今天跟大家聊聊人工智能中的神经网络模型相关内容。神经网络内容庞大,篇幅有限本文主要讲述其中的CNN神经网络模型。
一 基本概述
深度学习(Deep Learning)特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特点是具有自动提取特征的能力,所提取的特征也称为深度特征或深度特征表示,相比于人工设计的特征,深度特征的表示能力更强、更稳健。
人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。
二 基础知识
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络。是深度学习代表算法之一。
基本概念 :输入图通过卷积核得到特征图。
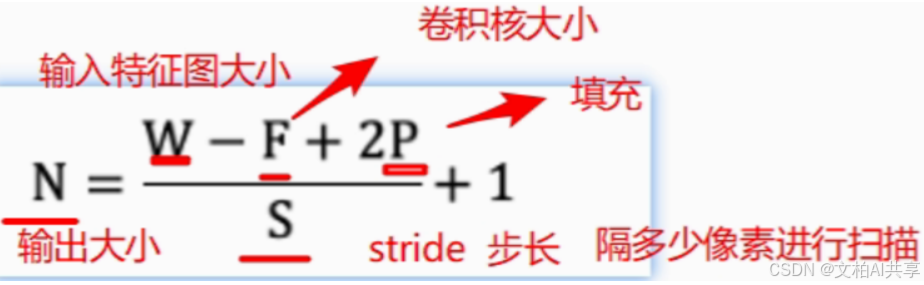
特征图计算公式:
计算结果特征图是 N*N 的。
池化层:主要对特征数据降维处理,即数据稀疏化。从而减小模型,简化计算。
池化层分类
# 框架Pytorch
# kernel_size=2池化窗口大小
# stride=1步长 每次移动的像素
# padding=0 四周填充0 填充1 就代表1像素填充一圈
# 最大池化层
polling1 = nn.MaxPool2d(kernel_size=2,stride=1,padding=0)
# 平均池化层
polling2 = nn.AvgPool2d(kernel_size=2,stride=1,padding=0)
三 经典案例
案例介绍:通过CNN神经网络实现图像分类.
数据集:CIFAR10
框架:Pytorch
# 测试环境
# import torch
# # 打印出正在使用的PyTorch和CUDA版本
# print(torch.__version__)
# print(torch.version.cuda)
# # 测试GPU是否生效
# print(torch.cuda.is_available())
# 0.导包
# import numpy as np
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor,Compose # 数据集转化和数据增强组合
import torch.optim as optim
from torch.utils.data import DataLoader
import time
# from torchsummary import summary
# import matplotlib.pyplot as plt
# 1.构建数据集
def create_dataset():
# 起初没有数据集download=True
# root 最好与项目文件在同目录下
# train = CIFAR10(root=r'E:\dataset\cifar10',train=True,transform=Compose([ToTensor()]),download=True)
train = CIFAR10(root=r'E:\dataset\cifar10',train=True,transform=Compose([ToTensor()]),download=False)
# valid = CIFAR10(root=r'E:\dataset\cifar10',train=False,transform=Compose([ToTensor()]),download=True)
valid = CIFAR10(root=r'E:\dataset\cifar10',train=False,transform=Compose([ToTensor()]),download=False)
# 返回数据集
return train,valid
# 2.搭建卷积神经网络 (一个继承两个方法)
class ImageClassificationModel(nn.Module):
# 定义网络结构
def __init__(self):
super(ImageClassificationModel,self).__init__()
# 定义网络层:卷积层+池化层+全连接层
# 第一层卷积层输入通道3和样本通道一致 ,输出通道卷积个数6可以自定义,卷积核大小3,步长1
self.conv1 = nn.Conv2d(3,6,kernel_size=3,stride=1)
# 优化1 加入BN层 参数等于上层的输出通道数
self.bn1 = nn.BatchNorm2d(6)
# 池化窗口大小2,步长2 如果是用固定的池化层,可以定义一个多次调用
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(6,16,kernel_size=3,stride=1)
self.bn2 = nn.BatchNorm2d(16)
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)
# 优化3 增加卷积层和核数
self.conv3 = nn.Conv2d(16, 32, kernel_size=3, stride=1)
self.bn3 = nn.BatchNorm2d(32)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
# 全连接层
# # 输入576,输出120
# self.linear1 = nn.Linear(576,120)
# self.linear2 = nn.Linear(120,84)
# 优化3 后
# mat1 (抻平层)的形状是 (16, 288),而 mat2(第1个隐藏层) 的形状是 (128, 64) 报错
# 注意满足矩阵乘法要求 第二个矩阵的行等于第一个矩阵的列
# 在调用 self.linear1 之前,打印 x 的形状,确保它符合预期 确保使其输入特征数与输入数据的特征数匹配。
# 输入288,输出128
self.linear1 = nn.Linear(288, 128)
# 优化8 加入Dropout(随机失活)
self.dropout1 = nn.Dropout(p=0.5)
self.linear2 = nn.Linear(128, 64)
self.dropout2 = nn.Dropout(p=0.5)
# 优化3 增加第三个全连接隐藏层
self.linear3 = nn.Linear(64, 32)
self.dropout3 = nn.Dropout(p=0.5)
# 输出层
self.out = nn.Linear(32,10)
# 定义前向传播
def forward(self,x):
# 优化前 卷积1+relu+池化1
# 优化后 卷积1+BN+relu+池化1
x = torch.relu(self.bn1(self.conv1(x)))
x = self.dropout1(x)
x = self.pool1(x)
# 卷积2+BN+relu+池化2
x = torch.relu(self.bn2(self.conv2(x)))
x = self.dropout2(x)
x = self.pool2(x)
# 优化3 增加卷积层和核数
x = torch.relu(self.bn3(self.conv3(x)))
x = self.dropout3(x)
x = self.pool3(x)
# print(x.shape) torch.Size([2, 16, 6, 6])
# [2, 16, 6, 6]即[B,C,H,w]
# x.size(0) 是一个batch的大小默认为2
# 展平 将特征图转成16X6X6行 1列的形式 相当于特征向量
x = x.reshape(x.size(0),-1)
# 全连接层
# 全连接隐藏层
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
# 优化3 增加第三个全连接隐藏层
x = torch.relu(self.linear3(x))
# 全连接输出层
output = self.out(x)
# 优化2 输出层使用softmax()激活函数
# dim=1 使得softmax函数在通道(分类任务常用)这个维度上对每个元素进行归一化,使其变为概率分布,因为每个通道可以代表一个类别.
# dim具体取值根据输入数据的维度来决定.注意-1表示最后一个维度,-2表示倒数第二个维度......
# 例如,如果输入是一个四维张量(batch_size, channels, height, width)
# dim = 0:沿着批次维度进行softmax操作。这意味着每个通道、高度和宽度上的所有批次样本会被归一化为概率分布。
# dim = 1:沿着通道维度进行softmax操作。这意味着每个批次、高度和宽度上的所有通道会被归一化为概率分布。
# dim = 2:沿着高度维度进行softmax操作。这意味着每个批次、通道和宽度上的所有高度会被归一化为概率分布。
# dim = 3:沿着宽度维度进行softmax操作。这意味着每个批次、通道和高度上的所有宽度会被归一化为概率分布。
# output = torch.softmax(self.out(x),dim=1)
return output
# 3.训练函数
def train(model,train_dataset):
# 构建损失函数 多分类交叉熵损失也叫做softmax损失
criterion = nn.CrossEntropyLoss()
# 优化器 Adam
optimizer = optim.Adam(model.parameters(),lr=0.001)
# # 优化4 修改优化器为 SGD
# optimizer = optim.SGD(model.parameters(),lr=0.01)
# 定义训练轮数
num_epoch = 25
# 遍历每个轮次
for epoch_idx in range(num_epoch):
# 初始化数据加载器 批量 多线程的 加载管理数据 支持数据打乱
# 32为每个batch的样本数量
train_loader = DataLoader(train_dataset,batch_size=32,shuffle=True)
# 样本数量
sam_num = 0
# 初始化损失值
total_loss = 0.0
# 第一轮训练开始时间点
start_time = time.time()
# 遍历测试数据集 即数据加载器 train_loader 中的每个批次数据 即每个batch
for x,y in train_loader:
x = x.to(cuda)
y = y.to(cuda)
# 前向传播 将数据送入网络模型训练(预测)
# output 对当前批次数据 x 的预测结果,形状通常是 [batch_size, num_classes]
output = model(x).to(cuda)
# 计算损失值
# y: 当前批次数据的真实标签,形状通常是 [batch_size]
# 损失函数使用的是 nn.CrossEntropyLoss(),它会计算每个样本的损失值,然后对这些损失值求平均.
# loos得到一批数据(当前批次)的平均损失值,不是单个样本的损失值.
loss = criterion(output,y)
# 梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 每批次的平均损失值累加 获得 当前轮所有批次的平均损失值和
# loss.item() 通过.item()方法取出当前批次平均损失值
total_loss += loss.item()
# 每批次的样本数量累加 获得 当前轮所有批次样本数和
sam_num += 1
# 通过每轮迭代 查看损失值下降 越接近0 说明预测值与真实值越接近 表示模型训练效果更好
# total_loss/sam_num 表示当前轮所有批次的平均损失值和/当前轮所有批次样本数 得到 某1轮所有batch的平均损失值
# 通过每轮耗时(单位:s)估计迭代周期
# 走到这说明第一轮所有批次执行完毕 跳出内循环 开始下一轮训练
print(f'epoch:第{epoch_idx +1}轮,loss:平均损失值{total_loss/sam_num},time:该轮耗时{time.time()-start_time}')
# 所有轮次执行完毕 保存模型
torch.save(model.state_dict(),r'E:\model\cifar10_model.pth')
# 4.模型预测函数
def test(model,valid_dataset):
# 构建数据加载器
dataloader = DataLoader(valid_dataset,batch_size=32,shuffle=False)
# 加载模型和训练好的网络参数
# 使用 torch.load 函数从指定路径加载预训练的模型参数
# weights_only=True 表示只加载模型的权重参数,不加载优化器等的参数
# 将加载的参数通过 load_state_dict 方法加载到当前模型中(上面训练的模型)
# 完成参数加载后,模型已经准备好进行验证或测试。
model.load_state_dict(torch.load(r'E:\model\cifar10_model.pth',weights_only=True))
# 计算精确率
# 初始化预测正确的数量
total_correct = 0
# 初始化样本总数量
total_samples = 0
# 遍历数据加载器中的每个批次batch
for x,y in dataloader:
# 输入特征移动到GPU
x = x.to(cuda)
# 标签移动到GPU
y = y.to(cuda)
# 前向传播 模型预测
output = model(x).to(cuda)
# 获取累加的预测正确的数量
# torch.argmax(output, dim=-1) 获取模型输出 output 在最后一个维度上的最大值索引,即模型对每个样本的预测类别
# == y 比较预测类别与真实标签 y 是否相等,返回一个布尔张量
# .sum() 对布尔张量求和,将 True 视为1,False 视为0,从而得到当前批次中预测正确的样本数量
# 最后将当前批次的正确预测数量累加到total_correct 获取总数量
total_correct += (torch.argmax(output,dim=-1)==y).sum()
# 累加当前批次的样本数量获取总数量
total_samples += len(y)
# 所有批次遍历完毕 计算打印总体精确率(并保留小数点后两位)
# 精确率(Precision)是分类模型性能评估的一个重要指标,用于衡量模型在所有被预测为正类的样本中,实际为正类的比例
# 本代码中,total_correct 是所有类别中预测正确的样本总数,total_samples 是所有样本的总数,因此计算的是整体的精确率
# 优化(未做):这个计算方式适用于二分类和多分类任务,但在多分类任务中,通常会计算每个类别的精确率,然后取平均值
# 未优化精确率为0.61
# 优化1:加入BN层优化精确率为0.64
# 优化2:输出层加入softmax()激活函数精确率为0.61 (失败)
# 优化3 增加卷积层数 卷积核数和第三层全连接隐藏层精确率为0.66 (有所提高)
# 优化4 修改优化器为 SGD精确率为0.66
# 优化5 轮次20修改成25精确率为0.68 (测试的最高精准率值--算是一个起点 要搞到0.80以上)
# 优化6 batch_size=16 改成 batch_size=32 精确率为0.67 (下降)
# 优化7 优化器SGD改回Adam精确率为0.67
# 优化8 加入dropout随机失活 精确率为0.56 (下降)
print(f'精确率为{total_correct/total_samples:.2f}')
# 5.main函数测试
if __name__ == '__main__':
# 指定训练设备 GPU 上 cuda0
cuda = torch.device('cuda:0')
# 加载数据集
train_dataset,valid_dataset = create_dataset()
# 查看数据集类别 Pytorch封装的固定写法.class_to_idx
# 数据集所有类别:{'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
# print(f'数据集所有类别:{train_dataset.class_to_idx}')
# 数据集中图像数据
# 训练集数据集:(50000, 32, 32, 3)
# print(f'训练集数据集:{train_dataset.data.shape}')
# 测试集数据集: (10000, 32, 32, 3)
# print(f'测试集数据集:{valid_dataset.data.shape}')
# 查看数据集类别数量
# 把训练集的标签转化为numpy 去重 再求长度
# 10
# print(len(np.unique(train_dataset.targets)))
# 画图
# figsize=(2, 2)画布大小
# dpi=200 分辨率
# plt.figure(figsize=(2, 2),dpi=200)
# plt.imshow(train_dataset.data[1])
# plt.title(train_dataset.targets[1])
# plt.show()
# 实例化模型 注意把模型放到GPU上
MyModel = ImageClassificationModel().to(cuda)
# summary(MyModel,input_size=(3,32,32),batch_size=1) # Total params: 81,302
# 训练模型
# 未优化loss平均值是0.6428983346247673
# 优化1 加入BN层优化loss平均值是0.5965962741136551
# 优化2 输出层加入softmax()激活优化loss平均值是1.8043147380065918 (损失值升高 优化失败)
# 优化3 增加卷积层数 卷积核数和第三层全连接隐藏层优化loss平均值是0.6324231018376351
# 优化4 修改优化器为 SGD loss平均值是0.6910492655086518
# 优化5 轮次20改成25 loss平均值是0.627374342212677
# 优化6 batch_size=16 改成 batch_size=32 loss平均值是0.6959678105871722
# 优化7 把优化器SGD改回Adam loss平均值是0.5132057572800192 (本次初始loss平均值是 1.4839402317848254)
# 优化8 加入dropout随机失活 loss平均值是1.1519099183747652 初始值1.673698478834185
train(MyModel,train_dataset)
# 预测模型
test(MyModel,valid_dataset)
好了,以上就是今天和大家分享的内容,喜欢的小伙伴可以点赞加关注,持续分析相关技术…案例介绍比较详细,如果你现在正准备学习图像识别处理相关的知识,希望对屏幕前的你有所帮助。我们下期见!