为了方便下次找到文章,也方便联系我给大家提供帮助,欢迎大家点赞👍、收藏📂和关注🔔!一起讨论技术问题💻,一起学习成长📚!如果你有任何问题或想法,随时留言,我会尽快回复哦😊!
近年来,人工智能(AI)技术,尤其是大模型的快速发展,打开了全新的时代大门。对于想要在这个时代迅速成长并提升自身能力的个人而言,学会利用AI辅助学习已经成为一种趋势。不论是国内的文心一言、豆包,还是国外的ChatGPT、Claude,它们都能成为我们编程学习的有力助手。利用AI进行编程学习将大大提升自己的编程学习效率,这里给大家推荐一个我自己在用的集成ChatGPT和Claude的网站(国内可用,站点稳定):传送门
一、数据存储方式
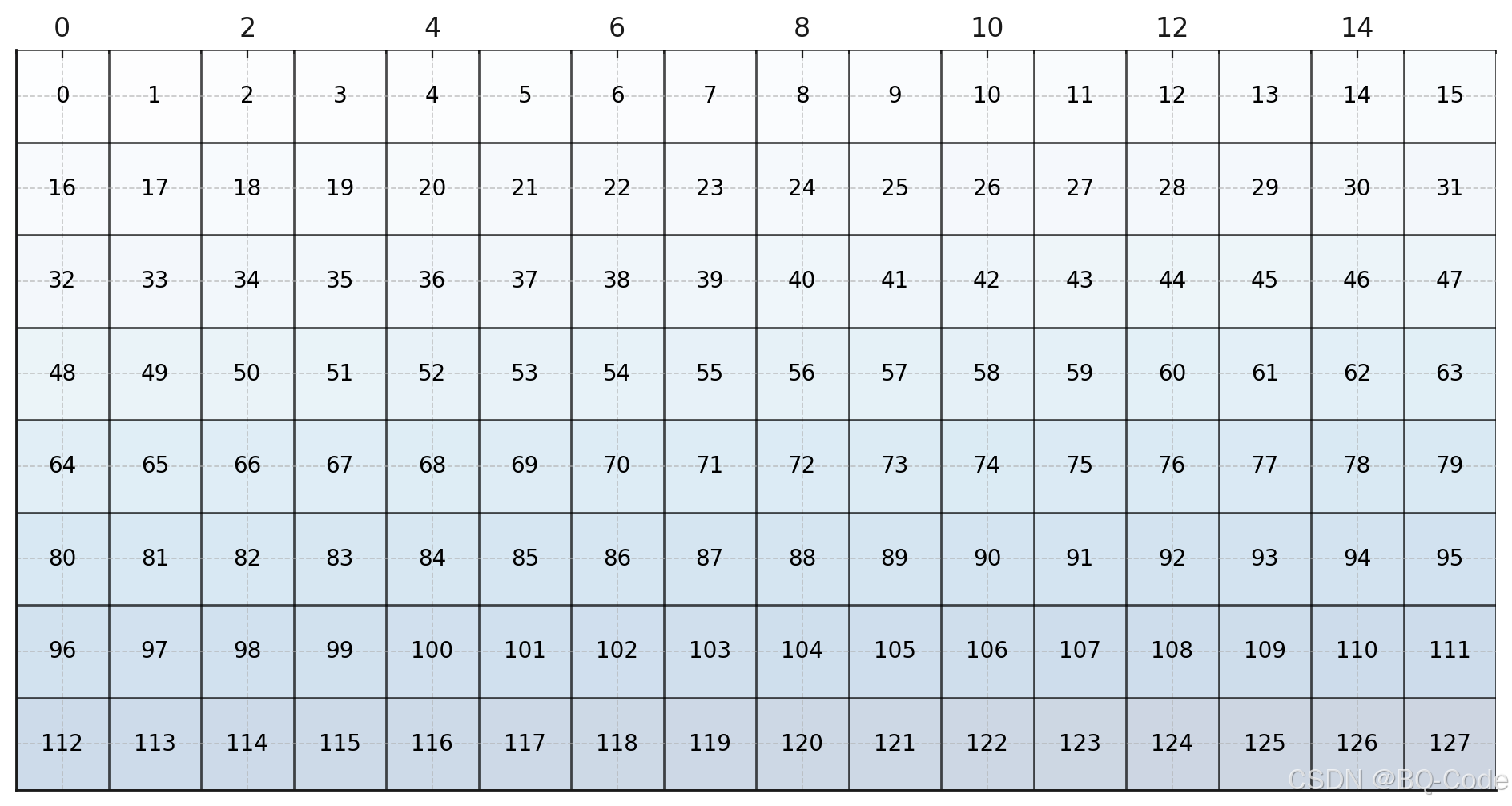
- 数据在内存中是以线性、以行为主的方式存储
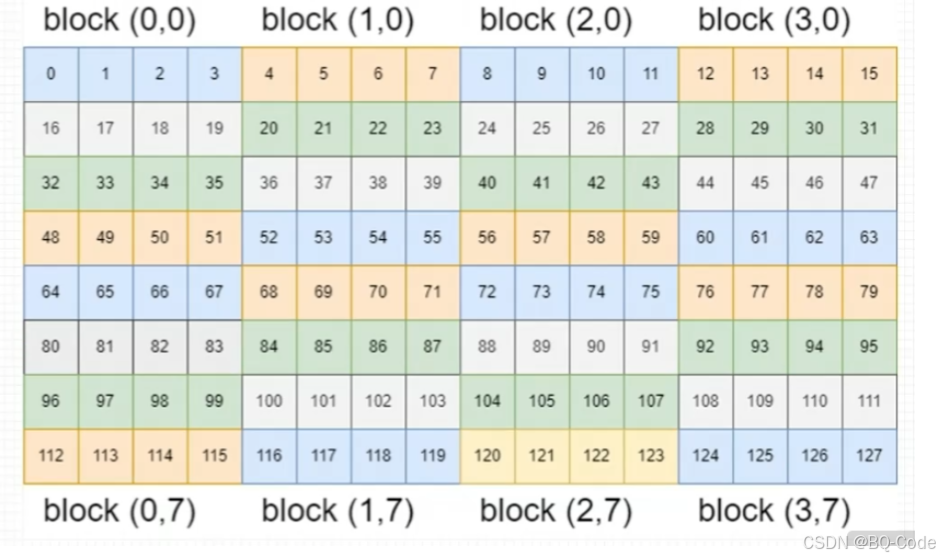
- 本篇文章中,16x8的二维数组,在内存中一段连续的128个地址存储该数组
代码结构
先放上头文件及main文件
common.cuh
#ifndef COMMON_CUH
#define COMMON_CUH
#include "cuda_runtime.h"
#include <stdio.h>
// 声明外部函数,它们将在其他文件中实现。
// 这些函数定义了 CUDA 的网格和块结构,分别表示
// 2维网格和2维线程块、2维网格和1维线程块、1维网格和1维线程块。
extern void grid2D_block2D();
extern void grid2D_block1D();
extern void grid1D_block1D();
// ErrorCheck 是一个内联函数,用于检查 CUDA 函数的返回错误码。
// 如果有错误发生,它将打印错误代码、错误名称、错误描述、文件名和行号。
// 此函数的目的是帮助调试 CUDA 错误。
inline cudaError_t ErrorCheck(cudaError_t error_code, const char* filename, int lineNumber) {
if (error_code != cudaSuccess) {
printf("CUDA error:\ncode=%d, name=%s, description=%s\nfile=%s,line=%d\n",
error_code, cudaGetErrorName(error_code), cudaGetErrorString(error_code), filename, lineNumber);
return error_code; // 返回错误码以便调用方了解错误情况。
}
return error_code; // 如果没有错误,返回相同的错误码。
}
// setGPU 是一个内联函数,用于设置 GPU 设备。
// 它首先获取系统中可用的 CUDA 兼容 GPU 数量。
// 如果没有找到可用的 GPU,程序将退出,否则设置设备并显示相应信息。
inline void setGPU() {
int iDeviceCount = 0; // 存储系统中可用 GPU 的数量
// 获取设备数量并检查返回的错误码。
cudaError_t error = ErrorCheck(cudaGetDeviceCount(&iDeviceCount), __FILE__, __LINE__);
// 如果没有 GPU 或发生错误,则终止程序。
if (error != cudaSuccess || iDeviceCount == 0) {
printf("No CUDA compatible GPU found\n");
exit(-1); // 返回非零值,表示错误。
} else {
printf("The count of GPUs is %d.\n", iDeviceCount); // 显示找到的 GPU 数量。
}
// 设置设备 ID 为 0 的 GPU
int iDevice = 0;
error = ErrorCheck(cudaSetDevice(iDevice), __FILE__, __LINE__);
if (error != cudaSuccess) {
printf("cudaSetDevice failed!\n");
exit(-1); // 设置失败时终止程序。
} else {
printf("cudaSetDevice success!\n"); // 成功设置 GPU 后的确认信息。
}
}
#endif // COMMON_CUH
main.cu
#include "cuda_runtime.h"
#include <stdio.h>
#include "./common.cuh" // 包含自定义的通用 CUDA 工具,例如 setGPU 和 ErrorCheck
int main() {
// grid2D_block2D(); // 使用 2维网格和 2维线程块的函数,已注释掉
// grid2D_block1D(); // 使用 2维网格和 1维线程块的函数,已注释掉
grid1D_block1D(); // 使用 1维网格和 1维线程块的函数,执行矩阵加法
return 0; // 返回 0 表示程序执行成功
}
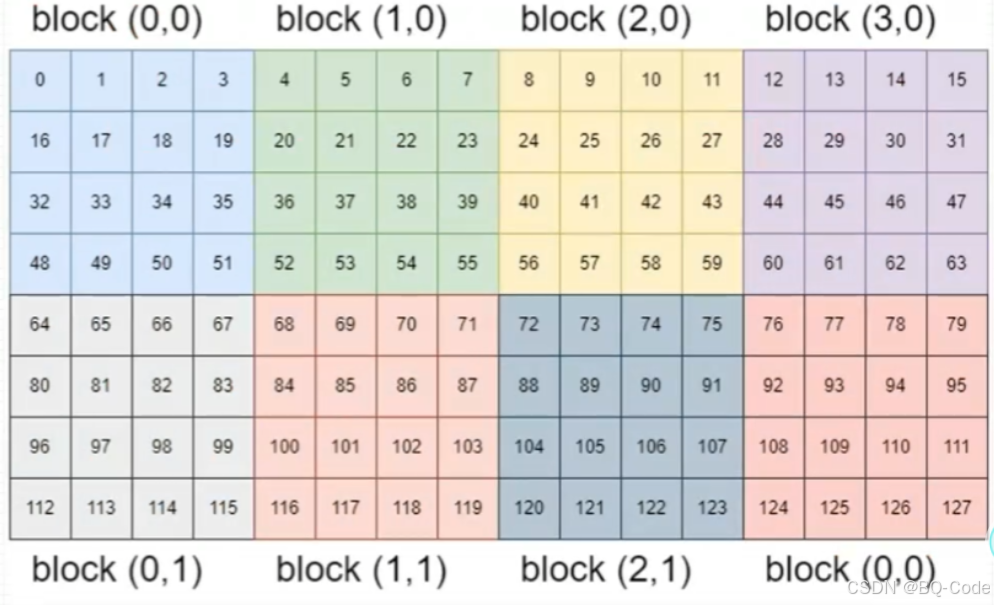
二、二维网格二维线程块
二维网格和二维线程块对二维矩阵进行索引,每个线程可负责一个矩阵元素的计算任务
//
// Created by Administrator on 2024/10/25.
//
#include "common.cuh"
// 定义一个 CUDA 内核函数 addMatrix,用于对两个矩阵进行元素逐一相加。
// A、B 是输入矩阵,C 是输出矩阵,nx 和 ny 分别是矩阵的列数和行数。
__global__ void addMatrix(int *A, int *B, int *C, const int nx, const int ny) {
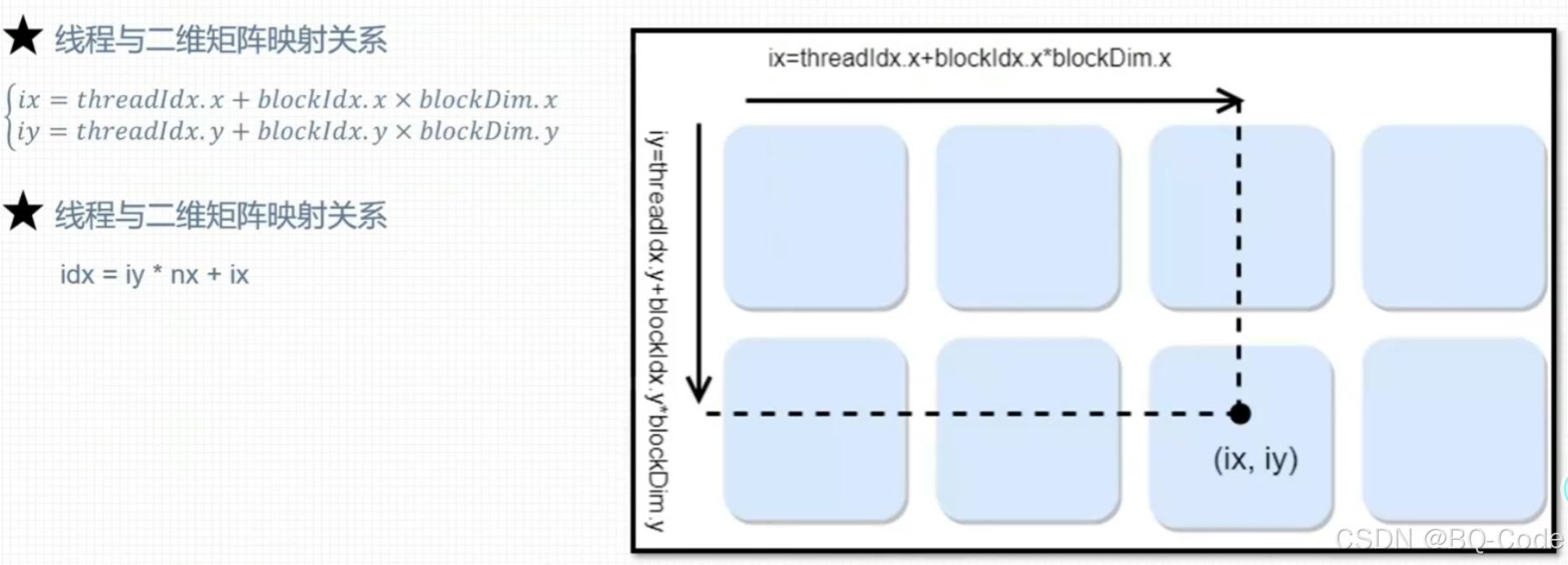
int ix = blockIdx.x * blockDim.x + threadIdx.x; // 确定线程在 x 方向上的索引
int iy = blockIdx.y * blockDim.y + threadIdx.y; // 确定线程在 y 方向上的索引
unsigned int idx = iy * nx + ix; // 计算该线程对应矩阵中的一维索引
// 仅当索引在矩阵范围内时执行加法运算,以避免越界访问
if (ix < nx && iy < ny) {
C[idx] = A[idx] + B[idx];
}
}
// 定义一个函数 grid2D_block2D 来设置并调用 CUDA 内核
// 该函数配置并使用二维网格和二维块结构
void grid2D_block2D(void) {
setGPU(); // 设置 GPU
// 初始化矩阵大小和字节数
int nx = 16; // 列数
int ny = 8; // 行数
int nxy = nx * ny; // 矩阵元素总数
size_t stBytesCount = nxy * sizeof(int); // 矩阵所需的总字节数
// 在主机(CPU)上分配内存
int *ipHost_A, *ipHost_B, *ipHost_C;
ipHost_A = (int *)malloc(stBytesCount); // 矩阵 A
ipHost_B = (int *)malloc(stBytesCount); // 矩阵 B
ipHost_C = (int *)malloc(stBytesCount); // 矩阵 C
// 初始化 A 和 B 的值,C 初始化为零
if (ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL) {
for (int i = 0; i < nxy; i++) {
ipHost_A[i] = i; // 矩阵 A 的元素值设为 i
ipHost_B[i] = i + 1; // 矩阵 B 的元素值设为 i+1
}
memset(ipHost_C, 0, stBytesCount); // 矩阵 C 的元素初始化为 0
}
else {
printf("fail to malloc memory.\n");
exit(-1); // 如果内存分配失败,退出程序
}
// 在设备(GPU)上分配内存
int *ipDevice_A, *ipDevice_B, *ipDevice_C;
ErrorCheck(cudaMalloc((int **)&ipDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int **)&ipDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int **)&ipDevice_C, stBytesCount), __FILE__, __LINE__);
if (ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL) {
// 将 A 和 B 从主机复制到设备
ErrorCheck(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_C, ipHost_C, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
}
else {
printf("fail to malloc memory.\n");
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
exit(-1); // 如果设备内存分配失败,退出程序
}
// 设置线程块和网格维度
dim3 block(4, 4); // 定义每个块的尺寸(4x4 线程块)
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y); // 定义网格尺寸
printf("Thread config : grid (%d, %d) block (%d, %d)\n", grid.x, grid.y, block.x, block.y);
// 启动 CUDA 内核
addMatrix<<<grid, block>>>(ipDevice_A, ipDevice_B, ipDevice_C, nx, ny);
ErrorCheck(cudaDeviceSynchronize(), __FILE__, __LINE__);
// 将结果从设备复制回主机
ErrorCheck(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
// 输出前 10 个元素的加法结果,验证计算是否正确
for (int i = 0; i < 10; i++) {
printf("idx=%2d\tmatrix_A:%d\tmatrix_B:%d\tresult=%d\n", i + 1, ipHost_A[i], ipHost_B[i], ipHost_C[i]);
}
// 释放主机和设备上的内存
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
ErrorCheck(cudaFree(ipDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return;
}
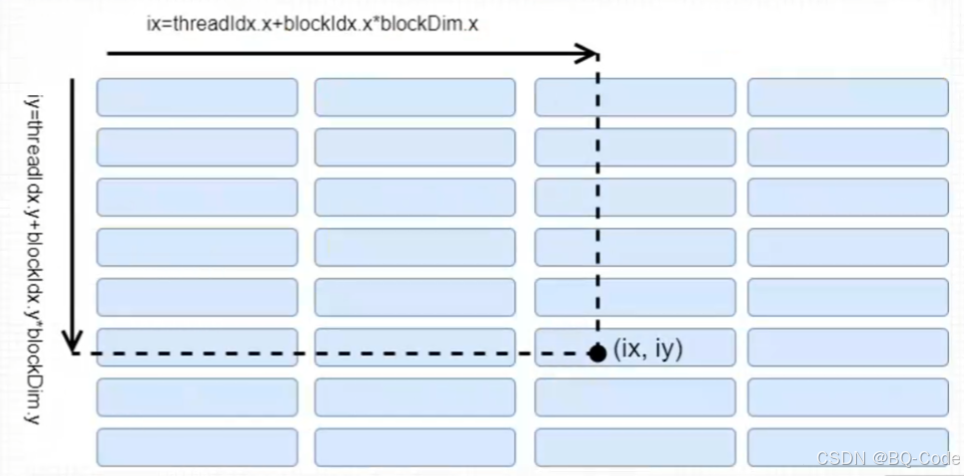
三、二维网格一维线程块
二维网格和一维线程块对二维矩阵进行索引
每个线程可负责一个矩阵元素的计算任务
与二维网格二维线程块的情况极为相似

//
// Created by Administrator on 2024/10/25.
//
#include "common.cuh"
// 定义一个 CUDA 内核函数 addMatrix_21D,用于执行矩阵相加操作。
// 与标准的 2维线程块不同,此内核使用 2维网格和 1维线程块配置。
// A、B 是输入矩阵,C 是输出矩阵,nx 和 ny 分别是矩阵的列数和行数。
__global__ void addMatrix_21D(int *A, int *B, int *C, const int nx, const int ny)
{
int ix = blockIdx.x * blockDim.x + threadIdx.x; // 计算线程在 x 方向上的索引
int iy = threadIdx.y; // 线程在 y 方向上的索引
unsigned int idx = iy * nx + ix; // 将二维索引转换为一维索引
// 仅在索引位于矩阵范围内时执行加法操作,避免越界访问
if (ix < nx && iy < ny)
{
C[idx] = A[idx] + B[idx];
}
}
// 定义一个函数 grid2D_block1D 来配置并调用 CUDA 内核。
// 该函数使用二维网格和一维块的配置。
void grid2D_block1D(void)
{
setGPU(); // 设置 GPU 设备
// 设置矩阵的尺寸
int nx = 16; // 矩阵列数
int ny = 8; // 矩阵行数
int nxy = nx * ny; // 矩阵总元素数
size_t stBytesCount = nxy * sizeof(int); // 矩阵所需的总字节数
// 在主机(CPU)上分配内存
int *ipHost_A, *ipHost_B, *ipHost_C;
ipHost_A = (int *)malloc(stBytesCount); // 分配矩阵 A 的内存
ipHost_B = (int *)malloc(stBytesCount); // 分配矩阵 B 的内存
ipHost_C = (int *)malloc(stBytesCount); // 分配结果矩阵 C 的内存
// 初始化矩阵 A 和 B 的数据
if(ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL){
for(int i = 0; i < nxy; i++){
ipHost_A[i] = i; // A 的每个元素为 i
ipHost_B[i] = i + 1; // B 的每个元素为 i+1
}
} else {
printf("fail to malloc memory.\n");
exit(-1); // 如果内存分配失败,退出程序
}
// 在设备(GPU)上分配内存
int *ipDevice_A, *ipDevice_B, *ipDevice_C;
ErrorCheck(cudaMalloc((int **)&ipDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int **)&ipDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int **)&ipDevice_C, stBytesCount), __FILE__, __LINE__);
if(ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL){
// 将主机内存复制到设备
ErrorCheck(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_C, ipHost_C, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
} else {
// 如果分配失败,释放内存并退出程序
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
exit(-1);
}
// 定义线程块和网格的尺寸
dim3 block(4); // 每个块有 4 个线程
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y); // 配置网格尺寸
printf("Thread config: grid (%d, %d), block(%d, %d).\n", grid.x, grid.y, block.x, block.y);
// 启动 CUDA 内核
addMatrix_21D<<<grid, block>>>(ipDevice_A, ipDevice_B, ipDevice_C, nx , ny);
ErrorCheck(cudaDeviceSynchronize(), __FILE__, __LINE__);
// 将结果从设备复制回主机
ErrorCheck(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
// 输出前 10 个元素的加法结果,进行验证
for(int i = 0; i < 10; i++){
printf("idx=%2d\tmatrix_A:%d\tmatrix_B:%d\tresult=%d\n", i + 1, ipHost_A[i], ipHost_B[i], ipHost_C[i]);
}
// 释放主机和设备上的内存
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
ErrorCheck(cudaFree(ipDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return;
}
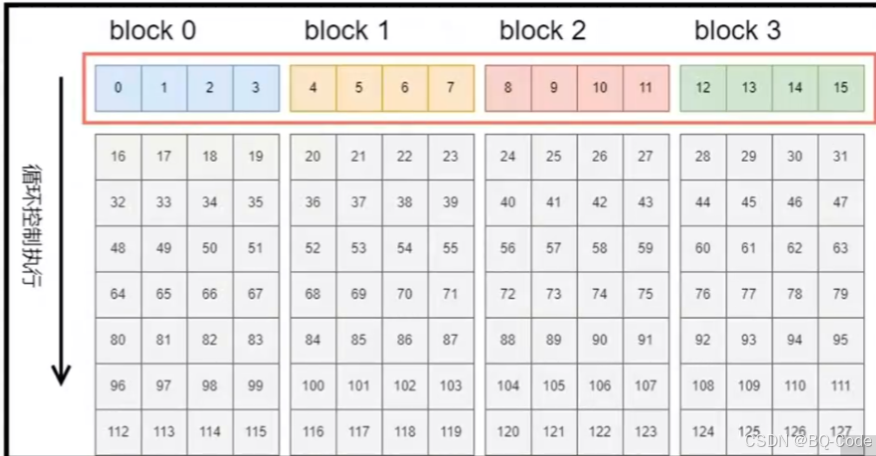
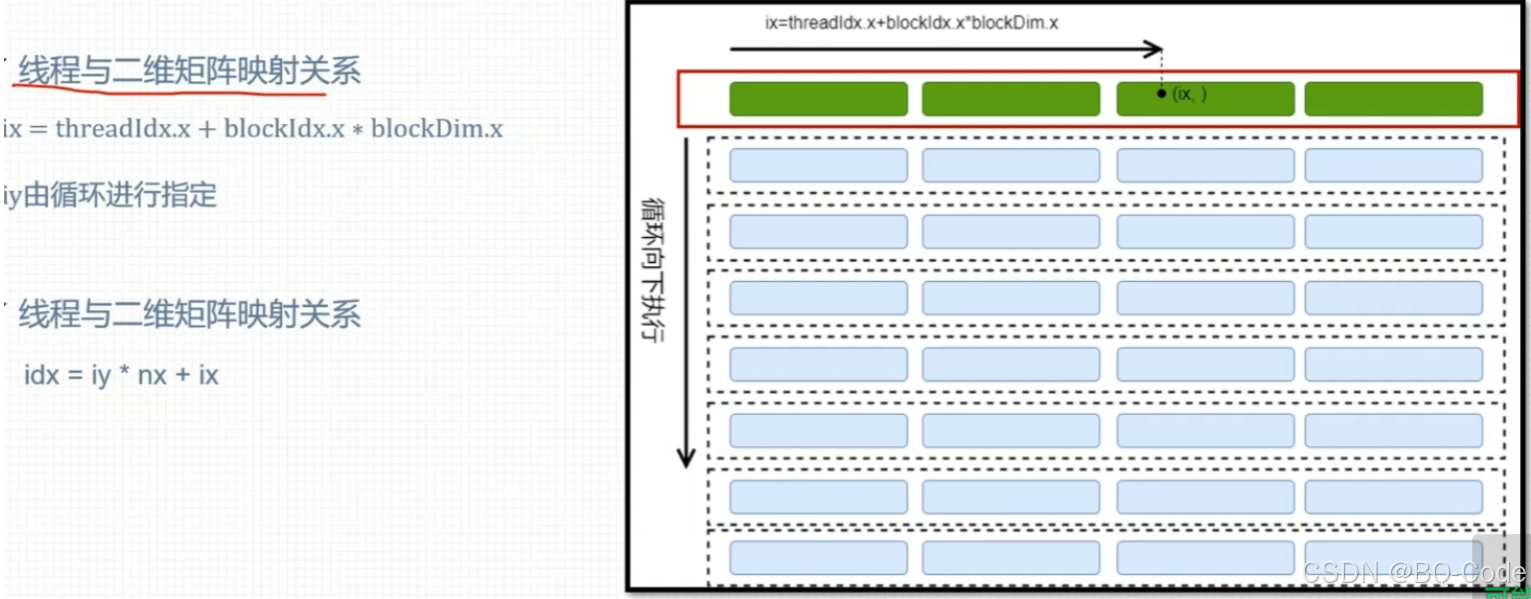
四、一维网格一维线程块
一维网格和一维线程块对二维矩阵进行索引
每个线程负责矩阵一列的运算
编写核函数时,需要使用循环
//
// Created by Administrator on 2024/10/28.
//
#include "common.cuh"
// 定义一个 CUDA 内核函数 addMatrix_11D,使用 1D 网格和 1D 块来执行矩阵相加。
// A、B 是输入矩阵,C 是输出矩阵,nx 和 ny 分别是矩阵的列数和行数。
__global__ void addMatrix_11D(int *A, int *B, int *C, const int nx, const int ny)
{
int ix = blockIdx.x * blockDim.x + threadIdx.x; // 计算线程在 x 方向的索引
// 确保索引在矩阵范围内
if (ix < nx)
{
// 在 y 方向上循环遍历
for (int iy = 0; iy < ny; iy++)
{
unsigned int idx = iy * nx + ix; // 将二维索引转换为一维索引
C[idx] = A[idx] + B[idx]; // 将 A 和 B 对应位置相加并存储在 C 中
}
}
}
// 定义一个函数 grid1D_block1D 来配置并调用 CUDA 内核,使用 1D 网格和 1D 块
void grid1D_block1D(void)
{
printf("grid1D_block1D\n");
setGPU(); // 设置 GPU 设备
// 定义矩阵的尺寸
int nx = 16; // 矩阵的列数
int ny = 8; // 矩阵的行数
int nxy = nx * ny; // 矩阵的总元素数
size_t stBytesCount = nxy * sizeof(int); // 矩阵所需的总字节数
// 在主机(CPU)上分配内存
int *ipHost_A, *ipHost_B, *ipHost_C;
ipHost_A = (int *)malloc(stBytesCount); // 分配矩阵 A 的内存
ipHost_B = (int *)malloc(stBytesCount); // 分配矩阵 B 的内存
ipHost_C = (int *)malloc(stBytesCount); // 分配结果矩阵 C 的内存
// 初始化矩阵 A 和 B 的数据
if(ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL){
for(int i = 0; i < nxy; i++){
ipHost_A[i] = i; // 矩阵 A 的元素设为 i
ipHost_B[i] = i + 1; // 矩阵 B 的元素设为 i+1
}
} else {
printf("fail to malloc memory.\n");
exit(-1); // 如果分配失败,退出程序
}
// 在设备(GPU)上分配内存
int *ipDevice_A, *ipDevice_B, *ipDevice_C;
ErrorCheck(cudaMalloc((int **)&ipDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int **)&ipDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int **)&ipDevice_C, stBytesCount), __FILE__, __LINE__);
if(ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL){
// 将主机内存复制到设备
ErrorCheck(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
} else {
// 如果分配失败,释放内存并退出程序
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
exit(-1);
}
// 设置线程块和网格的尺寸
dim3 block(4); // 每个块包含 4 个线程
dim3 grid((nx + block.x - 1) / block.x); // 设置 1D 网格的维度
printf("Thread config: grid (%d, %d), block(%d, %d).\n", grid.x, grid.y, block.x, block.y);
// 启动 CUDA 内核
addMatrix_11D<<<grid, block>>>(ipDevice_A, ipDevice_B, ipDevice_C, nx , ny);
ErrorCheck(cudaDeviceSynchronize(), __FILE__, __LINE__);
// 将结果从设备复制回主机
ErrorCheck(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
// 输出前 10 个元素的加法结果,验证计算正确性
for(int i = 0; i < 10; i++){
printf("idx=%2d\tmatrix_A:%d\tmatrix_B:%d\tresult=%d\n", i + 1, ipHost_A[i], ipHost_B[i], ipHost_C[i]);
}
// 释放主机和设备上的内存
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
ErrorCheck(cudaFree(ipDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return;
}