今天和大家聊一个机器学习算法-朴素贝叶斯,它的基于概率统计思想的一种机器学习算法常用于分类任务。
一 基本概念
先验概率:基于统计的概率,根据以往历史经验和分析得到的结果,不需要依赖当前发生的条件。
后验概率:从条件概率而来,由因推果,基于当下发生的事件计算之后的概率,依赖于当前发生的条件。
条件概率:记事件A发生的概率为P(A),事件B发生的概率为P(B),则B时间发生的前提下,A事件发生的概率为P(A|B)。
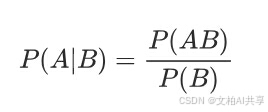
贝叶斯公式就是基于条件概率通过P(B|A)来求解P(A|B):
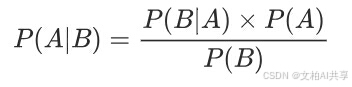
而朴素贝叶斯就是假设事件(特征)之间没有联系,给定训练数据集,其中每个样本x都包括n维特征,也就是x={x1,x2,x3,…,xn},有k种类别即y={y1,y2,y3,…,yk},对于给定的样本,判断属于什么标记的类别,根据贝叶斯定理可以获得P(yk|x)
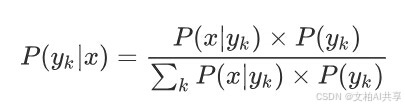
而朴素贝叶斯对条件概率分布做出了独立性的假设,所以每个特征相互独立,此时条件概率可以转化为:
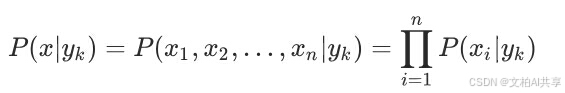
将此式带入到上述的贝叶斯公式中得出:
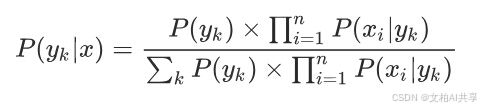
二 API使用
# 导包:
from sklearn.naive_bayes import MultinomialNB
# 调用:
alpha:拉普拉斯平滑系数
MultinomialNB(alpha = 1.0)
三 优缺点
优点:
- 朴素贝叶斯模型有稳定的分类效率。
- 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
- 需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
- 对输入数据的表达形式很敏感(离散、连续,值极大极小之类的)。
四 经典案例
4.1 案例1 情感分类
计算机中情感简单理解就是积极&消极 好评&差评 等等.并非人类的复杂情感。
本案例主要是使用朴素贝叶斯实现评价分类。
# 导包
import jieba
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer # 词频向量(做特征工程 提取特征)
from sklearn.naive_bayes import MultinomialNB # 多项分布朴素贝叶斯
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import joblib
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def load_data():
# 1.加载数据
data = pd.read_csv('data/书籍评价.csv',encoding='gbk') # 存在中文采用gbk编码
# print(data.head())
# 2.数据预处理
# 2.1 处理数据y
data['评论标号'] = np.where(data['评价']=='好评',1,0) # '好评'=>1,'差评'=>0
y = data['评论标号']
# 2.2 加载停用词
stopwords =[]
# 读取停用词文档
with open('data/stopwords.txt','r',encoding='utf-8') as f:
lines = f.readlines() # 读取所有行储存在lines
stopwords = [line.strip() for line in lines] # line.strip() 去除前后空格\换行符等放到停用词列表中
# print(stopwords)
stopwords = list(set(stopwords)) # 通过集合去重保存到停用词列表中
# print(stopwords)
# 2.3处理数据(评论内容)把文档分词
comment_list = [','.join(jieba.lcut(line)) for line in data['内容']]
# 2.4特征工程
transfer = CountVectorizer(stop_words=stopwords) # 创建向量化对象
x = transfer.fit_transform(comment_list)
# print(x)
mynames = transfer.get_feature_names_out() # 获取特征名称
x = x.toarray()
# print(x.shape)
# print(x)
# 3.准备训练集和测试集
x_train = x[:10,:] # 训练集前10条数据
y_train = y.values[0:10] # 训练集前10条数据对应的标签
x_test = x[10:,:] # 测试集后3条数据
y_test = y.values[10:] # 测试集后3条数据对应的标签
# print(x_train.shape)
# print(y_train.shape)
# 4.模型训练
# 4.1实例化贝叶斯模型
myMultinomialNB = MultinomialNB()
myMultinomialNB.fit(x_train,y_train)
# 4.2 模型预测
y_predict = myMultinomialNB.predict(x_test)
print('预测结果:',y_predict) # 预测结果: [0 0 0]
print('真实结果:',y_test) # 真实结果: [0 0 0]
# 5.模型评估
print(myMultinomialNB.score(x_test,y_test)) # 1.0
if __name__ == '__main__':
load_data()
4.2 案例2 垃圾邮件分类
- 数据集介绍
邮件数据存放在 trec06c 目录下,该目录下有 data、delay、full 三个子目录,其中 full 目录下的 index 文件中存储了所有邮件的路径,每一个路径为一个垃圾邮件。
数据集链接: https://plg.uwaterloo.ca/cgi-bin/cgiwrap/gvcormac/foo06
- 项目介绍
通过朴素贝叶斯实现垃圾邮件分类
- 温馨提示
本案例介绍了文本数据清洗过程与整个模型搭建步骤非常实用,小伙伴可以多关注项目实现思路部分。主要文件如下:


项目准备动作
# 0.导包
import pandas as pd
import os
import codecs
import re
import zhconv # 繁体转简体
import jieba
import jieba.posseg as psg # 词性标注
from sklearn.feature_extraction.text import CountVectorizer # 词频向量(做特征工程 提取特征)
from sklearn.model_selection import train_test_split
import pickle
import time
from tqdm import tqdm # 进度条
# 将当前目录设置为工作目录
# __file__ 表示当前文件路径
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# 设置结巴不输出日志
jieba.setLogLevel(jieba.logging.INFO)
# 1.数据转换(目的:把所有邮件放到一个csv文件中)
def load_email_data():
# 读取邮件目录
# 创建两个空列表 分别存储邮件名和邮件标签
filenames, labels = [], []
with open('trec06c/full/index') as file:
# 按行读取文件
for line in file:
# 用于移除字符串两端的指定字符,默认情况下移除的是空白字符(包括空格、制表符 \t、换行符 \n 等)不传参是移除两端空白字符
# 不传入任何参数,split() 会将字符串按任意空白字符(包括空格、制表符 \t、换行符 \n 等)进行分割 可以指定分隔符 如 逗号','
label, path = line.strip().split()
# 存储邮件标签和邮件路径
labels.append(label)
filenames.append(path)
# 读取邮件内容
os.chdir('trec06c/full')
contents = []
# filename每个路径
for filename in filenames:
# 打开文件
with open(filename, encoding='gbk', errors='ignore') as file:
# 读取每个路径中的邮件内容
content = file.read()
# 所有邮件内容放到列表中
contents.append(content)
# 数据集分割
x_train, x_test, y_train, y_test = \
train_test_split(contents, labels, test_size=0.2, stratify=labels, random_state=42)
# 存储到 csv 文件中
# __file__ 当前文件
# abspath(__file__)获取当前目录的绝对路径
# .dirname 上级路径名称
# .chdir切换路径
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# 创建训练集DF对象
train_data = pd.DataFrame()
# 添加特征和标签列
train_data['emails'] = x_train
train_data['labels'] = y_train
train_data.to_csv('data/01-原始邮件数据-训练集.csv')
test_data = pd.DataFrame()
test_data['emails'] = x_test
test_data['labels'] = y_test
test_data.to_csv('data/01-原始邮件数据-测试集.csv')
# 2.数据清洗
def clean_data(email):
# 去除非中文字符
# 参1 为正则表达式规则 参2 替换为空字符串 参3 为要正则化的对象
email = re.sub(r'[^\u4e00-\u9fa5]', '', email)
# 繁体转简体
email = zhconv.convert(email,'zh-cn')
# 邮件词性删选
# 数据类型格式 我: n 爱: v
email_pos = psg.cut(email)
# 词性类别表 名词 动词 形容词 人名 地名 组织名
allow_pos = ['n','v','a','nr','ns','nt']
email = []
for word,pos in email_pos:
# 词性符合给定的词性 把邮件内容放入email列表
if pos in allow_pos:
email.append(word)
# 转成str类型 用空格把分好的词拼接起来
# 储存邮件内容
email = ' '.join(email)
return email
# 清洗数据集并储存
def clean_email_data():
train_data = pd.read_csv('data/01-原始邮件数据-训练集.csv')
emails, labels = [], []
# progress 定义进度条
# tqdm 进度条模块
# len(train_data) 邮件数量
progress = tqdm(range(len(train_data)), desc='清洗进度')
for email, label in zip(train_data['emails'], train_data['labels']):
# 清洗语料 调用上面clean_data() 把邮件内容进行清洗
email = clean_data(email)
# 长度为0的数据剔除
if len(email) == 0:
continue
# 缓存清洗的标签和邮件内容结果
labels.append(label)
emails.append(email)
# 更新进度
progress.update()
# 存储到 csv 文件中
train_data = pd.DataFrame()
# 使用清洗后的数据修改train_data特征和标签列
train_data['emails'] = emails
train_data['labels'] = labels
# 储存到 csv 文件中
train_data.to_csv('data/02-清洗后的数据-训练集.csv')
# 3.邮件特征提取
# 只对训练集做特征工程 并转换成词频向量
def extract_email_feature():
train_data = pd.read_csv('data/02-清洗后的数据-训练集.csv')
# 提取特征
# CountVectorizer 统计词频 生成词频矩阵 同时将文本数据转换为词频向量
# max_features=10000 限制词汇表中最多包含 10000 个最频繁出现的词 以此作为特征
transfer = CountVectorizer(max_features=10000)
emails = transfer.fit_transform(train_data['emails'])
# 将转换完的训练数据存储
train_data_dict = {}
train_data_dict['emails'] = emails.toarray().tolist()
train_data_dict['labels'] = train_data['labels'].tolist()
# 使用pickle保存数据 wb 表示保存成二进制文件 3表示压缩级别 (高级的)
pickle.dump(train_data_dict, open('data/03-训练数据.pkl', 'wb'),3)
# 将提取到的特征进行存储
# 提取特征名
feature_names = transfer.get_feature_names_out()
print(f'查看特征数量:{len(feature_names)}') # 查看特征数量:10000
pickle.dump(feature_names,open('data/03-模型训练特征.pkl', 'wb'),3)
if __name__ == '__main__':
# 1.数据转换调用(目的:把所有邮件放到一个csv文件中)
# load_email_data()
# 2.数据清洗
# clean_email_data()
# 3.邮件特征提取
extract_email_feature()
模型训练
# 0. 导包
from sklearn.naive_bayes import MultinomialNB
import pickle
import joblib
if __name__ == '__main__':
# 1.加在训练数据
train_data = pickle.load(open('data/03-训练数据.pkl','rb'))
# 2.实例化模型
model = MultinomialNB()
# 3.训练模型
model.fit(train_data['emails'],train_data['labels'])
# 4.保存模型
joblib.dump(model,'data/04-邮件分类模型.pth')
模型预测和评估
# 0.导包
import pickle
import pandas as pd
import joblib
import os
import re
import zhconv
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
import jieba.posseg as psg
# 将当前目录设置为工作目录
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# 1.编写清洗函数
def clean_data(email):
# 去除非中文字符
email = re.sub(r'[^\u4e00-\u9fa5]', '', email)
# 繁体转简体
email = zhconv.convert(email,'zh-cn')
# 邮件词性删选
# 数据类型格式 我: n 爱: v
email_pos = psg.cut(email)
# 词性类别表 名词 动词 形容词 人名 地名 组织名
allow_pos = ['n','v','a','nr','ns','nt']
email = []
for word,pos in email_pos:
# 词性符合给定的词性 把邮件内容放入email列表
if pos in allow_pos:
email.append(word)
# 转成str类型 用空格把分好的词拼接起来
# 储存邮件内容
email = ' '.join(email)
return email
# 2.模型评估
def evaluate():
# 2.1 加载数据
test_data = pd.read_csv('data/01-原始邮件数据-测试集.csv')
# 2.2 构建特征提取器
# 加载处理好的模型训练特征数据集
vocab = pickle.load(open('data/03-模型训练特征.pkl', 'rb'))
# 具体提取特征过程
# CountVectorizer将文本数据转换为词频向量
# vocabulary=vocab 指定词汇表 生成是特征只包含表中的 此时使用之前训练好的特征做词汇表
transfer = CountVectorizer(vocabulary=vocab)
# 2.3 加载模型
model = joblib.load('data/04-邮件分类模型.pth')
# 2.4 测试集评估
y_pred = []
for email in test_data['emails'].to_numpy():
# 2.4.1 清洗数据
email = clean_data(email)
# 2.4.2 特征提取
email = transfer.transform([email]).toarray().tolist()
# 2.4.3 模型预测
output = model.predict(email)
# 2.4.4 预测结果存储
y_pred.append(output[0])
# 真实值
y_true = test_data['labels'].to_list()
# 获取样本数量
samples = len(test_data)
print(f'样本数量:{samples}') # 样本数量:12924
# 计算准确率
# 传入预测值和真实值
accuracy = accuracy_score(y_pred,y_true)
print(f'准确率:{accuracy:.2f}') # 准确率:0.96
# 计算精度
precision = precision_score(y_pred, y_true, pos_label='spam')
print('precision: %.2f' % precision) # precision: 0.97
# 召回率
recall = recall_score(y_pred, y_true, pos_label='spam')
print('recall: %.2f' % recall) # recall: 0.98
# 存储评估结果
eval_result = {
'sample_num': samples,
'accuracy': accuracy,
'precision': precision,
'recall': recall
}
pickle.dump(eval_result, open('data/05-模型评估结果.pkl', 'wb'), 3)
# 3.模型预测
# 模型预测就是我们输入文本邮件内容,由模型给出最终地预测结果:spam 表示垃圾邮件,ham 表示非垃圾邮件.
# 数据是从测试集数据中,随意选两封邮件.
def predict(email):
# 特征提取器
vocab = pickle.load(open('data/03-模型训练特征.pkl', 'rb'))
transfer = CountVectorizer(max_features=10000, vocabulary=vocab)
# 加载模型
model = joblib.load('data/04-邮件分类模型.pth')
# 数据清洗
# 输入的是原始邮件内容 需要对邮件内容进行清洗 去除非中文 转换为简体 提取词性
email = clean_data(email)
# 特征提取
# CountVectorizer 的 transform 方法期望接收一个可迭代对象(如列表、元组等),其中每个元素是一个文档(即一段文本)
# 即使只有一个文档需要转换,也需要将其包装在一个列表中,以符合 transform 方法的输入要求
# 所以这里需要把邮件内容放入列表中
# CountVectorizer 把输入的文本转成词频向量 得到的是一个稀疏矩阵 在机器学习中期望接收的是密集数组所以.toarray()
# 又因为列表在数据操作上比较灵活所以.tolist()
email = transfer.transform([email]).toarray().tolist()
# 模型模型预测
# 把从传入的邮件中提取的特征放入模型预测
output = model.predict(email)
print(f'特征内容:{email}') # [[0, 1,0,0,1,1...]]
print(f'预测结果列表:{output}') # 预测结果列表:['spam']
# 取列表中的第一个元素
print('最终的预测结果:', output[0]) # 最终地预测结果: spam
if __name__ == '__main__':
# 1.模型评估
# evaluate()
# 2.模型预测
# 准备测试数据
email1 = '''软 件 学 报(Ruanjian Xuebao)
第16卷第8期 2005年8月
张再跃,眭跃飞,曹存根.基于模糊命题模态逻辑的形式推理系统(英文).2005,16(8):1359-1365
李娟,李明树,武占春,王青.基于SPEM的CMM软件过程元模型.2005,16(8):1366-1377
曹东刚,梅宏,曹建农.在中间件中支持用户自定义连接子.2005,16(8):1378-1377
颜炯,王戟,陈火旺.基于UML的软件Markov链使用模型构造研究.2005,16(8):1386-1394
刘瑜,高勇,王映辉,邬伦,王立福.基于构件的地理工作流框架:一个方法学的探讨(英文).2005,16(8):1395-1406
游斓,周雅倩,黄萱菁,吴立德.基于最大熵模型的QA系统置信度评分算法.2005,16(8):1407-1414
邓赵红,王士同.鲁棒性的模糊聚类神经网络.2005,16(8):1415-1422
赵连伟,罗四维,赵艳敞,刘蕴辉.高维数据流形的低维嵌入及嵌入维数研究.2005,16(8):1423-1430
陈付幸,王润生.基于预检验的快速随机抽样一致性算法.2005,16(8):1431-1437
杨志华,齐东旭,杨力华,吴立军.基于经验模式分解的汉字字体识别方法.2005,16(8):1438-1444
李丹,吴建平,崔勇,徐恪.互联网名字空间结构及其解析服务研究.2005,16(8):1445-1455
张晋豫,孟洛明,邱雪松,关富英.优化的IP-DiffServ动态资源定价机制.2005,16(8):1456-1464
罗泽,崔辰州,南凯,阎保平.网格环境下银河系化学演化研究(英文).2005,16(8):1465-1473
郑静,卢锡城,王意洁.移动自组网中基于分簇的数据复制算法(英文).2005,16(8):1474-1483
郑彦兴,田菁,窦文华.基于Pareto最优的QoS路由算法.2005,16(8):1484-1489
郭山清,高丛,姚建,谢立.基于改进的随机森林算法的入侵检测模型(英文).2005,16(8):1490-1498
吴琦,熊光泽.非平稳自相似业务下自适应动态功耗管理.2005,16(8):1499-1505
张武生,杨广文,郑纬民.基于类型的运行时环境存储管理算法.2005,16(8):1506-1512
李俊,阳富民,卢炎生.一种可行的容错实时系统可调度性分析.2005,16(8):1513-1522
**************************************************************************
注:此为群发邮件。
如今后不希望再收到类似邮件,请回复此邮件,并在主题中注明:退订
**************************************************************************'''
email2 = '''Received: from coozo.com ([219.133.254.230])
by spam-gw.ccert.edu.cn (MIMEDefang) with ESMTP id j8L2Zoqi028766
for <[email protected]>; Fri, 23 Sep 2005 13:01:45 +0800 (CST)
Message-ID: <[email protected]>
From: "you" <[email protected]>
Subject: =?gb2312?B?us/X9w==?=
To: [email protected]
Content-Type: text/plain;charset="GB2312"
Content-Transfer-Encoding: 8bit
Date: Sun, 23 Oct 2005 23:44:32 +0800
X-Priority: 3
X-Mailer: Microsoft Outlook Express 6.00.2800.1106
您好!
我公司有多余的发票可以向外代开!'''
# 调用预测函数
predict(email1)
predict(email2)
以上就是今天和大家分享的朴素贝叶斯实现分类任务的应用场景,喜欢的小伙伴记得关注哦,往期文章也欢迎大家阅读…