前言:实际上设计任何一种数据库应用系统,不论是基于何种数据模型,都会遇到如何构造合适的数据模式即逻辑结构的问题。由于关系模型有严格的数学理论基础,并且可以向别的数据模型转换。所以要设计合适的关系模式,使其逻辑结构更加符合要求,出现了规范化理论。而三大范式即第一,第二,和第三范式就是规范化理论重要部分,是为了在设计中更好的解决数据冗余,数据有效性检查,提高存储效率。 另外还有第四范式,第五范式等。
1.第一范式:强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项。
2. 第二范式:要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
3.第三范式:任何非主属性不依赖于其它非主属性。
在实际的开发中需要考虑诸多问题,如:
- 考虑商业化的需求和目标(成本,用户体验),数据库的性能更加重要
- 在规范性能问题的时候,需要适当地考虑一下规范性
- 有时候会故意给某些表增加一些冗余的字段(多表查询→单表查询)
- 有时会故意增加一些计算列(比如当有几百万条数据时,SELECT COUNT(*)会非常慢,直接增加一个计算列,每次增加一条数据时,这个列自动加一 )(大数据量→小数据量)
-
由此可见,实际中并没有去严格遵守这种规范。因为规范和性能不可兼得!规范越高,性能越低。
范式(Normal Form,NF)
范式是符合某一种级别的关系模式的集合。关系数据库中的关系是要满足一定要求的,满足不同程度要求的为不同范式。
目前关系数据库有六种范式:1NF,2NF,3NF,BCNF,4NF,5NF
这六种范式是包含关系:5NF ⊂ 4NF ⊂ BCNF ⊂ 3NF ⊂ 2NF ⊂ 1NF
常用的是第一范式(1NF)、第二范式(2NF)、第三范式(3NF),俗称“三大范式”。
第一范式(1NF)
第一范式是指数据库表的每一列都是不可分割的基本数据项。
举例:
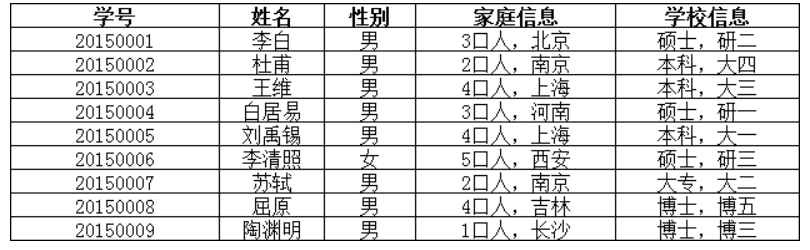
上面的表中,家庭信息”和“学校信息”就不满足第一范式,它们还可以再分割,调整如下:
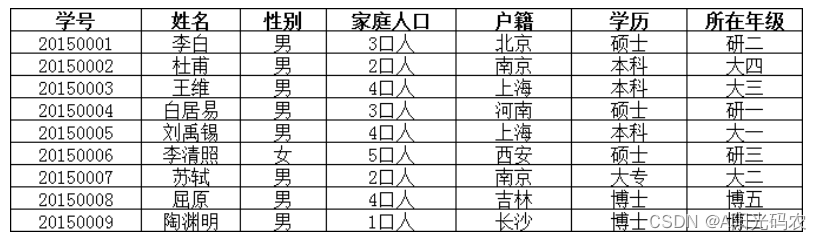
调整后每一列都不能再分了,故满足第一范式。
第二范式(2NF)
第二范式
-
必须满足第一范式
-
非主属性完全依赖于主关键字,不能依赖于主键的一部分
注:什么叫依赖于主键的一部分?这是针对联合主键而言的,联合主键就是用多个属性组成的主键。
例子
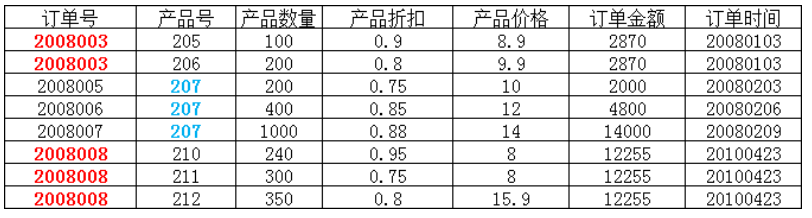
上表中,主键为联合主键[订单号,产品号],(只有这两个属性组合在一起,才能唯一地标识一行信息),这个表满足第一范式(不可再分),但不满足第二范式,因为“订单金额”和“订单时间”只依赖于“订单号”(知道订单号,订单金额和时间也就确定了),不依赖于“产品号”,换句话说,他们不完全依赖主键[订单号,产品号],而是依赖于主键的一部分,因此不满足第二范式。调整如下:
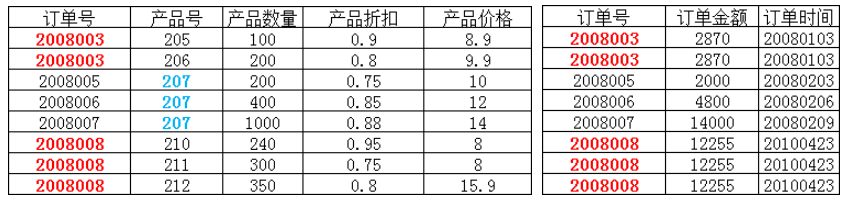
分成了两个表,每个表都满足第二范式,左表的非主属性完全依赖于主键[订单号,产品号],右表的非主属性完全依赖于主键[订单号]。
第三范式(3NF)
第三范式
- 必须满足第二范式
- 任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
就是说,对于一个满足第二范式的表,表中有可能存在某些列不直接依赖主键,而是间接依赖,必须消除。
例子
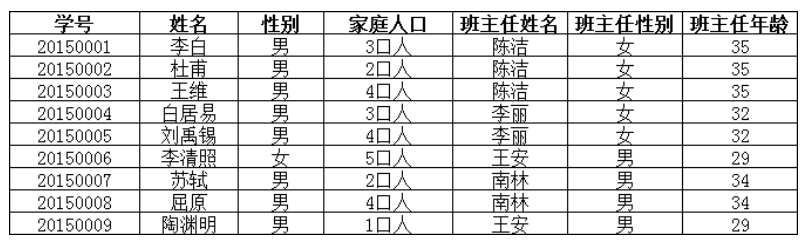
上表中,所有属性都完全依赖于学号这个主键,但是“班主任性别”和“班主任年龄”不是直接依赖学号的,而是通过直接依赖于“班主任姓名”而间接依赖于学号的(班主任姓名是直接依赖于学号的),故不满足第三范式。调整如下:
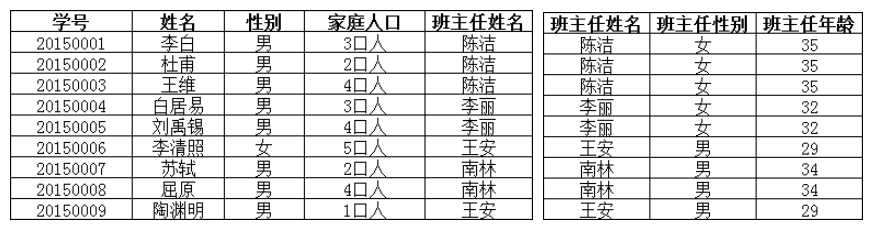
分成了两个表,每个表都满足第三范式。