爬取起点小说网
安装requests库
用到的方法:get(),post()方法
爬取步骤:
(1)导入requests库
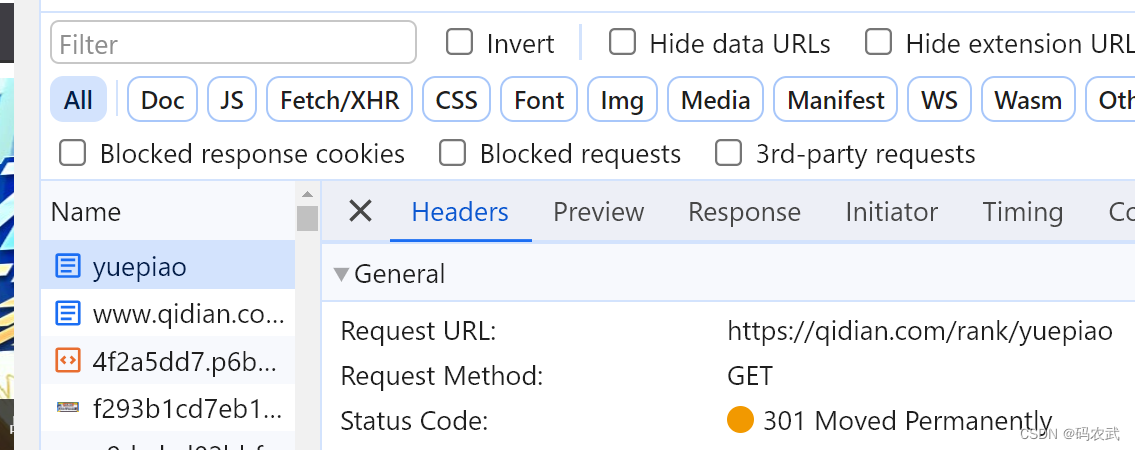
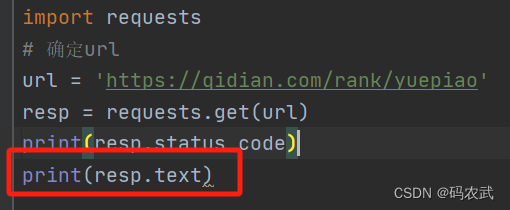
(2)确定url(爬取目标的地址)
起点小说网
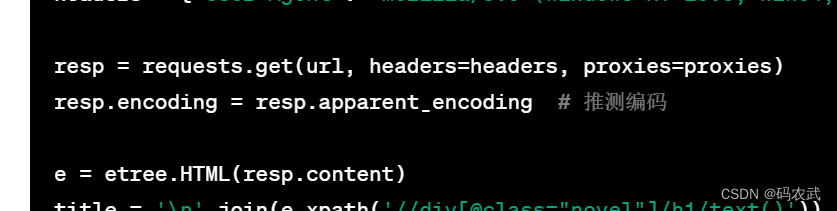
(3)使用requests发起请求,保存响应

(4)打印状态码
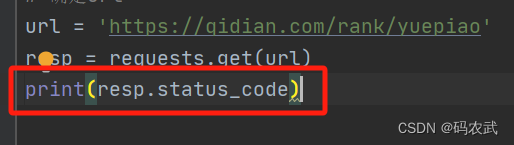
200代表状态正常,请求成功
(5)查看响应源码
(6)添加请求头


目的:伪装成浏览器
(7)使用解析工具--Xpath

安装lxml库
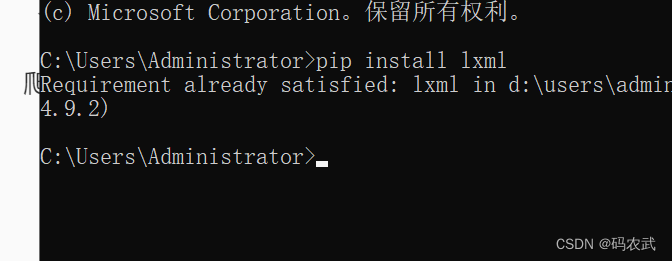
可能遇到的问题:
pip版本级别低:pip install --upgrade pip
网络问题:多次安装
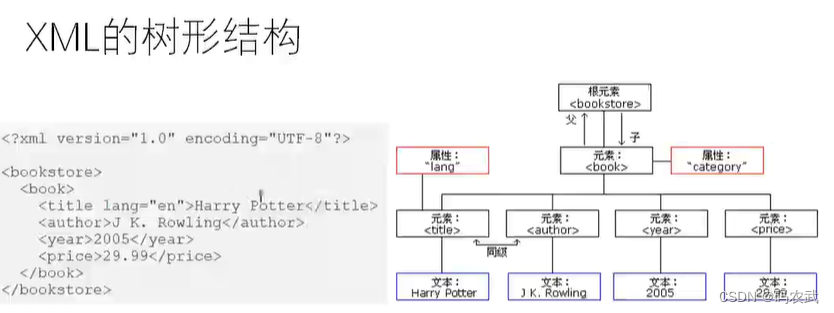
(8)解读XML结构
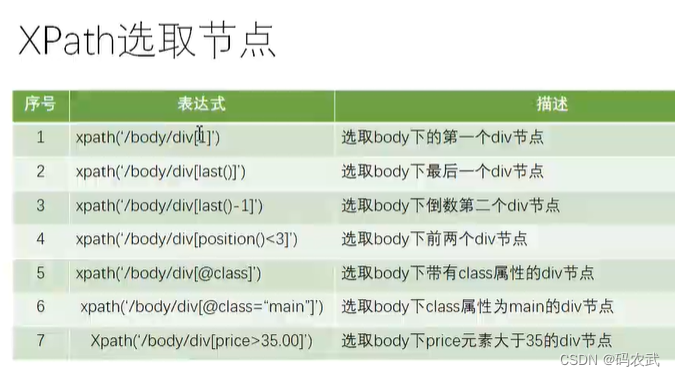
(9)使用XPath选取节点
(10)选取需要的内容
1.选取排行榜标题
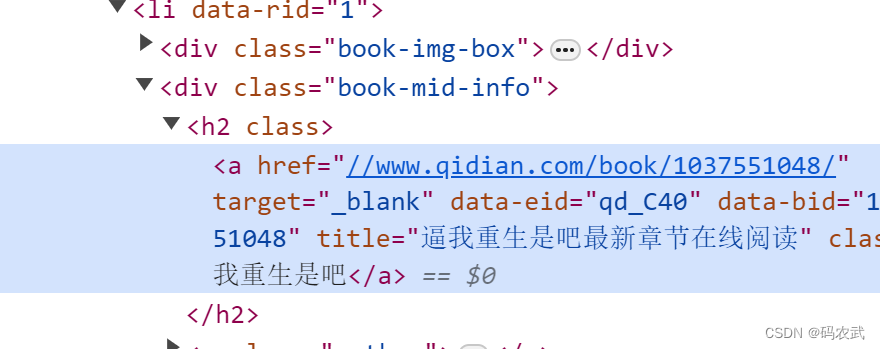
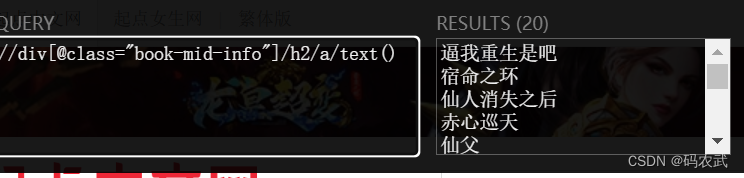
LXML练习:
利用XPath,选取所有的作者
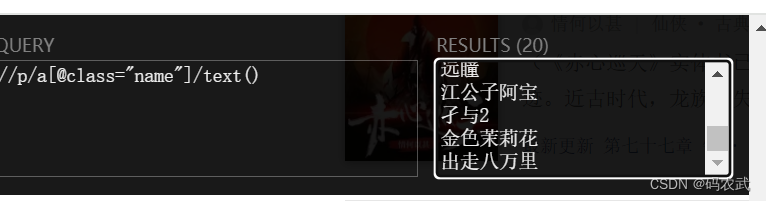
(11)程序中,使用XPath
1.导入LXML库

解决方式:

2.etree的作用,把获取到的数据,整理成咱们XML结构
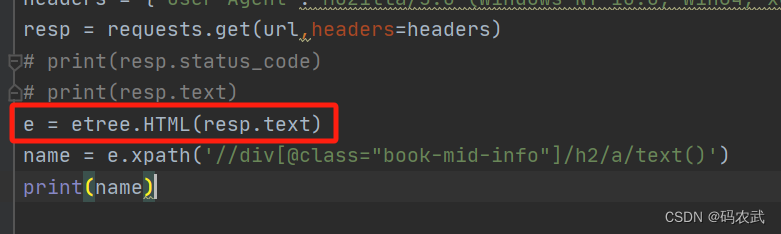
3.获取小说名称
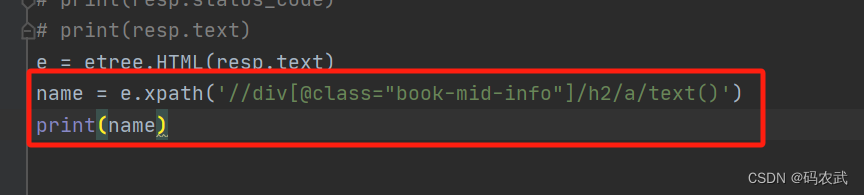
4.(练习)获取作者
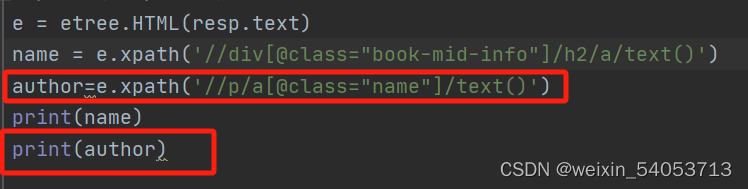
(12)整合数据
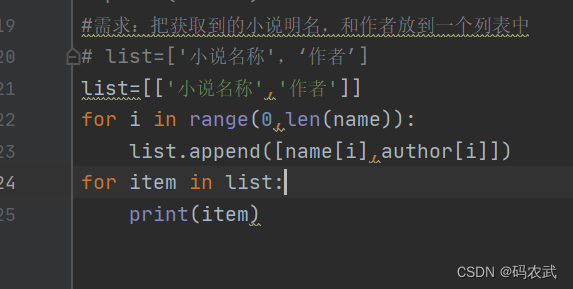
(13)数据的存储
获取到的数据,存储到excel表格中
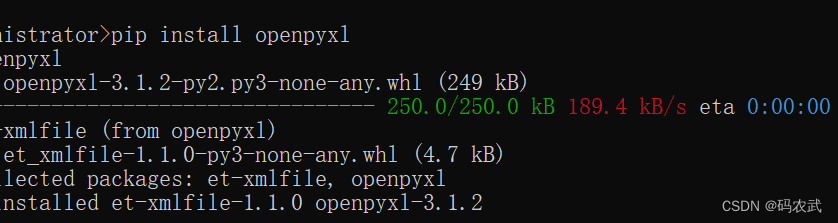
1.使用python操作excel表格,需要引用第三方库openpyxl
安装
pip install openpyxl
导入:
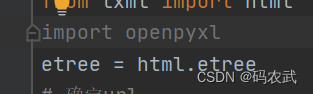
2.借助第三方库,操作excel文件
创建excel文件
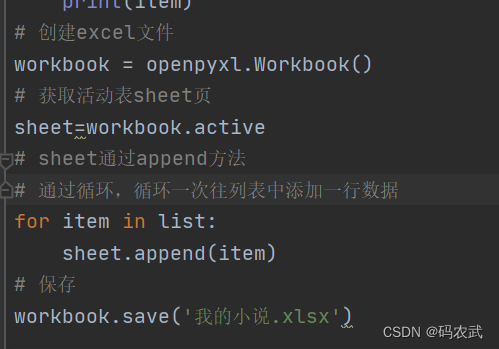
扩展练习:
爬取单独一章小说内容
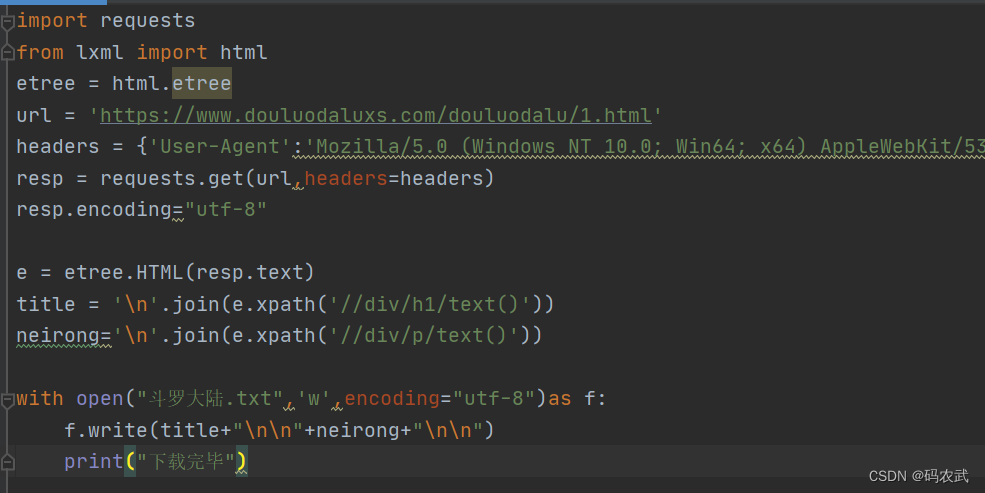
爬取整本小说内容
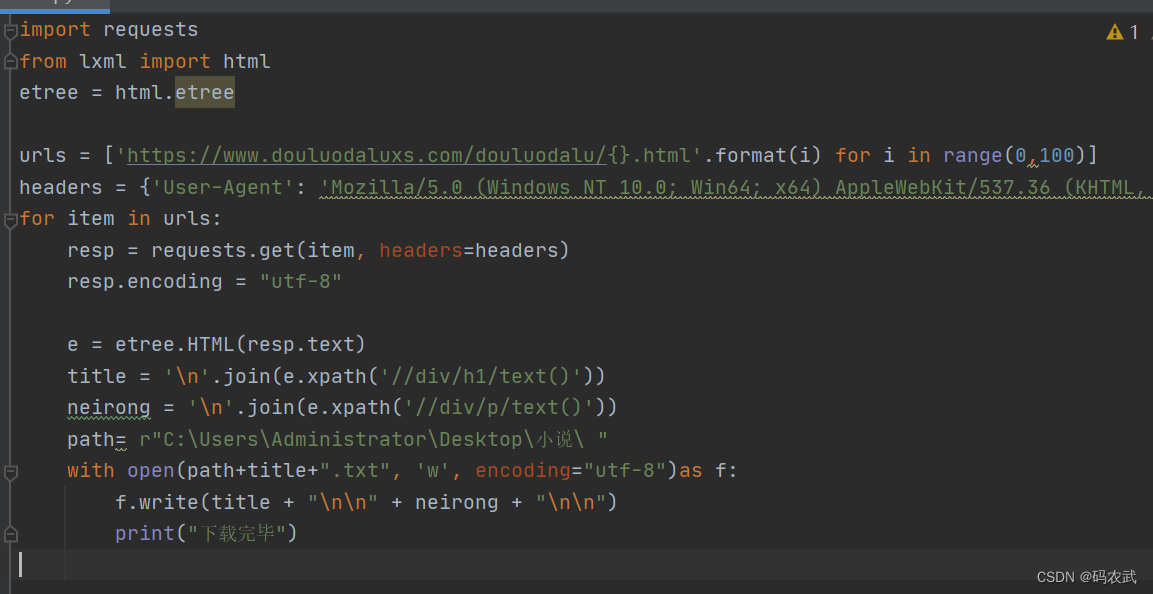
解决乱码问题: