论文地址: PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
1、引言
PETR v2是对PETR的改进,探索了在3D空间中进行时域建模的有效性, 不同于BEVFormer和BEVDet4D选择bird-eye-view(BEV)空间进行时序特征对齐,并利用BEV特征进行分割的解决方案。PETR v2直接利用前一帧的时间信息来增强3D目标检测,也就是直接在3D空间中进行时序特征对齐。具体来说,将PETR中的3D位置嵌入(3D PE)扩展为时域建模,实现不同帧目标位置的时间对齐,再结合不同视角相机的图像特征进行特征融合来进行3D空间的位置编码。同时,为了支持高质量的BEV分割,PETR v2添加一组分割query,每个分割query负责分割BEV地图的一个特定patch,以至于达到高质量BEV分割的效果。
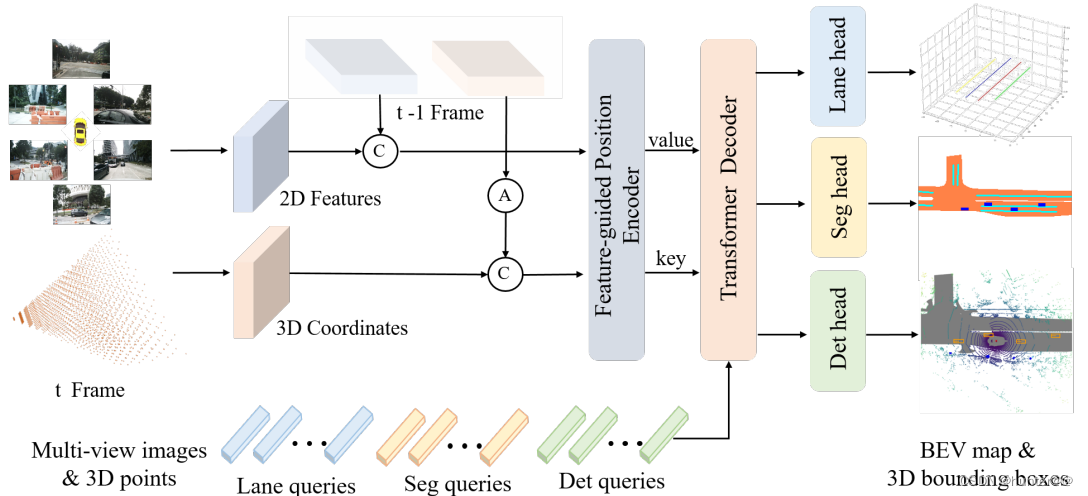
总体步骤:
(1)通过图像特征提取backbone对不同视角的相机图像进行特征提取,和上一时刻提取的图像特征在batch维度进行concat拼接。
(2)同PETR一样初始化一个[H,W,D,3]的3D网格点,并使用相机坐标转换矩阵转换为视锥,并和t-1时刻的视锥进行concat拼接。(这边视角转换的过程可以去看我的PETR那篇文章)。
(3)将t-1~t时刻的2D图像特征和t-1~t时刻的3D Coordinates进行encoder交互,也就是进行3D信息的位置编码,得到最终encoder的输出(也就是decoder模块的输入)。
(4)初始化一个object query,和encoder模块的最终输入进行交互,得到最终的3D bounding box。(这里还针对不同的任务初始化了多个query,例如Lane queries车道线检测 Seg queries和Det queries)。
注:下面的pipeline部分就不讲解代码,主要讲一下对论文部分的理解。
2、pipeline
2.1 Encoder
2.1.1 Temporal Modeling
原理:
Temporal Modeling也就是时间对齐的,作用是将t−1时刻的三维坐标变换为t时刻的坐标系(见图2),这中间其实就涉及到了一个比较关键的空间坐标变换问题。
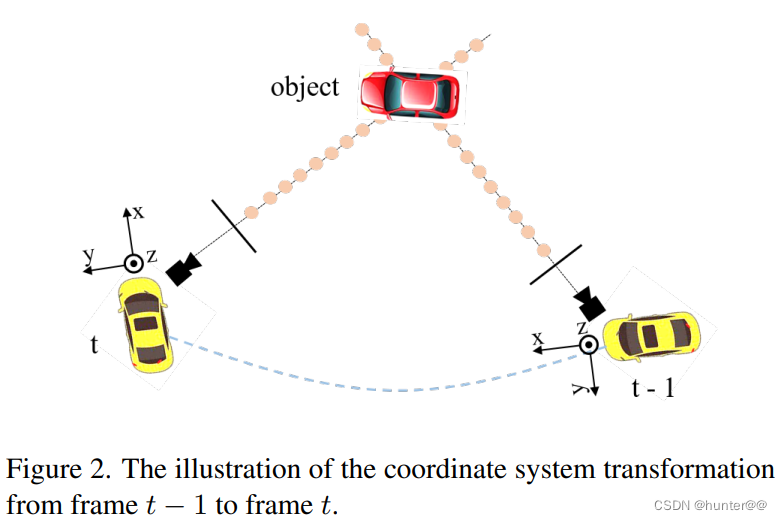
这里用一个比较抽象的数学模型来进行解释:
上式中,i表示相机的编号,c(t)表示t时刻的相机坐标系,l(t)表示t时刻的激光坐标系,e(t)表示t时刻的车体坐标系,Ki表示第i个相机的坐标转换矩阵,Pm(t)表示t时刻的原始相机生成的3D网格坐标,而生成之后的结果就表示最终的到视锥体(这个过程可以用图3来刻画)。
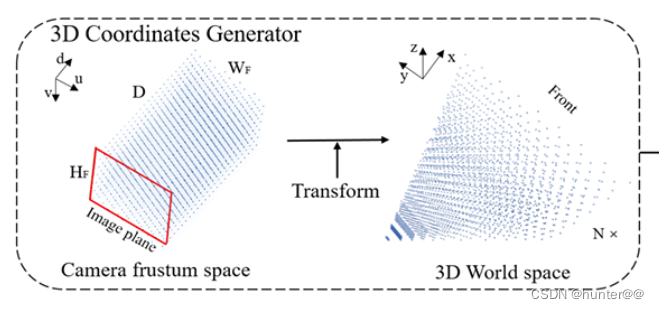
下面,我们想要刻画t-1时刻视锥体到t时刻视锥体的坐标转换过程:
其中,这里的T表示的是t-1时刻到t时刻的激光坐标系空间变换过程。
但是,我们并不知道t-1到t时刻的激光坐标系空间变换矩阵,因此我们需要利用已知信息求出其表达式,具体求解过程如下:

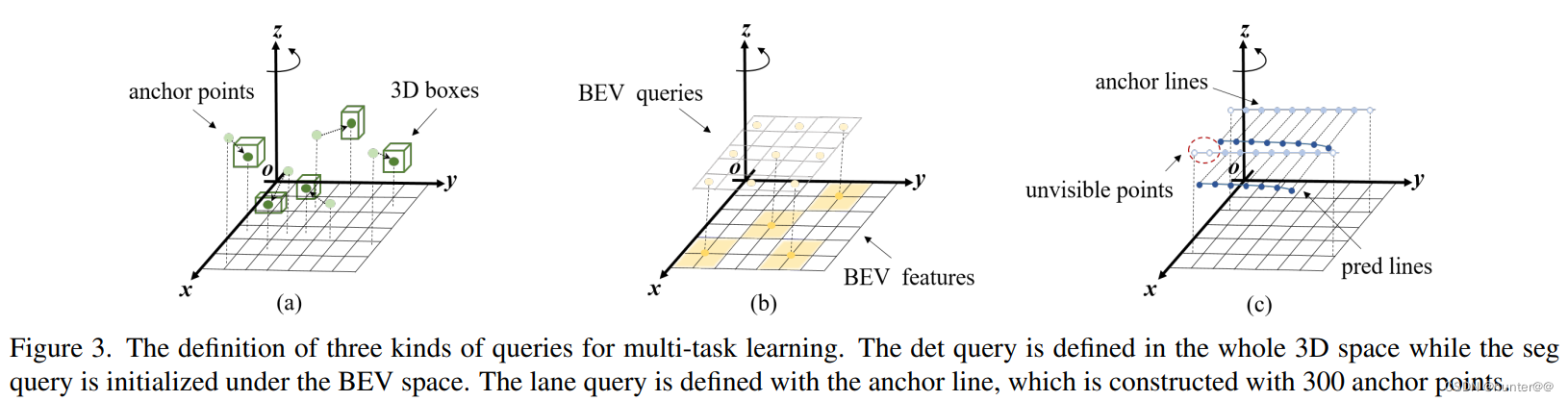
2.1.2 Multi-task Learning
原理
这里其实是对PETR任务的进一步扩展,将原本只能在3D检测任务上的head拓展到了BEV seg(BEV车道分割) 和 lane queries(车道线检测)任务上,因此这边定义了多个query,一个query用来处理一个任务。

2.1.3 Feature-guided Position Encoder
原理
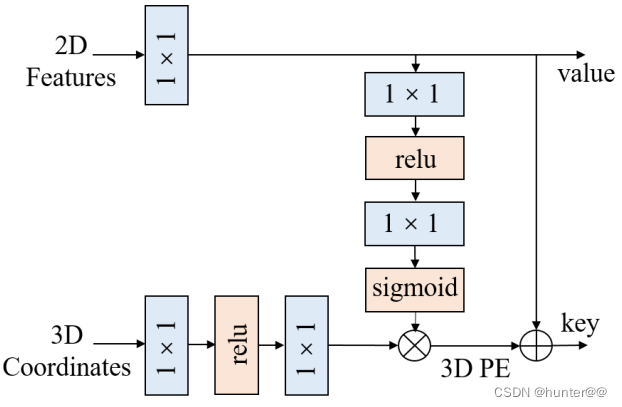
Feature-guided Position Encoder就是2D图像特征和3D视锥信息融合的过程,这边其实没有什么好说的,信息融合过程如下图:
2.2 Decoder
略(和PETR一模一样)
总结
(1)将PETR中的3D PE扩展到时序版本,通过对生成的3D coordinates进行变换,实现了时序对齐。
(2)PETR中,3D PE的生成是data-independent的,引入了一个特征引导的位置编码器,使得3D PE的生成和输入数据相关,隐式地从特征中获取到深度等信息。
(3)引入了一个简单高效的方案来支持BEV分割。受SOLQ5启发,DETR框架中一个query足以表征一块区域内的掩码,为此定义若干个分割查询向量实现高质量的BEV分割。
参考
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
旷视提出PETRv2:统一的多摄像头3D感知框架_petrv2: a unified framework for 3d perception from-CSDN博客