第一题
create database yhdb01;
show tables ;
create table sql2_1(
uid int,
subject_id int,
score int
)
row format delimited
fields terminated by "\t";
load data local inpath '/home/homedata/sql2/sql2_1.txt' into table sql2_1;
select * from sql2_1;
1001 01 90
1001 02 90
1001 03 90
1002 01 85
1002 02 85
1002 03 70
1003 01 70
1003 02 70
1003 03 85题目:找出所有科目成绩都大于某一学科平均成绩的学生
with t1 as (
select subject_id,round(avg(score),1) avgScore from sql2_1 group by subject_id
)
select uid from sql2_1,t1
where t1.subject_id = sql2_1.subject_id
group by uid having min(score) >min(avgScore) ;结果:

第二题
create table sql2_2(
user_id string,
visit_date string,
visit_count int
)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
'input.regex'='(.+?)\\s+(.+?)\\s+(\\d+)',
'output.format.string'='%1$s %2$s %3$s'
);
load data local inpath '/home/homedata/sql2/sql2_2.txt' into table sql2_2;
u01 2017/1/21 5
u02 2017/1/23 6
u03 2017/1/22 8
u04 2017/1/20 3
u01 2017/1/23 6
u01 2017/2/21 8
u02 2017/1/23 6
u01 2017/2/22 4题目:统计每个用户的累计访问次数
with t1 as (
select user_id,
substr(from_unixtime(unix_timestamp(visit_date,"yyyy/MM/dd"),"yyyy-MM-dd"),1,7) visit_date,
visit_count from sql2_2
)select distinct user_id,visit_date,
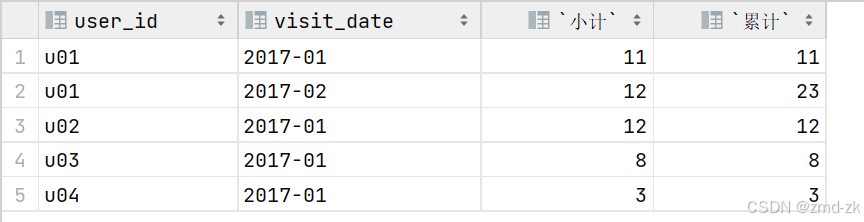
sum(visit_count) over (partition by user_id,visit_date order by visit_date) `小计`,
sum(visit_count) over (partition by user_id order by visit_date) `累计` from t1;结果
第三题
有50W个京东店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志,访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop。
请统计:
1)每个店铺的UV(访客数)
2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
create table sql2_3(
user_id string,
shop string
)
row format delimited
fields terminated by "\t";
truncate table sql2_3;
load data local inpath '/home/homedata/sql2/sql2_3.txt' into table sql2_3;
u1 a
u2 b
u1 b
u1 a
u3 c
u4 b
u1 a
u2 c
u5 b
u4 b
u6 c
u2 c
u1 b
u2 a
u2 a
u3 a
u5 a
u5 a
u5 a1)每个店铺的UV(访客数)
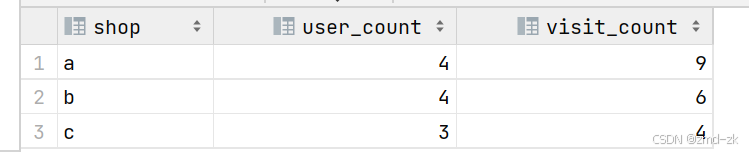
select shop,count(distinct user_id) user_count ,count(*) visit_count from sql2_3 group by shop;结果
2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
with t1 as (
select distinct user_id,shop,count(*) over (partition by shop,user_id) visit_count from sql2_3
),t2 as (
select shop,user_id,visit_count,dense_rank() over (partition by shop order by visit_count desc ) paixu from t1
)
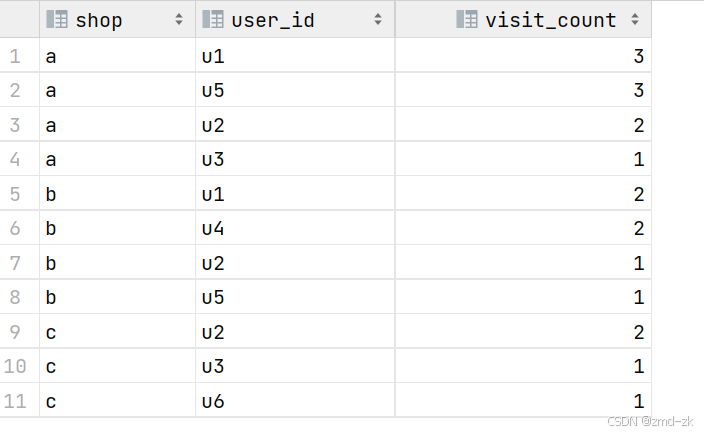
select shop,user_id,visit_count from t2 where paixu<=3;结果:也可以使用别的序列函数,看个人的理解了
第四题
这道题没有数据
已知一个表STG.ORDER,有如下字段:Date,Order_id,User_id,amount。请给出sql进行统计:数据样例:2017-01-01,10029028,1000003251,33.57。
1)给出 2017年每个月的订单数、用户数、总成交金额。
2)给出2017年11月的新客数(指在11月才有第一笔订单)
create table sql2_4(
dt string,
order_id string,
user_id string,
amount decimal(10,2)
) row format delimited fields terminated by '\t';
// 搞一条示例数据
insert into sql2_4 values('2017-01-01','10029028','1000003251',33.57);1)给出 2017年每个月的订单数、用户数、总成交金额。
select substr(dt,0,7) dt,
count(*) order_count,
count(distinct user_id) user_count,
sum(amount) total_money
from sql2_4 where substr(dt,0,4) = "2017" group by substr(dt,0,7);2)给出2017年11月的新客数(指在11月才有第一笔订单)
with t1 as (
select distinct user_id from sql2_4 where substr(dt,0,7) < "2017-11"
),t2 as (
select distinct user_id from sql2_4 where substr(dt,0,7) = "2017-11"
)select * from t2 where not exists (select * from t1 where t1.user_id = t2.user_id);第五题
有日志如下,请写出代码求得所有用户和活跃用户的总数及平均年龄。(活跃用户指连续两天都有访问记录的用户)
create table sql2_5(
dt string,
user_id string,
age int
)row format delimited
fields terminated by ',';
load data local inpath '/home/homedata/sql2/sql2_5.txt' into table sql2_5;
2019-02-11,test_1,23
2019-02-11,test_2,19
2019-02-11,test_3,39
2019-02-11,test_1,23
2019-02-11,test_3,39
2019-02-11,test_1,23
2019-02-12,test_2,19
2019-02-13,test_1,23
2019-02-15,test_2,19
2019-02-16,test_2,19所有用户和活跃用户的总数及平均年龄。
我是把这两个指标放在两个表中写了,当然都会使用with 或者 union,再多的指标都能一个SQL写完。
// 所有用户和平均年龄
with t1 as (
select distinct user_id, age from sql2_5
) select count(*) all_count,avg(age) avg_age from t1;
// 活跃用户和平均年龄
with t1 as (
select distinct dt,user_id,age from sql2_5
) ,t2 as (
select *,date_sub(dt,row_number() over (partition by user_id order by dt)) px from t1
) ,t3 as (
select user_id,age from t2 group by user_id,age,px having count(*) >=2
)
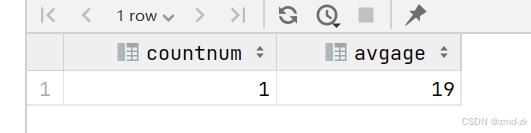
select count(distinct user_id) countNum,avg(age) avgAge from t3;全部

活跃