聚合函数与分组数据
一、聚合函数
列函数也被称为聚合函数,其主要功能是统计汇总表中的数据。常用的聚合函数有5个,分别是COUNT()、SUM()、MAX()和MIN()。
1.1、使用COUNT()函数求记录个数
在数据库操作中,有时需要统计表中的记录个数,这时就会用到COUNT()函数。
- 示例:在MySQL环境中,统计stu_info表中的记录个数
| select COUNT(*) from stu_info; |
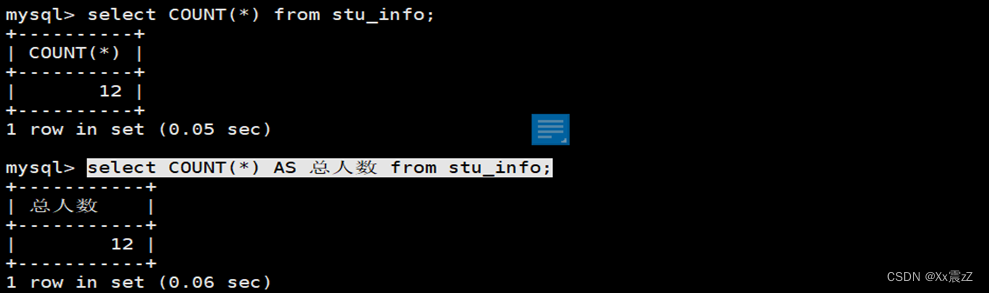
COUNT(*)不权可以求得表中所有记录的个数,也可以求得满足指定条件的记录的个数。
- 示例2:统计stu_info表中计科系学生的人数
| SELECT COUNT(*) AS 计科系学生人数 FROM stu_info WHERE institute = '计科系'; |

COUNT()函数的参数都是星号(*),除了星号以外,字段名也可以当COUNT()函数的参数;当字段名作为函数参数时,如果该字段中没有NULL值值,则与星号作为函数参数的效果相同;如果字段中含有NULL值,则统计个数时会排除含有NULL值的记录。
- 示例3:在COUNT()函数中,在字段名前加上DISTINCT关键字可不统计数据为NULL的情况。
| SELECT COUNT(*) AS 总人数,COUNT(DISTINCT phone) AS 有电话的人数,COUNT(DISTINCT email) AS 有email的人数 FROM user_info; |

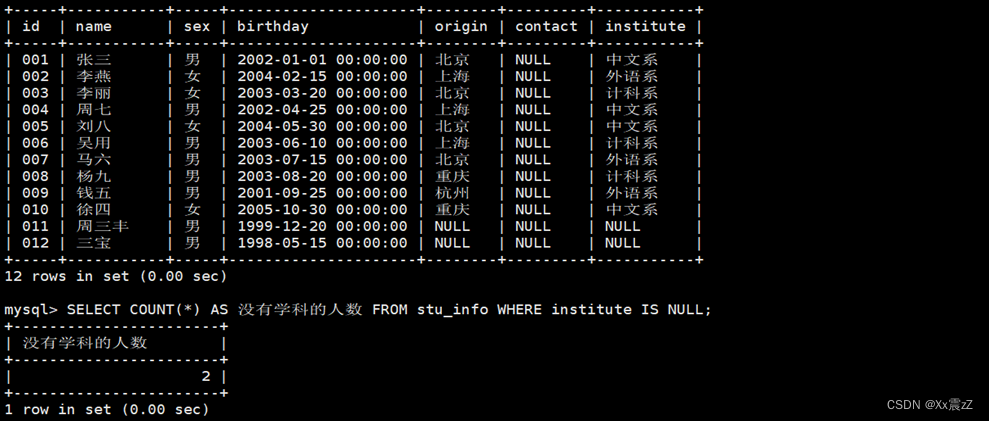
- 示例4:统计没有学科的的人数,其实就是统计该字段上有几个NULL值。
| SELECT COUNT(*) AS 没有学科的人数 FROM stu_info WHERE institute IS NULL; |
 1.2、使用SUM()函数求某字段的和
1.2、使用SUM()函数求某字段的和
数据库操作中,有时需要求某字段的和,其实更确切地说是需要求某字段多个记录值的和。该函数的参数必须是数值字段或者结果为数值的表达式。
- 示例1:在stu_course表中,求所有课程的总学分
| select SUM(credit) AS 必修课的学分总和 FROM stu_course WHERE type = '必修'; |

SUM()函数的参数必须是数值类型的字段名或者结果为数值的表达式,即该函数只能累加数值数据,SUM()函数会忽略NULL值。
1.3、使用AVG()函数求某字段的平均值
AVG()函数用于求字段的平均值,AVG()函数的参数也必须是数值类型的字段名或者结果为数值的表达式。
- 示例:在score表中,求“计算机基础”课的考试平均成绩
| SELECT AVG(result1) AS 计算机基础平均成绩 FROM score WHERE s_id IN (SELECT ID from stu_course WHERE course="计算机基础"); |
 1.4、使用MAX()、MIN()函数求最大、最小值
1.4、使用MAX()、MIN()函数求最大、最小值
MAX()和MIN()函数用于求指定字段中的最大值和最小值。如,想要知道stu_info表中,最早(最晚)的出生日期是多少时可以使用MAX()(MIN())函数。可以应用在文本类型、数值类型和日期时间类型的字段上,都忽略含有NULL值的记录。
- 示例1:求“计算机基础”课的考试成绩的最高分和最低分
| SELECT MAX(result1) AS 最高分,MIN(result1) AS 最低分 FROM score WHERE c_id IN(SELECT ID from stu_course WHERE course="教育学"); |

- 从stu_info表中查询生日最大的学生的姓名、出生日期和所属院系
从上述结果可知查询语句是错误的,因为在没有GROUP BY 子句的前提下,是不能将聚合函数和字段名一起放在SELECT子句的字段列表的位置上的。
| SELECT name AS 姓名,birthday AS 出生日期,institute AS 所属院系 FROM stu_info WHERE birthday IN(SELECT MAX(birthday) FROM stu_info); |

birthday=MAX(birthday)
原因是,聚合函数不能出现在WHERE子句中。
1.5、统计汇总相异值(不同值)记录
- 示例:统计stu_info表中的学生来自几个地区
分析:本例只要统计出不同来源地的个数即可;由于stu_info表中的来源地字段中有重复值出现,因此必须将重复值去掉,然后才能用COUNT()函数统计个数。
| SELECT COUNT(DISTINCT(origin)) AS 地区个数 FROM stu_info; |
 1.6、聚合函数对NULL值的处理
1.6、聚合函数对NULL值的处理
- COUNT()函数对NULL值的处理
如果COUNT()函数的参数为星号(*),则统计所有记录的个数;而如果参数为某字段,不统计含NULL值的记录个数,则应加上DISTINCT关键字。
- SUM()和AVG()函数对NULL值的处理
这两个函数忽略NULL值的存在,就好像该条记录不存在一样。
- MAX()和MIN()函数对NULL值的处理
MAX()和MIN()两个函数同样忽略NULL值的存在。
二、数据分组
数据分组是指将数据表中的数据按照某种值分为很多组。例如将表中的数据用性别进行分组,会得到两组,所有男生为一组,所有女生为一组;数据分组对统计汇总非常有用;例如,想要在一个查询结果集中显示男生和女生分别有多少人,首先必须得用性别分组。数据分组使用GROUP BY子句;如果想要将满足条件的分组查询出来,还需要HAVING子句的配合。
2.1、将表内容按列分组
GROUP BY子句用来分组数据。首先必须清楚一件事,分组是根据指定字段的不同值划分的;例如,性别字段中只有2个值,则如果按性别字段分组就会产生2个组;又如,假设所属院系字段中有5个不同的值,则如果按所属院系分组就会产生5个组。
Tips:前面讲过去除相同值,需要使用DISTINCT关键字;但是,使用DISTINCT会严重降低查询效率,为此,使用GROUP BY子句代替DISTINCT是一种非常好的解决方案。
- 如果查询语句中含有GROUP BY子句,则SELECT子句中通常不单独使用星号通配符。
- 在查询语句中含有GROUP BY子句的情况下,如果SELECT子句后是字段名列表,则这些字段名又不在聚合函数中,则应当在GROUP BY子句中列出所有这些字段名。
2.2、聚合函数与分组配合使用
将数据分成小组的很大原因是用于统计汇总,而统计汇总通常都要使用聚合函数。
- 示例1:统计stu_info表中男生的总人数和女生的总人数
| SELECT sex AS 性别,COUNT(*) AS 人数 FROM stu_info GROUP BY sex; |

- 示例2:统计stu_info表中每个院系的男生人数
| SELECT institute AS 所属院系,count(*) as 男生人数 FROM stu_info WHERE sex="男" GROUP BY institute; |
示例3:统计查询stu_course表中必修课的学分总和与选修课的学分总和
| SELECT type AS 类型,SUM(credit) AS 学分总和 FROM stu_course GROUP BY type; |
 2.3、查询数据的直方图
2.3、查询数据的直方图
直方图是表示不同实体之间的数据相对分布的条状图,在查询语句中使用GROUP BY子句,可以格式化数据生成图表。
| SELECT institute AS 所属院系,RPAD("",COUNT(*)*3,"=") AS 人数对比图 FROM stu_info GROUP BY institute; |

2.4、排序分组结果
排序分组结果应当使用ORDER BY子句,ORDER BY子句要放在GROUP BY子句的后面;实际上,ORDER BY子句要永远放在其他子句的后面。
- 示例:在stu_info表中,统计每个院系的学生人数,并按学生人数降序排序。
| SELECT institute AS 所属院系,COUNT(*) AS 人数 FROM stu_info GROUP BY institute ORDER BY COUNT(*) DESC; |
 2.5、反转查询结果
2.5、反转查询结果
| SELECT institute AS 所属院系, COUNT(CASE WHEN sex='男' THEN 1 ELSE NULL END) AS 男生人数, COUNT(CASE WHEN sex='女' THEN 1 ELSE NULL END) AS 女生人数 FROM stu_info GROUP BY institute; |
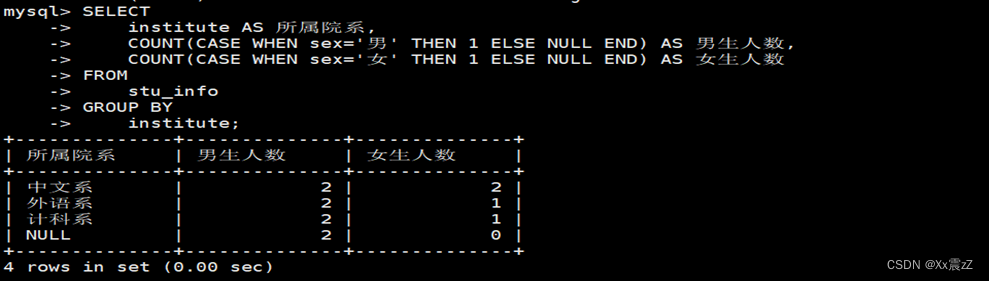
- SELECT institute AS 所属院系: 这一部分指定了要选择的列。它选择了学生信息表中的院系列,并将其命名为"所属院系"。
- COUNT(CASE WHEN sex='男' THEN 1 ELSE NULL END) AS 男生人数: 这一部分使用了 聚合函数。它统计了符合条件 的记录的数量,即男生的数量。使用 表达式来检查每条记录的性别是否为“男”,如果是,则计数为1,否则计数为NULL。函数会忽略 NULL 值,因此只会统计符合条件的记录数量。COUNTsex='男'CASECOUNT
- COUNT(CASE WHEN sex='女' THEN 1 ELSE NULL END) AS 女生人数: 类似于前一部分,这一部分统计了符合条件 的记录的数量,即女生的数量。sex='女'
- FROM stu_info: 这指定了查询要操作的表,即学生信息表()。stu_info
- GROUP BY institute: 这一部分指定了按照院系进行分组。这意味着查询将根据学生所属的院系对结果进行分组,以便对每个院系进行统计。
2.6、使用HAVING子句设置分组查询条件
有时人们只希望查看所需分组的统计信息,而并不是所有分组的统计信息;例如,只想查看计科系和外语系学生的总人数,这时就需要将其他院系的信息过滤掉。
HAVING子句用于设置分组查询条件,即过滤不需要的分组;该子句通常和GROUP BY子句一起使用,单独使用HAVING子句没有太大的意义。
- 示例:在stu_info表中,统计计科系和外语系的学生人数,并按学生人数降序排序。
| SELECT institute AS 所属院系,COUNT(*) AS 人数 FROM stu_info GROUP BY institute HAVING institute IN('计科系','外语系') ORDER BY COUNT(*) DESC; |
| SELECT institute AS 所属院系,COUNT(*) AS 人数 FROM stu_info WHERE institute IN('计科系','外语系') GROUP BY institute ORDER BY COUNT(*) DESC; |
- SELECT institute AS 所属院系, COUNT(*) AS 人数 FROM stu_info
- SELECT: 表示从数据库中选择数据。
- institute AS 所属院系: 选择 stu_info表中的 institute列,并将其命名为所属院系 。
- COUNT(*) AS 人数: 统计每个院系的记录数,并将结果命名为人数 。
- GROUP BY institute
- GROUP BY: 将结果集按照指定的列(这里是institute )进行分组。
- HAVING institute IN ('计科系','外语系')
- HAVING: 用于在分组后对分组结果进行筛选。
- institute IN ('计科系','外语系'): 只选择institute 列值为 '计科系' 或 '外语系' 的记录。
- ORDER BY COUNT(*) DESC
- ORDER BY: 对结果集进行排序。
- COUNT(*) DESC: 按照 列的值(即每个院系的人数)进行降序排序。
也可以使用WHERE子句代替HAVING子句,运行结果是一样的。
2.7、HAVING子句与WHERE子句的区别
- HAVING子句用于筛选组,而WHERE子句用于筛选记录。
- HAVING子句中可以使用聚合函数,而WHERE子句中不能使用聚合函数。
- HAVING子句中不能出现既不被GROUP BY子句包含,又不被聚合函数包含的字段;而WHERE子句中可以出现任意的字段。
- 通常HAVING子句总是和GROUP BY子句配合使用,而WHERE子句可以不用任何子句的配合。
- 示例:统计stu_info表中每个院系的男生人数
| SELECT institute AS 所属院系,COUNT(*) AS 男生人数 FROM stu_info WHERE sex='男' GROUP BY institute; |


这个错误表明在HAVING子句'sex'。在 SQL 查询中,HAVING 子句用于对分组后的结果进行筛选,但它只能使用聚合函数(如 COUNT()、SUM() 等)的结果进行比较,而不能直接使用表中的列名。
如果你想筛选出符合条件的记录,应该使用 WHERE 子句而不是 HAVING 子句。WHERE 子句用于在数据分组前筛选数据,而 HAVING 子句用于在数据分组后对数据进行筛选。