(此文章适合有 mysql 基础的朋友阅读!!!在了解 mysql 的基础上,探寻 oracle 与 mysql 的异同)
目录
一、Oracle 基本概念
首先了解几个有关 Oracle 的基本概念:
1. Oracle 数据库
Oracle 数据库是数据的物理存储。这就包括(数据文件 ORA 或者 DBF、控制文件、联机日志、参数文件)。其实 Oracle 数据库的概念和其它数据库不一样,这里的数据库是一个操作系统只有一个库。可以看作是 Oracle 就只有一个大数据库
2. 实例
一个Oracle实例(Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构(Memory Structures)组成。一个数据库可以有 n 个实例。
3. 数据文件(dbf)
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行。
4. 表空间
表空间是 Oracle 对物理数据库上相关数据文件(ORA 或者 DBF 文件)的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构。每个数据库至少有一个表空间(称之为 system 表空间)。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。
5. 用户
用户是在表空间下建立的。用户登陆后只能看到和操作自己的表, ORACLE的用户与 MYSQL 的数据库类似,每建立一个应用需要创建一个用户。
表空间 ----(包含多个)----> 用户 ----(包含多个)---> 表
在使用 Oracle 之前,我们需要做一下三个步骤:
-- 创建表空间
create tablespace 表名称
datafile '存储路径' size 100m
autoextend on next 10m;
-- 创建用户
create user 用户名
identified by 密码
default tablespace 所归属的表空间名称;
-- 给用户赋予DBA权限后,才能使用该用户登录、建表.......
grant dba to 用户名;二、Oracle 数据类型
1. 字符型
(1)CHAR : 固定长度的字符类型,最多存储 2000 个字节
(2)VARCHAR2 :可变长度的字符类型,最多存储 4000 个字节
(3)LONG : 大文本类型。最大可以存储 2 个 G
2. 数值型
NUMBER : 数值类型
例如:NUMBER(5) 最大可以存的数为 99999
NUMBER(5,2) 最大可以存的数为 999.99
3. 日期型
(1)DATE:日期时间型,精确到秒
(2)TIMESTAMP:精确到秒的小数点后 9 位
4. 二进制型(大数据类型)
(1)CLOB : 存储字符,最大可以存 4 个 G
(2)BLOB:存储图像、声音、视频等二进制数据,最多可以存 4 个 G
三、Oracle 数据的导出与导入
当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重构这个完整的数据库该处理称为数据库恢复,而要进行数据库的恢复必须要有数据库的备份工作。
(一)整库导出与导入
导出:
进入 cmd 命令行中,在任意目录下输入以下导出命令即可,执行命令后会在当前目录下生成一个叫 EXPDAT.DMP 的文件,此文件即为备份文件。如果想指定备份文件的名称,则添加 file 参数即可,命令如下 exp [用户名]/[密码] file=[文件名] full=y
-- 整库导出命令
exp 用户名/密码 full=y
-- 添加参数 full=y 就是整库导出
-- 示例:exp system/itcast full=y导入:
此命令如果不指定 file 参数,则默认用备份文件 EXPDAT.DMP 进行导入,如果指定 file 参数,则按照 file 指定的备份文件进行恢复
-- 整库导入命令
imp 登录的用户名/密码 full=y
-- 添加参数 full=y 就是整库导入,登录的用户可以是系统用户system,权限大
-- 示例:imp system/itcast full=y(二)按用户导出与导入
-- 按用户导出
exp 登录的用户名/密码 owner=要导出的用户名 file=[导出的文件名]
-- 示例: exp system/itcast owner=wateruser file=wateruser.dmp-- 按用户导入
imp 登录的用户名/密码 file=[导入的文件名] fromuser=要导入的用户名
-- 示例: imp system/itcast file=wateruser.dmp fromuser=wateruser同样,如果不加 file=[文件名],则默认导出和导入名为 EXPDAT.DMP 的文件。
注意:此导入是从要导入的文件中找到指定用户名的表进行导入,此文件也可以是全库的导出文件,即可以从全库的导出文件中只找到指定的用户进行导入,二者是可以相互使用的。
(三)按表导出与导入
-- 按表导出
exp 要导出的表所在的用户/密码 file=[文件名] tables=表名,[表名],......
-- 用 tables 参数指定需要导出的表,如果有多个表用逗号分割即可
-- 示例: exp wateruser/itcast file=a.dmp tables=t_account,a_area-- 按表导入
imp 要导入表的用户名/密码 file=[文件名] tables=表名,[表名],....
-- 示例: imp wateruser/itcast file=a.dmp tables=t_account,a_area注意:这里的按表导入与上面的按用户导入的注意事项一致,此导入文件既可以是全库的导出文件,也可以是按用户导出的文件。要导入的表也可以是其中的个别表。
四、Oracle 数据查询
1. 基于伪列的查询
在 Oracle 的表的使用过程中,实际表中还有一些附加的列,称为伪列。伪列就像表中的列一样,但是在表中并不存储。伪列只能查询,不能进行增删改操作。 接下来学习两个伪列:ROWID 和 ROWNUM。
① ROWID
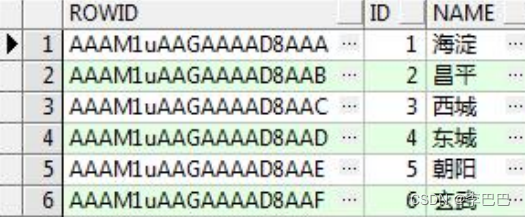
表中的每一行在数据文件中都有一个物理地址,ROWID 伪列返回的就是该行的物理地址。使用 ROWID 可以快速的定位表中的某一行。ROWID 值可以唯一的 标识表中的一行。由于 ROWID 返回的是该行的物理地址,因此使用 ROWID 可 以显示行是如何存储的。 查询语句:
select rowID,别名.* from 表名 别名
-- 示例: select rowID,t.* from T_AREA t
-- 注意:不能直接写select rowID,* from T_AREA (要有别名,或者不使用*)查询结果如下:
我们可以通过指定 ROWID 来查询记录
select rowID,t.* from T_AREA t where ROWID='AAAM1uAAGAAAAD8AAC';查询结果如下:

② ROWNUM
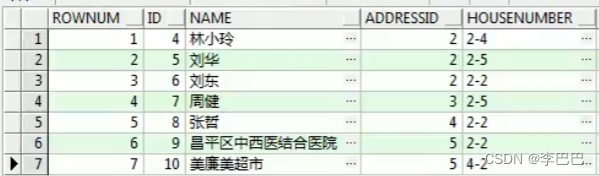
在查询的结果集中,ROWNUM 为结果集中每一行标识一个行号,第一行返回 1, 第二行返回 2,以此类推。通过 ROWNUM 伪列可以限制查询结果集中返回的行数。查询语句:
select rownum,别名.* from 表名 别名
-- 示例: select rownum,t.* from T_OWNERTYPE t where id>3查询结果如下:
2. 外连接
① 左外连接
-- 方法一:SQL1999标准,查询的是左表所有数据以及交集的部分
select 字段列表 from 表名1 left [outer] join 表名2 on 条件;-- 方法二:Oracle定义的标准,在where条件的等号右端加(+)
select
t1.name,
t1.age,
t2.name
from
表1 t1,
表2 t2
where
t1.表1字段 = t2.表2字段(+);② 右外连接
-- 方法一:SQL1999标准,查询的是右表所有数据以及交集的部分
select 字段列表 from 表名1 right [outer] join 表名2 on 条件;-- 方法二:Oracle定义的标准,在where条件的等号左端加(+)
select
t1.name,
t1.age,
t2.name
from
表1 t1,
表2 t2
where
t1.表1字段(+) = t2.表2字段;3. 单行函数
① 字符函数
|
函 数
|
说
明
|
|---|---|
|
ASCII
|
返回对应字符的十进制值
|
|
CHR
|
给出十进制返回字符
|
|
CONCAT
|
拼接两个字符串,与 || 相同
|
|
INITCAT
|
将字符串的第一个字母变为大写
|
|
INSTR
|
找出某个字符串的位置
|
|
LENGTH
|
以字符给出字符串的长度
|
|
LOWER
|
将字符串转换成小写
|
|
LPAD
|
使用指定的字符在字符的左边填充
|
|
LTRIM
|
在左边裁剪掉指定的字符
|
|
RPAD
| 使用指定的字符在字符的右边填充 |
|
RTRIM
|
在右边裁剪掉指定的字符
|
|
REPLACE
|
执行字符串搜索和替换
|
|
SUBSTR
|
取字符串的子串
|
|
TRANSLATE
|
执行字符串搜索和替换
|
|
TRIM
|
裁剪掉前面或后面的字符串
|
|
UPPER
|
将字符串变为大写
|
② 数值函数
|
函数
|
说明
|
|---|---|
|
ABS(value)
|
绝对值
|
|
CEIL(value)
|
大于或等于 value 的最小整数
|
|
FLOOR(value)
|
小于或等于 value 的最大整数
|
|
TRUNC(value,按 precision)
|
按照 precision 截取 value
|
|
ROUND(value,precision)
|
按 precision 精度 4 舍 5 入
|
|
MOD(value,divisor)
|
求模
|
③ 日期函数
| 函数 | 说明 |
|---|---|
|
ADD_MONTHS
|
在日期 date 上增加 count 个月
|
|
LAST_DAY( date )
|
返回日期 date 所在月的最后一天
|
|
TRUNC(date,’format’)
|
未指定 format 时,按日截取(将时间截取掉);指定为‘MM’时,按月截取,结果为本月的第一天;指定为'yyyy'时,按年截取,结果为该年的第一个月;指定为'hh'时,按小时截取,结果为整时;指为'mi'时,按分钟截取,结果为整分钟
|
④ 转换函数
| 函数 | 说明 |
|---|---|
|
TO_CHAR
|
转换数字到字符串
|
| TO_CHAR(date,'format') |
转换日期格式到字符串
|
|
TO_DATE(str,'format')
|
按照指定的格式将字符串转换到日期型
|
|
TO_NUMBER
|
将数字字符串转换到数字
|
⑤ 其他函数
| 函数 | 说明 |
|---|---|
|
NVL(a,b)
| 若a!=null,则返回a;若a==null,则返回b |
| NVL2(a,b,c) | 若a!=null,则返回b;若a==null,则返回c |
|
decode(条件,值 1,翻译值 1,值 2,翻译值 2,...值 n,翻译值 n,缺省值)
| 若条件值==值1,则返回翻译值1;若条件值==值2,则返回翻译值2;.......;若没有与条件值相等的,则返回缺省值。 |
| case 条件值 when 值1 then 翻译值1 when 值2 then 翻译值2 ......... when 值n then 翻译值n else 缺省值 | 与decode作用一致(sql1999标准) |
4. 分析函数
以下面三种排名方式的举例:
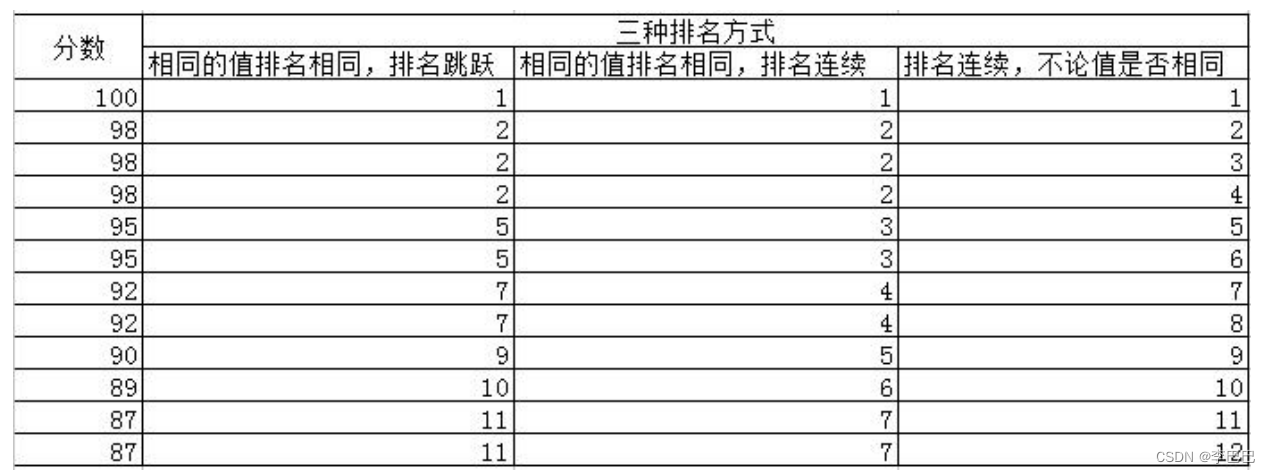
① RANK:相同的值排名相同,排名跳跃
select rank() over(order by 字段 desc ),字段,.... from 表名
-- 示例: select rank() over(order by usenum desc ),usenum from T_ACCOUNT② DENSE_RANK:相同的值排名相同,排名连续
select dence_rank() over(order by 字段 desc ),字段,.... from 表名
-- 示例: select dence_rank() over(order by usenum desc ),usenum from T_ACCOUNT③ ROW_NUMBER:返回连续的排名,无论值是否相等
select row_number() over(order by 字段 desc ),字段,.... from 表名
-- 示例: select row_number() over(order by usenum desc ),usenum from T_ACCOUNT5. 集合运算
集合运算就是将两个或者多个结果集组合成为一个结果集。集合运算包括:
- UNION ALL(并集),返回各个查询的所有记录,包括重复记录。
- UNION(并集),返回各个查询的所有记录,不包括重复记录。
- INTERSECT(交集),返回两个查询共有的记录。
- MINUS(差集),返回第一个查询检索出的记录减去第二个查询检索出的记录之 后剩余的记录。
示例:
-- UNION ALL 并集(不去掉重复记录)
select * from t_owners where id<=7
union
all select * from t_owners where id>=5
-- UNION 并集(去掉重复记录)
select * from t_owners where id<=7
union
select * from t_owners where id>=5
-- intersect 交集
select * from t_owners where id<=7
intersect
select * from t_owners where id>=5
-- minus 差集
select * from t_owners where id<=7
minus
select * from t_owners where id>=5五、Oracle的其他对象
Oracle 与 mysql 共有的几个对象:
下面介绍 Oracle 特有的对象和与 mysql 相比不同的用法:
1. 物化视图
视图是一个虚拟表(也可以认为是一条语句),基于它创建时指定的查询语句返回的结果集。每次访问它都会导致这个查询语句被执行一次。为了避免每次访问都执行这个查询,可以将这个查询果集存储到一个物化视图(也叫实体化视图)。
物化视图与普通的视图相比的区别是物化视图是建立的副本,它类似于一张表,需要占用存储空间。而对一个物化视图查询的执行效率与查询一个表是一样的。
创建物化视图的语法:
CREATE METERIALIZED VIEW view_name
[BUILD IMMEDIATE | BUILD DEFERRED ]
REFRESH [FAST|COMPLETE|FORCE]
[ON [COMMIT |DEMAND ] | START WITH (start_time) NEXT(next_time)]
AS subquery语句中各个参数的含义如下:
- 数据生成的时机
- BUILD IMMEDIATE: 是在创建物化视图的时候就生成数据,(默认)
- BUILD DEFERRED: 则在创建时不生成数据,以后根据需要再生成数据。
- REFRESH(刷新的方式) 指当基表发生了 DML 操作后,物化视图何时采用哪种方式和基表进行同步。
- FAST: 刷新采用增量刷新,只刷新自上次刷新以后进行的修改。
- COMPLETE: 刷新对整个物化视图进行完全的刷新,即先把原来的物化视图删掉,再自动使用创建物化视图语句重新创建物化视图。
- FORCE: Oracle 在刷新时会去判断是否可以进行快速刷新,如果可以则采用 FAST 方式,否则采用 COMPLETE的方式。(默认)
- 刷新的模式有两种:ON DEMAND 和 ON COMMIT。
- ON DEMAND: 指需要手动刷新物化视图(默认)。
- ON COMMIT: 指在基表发生 COMMIT 操作时自动刷新。
使用各个参数需要注意的事项:
① 在采用 FAST 增量刷新前,需要先创建物化日志表,语法如下:
create materialized view log on 基表名称 with 标识;-- 标识:一般为基表的id,是增删改物化视图中数据的依据,在物化视图的字段中必须要有该标识
-- 创建完日志后,会生成一个物化日志表,记录相关信息;当更新完物化视图后,日志表中的数据又会被删除
② 手动刷新物化视图的两种方法:
-- 方法一:执行下列sql语句
begin
DBMS_MVIEW.refresh('物化视图名称','C'); -- 系统内置的存储过程
end;-- 方法二:在SQL命令窗口执行下列语句
EXEC DBMS_MVIEW.refresh('物化视图名称','C');③ 若使用 BUILD DEFERRED 参数(创建物化视图时不生成数据),在第一次生成数据时需要手动刷新物化视图:
begin
DBMS_MVIEW.refresh('物化视图名称','C');
end;2. 序列
在 mysql 中,主键可以使用 auto_increment 实现自增长机制,但在 oracle 中没有此机制,而序列可以满足我们相同的需求。
序列是 ORACLE 提供的用于产生一系列唯一数字的、且独立于表的数据库对象。表示表,序列是序列,序列可以产生一系列唯一数字供表使用。
① 创建简单序列语法:
create sequence 序列名称 通过序列的伪列来访问序列的值
- NEXTVAL 返回序列的下一个值
- CURRVAL 返回序列的当前值
-- 提取下一个值
select 序列名称.nextval from dual
-- 提取当前值
select 序列名称.currval from dual② 创建复杂序列
CREATE SEQUENCE sequence -- 创建序列名称
[INCREMENT BY n] -- 递增的序列值是n, 如果n是正数就递增,如果是负数就递减。(默认是 1)
[START WITH n] -- 开始的值,递增默认是 minvalue ,递减是 maxvalue
[{MAXVALUE n | NOMAXVALUE}] -- 最大值
[{MINVALUE n | NOMINVALUE}] -- 最小值
[{CYCLE | NOCYCLE}] -- 循环/不循环(默认不循环)
[{CACHE n | NOCACHE}];-- 缓存/不缓存,是否分配并存入到内存中,n表示每次缓存n个数到内存(默认CACHE 20)3. 同义词
同义词简称外号,实质上是指定方案对象的一个别名。通过屏蔽对象的名称和所有者以及对分布式数据库的远程对象提供位置透明性,同义词可以提供一定程度的安全性。同时,同义词的易用性较好,降低了数据库用户的 SQL 语句复杂度。
同义词允许基对象重命名或者移动,这时,只需对同义词进行重定义,基于同义词的应用程序可以继续运行而无需修改。
你可以创建公共同义词和私有同义词。其中,公共同义词属于 PUBLIC 特殊用户组,数据库的所有用户都能访问;而私有同义词包含在特定用户的方案中,只允许特定用户或者有基对象访问权限的用户进行访问。
同义词本身不涉及安全,当你赋予一个同义词对象权限时,你实质上是在给同义词的基对象赋予权限,同义词只是基对象的一个别名。
创建同义词:
create [public] SYNONYM 同义词名称 for object;
-- ,object 表示 表、视图、序列等我们要创建同义词的对象的名称4. PL/SQL
① 什么是 PL/SQL?
PL/SQL(Procedure Language/SQL)是 Oracle 对 sql 语言的过程化扩展,指在 SQL 命令语言中增加了过程处理语句(如分支、循环等),使 SQL 语言具有过程处理能力。把 SQL 语言的数据操纵能力与过程语言的数据处理能力结合起来,使得 PLSQL 面向过程但比过程语言简单、高效、灵活和实用。
基本语法结构:
[declare] --声明变量
begin
--代码逻辑
[exception] --异常处理
end;② 变量
声明变量的语法:
变量名 类型(长度);变量赋值的语法:
-- 方法一:直接赋值
变量名:=变量值;
-- 方法二:Select into 方式赋值,结果必须是一条记录 ,有多条记录和没有记录都会报错
select 列名 into 变量名 from 表名 where 条件;补充:
DBMS_OUTPUT.put_line(x); -- 在控制台输出x③ 属性类型
-- 引用型(记录一个字段):
表名.列名%type
-- 记录型(记录一行(多个字段),相当于java中的一个对象实例):
表名%rowtypeeg:
-- 引用型:
declare id t_user.id%TYPE;
-- 记录型:
declare user t_user%rowtype;④ 异常
在运行程序时出现的错误叫做异常发生异常后,语句将停止执行,控制权转移到 PL/SQL 块的异常处理部分
异常有两种类型:
- 预定义异常 - 当 PL/SQL 程序违反 Oracle 规则或超越系统限制时隐式引发
- 用户定义异常 - 用户可以在 PL/SQL 块的声明部分定义异常,自定义的异常通过 RAISE 语句显式引发
Oracle 预定义异常有 21 个:
- ACCESS_INTO_NULL 未定义对象
- CASE_NOT_FOUND CASE 中若未包含相应的 WHEN ,并且没有设置 ELSE 时
- COLLECTION_IS_NULL 集合元素未初始化
- CURSER_ALREADY_OPEN 游标已经打开
- DUP_VAL_ON_INDEX 唯一索引对应的列上有重复的值
- INVALID_CURSOR 在不合法的游标上进行操作
- INVALID_NUMBER 内嵌的 SQL 语句不能将字符转换为数字
- NO_DATA_FOUND 使用 select into 未返回行
- TOO_MANY_ROWS 执行 select into 时,结果集超过一行
- ZERO_DIVIDE 除数为 0
- SUBSCRIPT_BEYOND_COUNT 元素下标超过嵌套表或 VARRAY 的最大值
- SUBSCRIPT_OUTSIDE_LIMIT 使用嵌套表或 VARRAY 时,将下标指定为负数
- VALUE_ERROR 赋值时,变量长度不足以容纳实际数据
- LOGIN_DENIED PL/SQL 应用程序连接到 oracle 数据库时,提供了不正确的用户名或密码
- NOT_LOGGED_ON PL/SQL 应用程序在没有连接 oralce 数据库的情况下访问数据
- PROGRAM_ERROR PL/SQL 内部问题,可能需要重装数据字典& pl./SQL 系统包
- ROWTYPE_MISMATCH 宿主游标变量与 PL/SQL 游标变量的返回类型不兼容
- SELF_IS_NULL 使用对象类型时,在 null 对象上调用对象方法
- STORAGE_ERROR 运行 PL/SQL 时,超出内存空间
- SYS_INVALID_ID 无效的 ROWID 字符串
- TIMEOUT_ON_RESOURCE Oracle 在等待资源时超时
遇到异常时,处理语法如下:
exception
when 异常类型 then
异常处理逻辑⑤ 条件判断
if 条件 then
业务逻辑
elsif 条件 then
业务逻辑
else
业务逻辑
end if;⑥ 循环
(1)无条件循环
loop
-- 循环语句
exit when 退出条件
end loop;(2)有条件循环
while 条件
loop
-- 循环语句
exit when 退出条件
end loop;(3)for 循环
for 变量 in 起始值..终止值
loop
-- 循环语句
end loop;⑦ 游标
声明游标:
-- 不带参数
cursor 游标名称 is SQL语句;
-- 带参数
cursor 游标名称(变量 变量类型) is SQL语句; -- SQL语句中要有带有变量游标使用语法:
-- 不带参数
open 游标名称 -- 打开游标
loop
fetch 游标名称 into 变量 -- 获取当前游标的值
exit when 游标名称%notfound
end loop;
close 游标名称 -- 关闭游标
-- 带参数
open 游标名称(参数) -- 打开游标
loop
fetch 游标名称 into 变量 -- 获取当前游标的值
exit when 游标名称%notfound
end loop;
close 游标名称 -- 关闭游标for 循环简化游标的使用:
-- for循环、不带参数游标
for 变量 in 游标名称
loop
-- 循环语句
end loop;
-- for循环、带参数游标
for 变量 in 游标名称(参数)
loop
-- 循环语句
end loop;5. 存储函数
存储函数又称为自定义函数。可以接收一个或多个参数,返回一个结果。在函数中我们可以使用 P/SQL 进行逻辑的处理。
创建或修改存储函数的语法如下:
CREATE [ OR REPLACE ] FUNCTION 函数名称(参数名称 参数类型, ...)
RETURN 结果变量数据类型
IS
变量声明部分;
BEGIN
逻辑部分;
RETURN 结果变量;
[EXCEPTION 异常处理部分]
END;调用自定义函数:
select 函数名(参数...) from 表名;6. 存储过程
存储过程是被命名的 PL/SQL 块,存储于数据库中,是数据库对象的一种。应用程序可以调用存储过程,执行相应的逻辑。
存储过程与存储函数都可以封装一定的业务逻辑并返回结果,存在区别如下:
- 存储函数中有返回值,且必须返回;而存储过程没有返回值,可以通过传出参数返回多个值。
- 存储函数可以在 select 语句中直接使用,而存储过程不能。过程多数是被应用程序所调用。
- 存储函数一般都是封装一个查询结果,而存储过程一般都封装一段事务代码
创建或修改存储过程的语法如下:
CREATE [ OR REPLACE ] PROCEDURE 存储过程名称(参数名 in/out/inout 类型, ...)
IS|AS
变量声明部分;
BEGIN
逻辑部分
[EXCEPTION 异常处理部分]
END;过程参数的三种模式:
- IN 传入参数(默认)
- OUT 传出参数 ,主要用于返回程序运行结果
- IN OUT 传入传出参数
调用存储过程:
-- 方式一:
call 存储过程名称(参数);
-- 方式二:
declare
[变量] -- 只有参数有输出时才用声明,用来接收输出的参数
begin
存储过程名称(参数,....,[变量])
end;7. 触发器
数据库触发器是一个与表相关联的、存储的 PL/SQL 程序。每当一个特定的数据操作语句(Insert,update,delete)在指定的表上发出时,Oracle 自动地执行触发器中定义的语句序列。
触发器可用于
- 数据确认
- 实施复杂的安全性检查
- 做审计,跟踪表上所做的数据操作等
- 数据的备份和同步
触发器分类
- 前置触发器(BEFORE)
- 后置触发器(AFTER)
创建触发器的语句:
CREATE [or REPLACE] TRIGGER 触发器名
BEFORE | AFTER
[DELETE] [[or] INSERT] [[or]UPDATE [OF 列名]]
ON 表名
[FOR EACH ROW ][WHEN(条件) ]
declare
……
begin
PLSQL 块
End ;FOR EACH ROW 作用是标注此触发器是行级触发器,即每影响一行数据就就会触发一次触发器。与之相对应的是语句级触发器,即每执行一条语句就会触发一次触发器。
在触发器中触发语句与伪记录变量的值:
|
触发语句
|
:old
|
:new
|
|---|---|---|
|
Insert
|
所有字段都是空
(null)
|
将要插入的数据
|
|
Update
|
更新以前该行的值
|
更新后的值
|
|
delete
|
删除以前该行的值
|
所有字段都是空
(null)
|