见添加回去默认是主节点,还需要将其中新加的一个变成slave
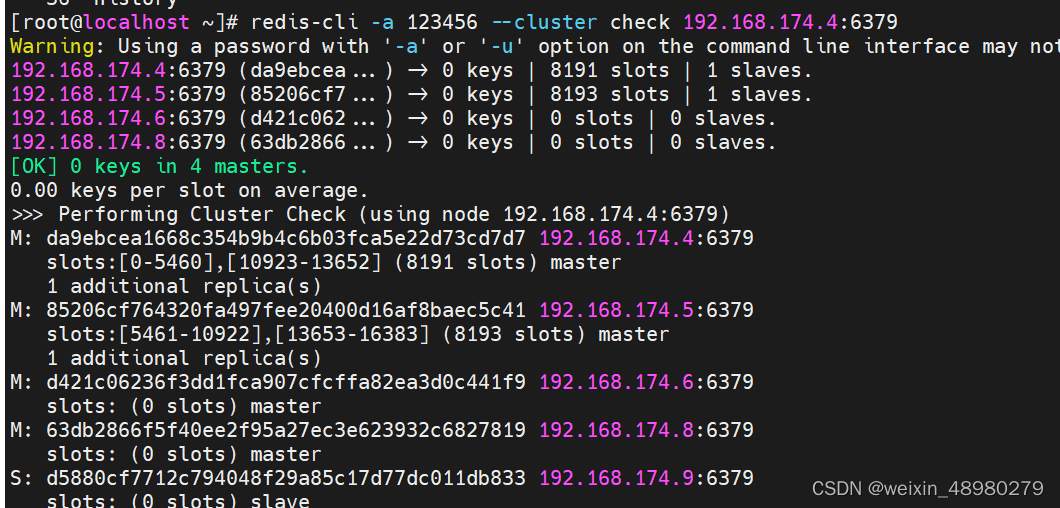
登录174.8,将其设成slave:
指向174.6

再次查看集群状态:
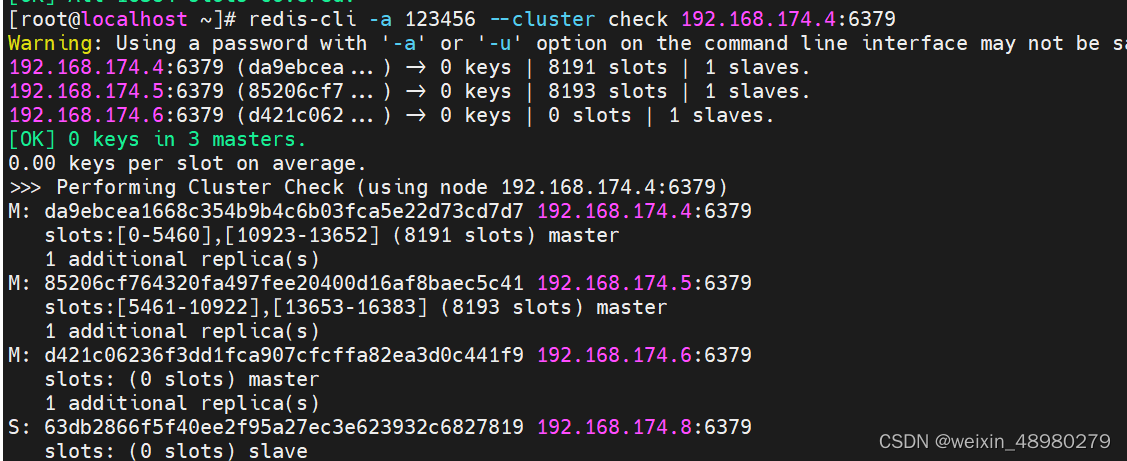
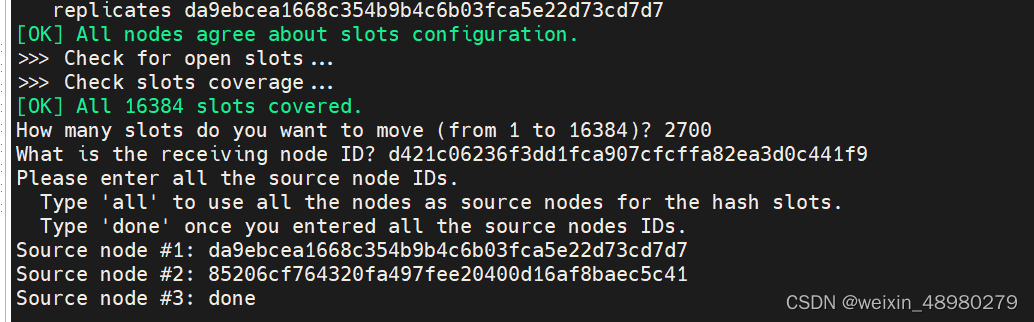
将slot分一部分给新加进去的主:
redis-cli -a 123456 --cluster reshard 192.168.174.4:6379
3. 总结 LVS的NAT和DR模型工作原理,并完成DR模型实战。
NAT:
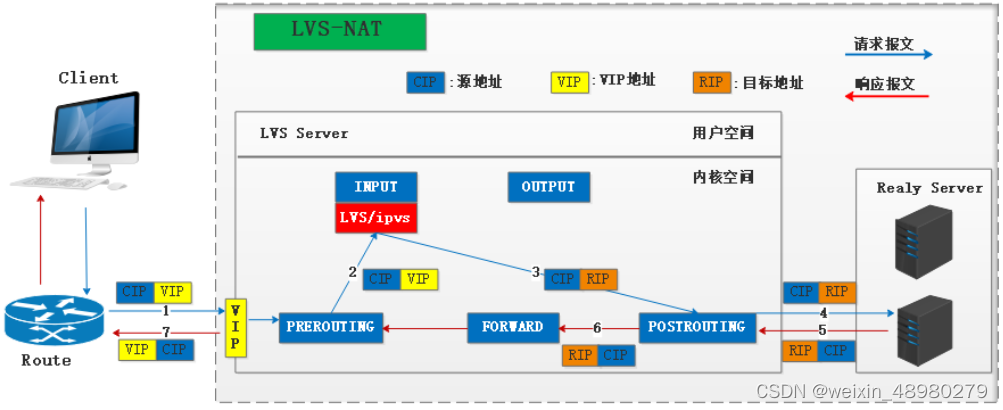
client请求资源,当报文达到director时,源和目标IP是CIP-VIP,IPVS会强行修改目标地址为RIP,将报文从INPUT发向POSTROUTING,源和目标IP修改为CIP-RIP,RS验证目标地址是本地地址,则接受报文并处理请求
RS响应请求,由于报文源IP是CIP,所以相应报文的目标IP是CIP;将响应报文发送给网关director后,director会通过SNAT将源IP修改为VIP,相当于中间人攻击
DR:
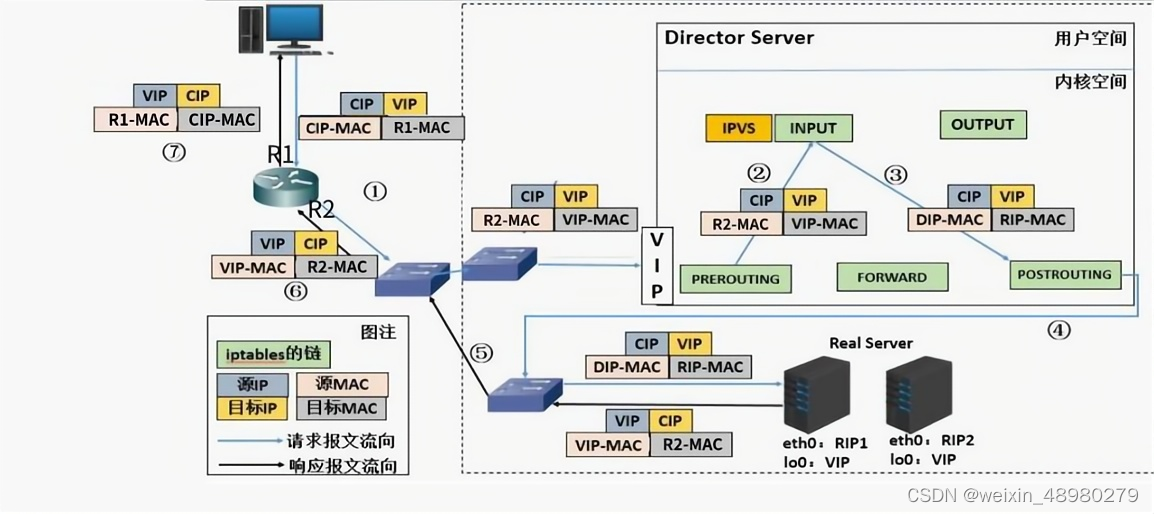
1) 客户端 发送请求到 Director Server,请求的数据报文(源 IP 是 CIP,目标 IP 是 VIP) 到达内核空间。
(2) Director Server 和 Real Server 在同一个网络中,数据通过二层数据链路层来传输。
(3) 内核空间判断数据包的目标 IP 是本机 VIP,此时 IPVS 比对数据包请求的服务是否是集群服务,是集群服务就重新封装数据包。修改源MAC 地址为 Director Server 的 MAC 地址,修改目标 MAC 地址为 Real Server 的 MAC 地址,源IP 地址与目标 IP 地址没有改 变,然后将数据包发送给 Real Server。(目的IP是配置在回环口上的VIP,目的MAC是RIP-MAC,物理网卡的MAC)
(4) 到达 Real Server 的请求报文的 MAC 地址是自身的 MAC 地址,就接收此报文。数 据包重新封装报文(源 IP 地址为VIP,目标 IP 为 CIP),将响应报文通过 lo 接口传送给物理 网卡然后向外发出。
(5) Real Server 直接将响应报文传送到客户端。
实战:
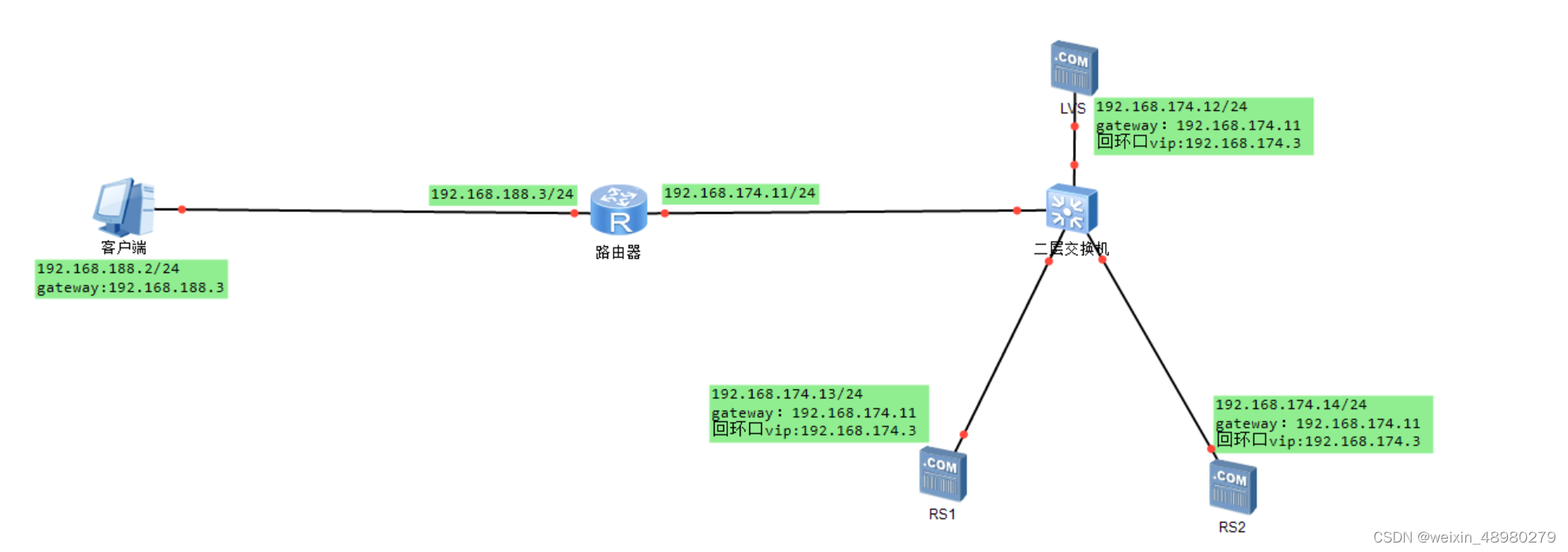
客户端1:虚拟机,配置仅主机模式的网卡
路由器:创建一台linux虚拟机,双网卡,一个网卡NAT模式,一个网卡仅主机模式,开启ip forward转发模式
交换机:vmware在nat模式下,自带交换机,即所有nat的网卡可以看作接在了同一个虚拟交换机上,无需配置
LVS,RS1,RS2安装上图进行配置,网关需要修改成此路由器下接口的ip,不是vmware默认的网关
客户端配置:
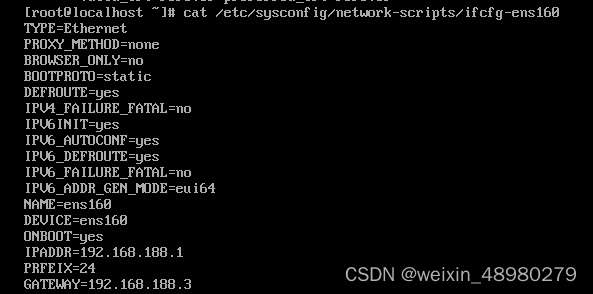
路由器配置:
配置ip:仅主机网卡:192.168.188.3
NAT网卡:192.168.174.11
开启转发(在开启前后用客户端ping LVS看一下):

RS1、RS2配置:
安装并启动httpd服务


先修改内核参数,避免ip冲突
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
RS1,RS2配置回环口的vip:
ifconfig lo:1 192.168.174.3/32
LVS配置:
NAT网卡:192.168.174.12
回环口配置vip:
ifconfig lo:1 192.168.174.3/32
下载ipvsadm包,并配置策略
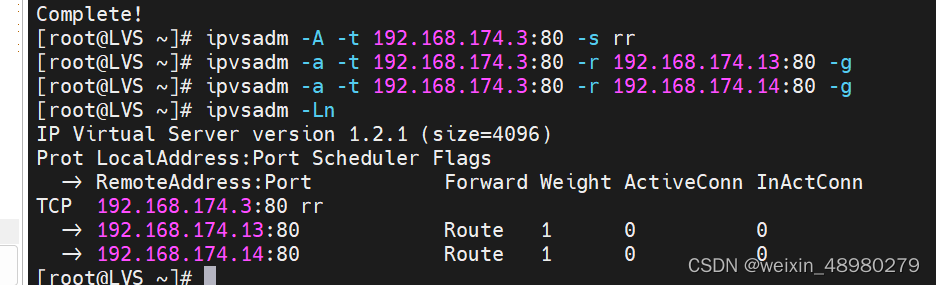
参数解析:
-A add virtual service
-t TCP
-s 调度算法,rr就是轮询
-a add real server
-r server-address server-address is host (and port)
-g gatewaying (direct routing) (default)
在客户端进行测试:

4. 总结 http协议的通信过程详解
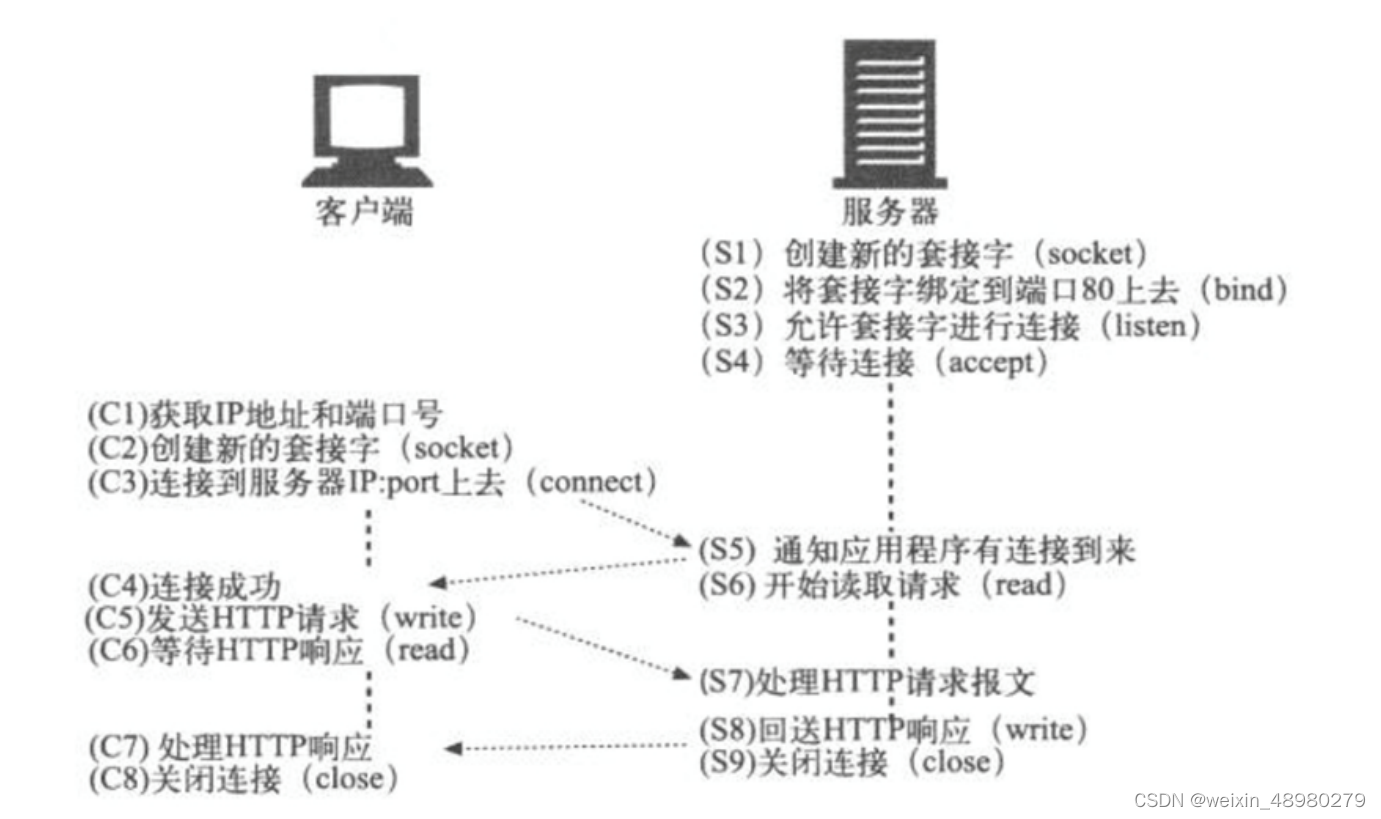
1.在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能进行更深层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80,tcp的80端口连上后才能进行后面的http通信
2.一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令,如GET。
3.客户机向服务器发出请求后,服务器会客户机回送应答
4.一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码Connection:keep-alive。TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽
5. 总结 网络IO模型和nginx架构
阻塞性IO(blocking IO):
用户线程通过系统调用read发起IO操作,由用户空间转到内核空间,数据包到内核后,再拷贝到用户空间完成read操作,在等待内核的过程中,线程被阻塞,不能干其他事
优点:程序简单
缺点:每一个连接都需要一个进程/线程单独处理,如1000个并发连接,会导致线程来回切换开销大
非阻塞性IO(nonblocking IO):
用户发起IO请求时立即返回,需要不断的进行请求,直到读到数据为止,发起请求有一个时间间隔。
IO多路复用型(IO mutiplexing):
一个线程可以同时(交替)监控和处理多个文件描述符对应的各自的IO,用户进程调用select,整个进程会被bolck,内核会监视所有select负责的socket,任何一个socket数据准备好了,select就返回,此时用户进程在调用read操作,从内核拷贝到用户进程中
信号驱动式IO(signal-driven IO):
进程不用等待,不用轮询,而是数据报准备好了后,发送信号通知进程,过来进行系统调用取数据,取数据的过程也是阻塞的。和阻塞性IO比,省去了无数据报准备好到数据报准备好的这段时间
异步IO(asyncchronous IO):
发起请求后无需等待,无需轮询,与信号驱动式的区别式,信号驱动是告诉你准备好了才让你发起请求,异步IO是你请求的时候不管准备与否,直接返回,准备好之后会把数据返回给你,整个过程非阻塞
nginx架构:
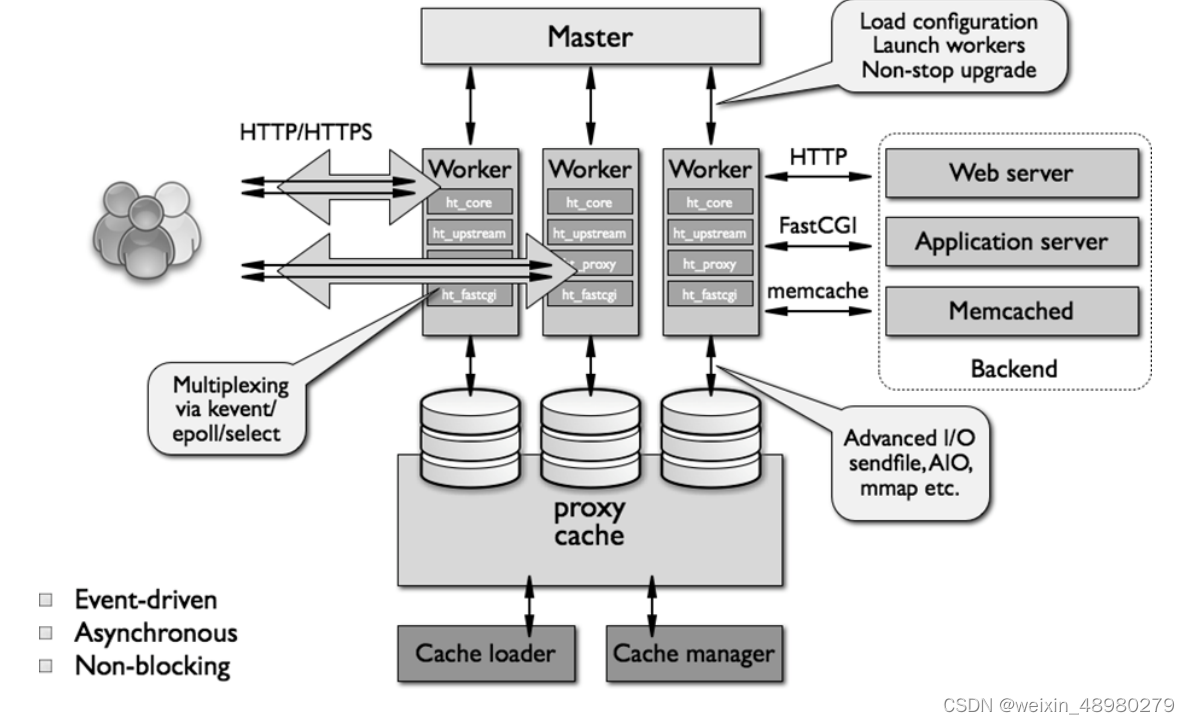
后台进程包含一个master进程和多个worker进程
master进程主要用来管理worker进程,worker进程异常停止会自动重启worker
worker进程:竞争处理网络请求,将请求送到各个模块进行处理,worker数一般为cpu核数
6. 完成nginx编译安装脚本
#!/bin/bash
create_nginx_user(){
id nginx &> /dev/null
if [ $? -eq 0 ];then
echo "nginx用户已创建"
else
echo "nginx用户创建中"
useradd -s /sbin/nologin -r nginx
fi
}
mkdir -p /apps/nginx &> /dev/null
nginx_DIR="/apps/nginx"
OS_cpu_core_num=$(lscpu|grep '^CPU(s)'|awk '{printf $2}')
# install depend
nginx_install(){
dnf -y install make gcc-c++ libtool pcre pcre-devel zlib zlib-devel openssl openssl-devel perl-ExtUtils-Embed
cd /opt
if [ -e /opt/nginx-1.24.0.tar.gz ];then
tar zxvf nginx-1.24.0.tar.gz
cd /opt/nginx-1.24.0
else
echo "nginx安装包未找到,请检查opt下是否存放安装包"
exit
fi
./configure --prefix=/apps/nginx/ --user=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module
make -j $OS_cpu_core_num && make install
if [ $? -eq 0 ];then
echo "nginx安装完成"
else
echo "nginx安装失败"
exit
fi
}
create_nginx_user
nginx_install
7. 总结nginx核心配置,并实现nginx多虚拟主机
配置:
user nginx nginx; #启动nginx的用户与组
worker_processes 4;### 一般设成cpu核数
错误日志记录配置:语法 error_log logs/error.log [debug|info|notice|warn|error|crit|alert|emerg]
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
error_log /apps/nginx/logs/error.log error;
#pid logs/nginx.pid; #pid文件路径
pid /apps/nginx/logs/nginx.pid
events {
worker_connections 1024; ##单个进程的最大并发数
use epoll;使用epoll事件驱动
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
##每一个server对应一个虚拟主机
server {
listen 80;
server_name localhost; 虚拟主机名
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html; 指定URL特性
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
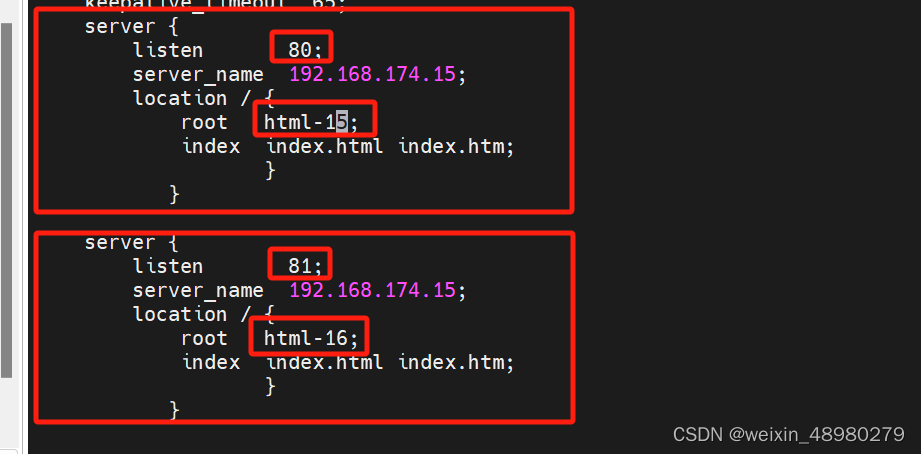
多虚拟主机:
这里基于端口不同来做:
nginx.conf文件:
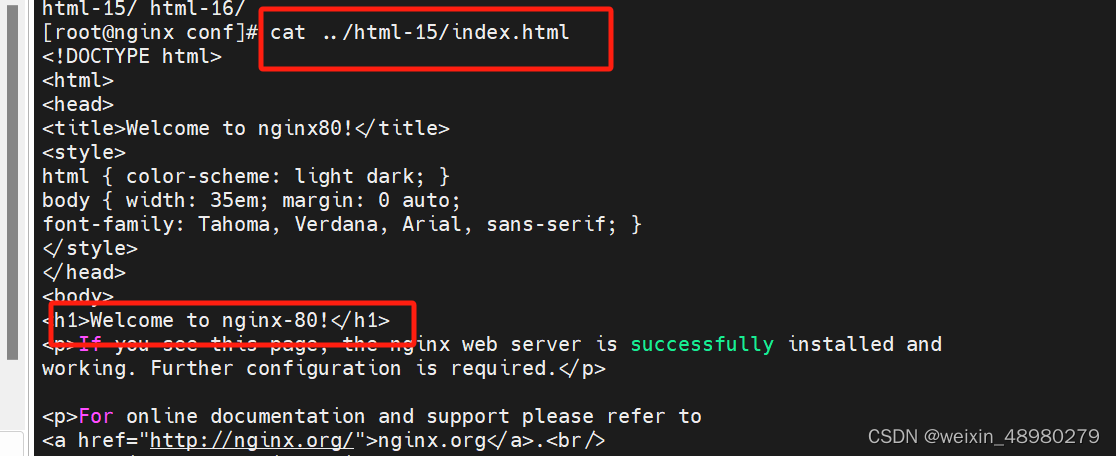
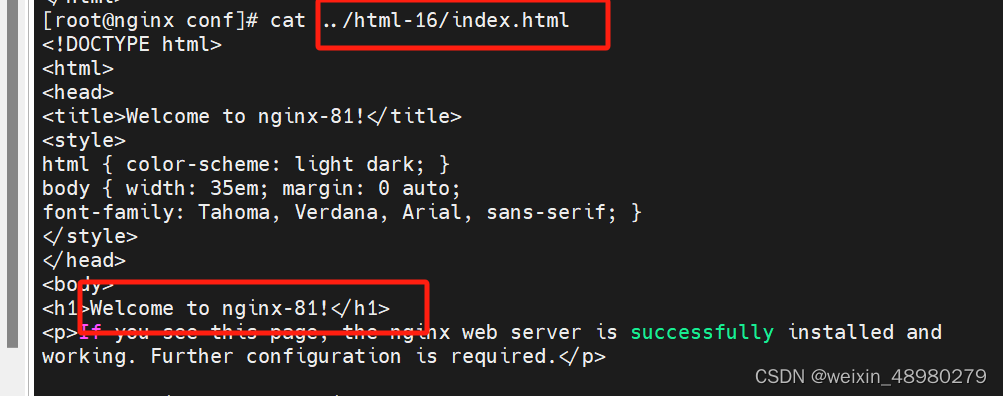
修改html文件:
然后reload下nginx
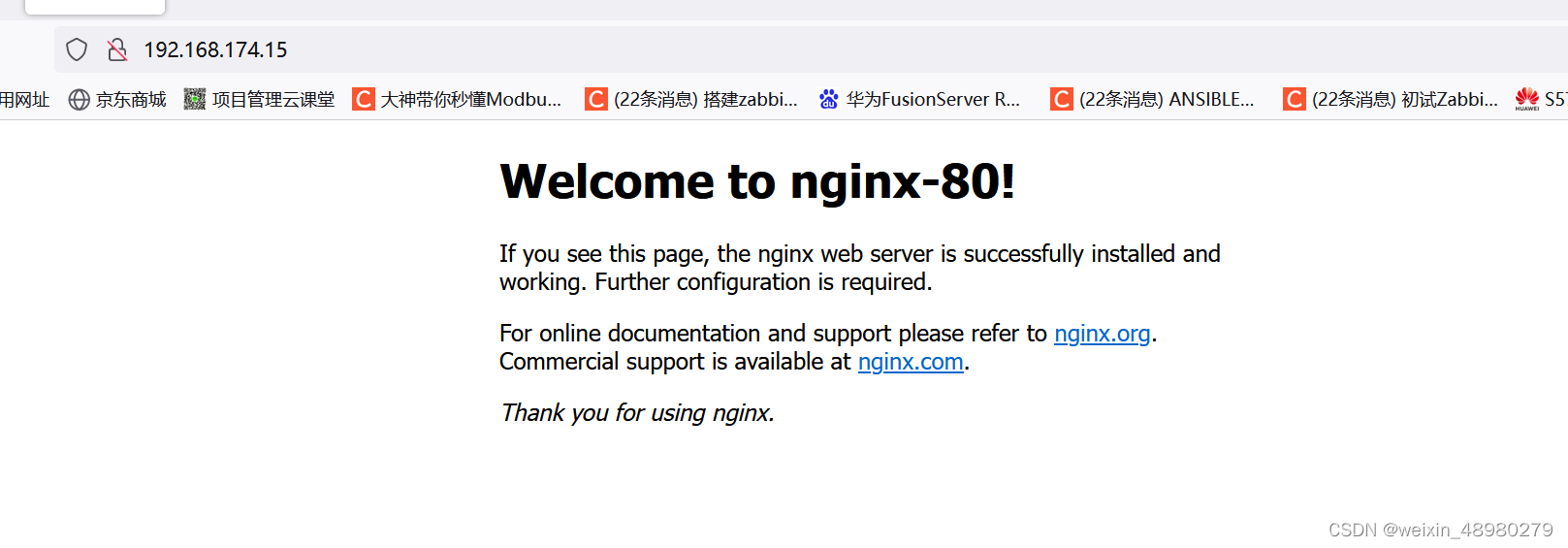
测试:
端口号不同,web也不同,相当于可以当多个web服务器来使

8. 总结nginx日志格式定制
配置文件(只能在http块来配置,不能在server块):

然后reload下
打开网页进行测试: