1、KNN邻近算法
如果一个样本在特征空间中的K个最相似(即特征空间中最近)的样本中大多数属于某一个类别,则样本也属于这一个类别。通俗一点而言就是看邻居的类别判断自己的类别,其中邻居的数量可调。
2、距离的选择和计算
KNN邻近算法主要就是根据距离来寻找距离自己最近的一个或者多个邻居,所以需要用到距离的计算。这里介绍三种,即:欧氏距离,曼哈顿距离,闵可夫斯基距离
距离通常采用欧氏距离,此外还有曼哈顿距离(绝对值距离)、闵可夫斯基距离等。
以二维平面而言,欧氏距离公式为:
d
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
d=\sqrt{(x_{1}-x_{2})^2+(y_{1}-y_{2})^2}
d=(x1−x2)2+(y1−y2)2
曼哈顿距离为:
d
=
∣
x
1
−
x
2
∣
+
∣
y
1
−
y
2
∣
d=|x_1-x_2|+|y_1-y_2|
d=∣x1−x2∣+∣y1−y2∣
对于n维变量,闵可夫斯基距离为:
d
12
=
∑
k
=
1
n
∣
x
1
k
−
x
2
k
∣
p
p
d_{12}=\sqrt[p]{\sum_{k=1}^n|x_{1k}-x_{2k}|^p}
d12=p∑k=1n∣x1k−x2k∣p
不难发现,当
p
=
1
p=1
p=1时,就变成了曼哈顿距离(绝对值距离)
当
p
=
2
p=2
p=2时,就变成了欧氏距离
所以实现欧氏距离和曼哈顿距离可以调整闵可夫斯基距离的参数
p
p
p进行选择。
k值选取需要合理,取得过小容易受到异常点影响,取得过大受到样本不均衡影响
3、API
KNN算法的API:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:int,可选(默认为5),k_neighbors查询默认使用的邻居数
algorithm:可选用于计算最近邻居的算法,auto将尝试根据传递的fit方法的值来决定最合适的算法。
4、代码示例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 特征工程---标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# KNN算法训练
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 模型评估
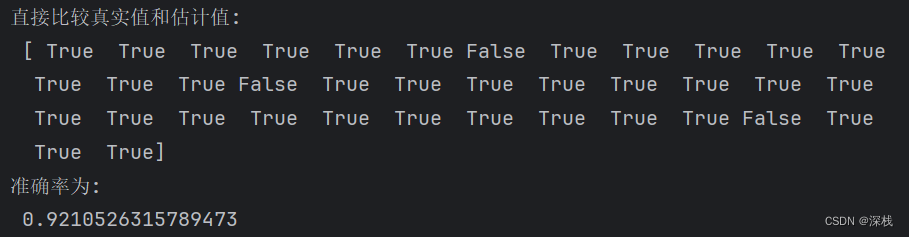
# 方法1:比较真实值与估计值是否相等
y_predict = estimator.predict(x_test)
print('直接比较真实值和估计值:\n', y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
5、运行结果及分析
对于鸢尾花分类,运行效果如下:
这里还可以使用网格搜索以及交叉验证来调节k_neighobors,即进行模型的评估与调优。
6、模型评估与调优
进行网格搜索和交叉验证,交叉验证即指将测试集再进行细分,如四折交叉验证就将测试集平均划分为四份,其中三组作为测试集,一组作为验证集。
交叉验证:将训练集继续分为训练集和验证集,如果将训练集分为3个小训练集和1个验证集,则称为四折交叉验证
超参数搜索(网格搜索):需要手动设置的参数称为超参数,例如KNN算法的K值,网格搜索使用API即可完成
API:sklearn.model_selection.GridSearchCV(estimator,param_grid=None,cv=None)
estimator:估计器对象
param_grid:估计器参数,即K值,以字典形式传入,例如{'n_neighbors':[1,3,5]}
cv:指定几折交叉验证
fit():输入训练数据
score():准确率
返回结果分析:
best_params_ 查看最佳参数
best_score_ 查看最佳结果
best_estimator_ 查看最佳估计器
cv_results_ 交叉验证结果
下面进行具体的交叉验证,在刚才的鸢尾花分类示例中,加入网格搜索找到最佳的n_neighbors并进行四折交叉验证,即设置cv=4。具体代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
iris = load_iris()
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 特征工程---标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# KNN算法训练
estimator = KNeighborsClassifier()
# 即依次查看哪个k值最优,进行四折交叉验证
estimator1 = GridSearchCV(estimator, {"n_neighbors": [1, 3, 5, 7, 10]}, cv=4)
estimator1.fit(x_train, y_train)
# 模型评估
print(f"最佳预估器为:{estimator1.best_estimator_}")
print(f"最佳正确率为:{estimator1.best_score_}")
print(f"最佳参数为:{estimator1.best_params_}")
print(f"四折交叉验证的结果为:{estimator1.cv_results_}")
前三项的运行结果如下
在这里可以发现n_neighbors的最佳值仍然为3,但是正确率却明细提升了,这是因为此处的测试集是经过交叉验证过后划分得到的。
