目录
一:🔥 HTTP 协议
🧑💻 虽然我们说, 应用层协议是我们程序猿自己定的,但实际上, 已经有大佬们定义了一些现成的,又非常好用的应用层协议,供我们直接参考使用. HTTP(超文本传输协议) 就是其中之一。
🧑💻 在互联网世界中, HTTP(HyperText Transfer Protocol, 超文本传输协议) 是一个至关重要的协议。 它定义了客户端(如浏览器) 与服务器之间如何通信, 以及交换或传输超文本(如 HTML 文档) 。
🧑💻 HTTP 协议是客户端与服务器之间通信的基础。 客户端通过 HTTP 协议向服务器发送请求, 服务器收到请求后处理并返回响应。 HTTP 协议是一个无连接、 无状态的协议, 即每次请求都需要建立新的连接, 且服务器不会保存客户端的状态信息。
🦋 认识 URL
📚 平时我们俗称的 “网址” 其实就是说的 URL

🦋 urlencode 和 urldecode
📚 像 / ? : 等这样的字符, 已经被 url 当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
📚 转义的规则如下:
- 将需要转码的字符转为 16 进制, 然后从右到左, 取 4 位(不足 4 位直接处理), 每 2 位做一位, 前面加上%, 编码成 %XY 格式
📚 例如:
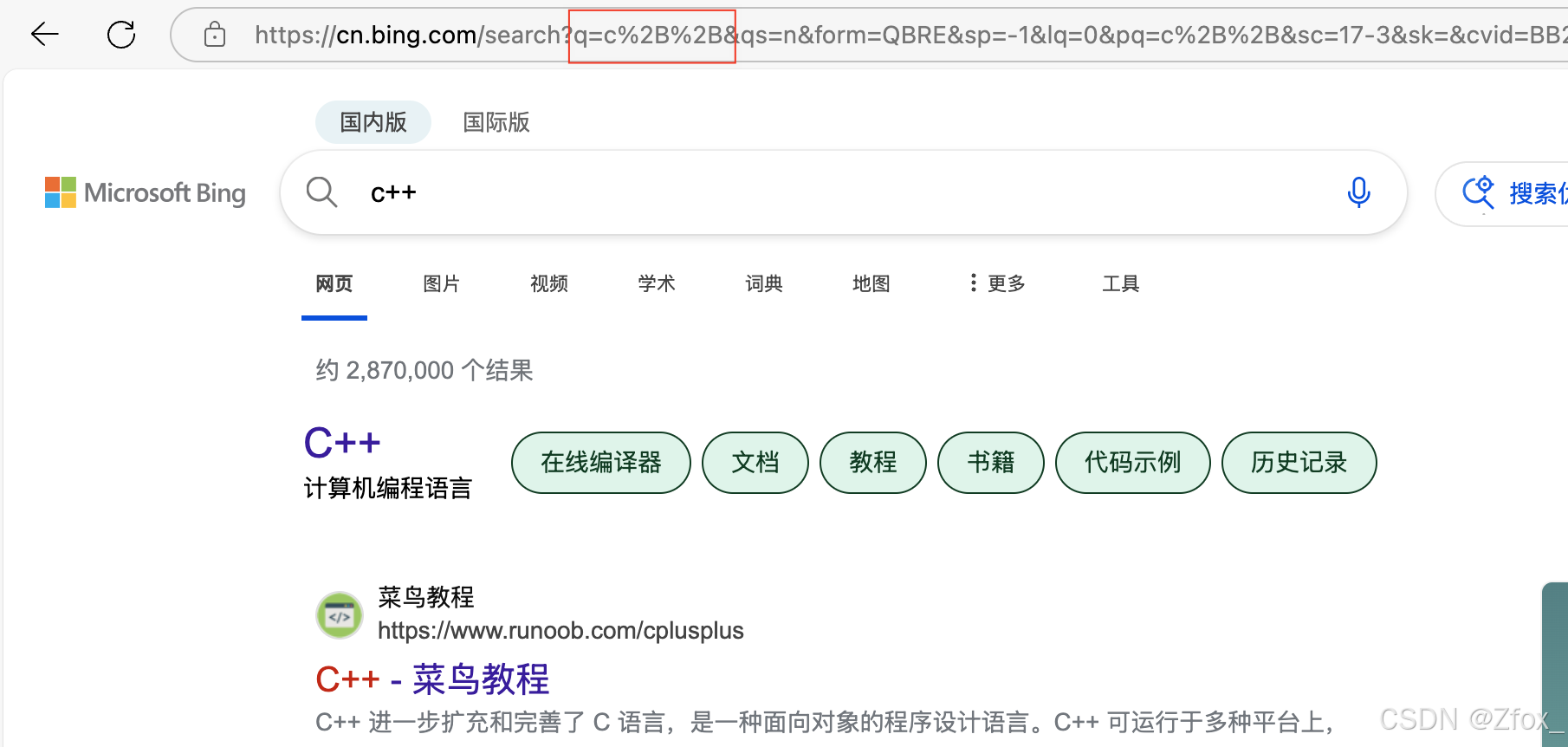
🧑💻 “+” 被转义成了 “%2B” urldecode 就是 urlencode 的逆过程;
urlencode 工具
二:🔥 HTTP 协议请求与响应格式
🦋 HTTP 请求
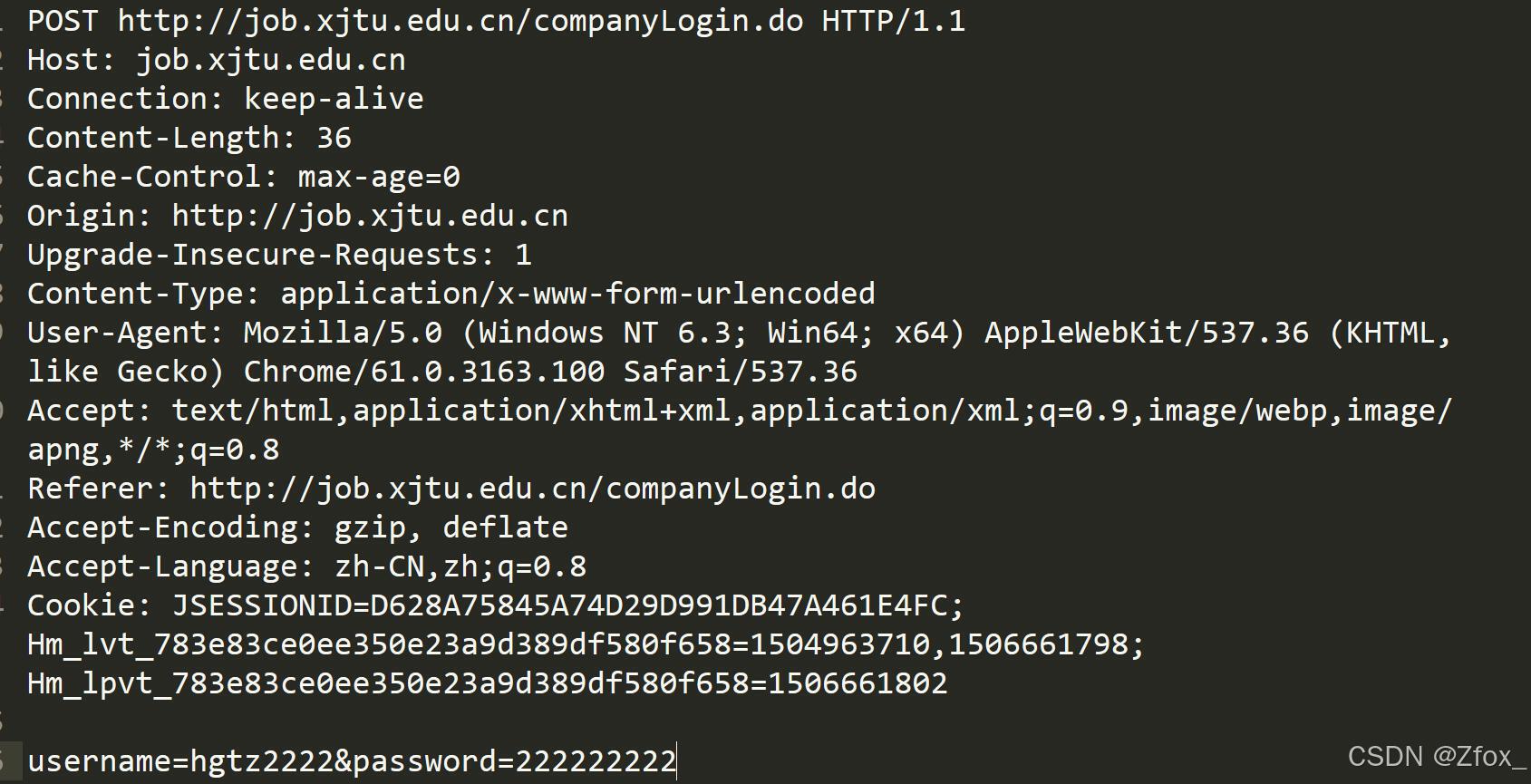
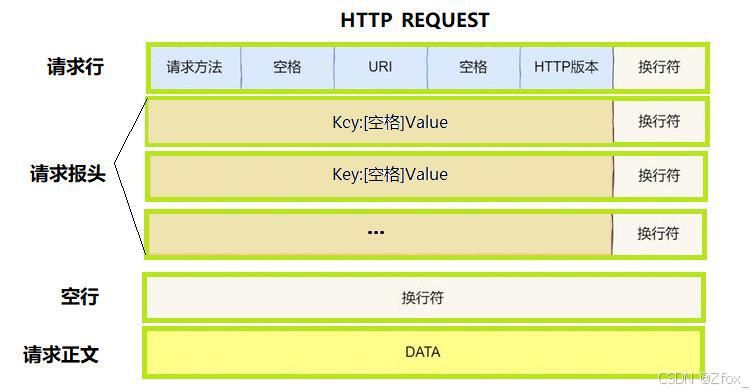
- 首行: [方法] + [uri] + [版本]
- Header: 请求报头, 冒号分割的键值对; 每组属性之间使用
\r\n分隔; 遇到空行表示 Header 部分结束- Body: 空行后面的内容都是 Body. Body 允许为空字符串.
如果 Body 存在, 则在 Header 中会有一个 Content-Length 属性来标识 Body 的长度;
🦋 HTTP 响应
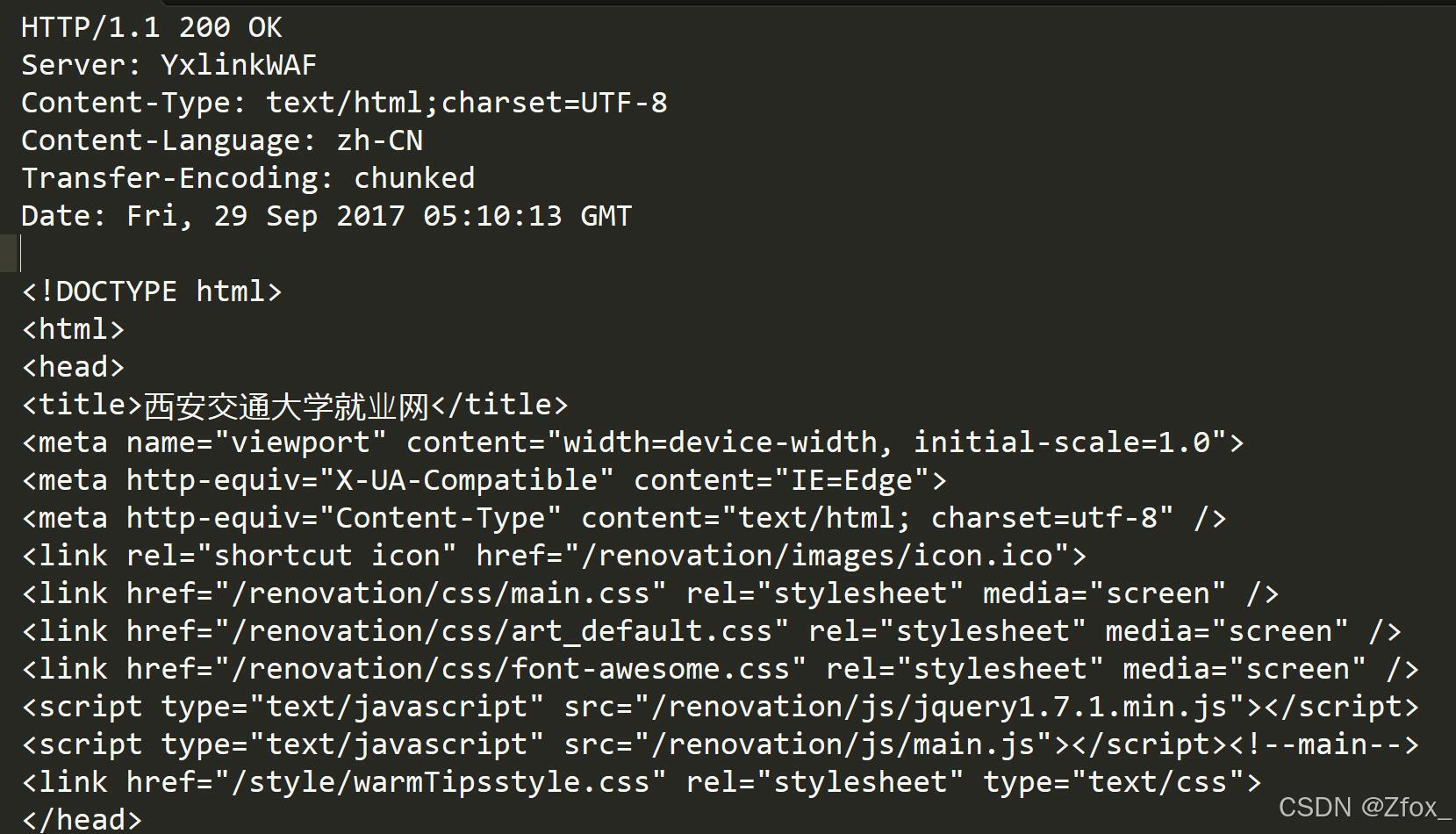
- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 响应报头, 冒号分割的键值对;每组属性之间使用 \r\n 分隔;遇到空行表示 Header 部分结束
- Body: 空行后面的内容都是 Body. Body 允许为空字符串. 如果 Body 存在, 则在 Header 中会有一个 Content-Length 属性来标识 Body 的长度; 如果服务器返回了一个 html 页面, 那么 html 页面内容就是在 body 中.

🦋 HTTP 的方法
📚 其中最常用的就是 GET 方法和 POST 方法.
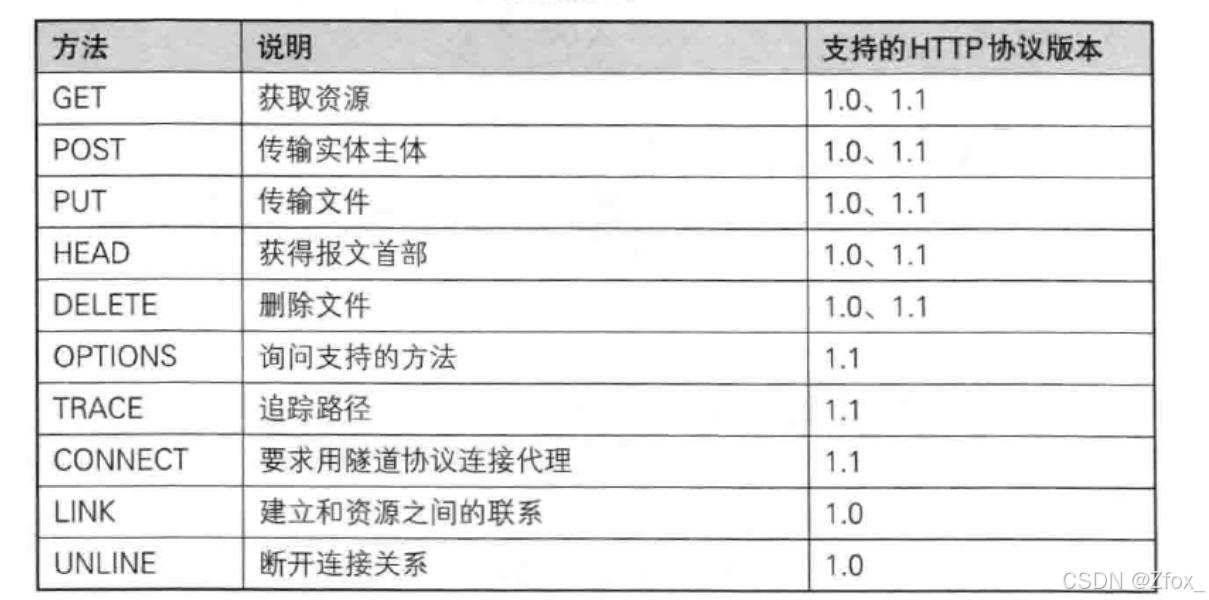
- GET 方法(重点)
- 用途: 用于请求 URL 指定的资源。
- 示例: GET /index.html HTTP/1.1
- 特性: 指定资源经服务器端解析后返回响应内容。
- form 表单: https://www.runoob.com/html/html-forms.html
- POST 方法(重点)
- 用途: 用于传输实体的主体, 通常用于提交表单数据。
- 示例: POST /submit.cgi HTTP/1.1
- 特性: 可以发送大量的数据给服务器, 并且数据包含在请求体中。
- form 表单: https://www.runoob.com/html/html-forms.htm
- PUT 方法(不常用)
- 用途: 用于传输文件, 将请求报文主体中的文件保存到请求 URL 指定的位置。
- 示例: PUT /example.html HTTP/1.1
- 特性: 不太常用, 但在某些情况下, 如 RESTful API 中, 用于更新资源。
- HEAD 方法
- 用途: 与 GET 方法类似, 但不返回报文主体部分, 仅返回响应头。
- 示例: HEAD /index.html HTTP/1.1
- 特性: 用于确认 URL 的有效性及资源更新的日期时间等。
- DELETE 方法(不常用)
- 用途: 用于删除文件, 是 PUT 的相反方法。
- 示例: DELETE /example.html HTTP/1.1
- 特性: 按请求 URL 删除指定的资源。
- OPTIONS 方法
- 用途: 用于查询针对请求 URL 指定的资源支持的方法。
- 示例: OPTIONS * HTTP/1.1
- 特性: 返回允许的方法, 如 GET、 POST 等。
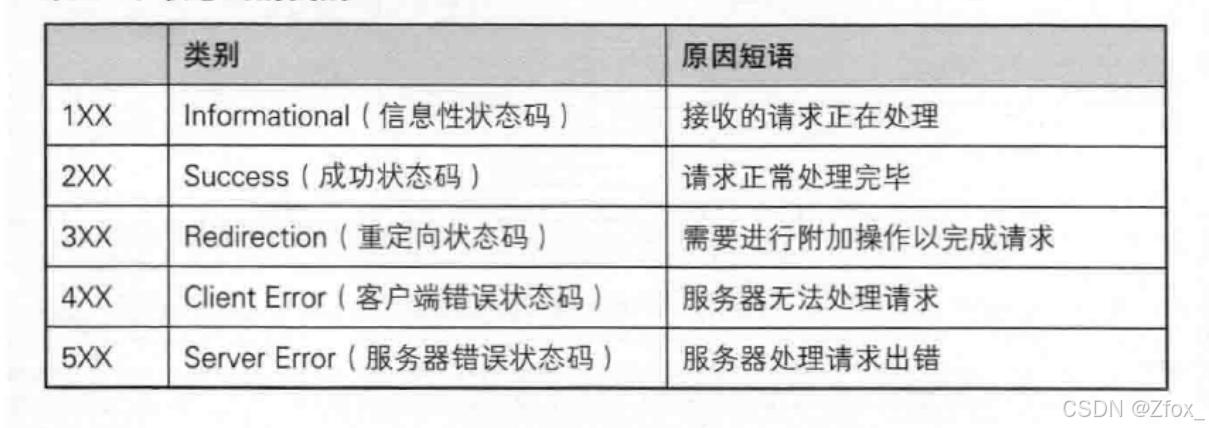
🦋 HTTP 的状态码
📚 最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
| 状态码 | 含义 | 应用样例 |
|---|---|---|
| 100 | Continue | 上传大文件时, 服务器告诉客户端可以继续上传 |
| 200 | OK | 访问网站首页, 服务器返回网页内容 |
| 201 | Created | 发布新文章, 服务器返回文章创建成功的信息 |
| 204 | No Content | 删除文章后, 服务器返回“无内容”表示操作成功 |
| 301 | Moved Permanently | 网站换域名后, 自动跳转到新域名; 搜索引擎更新网站链接时使用 |
| 302 | Found 或 See Other | 用户登录成功后, 重定向到用户首页 |
| 304 | Not Modified | 浏览器缓存机制, 对未修改的资源返回304 状态码 |
| 400 | Bad Request | 填写表单时, 格式不正确导致提交失败 |
| 401 | Unauthorized | 访问需要登录的页面时, 未登录或认证失败 |
| 403 | Forbidden | 尝试访问你没有权限查看的页面 |
| 404 | Not Found | 访问不存在的网页链接 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 |
| 502 | Bad Gateway | 使用代理服务器时, 代理服务器无法从上游服务器获取有效响应 |
| 503 | Service Unavailable | 服务器维护或过载, 暂时无法处理请求 |
📚 以下是仅包含重定向相关状态码的表格
| 状态码 | 含义 | 是否为临时重定向 | 应用样例 |
|---|---|---|---|
| 301 | Moved Permanently | 否(永久重定向) | 网站换域名后, 自动跳转到新域名;搜索引擎更新网站链接时使用 |
| 302 | Found 或 See Other | 是(临时重定向) | 用户登录成功后,重定向到用户首页 |
| 307 | Temporary Redirect | 是(临时重定向) | 临时重定向资源到新的位置(较少使用) |
| 308 | Permanent Redirect | 否(永久重定向) | 永久重定向资源到新的位置(较少使用) |
关于重定向的验证, 以 301 为代表:
HTTP 状态码 301(永久重定向) 和 302(临时重定向) 都依赖 Location 选项。 以下是关于两者依赖 Location 选项的详细说明:
HTTP 状态码 301(永久重定向) :
- 当服务器返回 HTTP 301 状态码时, 表示请求的资源已经被永久移动到新的位置。
- 在这种情况下, 服务器会在响应中添加一个 Location 头部, 用于指定资源的新位置。 这个 Location 头部包含了新的 URL 地址, 浏览器会自动重定向到该地址。
- 例如, 在 HTTP 响应中, 可能会看到类似于以下的头部信息:
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\n
HTTP 状态码 302(临时重定向) :
- 当服务器返回 HTTP 302 状态码时, 表示请求的资源临时被移动到新的位置。
- 同样地, 服务器也会在响应中添加一个 Location 头部来指定资源的新位置。 浏览器会暂时使用新的 URL 进行后续的请求,
但不会缓存这个重定向。 - 例如, 在 HTTP 响应中, 可能会看到类似于以下的头部信息:
HTTP/1.1 302 Found\r\n
Location: https://www.new-url.com\r\n
🦁 总结: 无论是 HTTP 301 还是 HTTP 302 重定向, 都需要依赖 Location 选项来指定资源的新位置。 这个 Location 选项是一个标准的 HTTP 响应头部, 用于告诉浏览器应该将请求重定向到哪个新的 URL 地址。
🦋 HTTP 常见 Header
- Content-Type: 数据类型(text/html 等)
- Content-Length: Body 的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
🦋 关于 connection 报头
🧑💻 HTTP 中的 Connection 字段是 HTTP 报文头的一部分, 它主要用于控制和管理客户端与服务器之间的连接状态
核心作用
管理持久连接: Connection 字段还用于管理持久连接(也称为长连接) 。 持久连接允许客户端和服务器在请求/响应完成后不立即关闭 TCP 连接, 以便在同一个连接上发送多个请求和接收多个响应。
持久连接(长连接)
HTTP/1.1: 在 HTTP/1.1 协议中, 默认使用持久连接。 当客户端和服务器都不明确指定关闭连接时, 连接将保持打开状态, 以便后续的请求和响应可以复用同一个连接。HTTP/1.0: 在 HTTP/1.0 协议中, 默认连接是非持久的。 如果希望在 HTTP/1.0 上实现持久连接, 需要在请求头中显式设置 Connection: keep-alive。
语法格式
Connection: keep-alive: 表示希望保持连接以复用 TCP 连接。Connection: close: 表示请求/响应完成后, 应该关闭 TCP 连接
🧑💻 下面附上一张关于 HTTP 常见 header 的表格
| 字段名 | 含义 | 样例 |
|---|---|---|
| Accept | 客户端可接受的响应内容类型 | Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8 |
| AcceptEncoding | 客户端支持的数据压缩格式 | Accept-Encoding: gzip, deflate, br |
| AcceptLanguage | 客户端可接受的语言类型 | Accept-Language: zhCN,zh;q=0.9,en;q=0.8 |
| Host | 请求的主机名和端口号 | Host: www.example.com:8080 |
| User-Agent | 客户端的软件环境信息 | User-Agent: Mozilla/5.0 (Windows NT10.0; Win64; x64)AppleWebKit/537.36 (KHTML, likeGecko) Chrome/91.0.4472.124Safari/537.36 |
| Cookie | 客户端发送给服务器的 HTTP cookie 信息 | Cookie: session_id=abcdefg12345;user_id=123 |
| Referer | 请求的来源 URL | Referer: http://www.example.com/previous_page.html |
| Content-Type | 实体主体的媒体类型 | Content-Type: application/x-wwwform-urlencoded (对于表单提交) 或Content-Type: application/json (对于JSON 数据) |
| Content-Length | 实体主体的字节大小 | Content-Length: 150 |
| Authorization | 认证信息, 如用户名和密码 | Authorization: BasicQWxhZGRpbjpvcGVuIHNlc2FtZQ== (Base64编码后的用户名:密码) |
| Cache-Control | 缓存控制指令 | 请求时: Cache-Control: no-cache 或Cache-Control: max-age=3600; 响应时:Cache-Control: public, maxage=3600 |
| Connection | 请求完后是关闭还是保持连接 | Connection: keep-alive 或Connection: close |
| Date | 请求或响应的日期和时间 | Date: Wed, 21 Oct 2023 07:28:00 GMT |
| Location | 重定向的目标URL(与 3xx 状态码配合使用) | Location:http://www.example.com/new_location.html (与 302 状态码配合使用) |
| Server | 服务器类型 | Server: Apache/2.4.41 (Unix)Last-Modified 资源的最后修改时间Last-Modified: Wed, 21 Oct 202307:20:00 GMT |
| ETag | 资源的唯一标识符, 用于缓存 | ETag: “3f80f-1b6-5f4e2512a4100” |
| Expires | 响应过期的日期和时间 | Expires: Wed, 21 Oct 2023 08:28:00 GMT |
三:🔥 实现 HTTP 服务器
🧑💻 设计模式:使用 模板方法模式 封装套接字 socket
🦁 模板方法模式是一种行为型设计模式,它在一个抽象类中定义了一个算法(业务逻辑)的骨架,具体步骤的实现由子类提供。它通过将算法的不变部分放在抽象类中,可变部分放在子类中,达到代码复用和扩展的目的。
- 复用:所有子类可以直接复用父类提供的模板方法,即上面提到的不变的部分。
- 扩展: 子类可以通过模板定义的一些扩展点就行不同的定制化实现。
模板方法模式的特点:
- 算法骨架 : 在基类中定义一个算法的固定执行步骤(模板方法),具体实现步骤交给子类完成。
- 复用代码: 子类复用基类中定义的通用逻辑,仅需实现特定步骤。
- 遵循开闭原则: 基类的骨架逻辑对扩展开放,对修改关闭。
一般用在什么场景?
- 定义算法骨架: 有一个固定的流程,但某些步骤需要根据具体情况自定义
- 复用公共逻辑: 多个子类共享相同的算法结构,仅需重写特定步骤。
- 控制执行顺序: 需要对子类执行方法的顺序进行控制时,
典型场景:
- 数据处理流程(如读取数据、处理数据、输出结果)
- Web 请求处理 (如解析请求、处理逻辑、返回响应)
📦 socket.hpp
#pragma once
#include <iostream>
#include <string>
#include <sys/socket.h>
#include <sys/types.h>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <cstdlib>
#include "Log.hpp"
#include "Common.hpp"
#include "InetAddr.hpp"
namespace SocketModule
{
using namespace LogModule;
class Socket;
using SockPtr = std::shared_ptr<Socket>;
// 基类,规定创建socket的方法
// 提供一个/若干个/固定模式的socket方法
class Socket
{
public:
virtual void SocketOrDie() = 0;
virtual void SetSocketOpt() = 0;
virtual bool BindOrDie(int port) = 0;
virtual bool ListenOrDie() = 0;
virtual SockPtr Accepter(InetAddr *client) = 0;
virtual void Close() = 0;
virtual int Recv(std::string *out) = 0;
virtual int Send(const std::string &in) = 0;
virtual int Fd() = 0;
virtual ~Socket() = default;
// 其他方法,需要的时候再加
// 提供一个创建 listensockfd 的固定套路
// 设计模式:模板方法模式
void BuildTcpSocketMethod(int port)
{
SocketOrDie();
SetSocketOpt();
BindOrDie(port);
ListenOrDie();
}
// #ifdef WIN
// // 提供一个创建 listensockfd 的固定套路
// void BuildTcpSocket()
// {
// SocketOrDie();
// SetSocketOpt();
// BindOrDie();
// ListenOrDie();
// }
// #else // Linux
// #endif
// 提供一个创建 listensockfd 的固定套路
// void BuildTcpSocket()
// {
// SocketOrDie();
// SetSocketOpt();
// BindOrDie();
// ListenOrDie();
// }
};
class TcpSocket : public Socket
{
public:
TcpSocket() : _sockfd(gdefaultsockfd)
{}
TcpSocket(int sockfd) : _sockfd(sockfd)
{}
virtual void SocketOrDie() override
{
_sockfd = ::socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
LOG(LogLevel::ERROR) << "socket error";
exit(SOCKET_ERR);
}
LOG(LogLevel::DEBUG) << "socket create success: " << _sockfd;
}
virtual void SetSocketOpt() override
{
// 保证服务器,异常断开之后,可以立即重启,不会有bind问题
int opt = 1;
int n = ::setsockopt(_sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
(void)n;
}
virtual bool BindOrDie(int port) override
{
if(_sockfd == gdefaultsockfd) return false;
InetAddr addr(port);
int n = ::bind(_sockfd, addr.NetAddr(), addr.NetAddrLen());
if(n < 0)
{
LOG(LogLevel::ERROR) << "bind error";
exit(BIND_ERR);
}
LOG(LogLevel::DEBUG) << "bind success: " << _sockfd;
return true;
}
virtual bool ListenOrDie() override
{
if(_sockfd == gdefaultsockfd) return false;
int n = ::listen(_sockfd, gbacklog);
if(n < 0)
{
LOG(LogLevel::ERROR) << "listen error";
exit(LISTEN_ERR);
}
LOG(LogLevel::DEBUG) << "listen create success: " << _sockfd;
return true;
}
// 1. 文件描述符 2. client info
virtual SockPtr Accepter(InetAddr *client) override
{
if(!client) return nullptr;
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int newsockfd = ::accept(_sockfd, CONV(&peer), &len);
if(newsockfd < 0)
{
LOG(LogLevel::WARNING) << "accept error";
return nullptr;
}
client->SetAddr(peer, len);
return std::make_shared<TcpSocket>(newsockfd); // accept之后链接好的 sockfd
}
virtual void Close() override
{
if(_sockfd == gdefaultsockfd) return ;
::close(_sockfd);
}
virtual int Recv(std::string *out) override
{
char buffer[1024 * 8];
auto size = ::recv(_sockfd, buffer, sizeof(buffer), 0);
if(size > 0)
{
buffer[size] = 0;
*out = buffer;
}
return size;
}
virtual int Send(const std::string &in) override
{
auto size = ::send(_sockfd, in.c_str(), in.size(), 0);
return size;
}
virtual int Fd() override
{
return _sockfd;
}
virtual ~TcpSocket()
{
}
private:
int _sockfd;
};
}
📦 http协议封装
HttpProtocol.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
#include <unordered_map>
#include <fstream>
#include "Common.hpp"
#include "Log.hpp"
const std::string Sep = "\r\n";
const std::string LineSep = " ";
const std::string HeaderLineSep = ": ";
const std::string BlankLine = Sep;
const std::string defaulthomepage = "wwwroot";
const std::string http_version = "HTTP/1.0";
const std::string page404 = "wwwroot/404.html";
const std::string firstpage = "index.html";
using namespace LogModule;
class HttpReauest
{
public:
HttpReauest() {}
~HttpReauest() {}
bool IsHasArgs()
{
return _isexec;
}
bool ParseHeaderKv()
{
std::string key, value;
for(auto &herder : _req_header)
{
if(SplitString(herder, HeaderLineSep, &key, &value))
{
_headerkv.insert(std::make_pair(key, value));
}
}
return true;
}
bool ParseHeader(std::string &request_str)
{
std::string line;
while(true)
{
bool r = ParseOneLine(request_str, &line, Sep);
if(r && !line.empty())
{
_req_header.push_back(line);
}
else if(r && line.empty())
{
_blank_line = Sep;
break;
}
else
{
return false;
}
}
ParseHeaderKv();
return true;
}
void Deserialize(std::string &request_str)
{
if(ParseOneLine(request_str, &_req_line, Sep))
{
// 提取请求行中的详细字段
ParseReqLine(_req_line, LineSep);
ParseHeader(request_str); // 解析报头
_body = request_str;
// 分析请求中是否含有参数
if(_method == "POST")
{
_isexec = true; // 参数在正文
_path = _uri;
_args = _body;
}
else if(_method == "GET")
{
auto pos = _uri.rfind('?');
if(pos != std::string::npos)
{
_isexec = true;
// /login?name=zhangsan&passwd=123456
_path = _uri.substr(0, pos);
_args = _uri.substr(pos + 1);
}
}
}
}
std::string GetContent(const std::string &path)
{
// 二进制读
std::string content;
std::ifstream in(path, std::ios::binary);
if(!in.is_open()) return std::string();
in.seekg(0, in.end);
int filesize = in.tellg();
in.seekg(0, in.beg);
content.resize(filesize);
in.read((char*)content.c_str(), filesize);
in.close();
LOG(LogLevel::DEBUG) << "content length: " << content.size();
return content;
// 暂时做法
// std::string content;
// std::ifstream in(_uri);
// if(!in.is_open()) return std::string();
// std::string line;
// while(getline(in, line))
// {
// content += line;
// }
// in.close();
// return content;
}
void Print()
{
std::cout << "_method: " << _method << std::endl;
std::cout << "_uri: " << _uri << std::endl;
std::cout << "_version: " << _version << std::endl;
for(auto &kv : _headerkv)
{
std::cout << kv.first << " # " << kv.second << std::endl;
}
std::cout << "_blank_line: " << _blank_line << std::endl;
std::cout << "_body: " << _body << std::endl;
}
std::string Uri()
{
return _uri;
}
void SetUri(const std::string &newuri)
{
_uri = newuri;
}
std::string Path() { return _path; }
std::string Args() { return _args; }
std::string Suffix()
{
auto pos = _uri.rfind(".");
if(pos == std::string::npos) return std::string(".html");
else return _uri.substr(pos);
}
private:
void ParseReqLine(const std::string &_req_line, const std::string &LineSep) // 请求行字段解析
{
(void)LineSep;
std::stringstream ss(_req_line);
ss >> _method >> _uri >> _version;
}
private:
std::string _req_line;
std::vector<std::string> _req_header;
std::string _blank_line;
std::string _body;
// 在反序列化的过程中,细化我们解析出来的字段
std::string _method;
std::string _uri; // 用户想要这个
std::string _path;
std::string _args;
std::string _version;
std::unordered_map<std::string, std::string> _headerkv;
bool _isexec = false;
};
// 对于http请求,都要有应答
class HttpResponse
{
public:
HttpResponse() : _version(http_version), _blank_line(Sep)
{}
void Build(HttpReauest &req)
{
std::string uri = defaulthomepage + req.Uri();
if(uri.back() == '/')
{
uri += firstpage;
// req.SetUri(uri);
}
_content = req.GetContent(uri);
if(_content.empty())
{
// 用户请求的资源并不存在
_status_code = 404;
_content = req.GetContent(page404);
}
else
{
_status_code = 200;
}
LOG(LogLevel::DEBUG) << "客户端在请求:" << req.Uri();
_status_desc = Code2Desc(_status_code); // 和状态码是强相关的
if(!_content.empty())
{
SetHeader("Content-Length", std::to_string(_content.size()));
std::string mime_type = Suffix2Desc(req.Suffix());
SetHeader("Content-Type", mime_type);
}
_body = _content;
}
void SetCode(int code)
{
_status_code = code;
_status_desc = Code2Desc(_status_code);
}
void SetBody(const std::string &body)
{
_body = body;
}
void SetHeader(const std::string &k, const std::string &v)
{
_header_kv[k] = v;
}
void Serialize(std::string *resp_str)
{
for(auto &header : _header_kv)
{
_resp_header.push_back(header.first + HeaderLineSep + header.second);
}
_resp_line = _version + LineSep + std::to_string(_status_code) + LineSep + _status_desc + Sep; // 第一行
// 序列化
*resp_str = _resp_line;
for(auto &line : _resp_header)
{
*resp_str += (line + Sep);
}
*resp_str += _blank_line;
*resp_str += _body;
}
~HttpResponse() {}
private:
std::string Code2Desc(int code)
{
switch (code)
{
case 200:
return "OK";
case 404:
return "Not Found";
case 301:
return "Move Permanently";
case 302:
return "Found";
default:
return std::string();
}
}
std::string Suffix2Desc(const std::string &suffix)
{
if(suffix == ".html")
return "text/html";
else if(suffix == ".jpg")
return "application/x-jpg";
else
return "text/html";
}
private:
// 必备的要素
std::string _version;
int _status_code;
std::string _status_desc;
std::string _content;
std::unordered_map<std::string, std::string> _header_kv;
// 最终要这4部分,构建应答
std::string _resp_line;
std::vector<std::string> _resp_header;
std::string _blank_line;
std::string _body;
};
🦋 完整代码移步我的Gitee仓库
🧑💻 点击跳转 包含代码和详细注释
🧑💻 至此 成功访问http服务器上搭建的网站


备注:
此处我们使用 8080 端口号启动了 HTTP 服务器. 虽然 HTTP 服务器一般使用 80 端口,
但这只是一个通用的习惯. 并不是说 HTTP 服务器就不能使用其他的端口号.
四:🔥 附录
🦋 HTTP 历史及版本核心技术与时代背景
🧑💻 HTTP(Hypertext Transfer Protocol, 超文本传输协议) 作为互联网中浏览器和服务器间通信的基石, 经历了从简单到复杂、 从单一到多样的发展过程。 以下将按照时间顺序, 介绍 HTTP 的主要版本、 核心技术及其对应的时代背景。
🦋 HTTP/0.9
📚 核心技术:
- 仅支持 GET 请求方法。
- 仅支持纯文本传输, 主要是 HTML 格式。
- 无请求和响应头信息。
📚 时代背景:
- 1991 年, HTTP/0.9 版本作为 HTTP 协议的最初版本, 用于传输基本的超文本 HTML 内容。
- 当时的互联网还处于起步阶段, 网页内容相对简单, 主要以文本为主。
🦋 HTTP/1.0
📚 核心技术:
- 引入 POST 和 HEAD 请求方法。
- 请求和响应头信息, 支持多种数据格式(MIME) 。
- 支持缓存(cache) 。
- 状态码(status code) 、 多字符集支持等。
📚 时代背景:
- 1996 年, 随着互联网的快速发展, 网页内容逐渐丰富, HTTP/1.0 版本应运而生。
- 为了满足日益增长的网络应用需求, HTTP/1.0 增加了更多的功能和灵活性。
- 然而, HTTP/1.0 的工作方式是每次 TCP 连接只能发送一个请求, 性能上存在一定局限。
🦋 HTTP/1.1
📚 核心技术:
- 引入持久连接(persistent connection) , 支持管道化(pipelining) 。
- 允许在单个 TCP 连接上进行多个请求和响应, 提高了性能。
- 引入分块传输编码(chunked transfer encoding) 。
- 支持 Host 头, 允许在一个 IP 地址上部署多个 Web 站点。
📚 时代背景:
- 1999 年, 随着网页加载的外部资源越来越多, HTTP/1.0 的性能问题愈发突出。
- HTTP/1.1 通过引入持久连接和管道化等技术, 有效提高了数据传输效率。
- 同时, 互联网应用开始呈现出多元化、 复杂化的趋势, HTTP/1.1 的出现满足了这些需求。
🦋 HTTP/2.0
📚 核心技术:
- 多路复用(multiplexing) , 一个 TCP 连接允许多个 HTTP 请求。
- 二进制帧格式(binary framing) , 优化数据传输。
- 头部压缩(header compression) , 减少传输开销。
- 服务器推送(server push) , 提前发送资源到客户端。
📚 时代背景:
- 2015 年, 随着移动互联网的兴起和云计算技术的发展, 网络应用对性能的要求越来越高。
- HTTP/2.0 通过多路复用、 二进制帧格式等技术, 显著提高了数据传输效率和网络性能。
- 同时, HTTP/2.0 还支持加密传输(HTTPS) , 提高了数据传输的安全性。
🦋 HTTP/3.0
📚 核心技术:
- 使用 QUIC 协议替代 TCP 协议, 基于 UDP 构建的多路复用传输协议。
- 减少了 TCP 三次握手及 TLS 握手时间, 提高了连接建立速度。
- 解决了 TCP 中的线头阻塞问题, 提高了数据传输效率。
📚 时代背景:
- 2022 年, 随着 5G、 物联网等技术的快速发展, 网络应用对实时性、 可靠性的要求越来越高。
- HTTP/3.0 通过使用 QUIC 协议, 提高了连接建立速度和数据传输效率, 满足了这些需求。
- 同时, HTTP/3.0 还支持加密传输(HTTPS) , 保证了数据传输的安全性
五:🔥 共勉
以上就是我对 应用层协议 HTTP 讲解&实战:从0实现HTTP 服务器 的理解,想要完整代码可以私信博主噢!觉得这篇博客对你有帮助的,可以点赞收藏关注支持一波~😉