1.规则挖掘简介
- 两种常见的风险规避手段:
- AI模型
- 规则
- 如何使用规则进行风控
- **使用一系列逻辑判断(以往从职人员的经验)**对客户群体进行区分, 不同群体逾期风险有显著差别
- 比如:多头借贷是否超过一定的数量,设定一个值,如果超过这个值则拒绝借贷
- 采用一条规则就可以将用户进行分组,可以将用户划分到高风险组,在高风险组中的用户则直接进行拒绝;如果不在高风险组就进入到下一条规则的判断
- 规则和AI模型的优点:
- 规则:可以快速使用,便于业务人员理解,但是判断相对简单粗暴,单一维度不满条件直接拒绝
- AI模型:开发周期长,对比使用规则更复杂,但是更加灵活,用于对于风控精度要求更高的场景。
- 可以通过AI模型辅助建立规则引擎,决策树很适合规则挖掘的场景。
2 规则挖掘案例
2.1 案例背景
某互联网公司拥有多个业务板块,每个板块下都有专门的贷款产品。
-
外卖平台业务的骑手可以向平台申请“骑手贷”
-
电商平台业务的商户可以申请“网商贷”
-
网约车业务的司机可以向平台申请“司机贷”
公司有多个类似的场景,共用相同的规则引擎及申请评分卡,贷款人都是该公司的兼职人员
近期发现,“司机贷”的逾期率较高
- 整个金融板块30天逾期率为1.5%
- 司机贷”产品的30天逾期达到了5%
期望解决方案:
- 现有的风控架构趋于稳定
- 希望快速开发快速上线,解决问题
- 尽量不使用复杂的方法
- 考虑使用现有数据挖掘出合适的业务规则
数据:
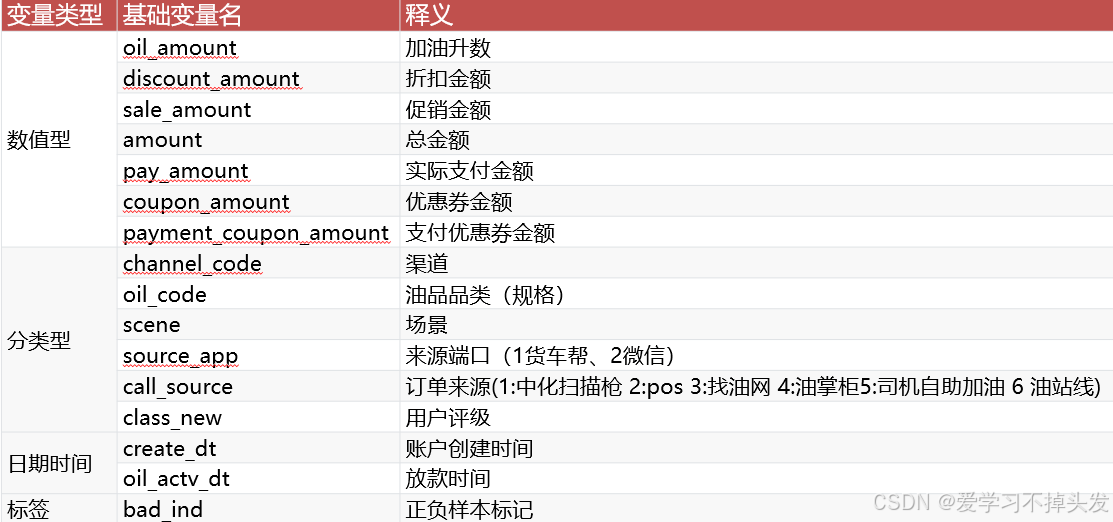
- 常用的数据分为两类:数值型数据和类别型数据
- 原始数据中有些数据需要进行处理,有些数据不需要进行处理
2.2 规则挖掘流程
加载数据
import pandas as pd
import numpy as np
data = pd.read_excel('../data/rule_data.xlsx')
data.head()

data.shape

# 查看有多少类别
data.class_new.unique()

data.info()

- create_dt - 有很多缺失值,需要进行处理
2.3 特征衍生
原始数据的特征太少,考虑在原始特征基础上衍生出一些新的特征来,将特征分成三类分别处理
- 数值类型变量:按照id分组后,采用多种方式聚合,衍生新特征
- 最终得到每个特征按照id分组聚合之后的df
- 分类类型变量,按照id分组后,聚合查询条目数量,衍生新特征
- 其它:日期时间类型,是否违约(标签),用户评级等不做特征衍生处理
# 原始数据中有19个特征
# org_list - 不用于进行特征衍生的列
# agg_list - 数值类型的特征,需要进行分组聚合
# count_list - 类别型特征,需要进行分组计数
org_list = ['uid','create_dt','oil_actv_dt','class_new','bad_ind']
agg_list = ['oil_amount','discount_amount','sale_amount','amount','pay_amount','coupon_amount','payment_coupon_amount']
count_list = ['channel_code','oil_code','scene','source_app','call_source']
- 对原始数据进行copy,防止操作出错,需要重新加载数据
df = data[org_list].copy()
df[agg_list] = data[agg_list].copy()
df[count_list] = data[count_list].copy()
# 查看数据是不是又缺失值
df.isna().sum()

- 缺失值填充
# 按照uid和create_dt进行降序排序
df.sort_values(['uid','create_dt'],ascending = False)
- 对creat_dt做补全,用oil_actv_dt来填补
# 传入两个值
ef time_isna(x,y):
if str(x) == 'NaT':
x = y
return x
df2 = df.sort_values(['uid','create_dt'],ascending = False)
# apply返回一个由自定函数返回值组成的series
# axis = 1 将df2的行送入到series中 ,df传入的虽然是行,但是结构仍然是series
df2['create_dt'] = df2.apply(lambda x: time_isna(x.create_dt,x.oil_actv_dt),axis = 1)
# df2.apply(lambda x: time_isna(x.create_dt,x.oil_actv_dt),axis = 1)
- 截取申请时间和放款时间不超过6个月的数据(考虑数据时效性)
# 两个时间相减得到的是timedelta类型的数据
# 需要通过x.days获取到具体的不带days的数据
df2['dtn'] = (df2.oil_actv_dt - df2.create_dt).apply(lambda x :x.days)
df = df2[df2['dtn']<180]
df.head()
- 将用户按照id编号排序,并保留最近一次申请时间,确保每个用户有一条记录(每个样本送入到模型中都是一条数据)
base = df[org_list] # 不进行特征衍生的数据
base['dtn'] = df['dtn']
base = base.sort_values(['uid','create_dt'],ascending = False)
base = base.drop_duplicates(['uid'],keep = 'first')
base.shape

- 特征值衍生
- 对连续统计型变量进行函数聚合
- 方法包括对历史特征值计数、求历史特征值大于0的个数、求和、求均值、求最大/小值、求最小值、求方差、求极差等
gn = pd.DataFrame() # 创建一个空的dataframe
for i in agg_list: # 遍历需要进行特征衍生的特征
# 按照uid进行分组,groupby()应用apply函数传入的是每个组的df
# 获取长度
tp = df.groupby('uid').apply(lambda df:len(df[i])).reset_index()
tp.columns = ['uid',i + '_cnt']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求历史特征值大于0的个数
tp = df.groupby('uid').apply(lambda df:np.where(df[i]>0,1,0).sum()).reset_index()
tp.columns = ['uid',i + '_num']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求和
tp = df.groupby('uid').apply(lambda df:np.nansum(df[i])).reset_index()
tp.columns = ['uid',i + '_tot']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求平均值
tp = df.groupby('uid').apply(lambda df:np.nanmean(df[i])).reset_index()
tp.columns = ['uid',i + '_avg']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求最大值
tp = df.groupby('uid').apply(lambda df:np.nanmax(df[i])).reset_index()
tp.columns = ['uid',i + '_max']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求最小值
tp = df.groupby('uid').apply(lambda df:np.nanmin(df[i])).reset_index()
tp.columns = ['uid',i + '_min']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求方差
tp = df.groupby('uid').apply(lambda df:np.nanvar(df[i])).reset_index()
tp.columns = ['uid',i + '_var']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求极差
tp = df.groupby('uid').apply(lambda df:np.nanmax(df[i]) -np.nanmin(df[i]) ).reset_index()
tp.columns = ['uid',i + '_ran']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
- 查看衍生结果
gn.columns

- 对dstc_lst变量求distinct个数
- 对类别型的变量,按照uid进行分组之后,去重之后进行计数
gc = pd.DataFrame()
for i in count_list:
tp = df.groupby('uid').apply(lambda df: len(set(df[i]))).reset_index()
tp.columns = ['uid',i + '_dstc']
if gc.empty:
gc = tp
else:
gc = pd.merge(gc,tp,on = 'uid',how = 'left')
- 将三个部分的df进行拼接
fn = pd.merge(base,gn,on= 'uid')
fn = pd.merge(fn,gc,on= 'uid')
fn.shape
- merge过程中可能会出现缺失情况,填充缺失值
fn = fn.fillna(0)
fn.head(100)
2.4 训练决策树模型
- 选择数据,训练模型
x = fn.drop(['uid','oil_actv_dt','create_dt','bad_ind','class_new'],axis = 1)
y = fn.bad_ind.copy()
from sklearn import tree
dtree = tree.DecisionTreeRegressor(max_depth = 2,min_samples_leaf = 500,min_samples_split = 5000)
dtree = dtree.fit(x,y)
- 输出决策树图像
import pydotplus
from IPython.display import Image
from six import StringIO
# import os
# os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
# with open("dt.dot", "w") as f:
# tree.export_graphviz(dtree, out_file=f)
dot_data = StringIO() # 开辟内存空间
# dtree - 指定模型
# out_file - 指定空间
# feature_name - 指定特征矩阵x的列名 x.columns
# class_name - 指定y标签列的列名
tree.export_graphviz(dtree, out_file=dot_data,
feature_names=x.columns,
class_names=['bad_ind'],
filled=True, rounded=True,
special_characters=True)
dot_data.getvalue()
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
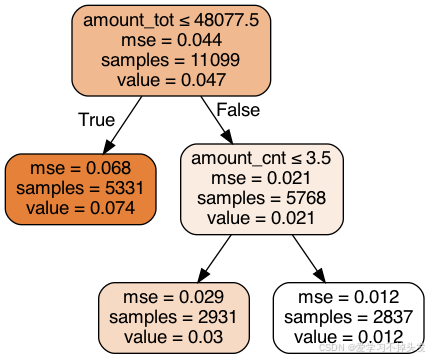

2.5 利用结果划分分组
group_1 = fn.loc[(fn.amount_tot>48077.5)&(fn.amount_cnt>3.5)].copy()
group_1['level'] = 'past_A'
group_2 = fn.loc[(fn.amount_tot>48077.5)&(fn.amount_cnt<=3.5)].copy()
group_2['level'] = 'past_B'
group_3 = fn.loc[fn.amount_tot<=48077.5].copy()
group_3['level'] = 'past_C'
- 如果拒绝past_C类客户,则可以使整体负样本占比下降至0.021
- 如果将past_B也拒绝掉,则可以使整体负样本占比下降至0.012
- 至于实际对past_A、past_B、past_C采取何种策略,要根据利率来做线性规划,从而实现风险定价