前言 (后序需要线程 + epoll相关知识点) 读者可按需所读
- 线程相关地各种知识点: 我仅仅写过一篇解决生产者消费者模式地博文,需要地可以读取
 https://blog.csdn.net/weixin_53695360/article/details/123082273?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_53695360/article/details/123082273?spm=1001.2014.3001.5502- 下文中写有epoll 因为 epoll也被称为解决C10k问题地一把好手 (epoll多路复用基础)
- 点进来了就是缘分,这些文章都是小杰地学习总结随笔,如果您感兴趣,或者正好在休息,可以麻烦看完给小杰点评一下,感谢大家地支持,谢谢大家。。。如果决定小杰写的还不错地可以康康小杰地网络部分随笔,感谢。
一.锁
-
锁出现地原因
- 临界资源是什么: 多线程执行流所共享地资源
- 锁地作用是什么, 可以做原子操作, 在多线程中针对临界资源地互斥访问... 保证一个时刻只有一个线程可以持有锁对于临界资源做修改操作...
- 任何一个线程如果需要修改,向临界资源做写入操作都必须持有锁,没有持有锁就不能对于临界资源做写入操作.
- 锁 : 保证同一时刻只能有一个线程对于临界资源做写入操作 (锁地功能)
-
再一个直观地代码引出问题,再从指令集地角度去看问题
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
void* Routine(void* arg) {
int *pcount = (int*)arg;
for (int i = 0; i < 20000000; ++i) {
(*pcount)++;
}
return (void*)0;
}
int main() {
int count = 0;
pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, Routine, (void*)&count);
pthread_create(&tid2, NULL, Routine, (void*)&count);
pthread_create(&tid3, NULL, Routine, (void*)&count);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
//看一看结果
printf("count: %d\n", count);
return 0;
}
- 上述一个及其奇怪的结果,这个结果每一次运行都可能是不一样的,Why ? 按照我们本来的想法是每一个线程 + 20000000 结果肯定应该是60000000呀,可以就是达不到这个值
为何? (深入汇编指令来看) 一定将过程放置到汇编指令上去看就可以理解这个过程了.
a++; 或者 a += 1; 这些操作的汇编操作是几个步骤?
- 其实是三个步骤:
- 将数据从内存读取到寄存器中
- 在寄存器中进行对应的运算
- 将数据运算结果从寄存器写回内存
正常情况下,数据少,操作的线程少,问题倒是不大,想一想要是这样的情况下,操作次数大,对齐操作的线程多,有些线程从中间切入进来了,在运算之后还没写回内存就另外一个线程切入进来同时对于之前的数据进行++ 再写回内存, 啥效果,多次++ 操作之后结果确实一次加加操作后的结果。 这样的操作 (术语叫做函数的重入) 我觉得其实就是重入到了汇编指令中间了,还没将上一次运算的结果写回内存就从新对这个内存读取再运算写入,结果肯定和正常的逻辑后的结果不一样呀
来一幅图篇解释一下

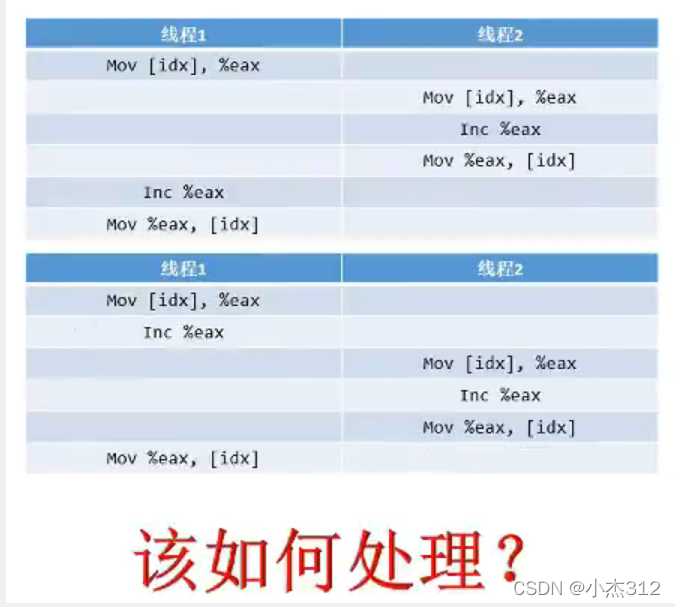
- 咋办? 其实问题很清楚,我们只需要处理的是多条汇编指令不能让它中间被插入其他的线程运算. (要想自己在执行汇编指令的时候别人不插入进来) 将多条汇编指令绑定成为一条指令不就OK了嘛。
- (也就是原子操作,将汇编指令改造成原子操作的方法我是不会的,感兴趣的可以去查阅一下咋办)
- 咱自己是汇编没学到精华不知道咋通过汇编来将多条指令搞成原子操作
- 但是操作系统给咱提供了线程的 绑定方式工具呀:mutex 互斥锁(互斥量), 自旋锁(spinlock), 读写锁(readers-writer lock) 他们也称作悲观锁. 作用都是一个样,将多个汇编指令锁成为一条原子操作 (此处的汇编指令也相当于如下的临界资源)
- 悲观锁:锁如其名,每次都悲观地认为其他线程也会来修改数据,进行写入操作,所以会在取数据前先加锁保护,当其他线程想要访问数据时,被阻塞挂起
- 乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前, 会判断其他数据在更新前有没有对数据进行修改。(个人了解不足,想要了解地可以查阅资料)
-
互斥锁
- 最为常见使用地锁就是互斥锁, 也称互斥量. mutex
- 特征,当其他线程持有互斥锁对临界资源做写入操作地时候,当前线程只能挂起等待,让出CPU,存在线程间切换工作
- 解释一下存在线程间切换工作 : 当线程试图去获取锁对临界资源做写入操作时候,如果锁被别的线程正在持有,该线程会保存上下文直接挂起,让出CPU,等到锁被释放出来再进行线程间切换,从新持有CPU执行写入操作
- 互斥锁需要进行线程间切换,相比自旋锁而言性能会差上许多,因为自旋锁不会让出CPU, 也就不需要进行线程间切换地步骤,具体原理下一点详述

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
pthread_mutex_t mtx;
void* Routine(void* arg) {
int *pcount = (int*)arg;
for (int i = 0; i < 20000000; ++i) {
pthread_mutex_lock(&mtx);
(*pcount)++;
pthread_mutex_unlock(&mtx);
}
return (void*)0;
}
int main() {
pthread_mutex_init(&mtx, NULL);
int count = 0;
pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, Routine, (void*)&count);
pthread_create(&tid2, NULL, Routine, (void*)&count);
pthread_create(&tid3, NULL, Routine, (void*)&count);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
//看一看结果
printf("count: %d\n", count);
pthread_mutex_destroy(&mtx);//销毁锁
return 0;
}加互斥量(互斥锁)确实可以达到要求,但是会发现运行时间非常的长,因为线程间不断地切换也需要时间, 线程间切换的代价比较大.
-
自旋锁
- spinlock.自旋锁.
- 对比互斥量(互斥锁)而言,获取自旋锁不需要进行线程间切换,如果自旋锁正在被别的线程占用,该线程也不会放弃CPU进行挂起休眠,而是恰如其名的在哪里不断地循环地查看自旋锁保持者(持有者)是否将自旋锁资源释放出来... (自旋地原来就是如此)
- 口语解释自旋:持有自旋锁地线程不释放自旋锁,那也没有关系呀,我就在这里不断地一遍又一遍地查询自旋锁是否释放出来,一旦释放出来我立马就可以直接使用 (因为我并没有挂起等待,不需要像互斥锁还需要进行线程间切换,重新获取CPU,保存恢复上下文等等操作)
- 哪正是因为上述这些特点,线程尝试获取自旋锁,获取不到不会采取休眠挂起地方式,而是原地自旋(一遍又一遍查询自旋锁是否可以获取)效率是远高于互斥锁了. 哪我们是不是所有情况都使用自旋锁就行了呢,互斥锁就可以放弃使用了吗????
- 解释自旋锁地弊端:如果每一个线程都仅仅只是需要短时间获取这个锁,那我自旋占据CPU等待是没啥问题地。要是线程需要长时间地使用占据(锁)。。。 会造成过多地无端占据CPU资源,俗称站着茅坑不拉屎... 但是要是仅仅是短时间地自旋,平衡CPU利用率 + 程序运行效率 (自旋锁确实是在有些时候更加合适)
- 自旋锁需要场景:内核可抢占或者SMP(多处理器)情况下才真正需求 (避免死锁陷入死循环,疯狂地自旋,比如递归获取自旋锁. 你获取了还要获取,但是又没法释放)
- 自旋锁地使用函数其实和互斥锁几乎是一摸一样地,仅仅只是需要将所有的mutex换成spin即可
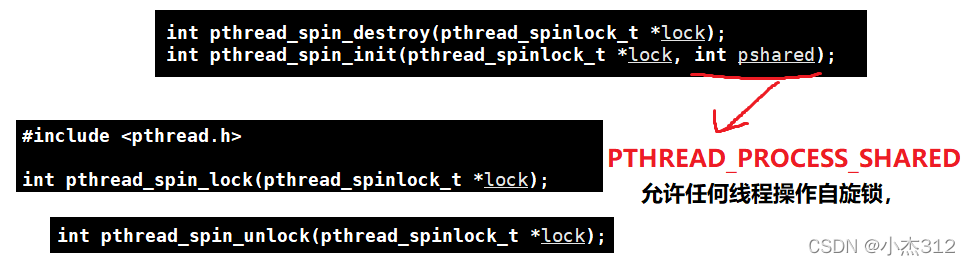
仅仅只是在init存在些许不同
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
pthread_spinlock_t mtx;
void* Routine(void* arg) {
int *pcount = (int*)arg;
for (int i = 0; i < 20000000; ++i) {
pthread_spin_lock(&mtx);
(*pcount)++;
pthread_spin_unlock(&mtx);
}
return (void*)0;
}
int main() {
pthread_spin_init(&mtx, PTHREAD_PROCESS_SHARED);
int count = 0;
pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, Routine, (void*)&count);
pthread_create(&tid2, NULL, Routine, (void*)&count);
pthread_create(&tid3, NULL, Routine, (void*)&count);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
//看一看结果
printf("count: %d\n", count);
pthread_spin_destroy(&mtx);//销毁锁
return 0;
}
- 解决上述地问题地方式二, 不是使用std=c99 而是直接将 int i 放置到for循环外面
-
读写锁 + 读者写者模式:
- 主要是处理读多写少地情况,和本文后序关联不大,需要的可自行查阅了解
二.epoll惊群问题地理解
- 何为惊群,池塘一堆🐟, 我瞄准一条插过去,但是好似所有的🐟都像是觉着自己正在被插一样的四处逃窜。 这个就是惊群的生活一点的理解
- 惊群现象其实一点也不少,比如说 accept pthread_cond_broadcast 还有多个线程共享epoll监视一个listenfd 然后此刻 listenfd 说来 SYN了,放在了SYN队列中,然后完成了三次握手放在了 accept队列中了, 现在问题是这个connect我应该交付给哪一个线程处理呢.
- 多个epoll监视准备工作的线程 就是这群 (🐟),然后connet就是鱼叉,这一叉下去肯定是所有的 epoll线程都会被惊醒 (多线程共享listenfd引发的epoll惊群)
- 同样如果将上述的多个线程换成多个进程共享监视 同一个 listenfd 就是(多进程的epoll惊群现象)
咱再画一个草图再来理解一下这个惊群:
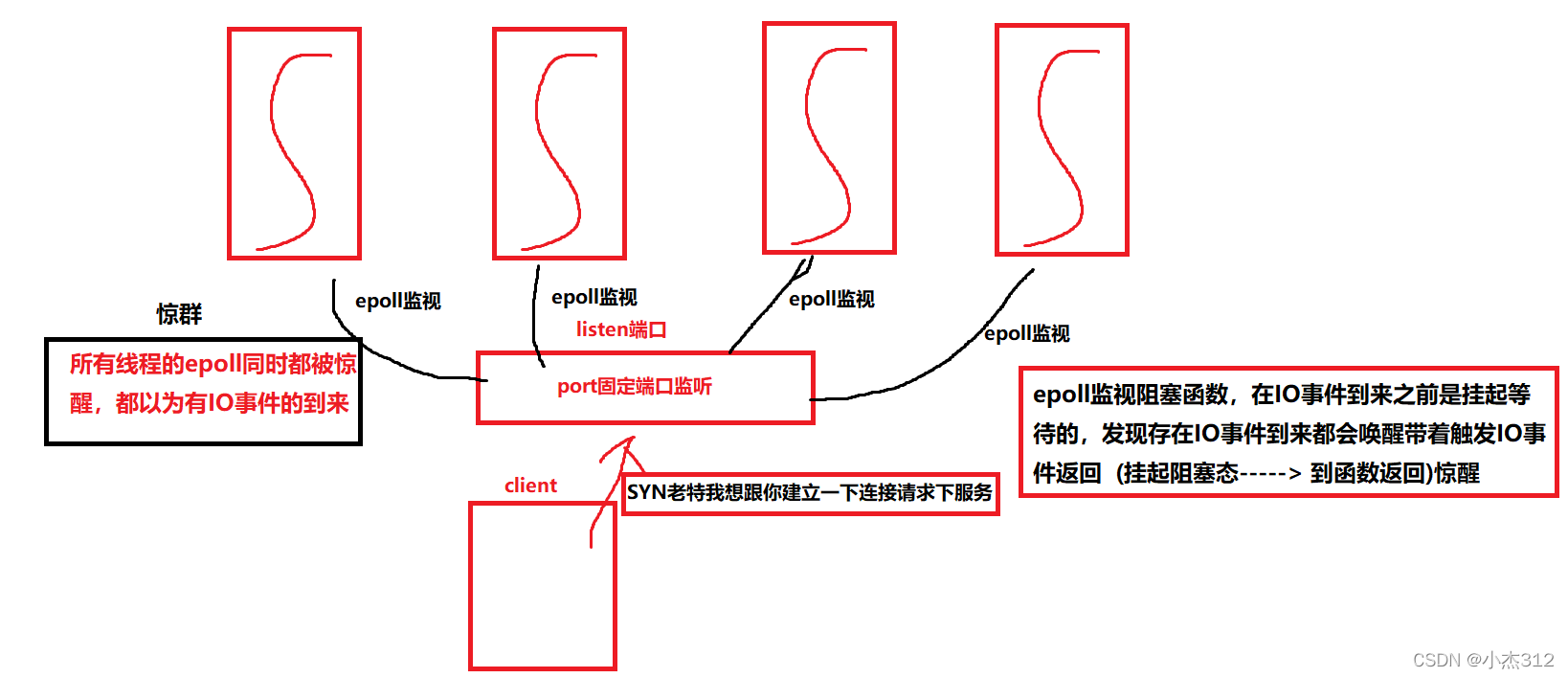
- 如果是多进程道理是一样滴,仅仅只是将所有的线程换成进程就OK了
三. epoll惊群问题地解决
- 终是来到了今天地正题了: epoll惊群问题地解决上面了...
- 首先 先说说accept地惊群问题,没想到吧accept 平时大家写它的多线程地时候,多个线程同时accept同一个listensock地时候也是会存在惊群问题地,但是accept地惊群问题已经被Linux内核处理了: 当有新的连接进入到accept队列的时候,内核唤醒且仅唤醒一个进程来处理
- 但是对于epoll地惊群问题,内核却没有直接进行处理。哪既然内核没有直接帮我们处理,我们应该如何针对这种现象做出一定地措施呢?
- 惊群效应带来地弊端: 惊群现象会造成epoll地伪唤醒,本来epoll是阻塞挂起等待着地,这个时候因为挂起等待是不会占用CPU地。。。 但是一旦唤醒就会占用CPU去处理发生地IO事件, 但是其实是一个伪唤醒,这个就是对于线程或者进程地无效调度。然而进程或者线程地调取是需要花费代价地,需要上下文切换。需要进行进程(线程)间地不断切换... 本来多核CPU是用来支持高并发地,但是现在却被用来无效地唤醒,对于多核CPU简直就是一种浪费 (浪费系统资源) 还会影响系统地性能.
- 解决方式(一般是两种)
Nginx地解决方式:
- 加锁:惊群问题发生的前提是多个进程(线程)监听同一个套接字(listensock)上的事件,所以我们只让一个进程(线程)去处理监听套接字就可以了。
// 是否开启 accept 锁, // 开启则需要抢锁,以防惊群,默认是关闭的。 if (ngx_use_accept_mutex) { if (ngx_accept_disabled > 0) { // ngx_accept_disabled 的值是经过算法计算出来的, // 当值大于 0 时,说明此进程负载过高,不再接收新连接。 ngx_accept_disabled--; } else { // 尝试抢 accept 锁,发生错误直接返回 if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) { return; } if (ngx_accept_mutex_held) { // 抢到锁,设置事件处理标识,后续事件先暂存队列中。 flags |= NGX_POST_EVENTS; } else { // 未抢到锁,修改阻塞等待时间,使得下一次抢锁不会等待太久 if (timer == NGX_TIMER_INFINITE || timer > ngx_accept_mutex_delay) { timer = ngx_accept_mutex_delay; } } } }
- 上述地处理方式说实话:小杰功底不够,其实看不是很懂:贴上大佬地博文一张:
方式2: 是小杰可以理解地方式方法: 使用 设置SO_REUSEPORT:使得端口号可以复用, 如此多个进程或者线程便可以绑定同一个端口号了 这样相当于是每一个进程或线程都监视一个listensock
画两张图来理解一下:

四. 代码演示:
#include <stdio.h>
#include <sys/epoll.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/socket.h>
#include <string.h>
#include <arpa/inet.h>
#include <pthread.h>
#include <sys/types.h>
#include <fcntl.h>
typedef struct sockaddr SA;
#define CLIENTSIZE 1000
#define BUFFSIZE 256
#define SERVE_PORT 8080
#define ERR_EXIT(m)\
do { perror(m); close(EXIT_FAILURE); } while(0)
int CreateSocket() {
int listensock = socket(AF_INET, SOCK_STREAM, 0);
int reuseport = 1;
if (-1 == setsockopt(listensock, SOL_SOCKET, SO_REUSEPORT, &reuseport, sizeof(reuseport))) {
ERR_EXIT("setsocketopt");
}
struct sockaddr_in serveAdd;
//确定服务端协议地址簇
memset(&serveAdd, 0, sizeof(serveAdd));//清空
serveAdd.sin_family = AF_INET;
serveAdd.sin_addr.s_addr = htonl(INADDR_ANY);//其实就是0.0.0.0 通配地址
serveAdd.sin_port = htons(SERVE_PORT);
if (-1 == bind(listensock, (SA*)&serveAdd, sizeof(serveAdd))) {
ERR_EXIT("bind");
}
if (-1 == listen(listensock, 5)) {
ERR_EXIT("listen");
}
return listensock;
}
void setnoblock(int fd) {
int oldflag;
oldflag = fcntl(fd, F_GETFL); //获取flag
if (-1 == fcntl(fd, F_SETFL, oldflag | O_NONBLOCK)) {
ERR_EXIT("fcnl");
}
}
//像epfd中增加监视事件,将监视事件挂在到红黑树上
void addfd(int epfd, int fd) {
struct epoll_event ev;
ev.data.fd = fd;
ev.events = EPOLLIN | EPOLLERR | EPOLLET;
if (-1 == epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev)) {
ERR_EXIT("epoll_ctl");
}
setnoblock(fd);
//设置非阻塞IO,因为是ET
}
void delfd(int epfd, int fd) {
struct epoll_event ev;
if (-1 == epoll_ctl(epfd, EPOLL_CTL_DEL, fd, &ev)) {
ERR_EXIT("epoll_ctl");
}
}
//使用多线程去演示
void* Routine(void* arg) {
struct epoll_event* evs = (struct epoll_event*)calloc(CLIENTSIZE, sizeof(struct epoll_event));
char buff[BUFFSIZE];
//每一个线程都创建一个新地监视窗口,但是其实监视在一个port上
//将问题抛给内核处理,
int listensock = (int)arg;
int epfd = epoll_create(CLIENTSIZE);
int i;
addfd(epfd, listensock);
int count = 1; //记录监视IO事件地数目
while (1) {//循环监视
int nready = epoll_wait(epfd, evs, count,-1);
printf("tid: %d 线程被唤醒处理IO事件\n", pthread_self());
sleep(2000);
for (i = 0; i < nready; ++i) {
if (evs[i].events & EPOLLERR) {
//处理错误断开连接等等操作
} else if ((evs[i].events & EPOLLIN) && evs[i].data.fd == listensock) {
socklen_t clientLen;
struct sockaddr_in clientAdd;
//处理accept操作
int connectsock = accept(listensock, (SA*)&clientAdd, &clientLen);
if (connectsock == -1) {
ERR_EXIT("accept");
}
printf("accept sucess and fd is %d\n", connectsock);
//增加监视事件
addfd(epfd, connectsock);
} else if (evs[i].events & EPOLLIN) {
//read
//decode
//compute
//encode
//修改成监视写事件
} else if (evs[i].events & EPOLLOUT) {
//write
//改成读事件
}
}
}
free(evs); //释放资源
}
int main() {
pthread_t tid;
int i;
//此处显示多个线程共享一个listensock 看看效果
int listensock = CreateSocket();
for (i = 0; i < 10; ++i) { //简单地开十个线程
//int listensock = CreateSocket();
pthread_create(&tid, NULL, Routine, (void*)listensock);
pthread_detach(tid);//分离线程
}
while (1); //主线程等待子线程结束
return 0;
}- 上述还没有进行一个每一个进程都对应一个listensock 而是多线程共享一个listensock 运行结果如下

所有的线程同时被唤醒了,但是实际上会处理连接的仅仅只是一个线程,
int main() {
pthread_t tid;
int i;
//int listensock = CreateSocket();
for (i = 0; i < 10; ++i) { //简单地开十个线程
int listensock = CreateSocket();
pthread_create(&tid, NULL, Routine, (void*)listensock);
pthread_detach(tid);//分离线程
}
while (1); //主线程等待子线程结束
return 0;
}
- 咱仅仅只是将主线程做如上这样一个简单的修改,每一个线程对应一个listensock;每一个线程一个独有的监视窗口,将问题抛给内核去处理,让内核去负载均衡 : 结果如下

仅仅唤醒一个线程来进行处理连接,解决了惊群问题
五. 总结本章:
- 本文通过介绍两种锁入手,以及为什么需要锁,锁本质就是为了保护,持有锁你就有权力有能力操作写入一定的临界保护资源,没有锁你就不行需要等待,本质其实是将多条汇编指令绑定成原子操作
- 然后介绍了惊群现象,通过一个巧妙地例子,扔一颗石子,只是瞄准一条鱼扔过去了,但是整池鱼都被惊醒了,
- 对应我们地实际问题就是, 多个线程或者进程共同监视同一个listensock。。。。然后IO连接事件到来地时候本来仅仅只是需要一个线程醒过来处理即可,但是却会使得所有地线程(进程)全部醒过来,造成不必要地进程线程间切换,多核CPU被浪费喔,系统资源被浪费
- 处理方式 一。 Nginx 源码加互斥锁处理。。 二。设置SO_REUSEPORT, 使得多个进程线程可以同时连接同一个port , 为每一个进程线程搞一个listensock... 将问题抛给内核去处理,让他去负载均衡地仅仅将IO连接事件分配给一个进程或线程