目录
一、前言
在当今信息爆炸的时代,数据已成为企业决策、科学研究乃至个人生活中不可或缺的一部分。然而,面对海量的数据,如何高效、准确地提取有价值的信息,成为了我们面临的一大挑战。此时,数据分析工具的重要性便凸显出来,而Pandas正是这一领域中的佼佼者。
Pandas是Python编程语言中一个强大的数据分析库,它提供了高效、灵活且易于使用的数据结构和数据分析工具,使得数据处理和分析变得简单而高效。自诞生以来,Pandas凭借其卓越的性能和广泛的应用场景,迅速成为了数据分析领域的热门工具之一。
1. 强大的数据处理能力
Pandas的主要优势在于其丰富的数据结构和强大的数据处理能力。它提供了Series和DataFrame两种核心数据结构,分别用于处理一维和二维的数据集。这些数据结构不仅支持多种数据类型,还提供了丰富的索引和切片功能,使得数据访问和查询变得非常方便。此外,Pandas还提供了大量的数据处理函数和方法,如数据清洗、转换、排序、分组和聚合等,这些功能使得数据分析的各个环节都能够得到很好的支持。
2. 良好的兼容性和可扩展性
除了强大的数据处理能力外,Pandas还具有良好的兼容性和可扩展性。它支持多种文件格式的数据导入和导出,如CSV、Excel、SQL数据库等,使得数据的获取和共享变得非常便捷。同时,Pandas还提供了丰富的API接口,可以与其他Python库(如NumPy、Matplotlib等)进行无缝集成,从而构建出更加复杂和强大的数据分析系统。
3. 广泛的应用领域
在数据分析领域,Pandas的应用范围非常广泛。无论是商业智能、金融分析还是科学研究,Pandas都能够提供有力的支持。通过Pandas,我们可以轻松地对数据进行清洗、转换和可视化,发现数据中的规律和趋势,为决策提供有力的依据。同时,Pandas还能够帮助我们构建复杂的数据模型,进行预测和推荐等高级分析任务。
本文旨在介绍Pandas在数据分析中的应用和技巧,并罗列整理了大量场景的Pandas的API,帮助读者更好地理解和使用这一强大的工具。
二、两种基本数据结构
Pandas是用于数据分析的开源Python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能 ,Pandas 主要提供了两种数据结构:
- Series:一维标签数组,能够保存任何数据类型(整数、字符串、浮点数、Python 对象等)。它有一个轴标签(即索引),可以通过这个索引访问数组中的值。
- DataFrame:二维的、大小可变的、有标签的数据结构。你可以把它想象成一个 Excel 表格,或者一个 SQL 表,或者一个字典对象,其中包含了多个 Series 对象。DataFrame 既有行索引也有列索引。
三、数据读取和写出
1. 数据读取

2. 导出数据
- 导出到excel表中
df.to_excel('data/df_output.xlsx', index=False)
# 注意导出的数据不需要索引列时,一定要加上参数 index=False- 导出到MySQL数据库中
# 1. 准备动作.
# 确保你的 MySQL服务已经成功启动, 如果是windows本地, 则是: phpstudy, 如果是Linux虚拟机, 默认开启.
# 用PyCharm连接 MySQL, 把: 数据库 rfm_db 先创建出来.
# 2. 创建引擎对象.
# mysql: 表示要操作的数据库.
# pymysql: 表示操作该数据库, 用的Python的包
# root:123456 要连接到的数据库的账号, 密码
# localhost:3306 要连接的数据库所在的 机器ip 和 端口号. 如果是虚拟机, 则写: node1.itcast.cn:3306 或者 192.168.88.161:3306
# rfm_db 要写出数据到的 目标数据库名, 想写出到哪个数据库, 就写谁的名字即可.
# charset=utf8 采用utf8字符集, 防止中文, 乱码.
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/rfm_db?charset=utf8")
# 2. 把 df数据写出到MySQL表中即可.
# 参1: 表示要把df数据写到哪个数据表, 这里是: rfm_table表.
# engine: 连接引擎
# index: False表示不写出行索引列, 对应的是: SQL表中的 自增索引. True: 表示写出.
# if_exists: 如果目标表存在了, 怎么处理? 三个值: fail(默认), 报错, append: 追加, replace: 替换
rfm_gb.to_sql('rfm_table', engine, index=True, if_exists='replace')四、分组聚合和数据透视
1. 分组聚合
- 写法
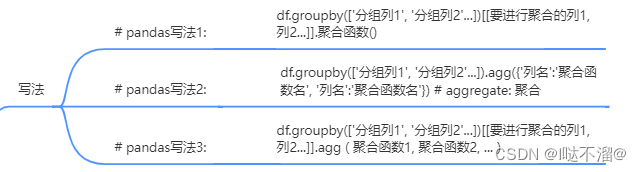
- 内部参数

- 索引操作

- 注意事项

2. 数据透视
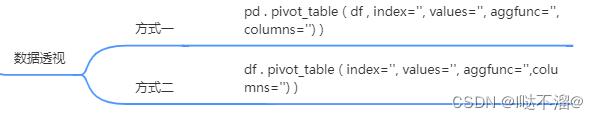
五、自定义函数的应用
1. 自定义函数
常用aplly()函数,其他还有pipe(),map()等等,了解即可。
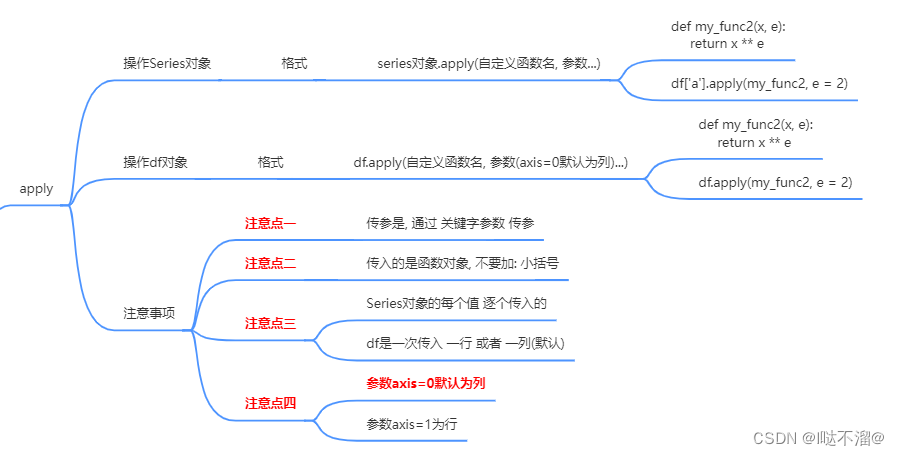
2. 向量化函数

3. Lambda表达式

六、缺失值处理
1. 导包
2. 判断

3. 加载

4. 缺失值的可视化

5. 删除

6. 填充非时间数据序列

7. 填充时间数据序列
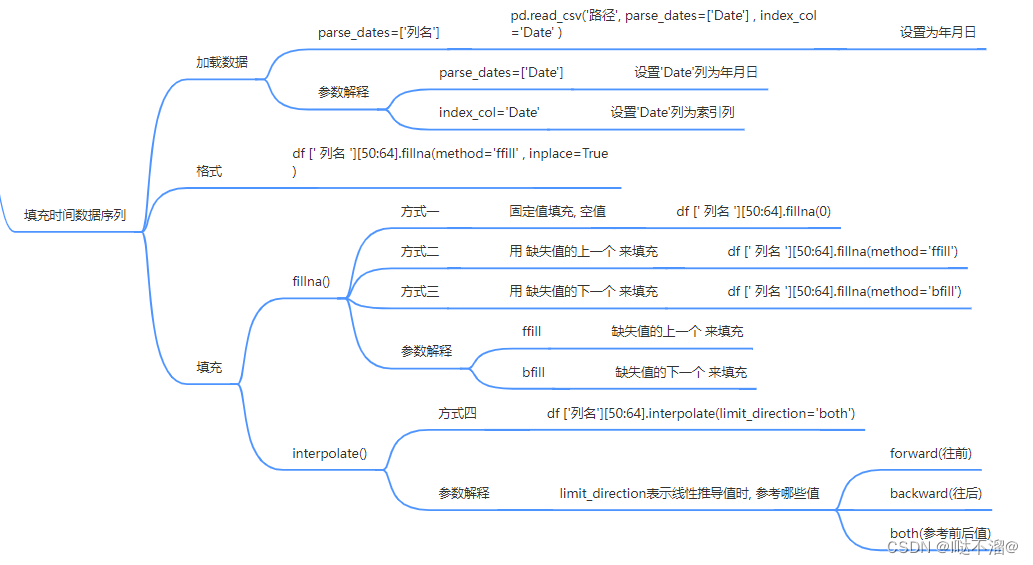
七、数据组合
1. 概述

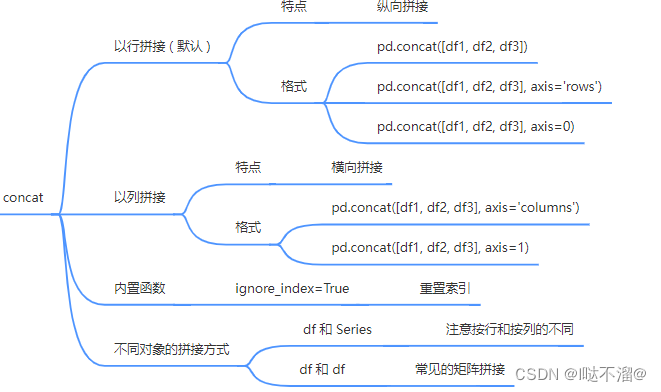
2. concat函数
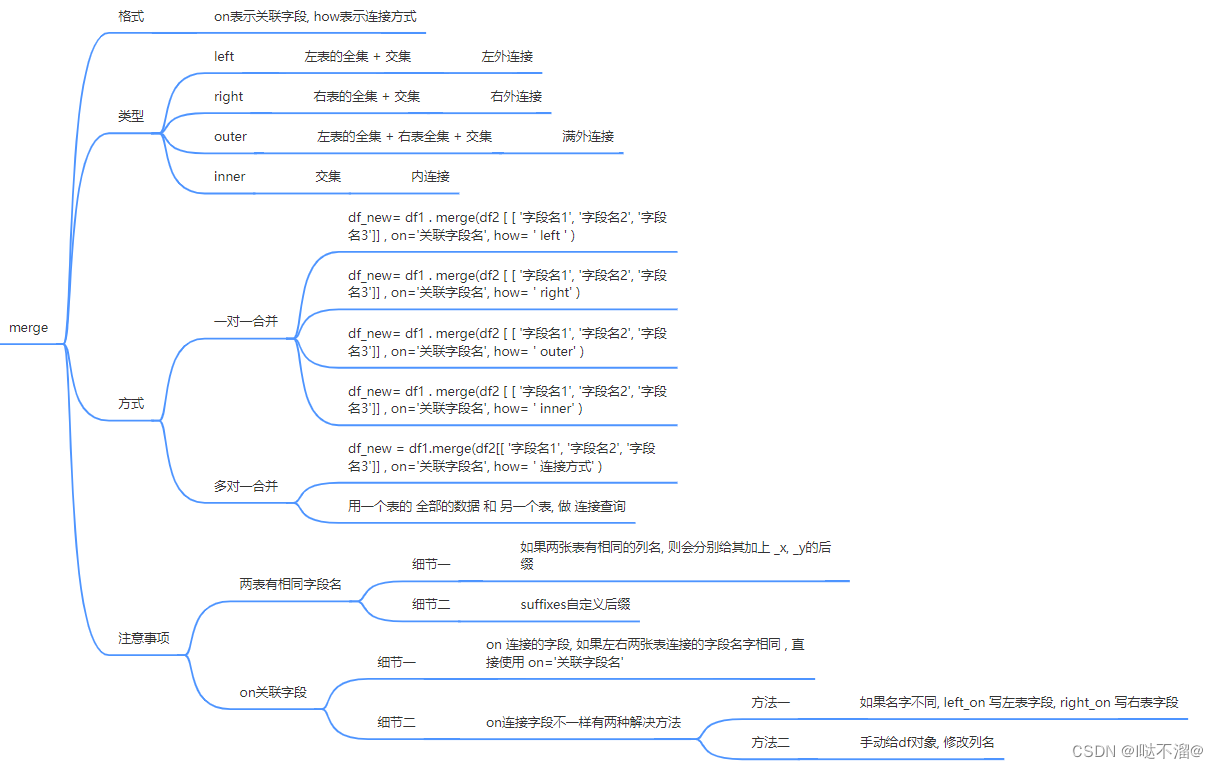
3. merge函数
4. join函数

5. 内置参数

八、分组操作
1. 分组转换
2. 分组聚合

3. 分组过滤

九、时间类型
1. Python内置

2. Pandas内置
- 导包和定义

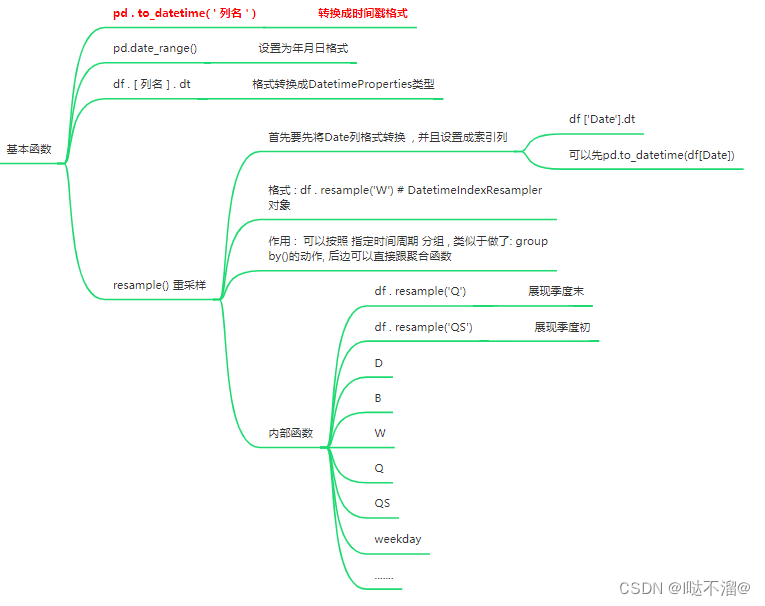
- 基本函数
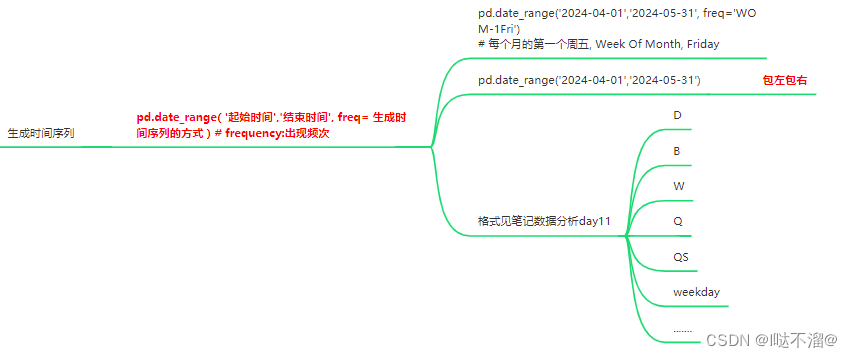
- 生成时间序列
- 加载时定义时间类型

- 获取时间属性
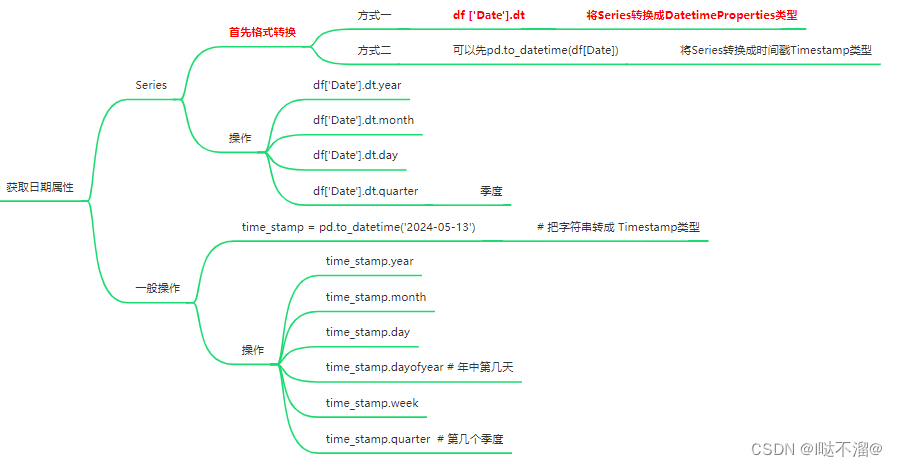
- 时间序列取值

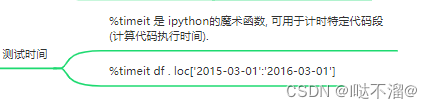
- 测试时间
3. 逻辑比较

十、总结
总之,Pandas是一个功能强大、易于使用的数据分析工具,它为我们提供了一个高效、灵活的数据处理和分析平台。在这个信息爆炸的时代,掌握Pandas的技能将会对我们的职业发展产生深远的影响。