本篇学习日志是基于有python基础的复习回顾【 编辑器:Visual Studio Code (VS Code) 】,主要侧重于一些快捷键与文件方面的备忘记录,而且由于编辑器存在差异,可能内容有些许纰漏。
目录
1. 字符串
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号 [] 来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]
注意:索引值以 0 为开始值,-1 为从末尾的开始位置。
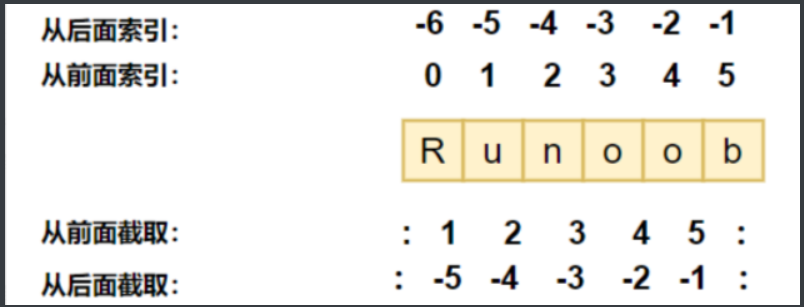
1.1. 字符串切片
取指定字符
>>> print("Hello"[0]) #表示输出字符串中第一个字符H
>>> print("Hello"[-1]) #表示输出字符串中最后一个字符o
字符串分割
>>> print("Hello"[1:3]) #[截取下标为1的字符:截取到下标为3的字符] 左闭右开...
el
特殊情况
>>> print("Hello"[:3]) #从第一个字符开始截取
Hel
>>> print("Hello"[0:]) #从第一个字符开始截取,一直截取到最后
Hello
>>> print("Hello"[:]) #同上
Hello
步长截取
>>> print("Hello"[::2]) #从第一个字符开始截取,间隔2个字符取一个。
Hlo
>>> print("Hello"[::-2]) #从第一个字符开始截取,间隔2个字符取一个。
olH
1.2. 字符串处理方法
1.#title() 获取字符串的内容-》开头大写
>>> name = "hello"
>>> print(name.title())
Hello
##################分界线###################
2.#str(number) 强转至字符串类型
print(str(11) + '岁')
print(11 + '岁') # 报错
aa = "12"
print(int(aa)+11)
##################分界线###################
3.#upper()、lower() 获取字符串的大小写输出
>>> name = "warsec"
>>> print(name.upper())
WARSEC
>>> print(name.lower())
warsec
##################分界线###################
4.#rstrip() 、lstrip()、strip() 分别是删除尾部空格、首部空格以及首尾部空格
name = ' war sec NB '
print(name.lstrip()) #删除首部的空格
print(name.rstrip()) #删除末尾的空格
print(name.strip()) #删除首部及末尾的空格
##################分界线###################
5.#split方法将字符串格根据某个分隔符进行分割,分割之后得到一个列表
>>> "www.baidu.com".split('.')
['www', 'baidu', 'com']
##################分界线###################
6.#in判断某个字符是否存在另外一个字符串内,如果包含就返回True,否则就返回False
a='hello'
b='world'
if ('l' in a):
print('l 在a 内')
else:
print('l 不在 a 内')
##################分界线###################
7.#center方法使指定的字符串居中显示,而侧在加上指定数量的字符
print("Welcome".center(40,"#"))
8.len()可以统计对象中的字符个数
print(len("name"))2. 列表 []
2.1. 修改列表元素(增删改)
name = ['lao', 'war', 'sec']
name[-1] = 'wuhu' # 修改
print(name)
name.append('gg') # 在末尾追加元素
print(name)
name.insert(-1, 'gg') # 插入元素
print(name)
del name[-1] # 根据下标删除元素
print(name)
name.pop() # 删除最后一位元素
print(name)
name.pop(0) # 删除索引为0的元素
print(name)
name.remove('wuhu') # 根据值删除元素,如果存在多个重复的值,只删除第一次出现的
print(name)2.2. 组织列表排序
sort() 不可还原性排序与sort()
name = ['lan', 'lu', 'yu']
name.sort() # 对字符串元素按字母表顺序排序,永久性改变name中元素顺序
print(name)
name = ['lan', 'lu', 'yu']
name.sort(reverse=True) # 逆序 与name.reverse()效果一致
print(name)
name = ['lu', 'lan', 'yu']
print(sorted(name)) # 只返回排序结果,不改变name列表中元素顺序
print(name)
#其中 name.sort(reverse=True) 逆序 与name.reverse()效果一致;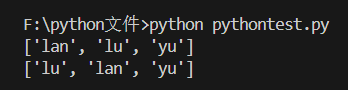
2.3. 列表中的数学
names = ['test1', 'test2', 'test3']
for index in range(0,3): # 包头不包尾
print(names[index])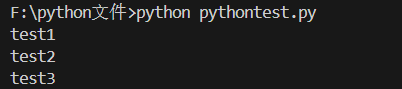
names = ['test1', 'test2', 'test3']
for index in range(0,3,2): # 函数range()第三个参数可设置步长且步长为2
print(names[index])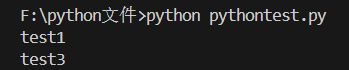
numList = [2, 3, 1, 10, 4]
min(numList) #求数字列表的最小
max(numList) #求数字列表的最大
sum(numList) #求数字列表的和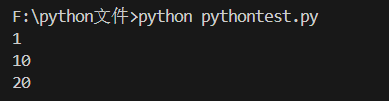
3. 元组 ()
简而言曰,元组用()包含,与列表相似,但是里面的数据无法修改;但其变量的引用可以重新赋值

4. 字典 {}
test = { 'name': 'Kucei', 'age':18}
左侧的是键key,右侧的是值value,采用逗号分隔;
其中键为字符串形式;值可以为数字、字符串、列表甚至是字典;
4.1. 字典的遍历
test = { 'name': 'Kucei', 'age':18}
for key, value in test.items(): # 利用items函数遍历键-值对
print('\nkey = ' + key)
print('\nvalue = ' + value)
for key in test.keys(): # 利用keys函数遍历键
print('\nkey = ' + key)
for value in test.values(): # 利用items函数遍历值
print('\nvalue = ' + value)5. 集合 set()
集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合;
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
变量名 = {value01,value02,...}
或者
set(value)
5.1. 去重功能


5.2. 快速判断元素否存在于集合内
test1={'a','b','c','d','a','e'}
print('a' in test1)
print('A' in test1)
5.3. 集合的基本操作
# 添加元素:xxxxx.add( x )
test = set(("腾讯", "网易 ", "京东"))
test.add("阿里巴巴")
print(test)
# 输出 {'京东', '网易 ', '阿里巴巴', '腾讯'}
##################分界线###################
# 更新元素:xxxxx.update( x )
# 可以添加元素,且参数可以是列表,元组,字典等
test = set(("腾讯", "网易 ", "京东"))
test.update({1,3})
print(test)
# 输出 {1, '网易 ', 3, '京东', '腾讯'}
test.update([1,4],[5,6])
print(test)
# 输出 {1, '网易 ', '京东', 3, 4, 5, 6, '腾讯'}
##################分界线###################
# 移除元素:xxx.remove( x )
# 将元素 x 从集合 xxx 中移除,如果元素不存在,则会发生错误。
test = set(("腾讯", "网易 ", "京东"))
test.remove("京东")
print(test)
# 输出 {'腾讯', '网易 '}
# 移除元素 xxx.discard( x )
# 移除集合中的元素,且如果元素不存在,不会发生错误。
test.discard("京东") # 不存在不会发生错误
# 输出 {'腾讯', '网易 '}
随机删除集合中的元素:xxx.pop()
test = set(("腾讯", "网易 ", "京东"))
x = test.pop()
print(x)
# 输出 京东
##################分界线###################
# 清空集合:xxx.clear()
test = set(("腾讯", "网易 ", "京东"))
test.clear()
print(test)
set()
##################分界线###################
# 判断元素是否在集合中存在:x in s
# 判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
test = set((test = set(("腾讯", "网易 ", "京东"))
x = test.pop()
print(x)))
print("腾讯" in test)
# 输出 True
print("阿里巴巴" in test)
# 输出 False