pix2pix论文详解 – 潘登同学的对抗神经网络笔记
文章目录
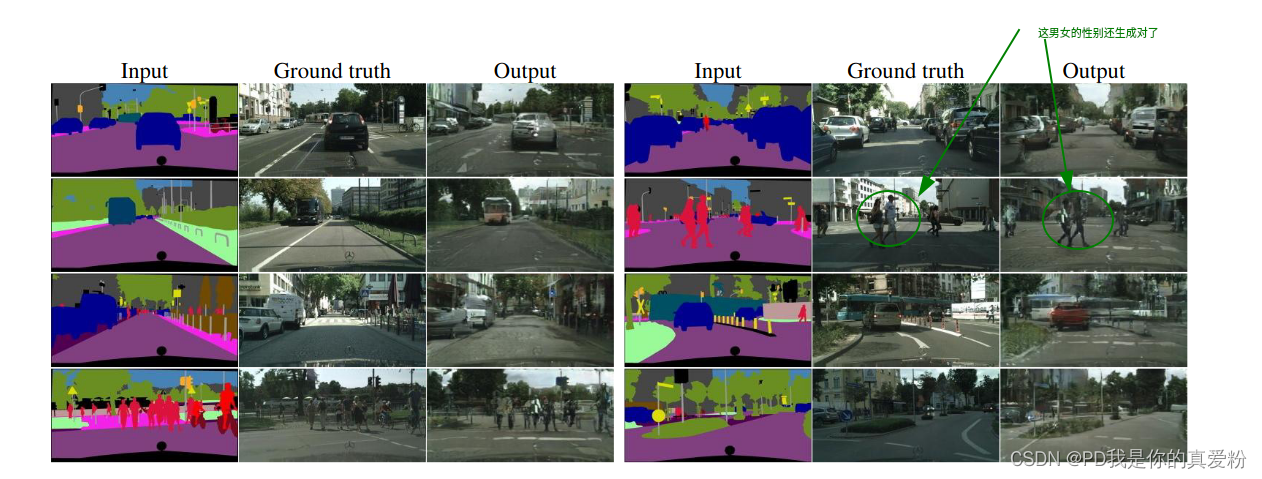
pix2pix在语义标签图转真实照片、简笔画转真图、黑白图像上色、卫星航拍图转地图等图像转译任务上表现优秀
pix2pix简介
pix2pix是Conditional GAN的一个变体,能够实现从图像到图像的映射,在从标签映射合成照片、从边缘映射重建对象、图片上色等多类人物的表现较好。它比较适合于监督学习,即图像的输入和它的输出是相互匹配的。所谓匹配数据集是指在训练集中两个互相转换的领域之间有明确的一一对应数据。在工程实践中研究者需要自己收集这些匹配数据,但有时同时采集两个不同领域的匹配数据是麻烦的,通常采用的方案是从更完整的数据中还原简单数据。比如直接将彩色图片通过图像处理的方法转为黑白图片。
模型输入
下图展示了Pix2Pix使用Conditional GAN训练生成对抗网络的思路,这里是手绘鞋和真实鞋子图像的一组配对数据,生成器通过作为条件的手绘数据生成了左图中的鞋子,然后我们将两者放入判别器中,判别器应该判断为假,而当我们将真实的配对数据输入时,判别器应该判断为真。

与GAN的区别
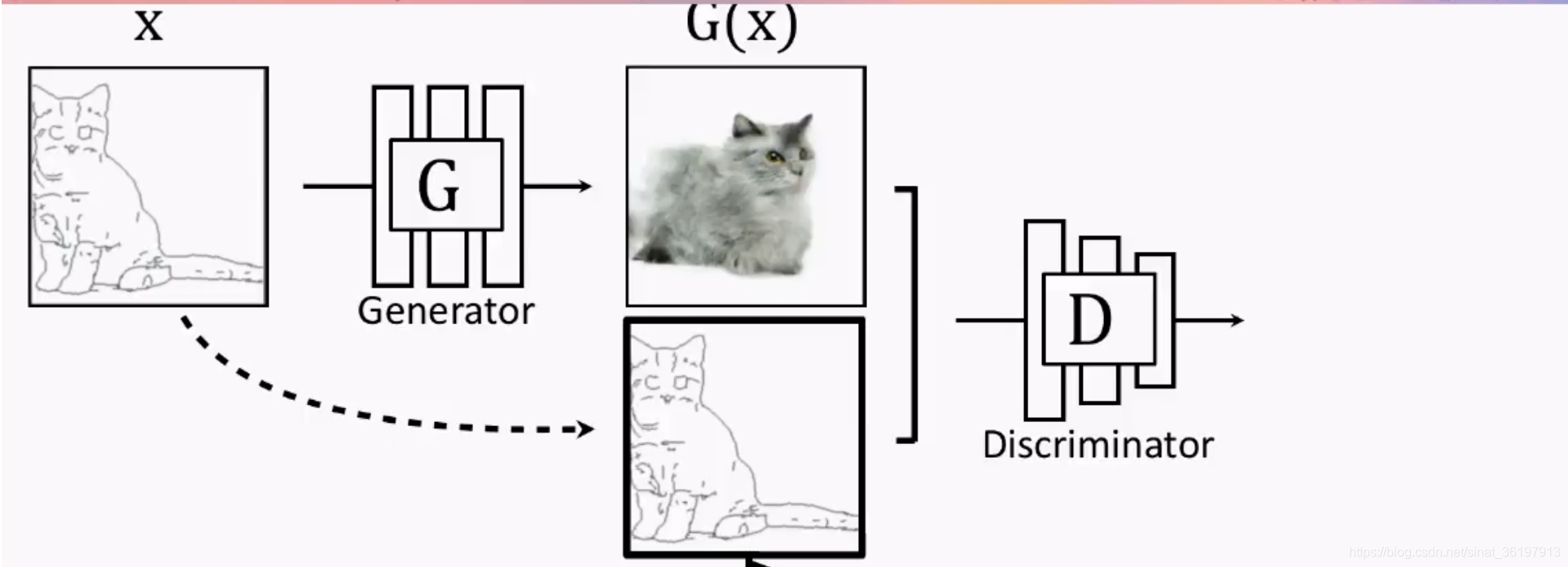
对于图像翻译任务来说,pix2pix对传统的GAN做了个小改动,它不再输入随机噪声,而是输入用户给的图片。它的G输入显然应该是一张图 x x x,输出当然也是一张图 y y y。但是D的输入却应该发生一些变化,因为除了要生成真实图像之外,还要保证生成的图像和输入图像是匹配的。于是D的输入就做了一些变动,如下图所示:
Loss函数的选取


conditional GAN的loss
x是输入图像,y是真实图像,z是噪声; 判别器G想让Loss最大化,而生成器D则想让Loss最小化
L
c
G
A
N
(
G
,
D
)
=
E
x
,
y
[
log
D
(
x
,
y
)
]
+
E
x
,
z
[
log
(
1
−
D
(
x
,
G
(
x
,
z
)
)
)
]
L_{cGAN}(G,D) = E_{x,y}[\log{D(x,y)}] + E_{x,z}[\log(1-D(x,G(x,z)))]
LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
作为对比,以下列一个普通GAN的loss函数
L
G
A
N
(
G
,
D
)
=
E
y
[
log
D
(
y
)
]
+
E
x
,
z
[
log
(
1
−
D
(
G
(
x
,
z
)
)
)
]
L_{GAN}(G,D) = E_y[\log{D(y)}] + E_{x,z}[\log(1-D(G(x,z)))]
LGAN(G,D)=Ey[logD(y)]+Ex,z[log(1−D(G(x,z)))]
同时,一般的conditional GAN会给loss加上一个l2 loss,但是pix2pix实验过后,选择了l1 loss(这两者都会使得图像变得模糊)
L
L
1
(
G
)
=
E
x
,
y
,
z
[
∣
∣
y
−
G
(
x
,
z
)
∣
∣
1
]
L_{L1}(G) = E_{x,y,z}[||y - G(x,z)||_{1}]
LL1(G)=Ex,y,z[∣∣y−G(x,z)∣∣1]
总的来说,pix2pix的目标函数就是
G
∗
=
arg min
G
m
a
x
D
L
c
G
A
N
(
G
,
D
)
+
λ
L
L
1
(
G
)
G^* = \argmin_{G}max_{D} L_{cGAN}(G,D) + \lambda L_{L1}(G)
G∗=GargminmaxDLcGAN(G,D)+λLL1(G)
注意 这里之所以加噪声的原因是: 如果不加噪声的话,会导致网络总是生成确定性的结果(对于cGAN);就是所谓的delta functiion. delta function就是在x为零的时候,输出的y不为零,当x不为零的时候,输出的y一直为零; (但是在pix2pix中,没有发现这个现象,而且pix2pix是通过dropout来增加爱随机性的)

生成器网络结构
网络采用的是U-Net的FCN全卷积网络
之前在讲语义分割的时候,也讲过U-Net,重新回顾一下;
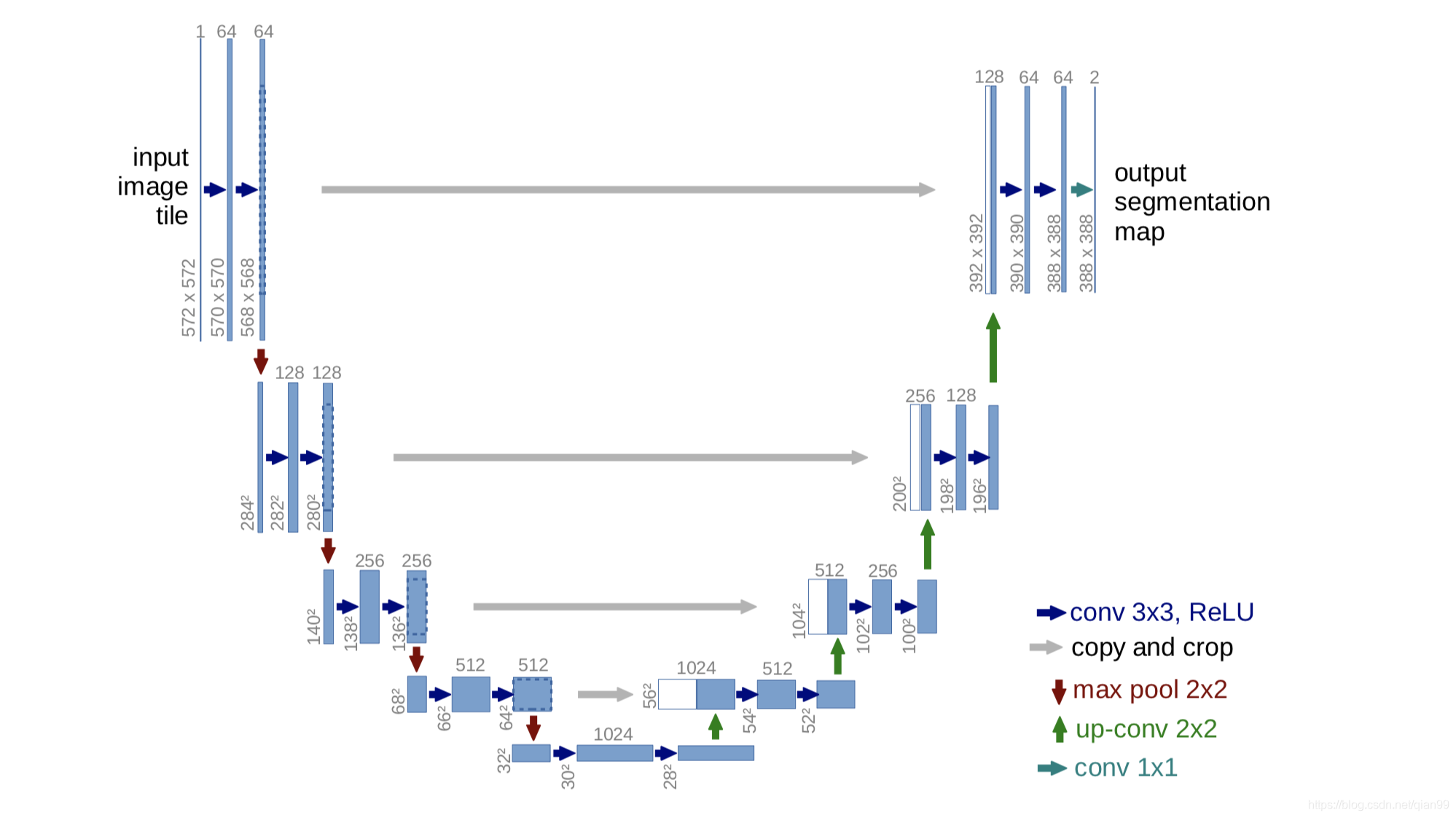
整个 U-Net 网络结构如图,类似于一个大大的 U 字母:首先进行 Conv+Pooling 下采样;然后 Deconv 反卷积进行上采样,crop 之前的低层 feature map,进行融合;然后再次上采样。重复这个过程,直到获得输出 388x388x2 的 feature map,最后经过 softmax 获得 output segment map。总体来说与 FCN 思路非常类似;
判别器网络结构
判别器网络结构采用的是PatchGAN, Patch是小图块的意思; 作者给他起了个名字叫做Markovian discriminator 马尔科夫是一个假设,假设状态与状态之间独立,而PatchGAN的思路也是 Patch与Patch之间独立;
前面的L1 和 L2 Loss都会导致判别器只捕获到了低频的颜色渐变信息而不是高频的边缘信息;而设计判别器的初衷只是为了捕捉高频信息,让l1 loss去捕捉低频信息; 所以PatchGAN将图片划分成了 N ∗ N N*N N∗N个网格,对每个网格做二分类,最后将 N ∗ N N*N N∗N的结果加起来求平均,得到最终的判别结果;


训练过程
生成器G的训练技巧
与GAN一样,对G和D采取了交替训练的技巧
对于生成器 G G G,最小化 log ( 1 − D ( x , G ( x , z ) ) ) \log(1-D(x,G(x,z))) log(1−D(x,G(x,z))),在刚开始的时候 G G G生成的图片非常假,判别器很容易判别出来,对应函数 log ( 1 − D ( x , G ( x , z ) ) ) \log(1-D(x,G(x,z))) log(1−D(x,G(x,z)))很接近0,导致梯度很小,基本调不动;所以在训练的时候最大化 D ( x , G ( x , z ) ) D(x,G(x,z)) D(x,G(x,z))
将dropout用在预测
过往的dropout都是只用在训练而不用在预测,pix2pix为了给生成的图像增加随机性,在测试过程中也使用的dropout;
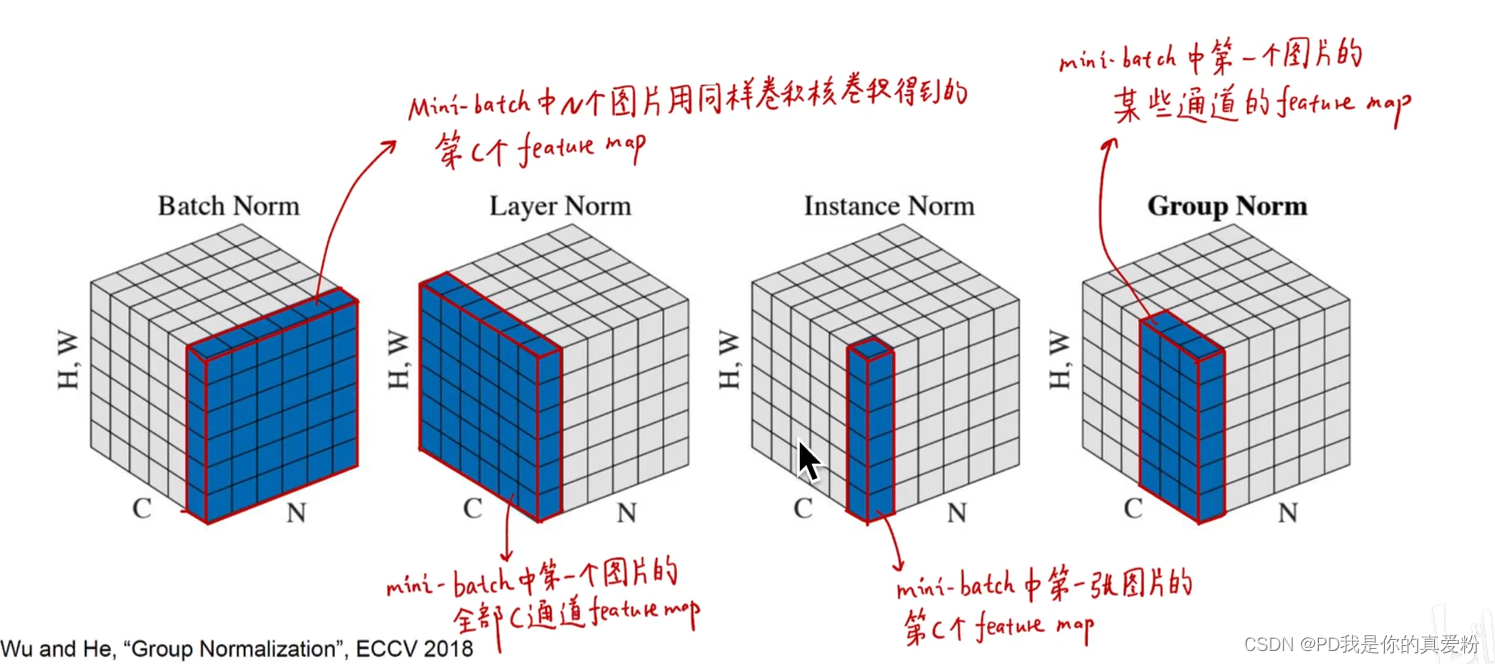
除此之外,在BN层的时候, 过往的都是通过train data来训练BN,而pix2pix在test的时候的BN则是采用输入图像来做; (贴一个BN的复习图)
评估指标
评估方法与CycleGAN基本一样,要么AMT众包平台,要么给语言分割模型,将生成的图输入给语言分割,结果是否与真正表达的语义信息相等;
艺术欣赏
剩下就是欣赏pix2pix的神奇了…