目录
一、多级缓存介绍
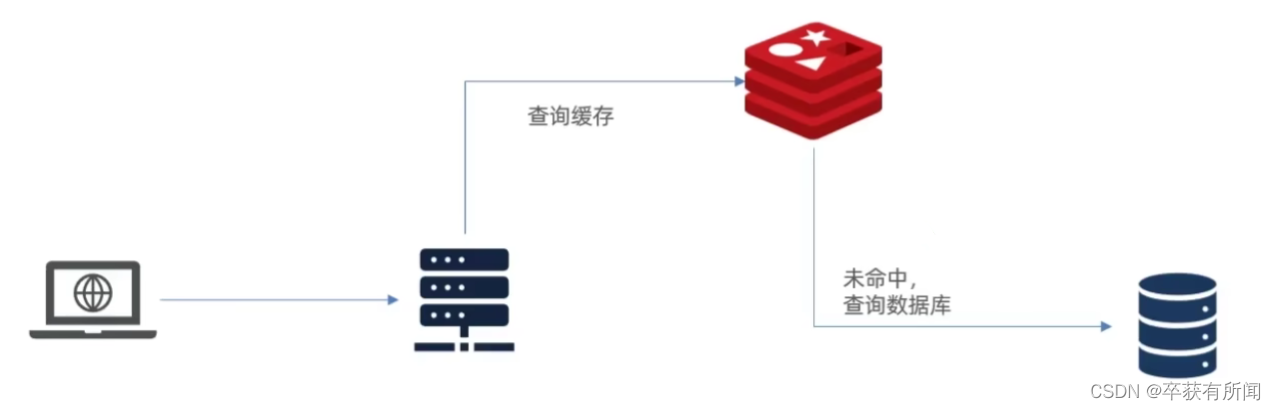
1、传统缓存的问题
传统缓存策略一般是请求到tomcat后,先查询redis,如果未命中则查询数据库
请求要先经过tomcat处理,tomcat的性能成为整个系统的瓶颈
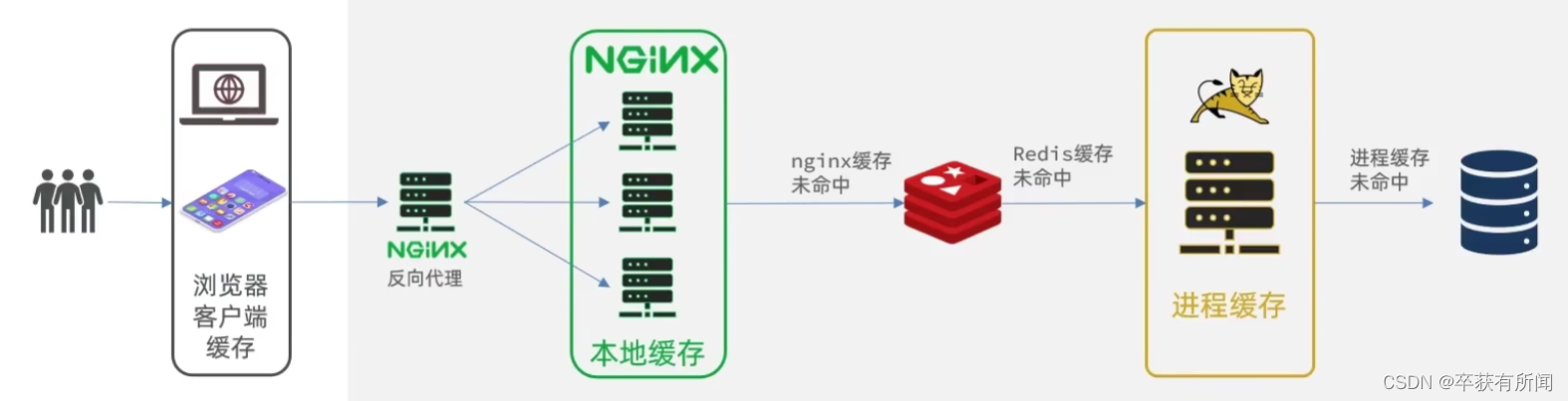
2、多级缓存方案
多级缓存就是利用请求处理的每个环节,分别添加缓存,减轻tomcat压力,提升服务器性能:
二、JVM进程缓存
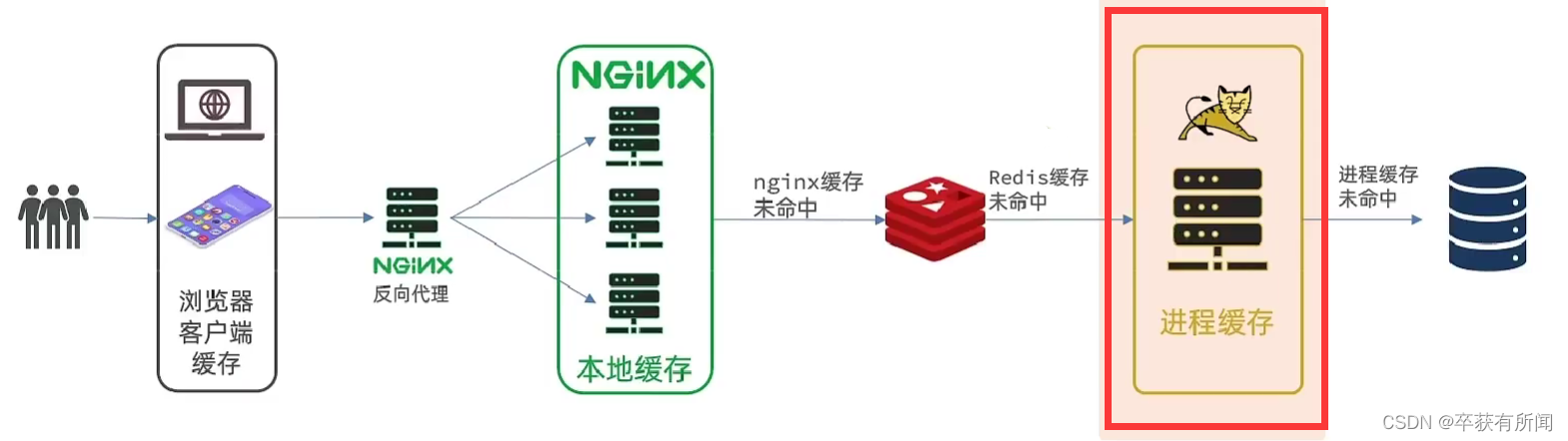
1、初始Caffeine
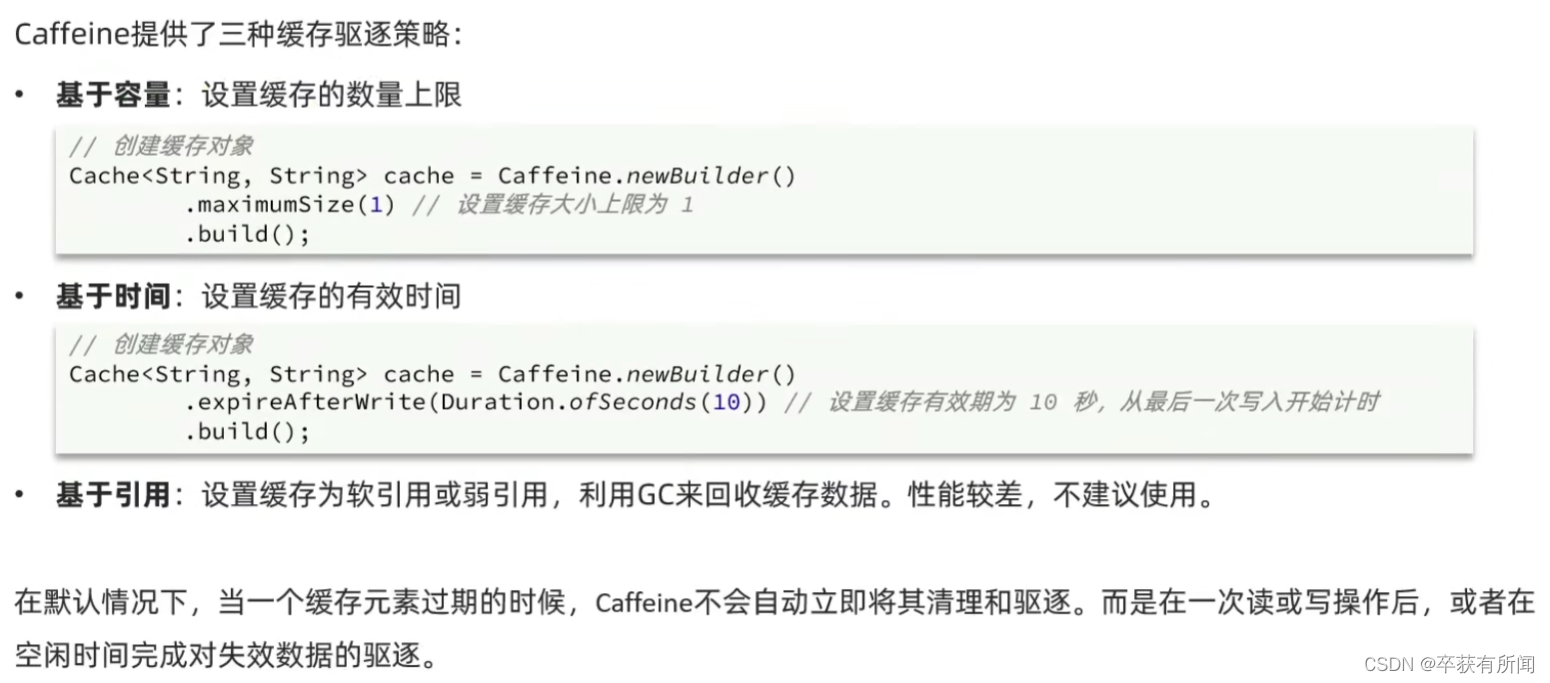
缓存分类
我们把缓存分为两类:分布式缓存和进程本地缓存
分布式缓存,例如Redis:
- 优点:缓存容量更大,可靠性更好,可以在集群间共享
- 缺点:访问缓存网络开销大
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
进程本地缓存,例如hashMap、GuavaCache
- 优点:读取本地内存,没有网络开销,速度快
- 缺点:存储量有限,可靠性低,无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine入门
Cafeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。

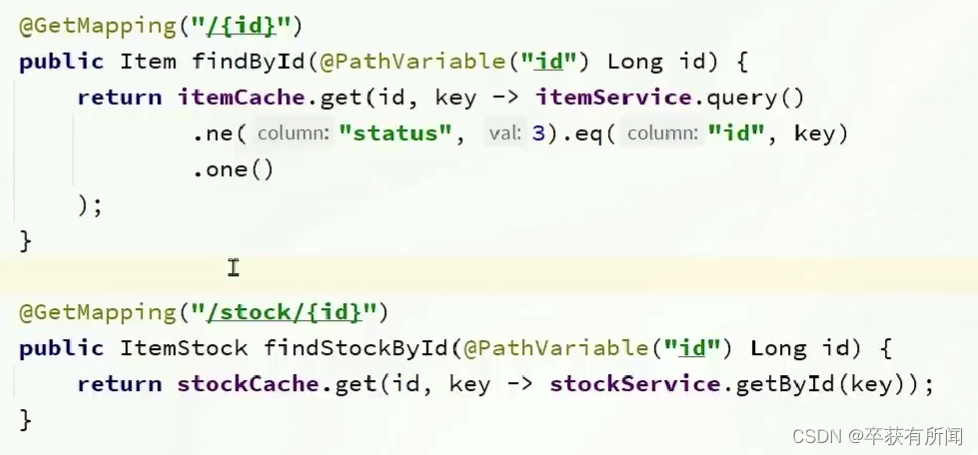
2、实现进程缓存

创建一个CaffeineConfig配置类

在要使用的地方注入bean

修改业务
三、Lua脚本
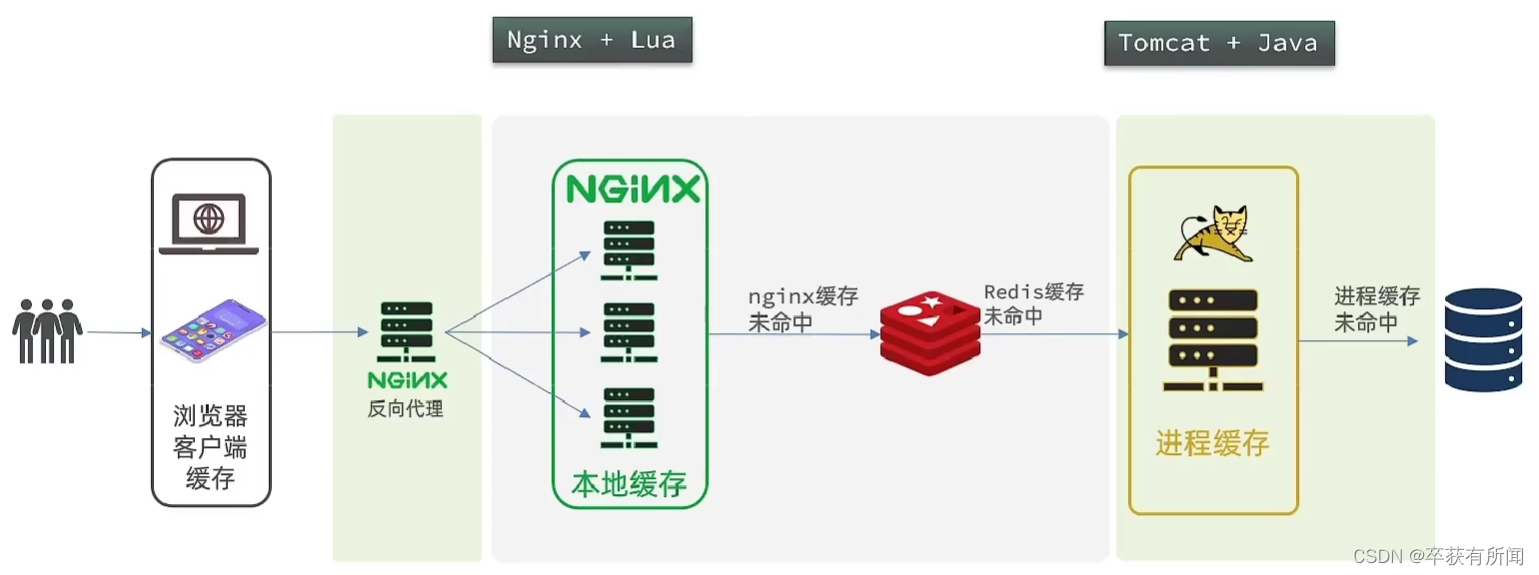
我们现在已经完成了nginx反向代理和tomcat的进程缓存
接下来我们要用lua来完成nginx的本地缓存
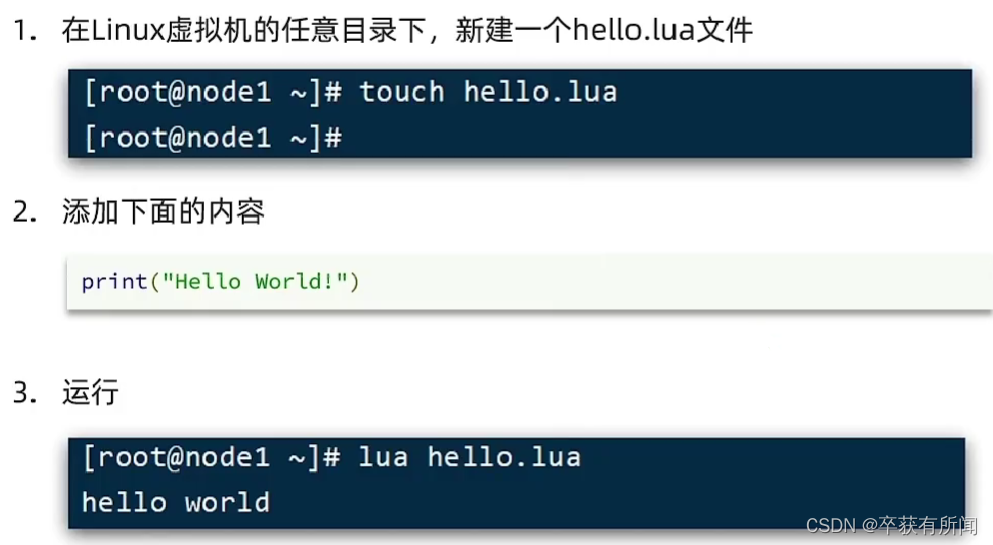
1、初始Lua
Lua是轻量小巧的脚本语言,用c编写,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能,经常用在游戏开发中
centOS自带了lua,所有不用安装
2、Lua语法
数据类型

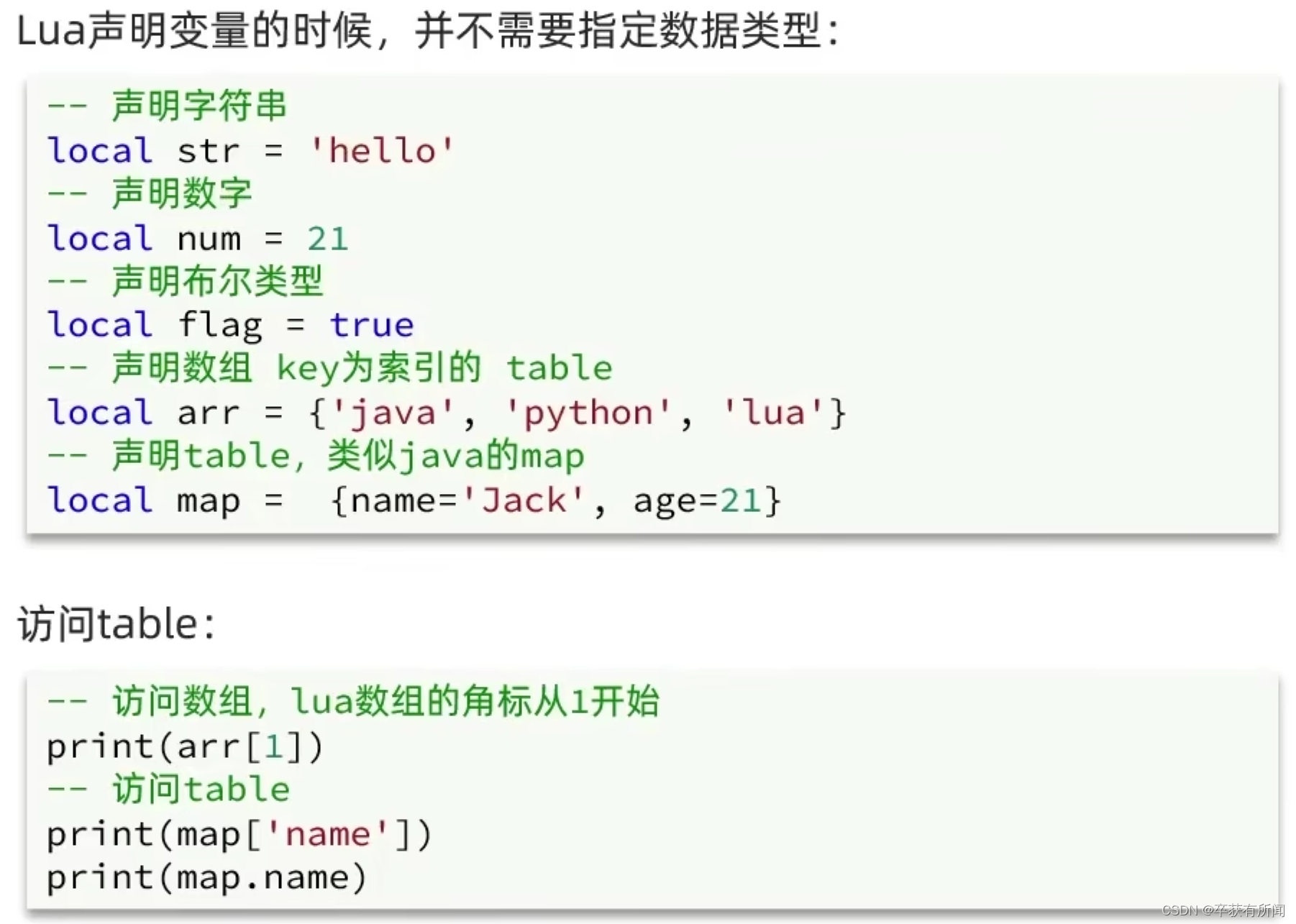
变量
Lua声明变量的时候,不需要指定数据的类型,local表示局部变量的意思
循环
for循环遍历的时候do和end就相当于大括号,in后面是要遍历的对象括号里面是类型
前面是以键值对的方式来遍历的,index数组的话就是索引和value就是值

函数

条件控制

四、OpenResty
1、初始OpenResty
OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
先按照好OpenResty然后配置好nginx
2、OpenResty快速入门
修改nginx配置
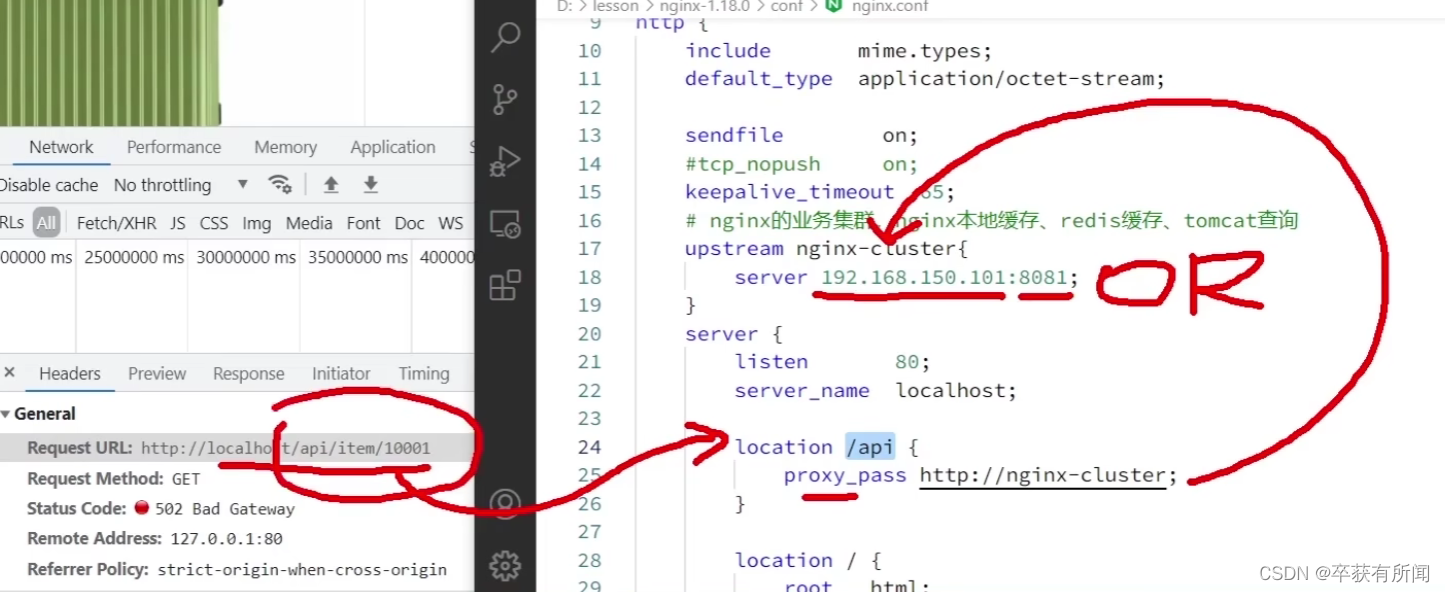
我们先把自己的接口请求打到nginx反向代理服务器,然发到OpenResty的服务器上
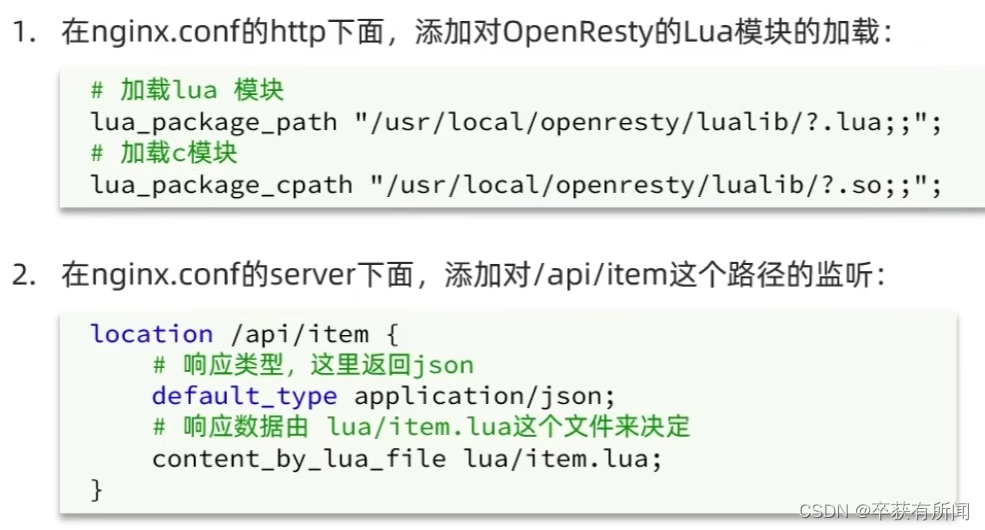
openResty的lua模块是固定的直接复制
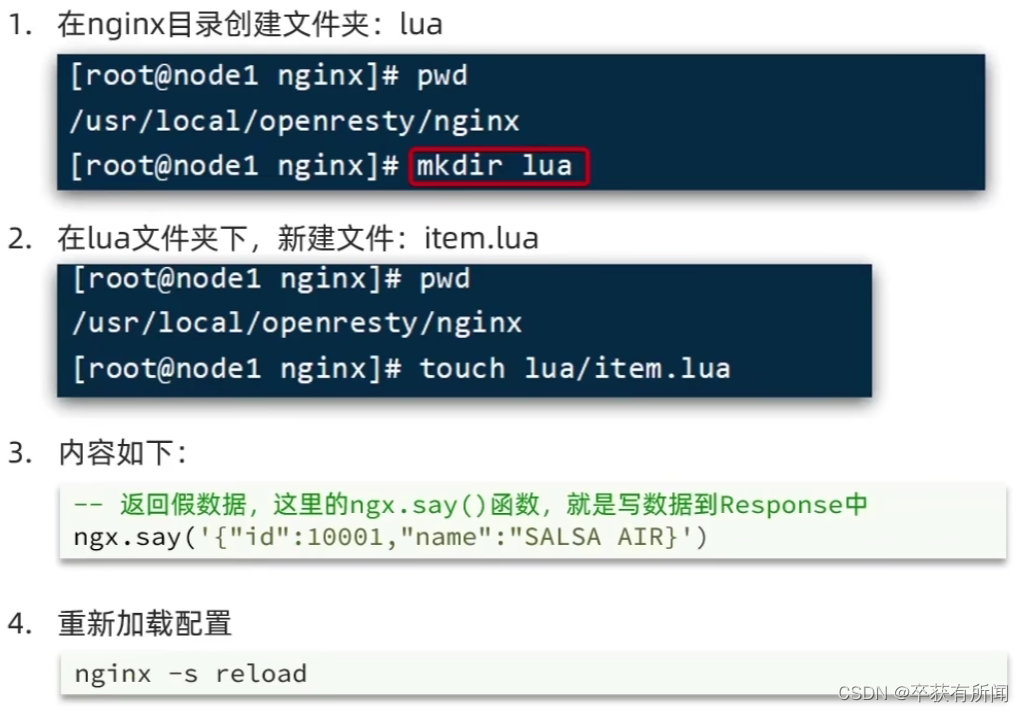
编写lua文件
因为是快速入门,我们先用假数据返回固定的
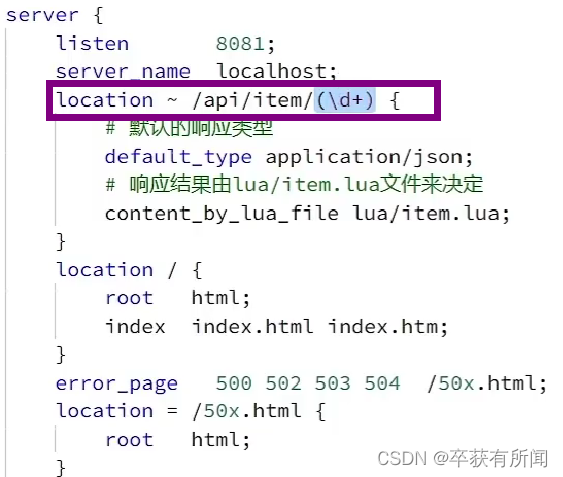
3、OpenResty获取请求参数


4、封装Http请求工具
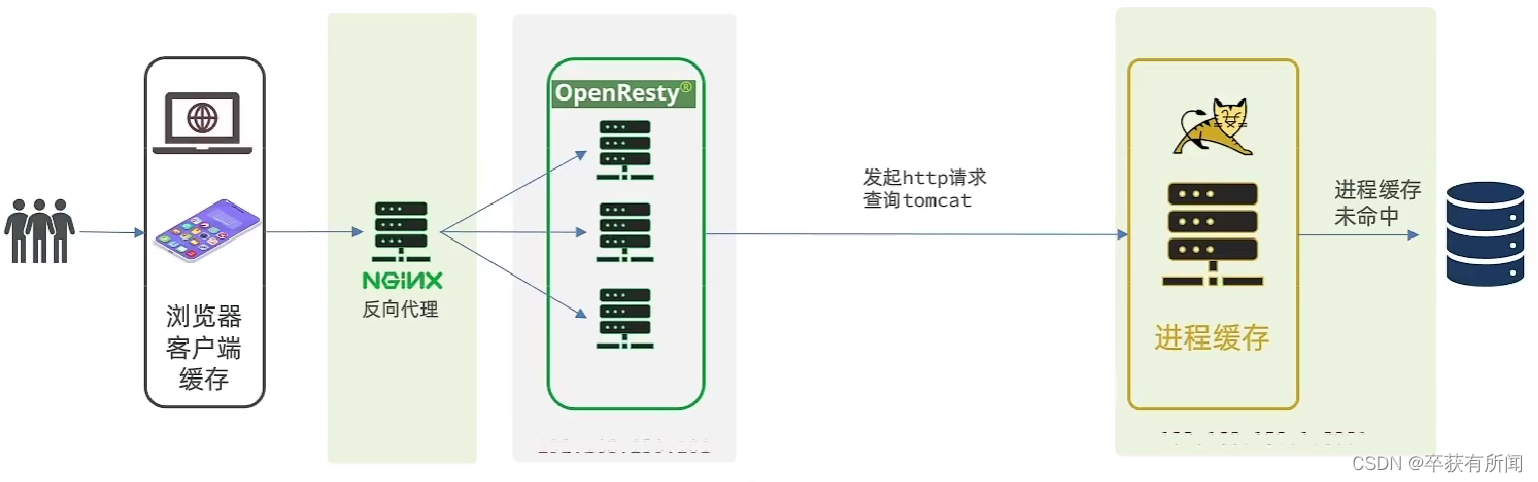

我们可以把请求打到nginx的负载均衡服务器再转发到tomcat
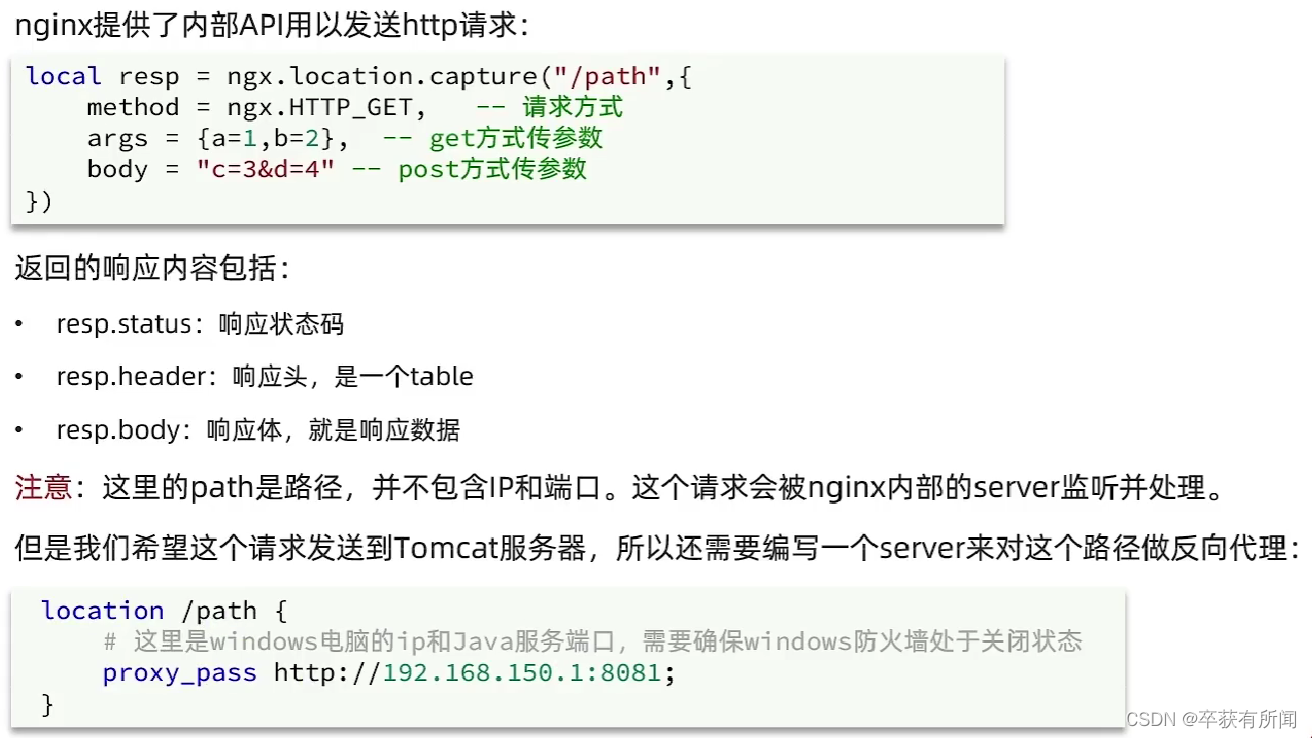
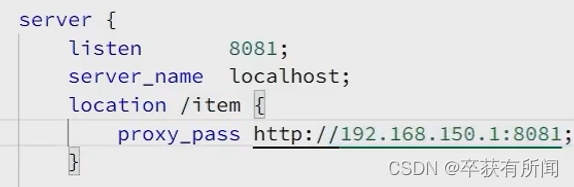
我们这个请求是要发两次的,我们要提取出来,方便复用,放到lualib目录下
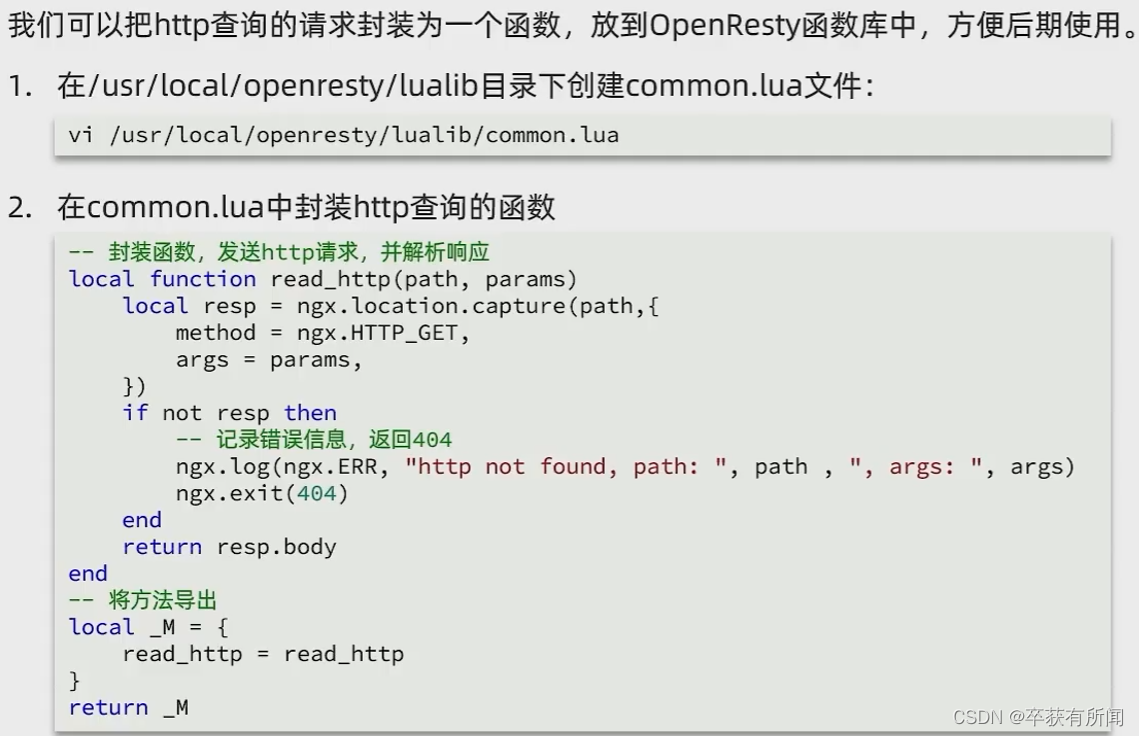
5、向tomcat发http请求
编写lua脚本
因为中间要用到字符串拼接,json不能实现所有要转成lua语法再拼接然后转化json返回

6、对tomcat集群负载均衡
我们实际上不可能只有一台tomcat肯定是集群,所以我们要配置负载均衡
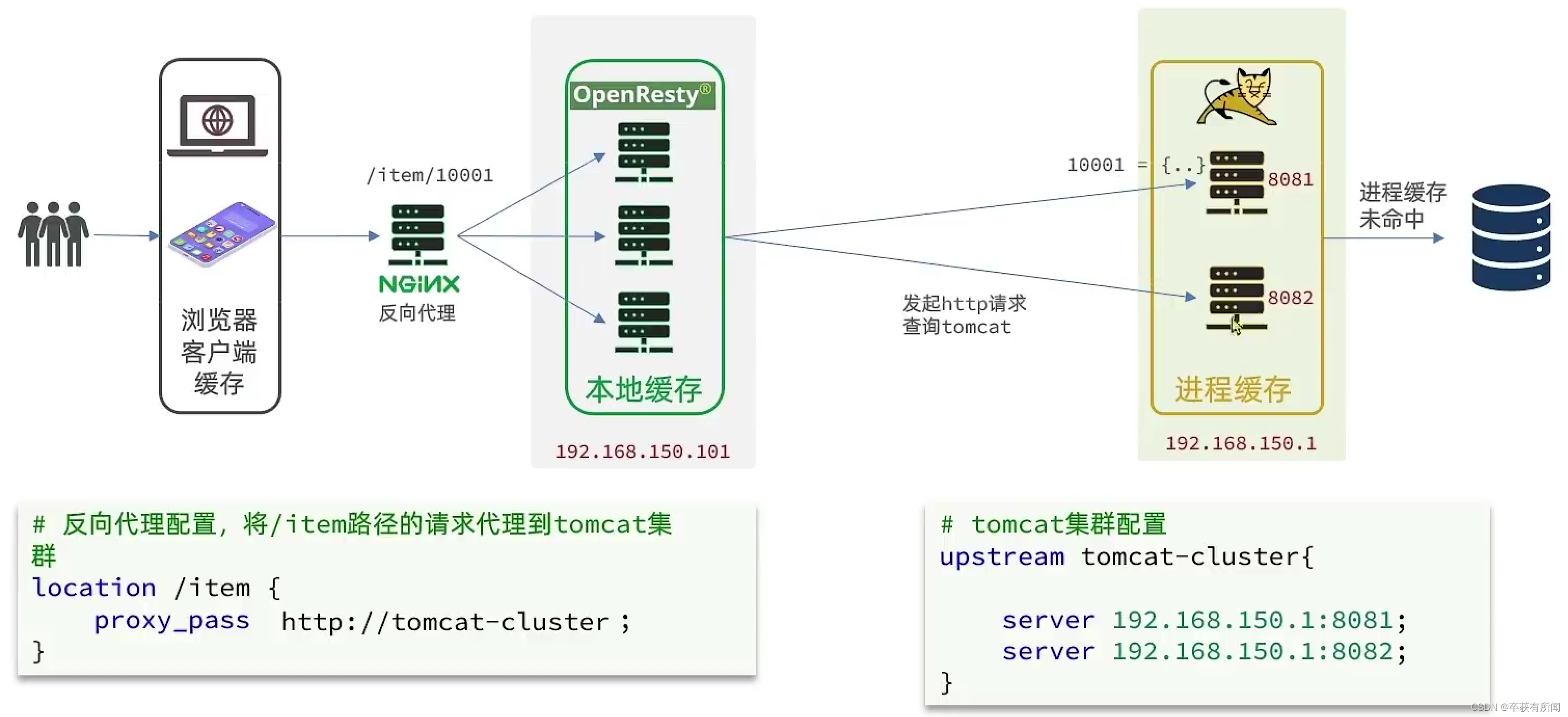
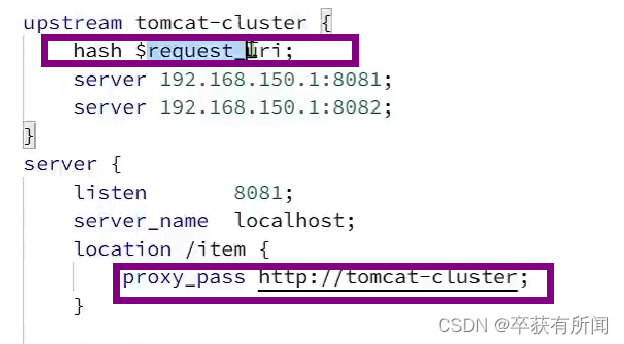
我们肯定不能每次走不同的,这样会导致进程缓存重复缓存,所以我们经历同一个id的请求打到一个服务器上,我们要用hash运算然后对服务器数量取模。
7、Redis缓存预热
冷启动:服务刚刚启动时,redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,再项目启动时将这些热点数据提前查询并保存redis中
所以在我们redisconfig里面添加上预热
因为我们是分表的商品信息表和库存表,所以分开缓存,库存表经常变动

8、OpenResty查询Redis
OpenResty的Redis模块
OpenResty提供了操作Redis的模块,我们只需要引入该模块就能直接使用:

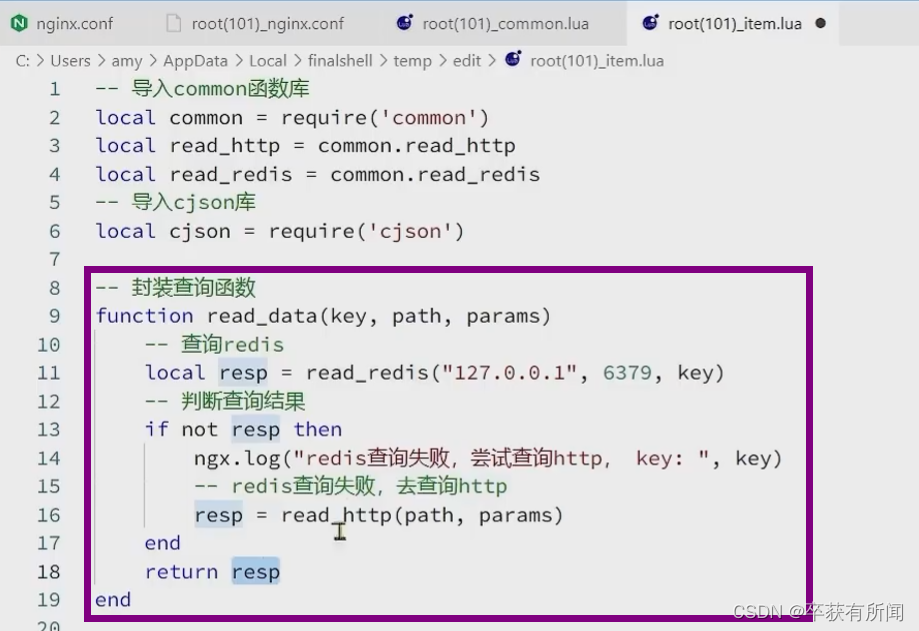
查询数据的方法

把查询和释放的方法都写到common.lua里面,然后暴露出去,到时候调用就行
查询逻辑也要改,先查询redis,redis没命中再查tomcat
9、Nginx本地缓存
OpenResty为Nginx提供了shard dIct功能,可以在nginx的多个worker之间共享数据,实现缓存功能
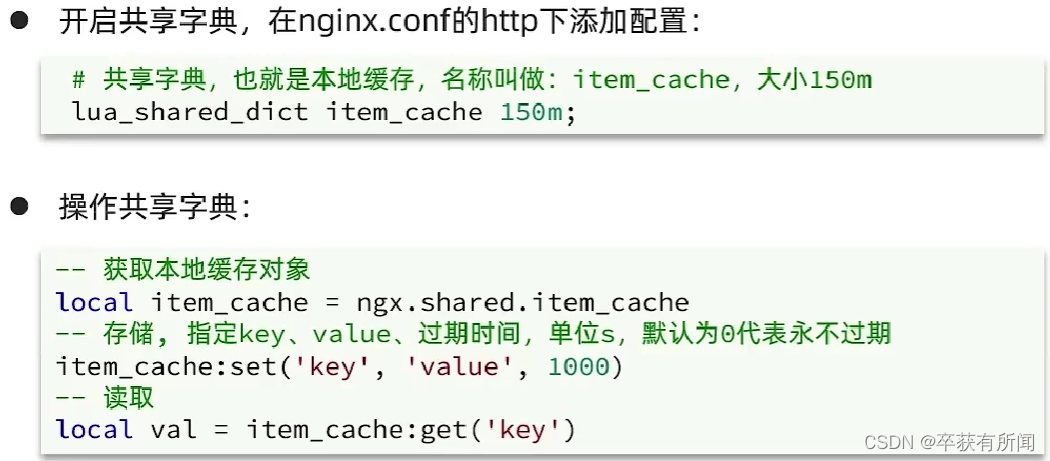
先再nginx.conf中配置共享词典
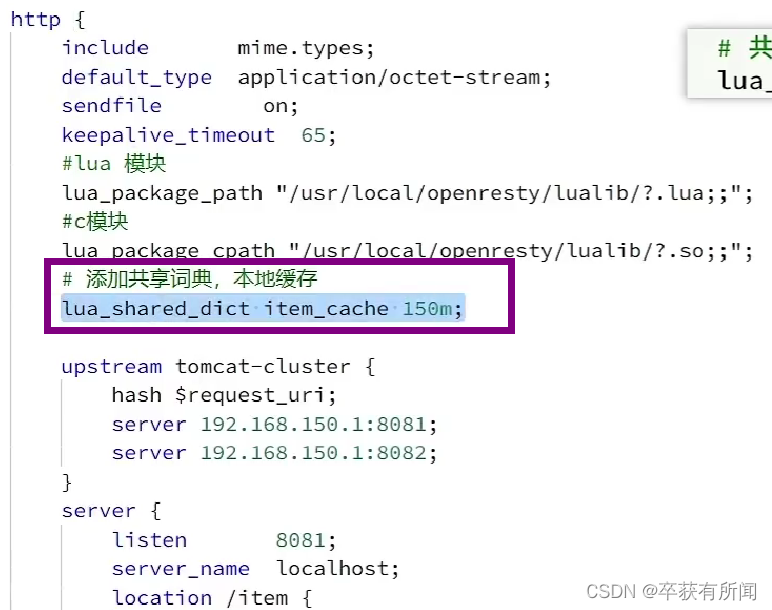
然后导入

需求
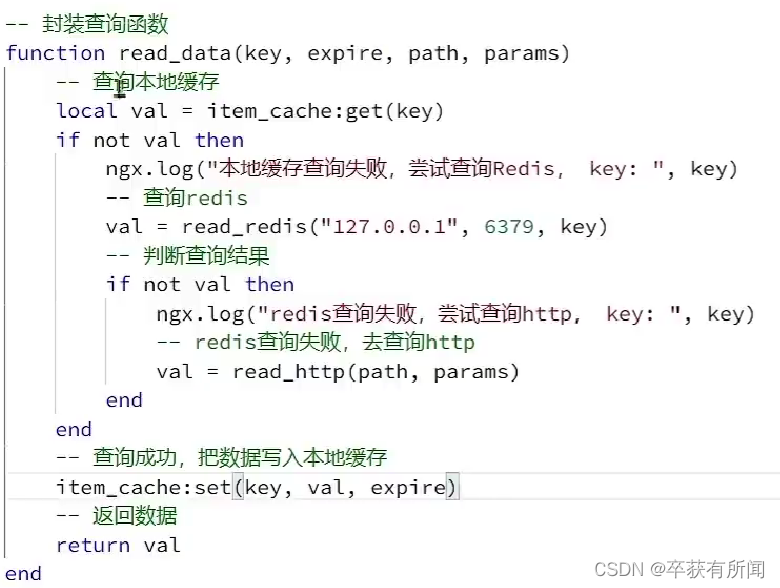
- 修改item,lua中的read data函数,优先查询本地缓存,未命中时再查询Redis、Tomcat
- 查询Redis或Tomcat成功后,将数据写入本地缓存,并设置有效期
- 商品基本信息,有效期30分钟(基本上常年不变的可以缓存久点)
- 库存信息,有效期1分钟(要检测变动的)
五、缓存同步
1、数据同步策略
缓存数据同步的常见方式有三种:
- 设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
- 同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
- 异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
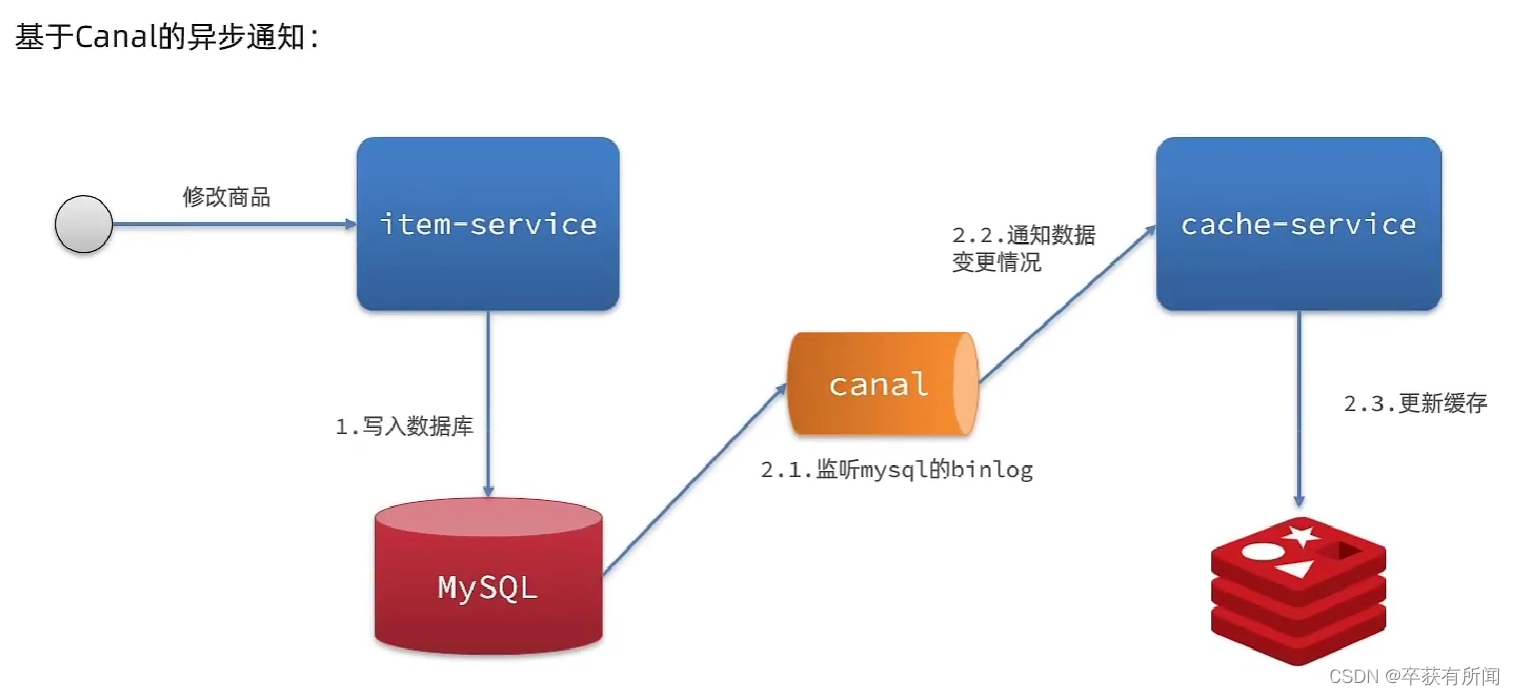
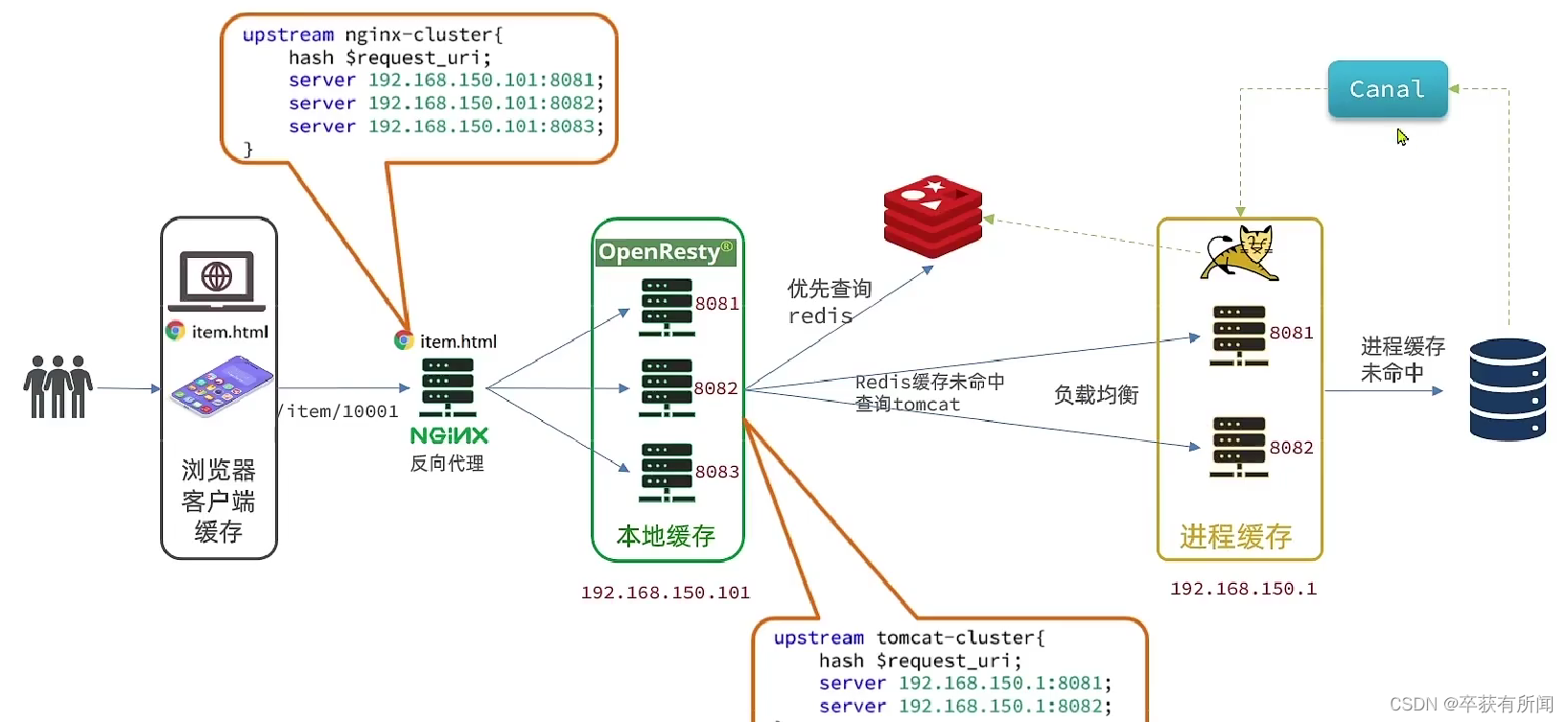
引入canal的异步通知,canal监听数据库的变化,发生变化后立刻通知更新缓存
2、Canal入门
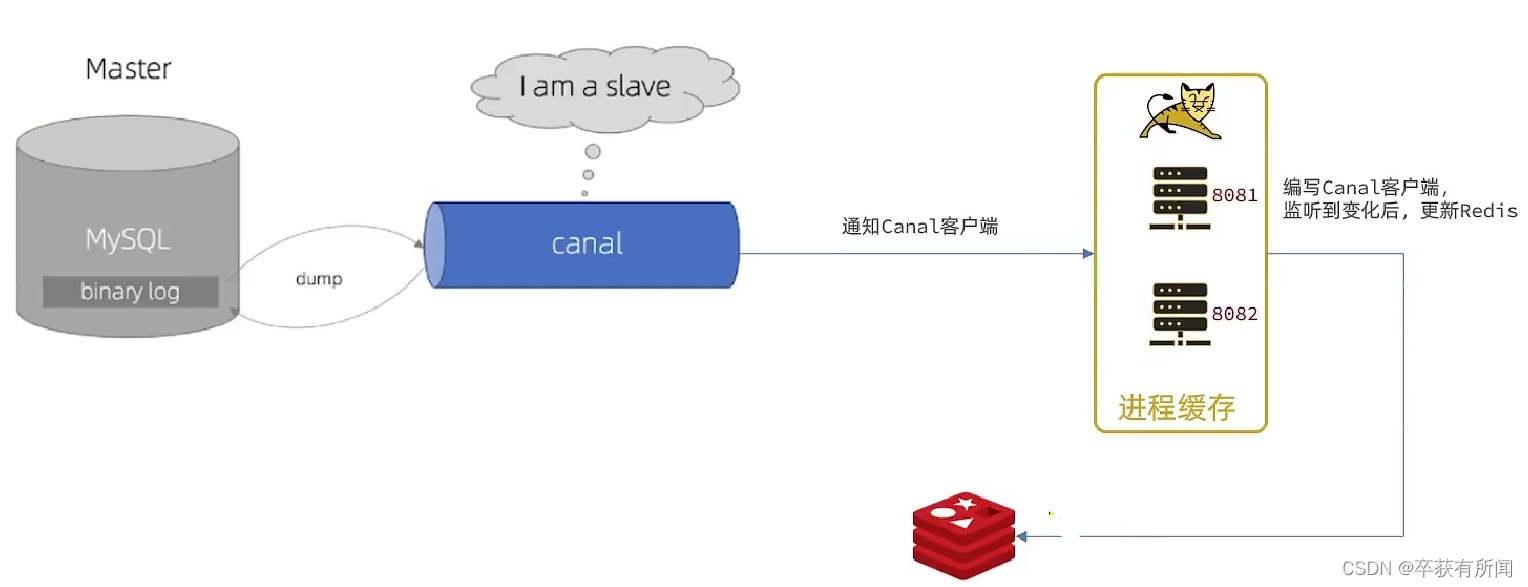
Canal译为水道、管道,是阿里开源项目,基于java开发。基于数据库增量日志解析,提供增量数据订阅&消费
Canal是基于mysql主从同步实现的,mysql主从同步原理如下
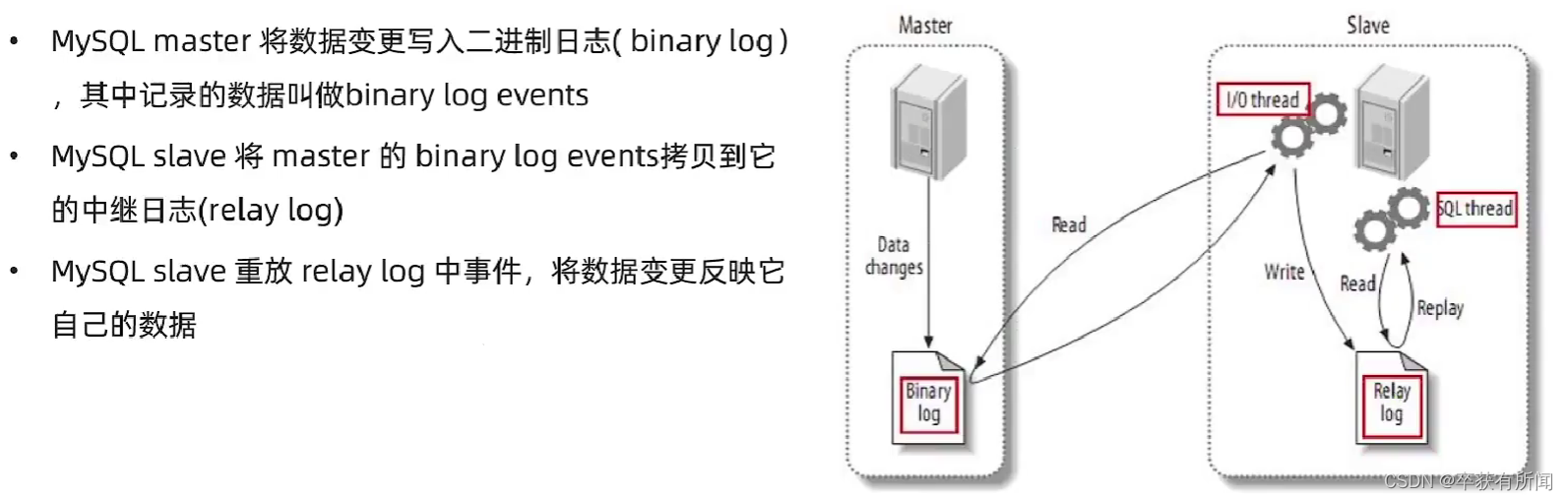
Canal就是把自己伪装成mysql的一个slava节点,从而监听master的binary log变化,再把变化的信息通知给canal客户端,进而完成对其他数据库的同步
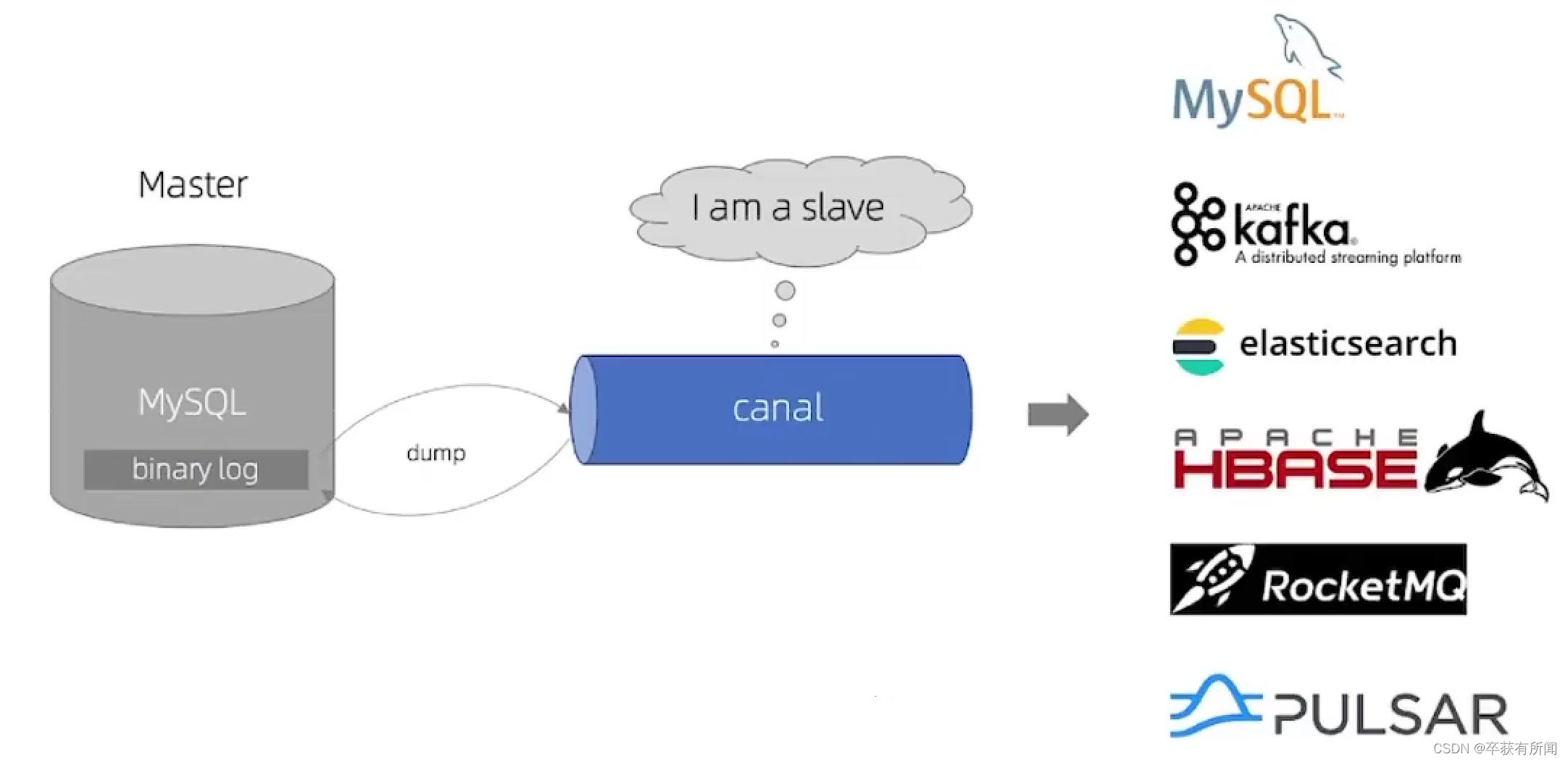
3、引入Canal
(1)先开启mysql主从同步
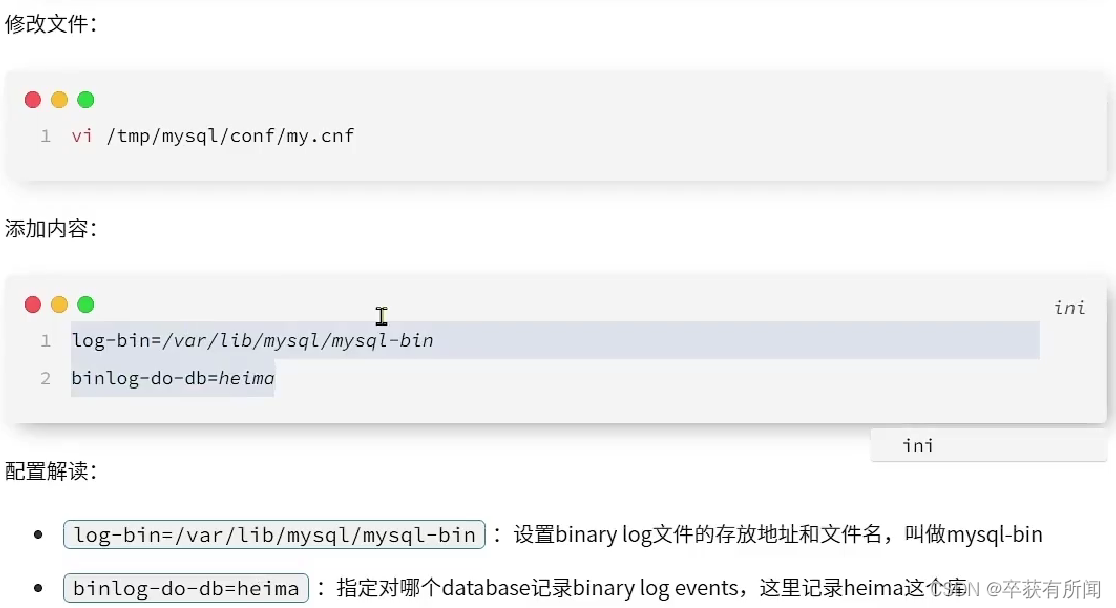
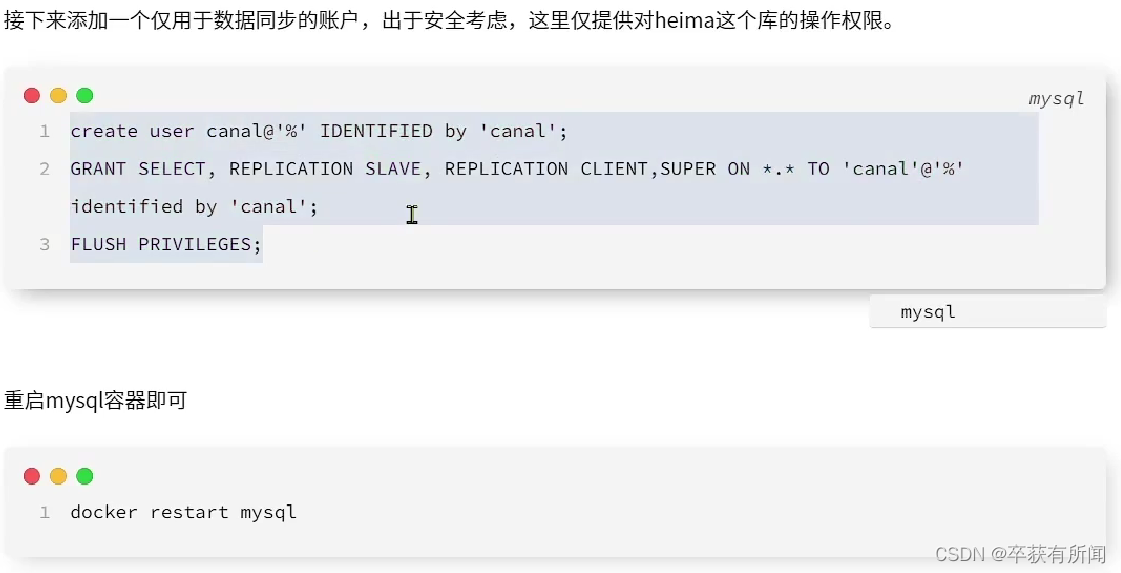
(2)安装Canal
(3)执行命令创建Canal容器:
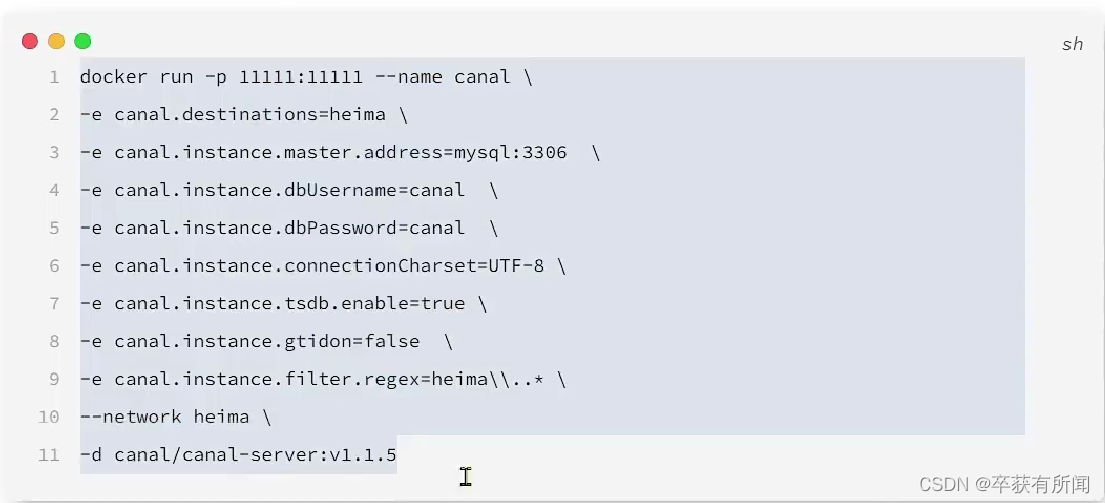

这样,我们就成功用Canal对mysql进行监听了
4、Canal客户端
接下来我们就更新tomcat的客户端,来监听Canal的消息
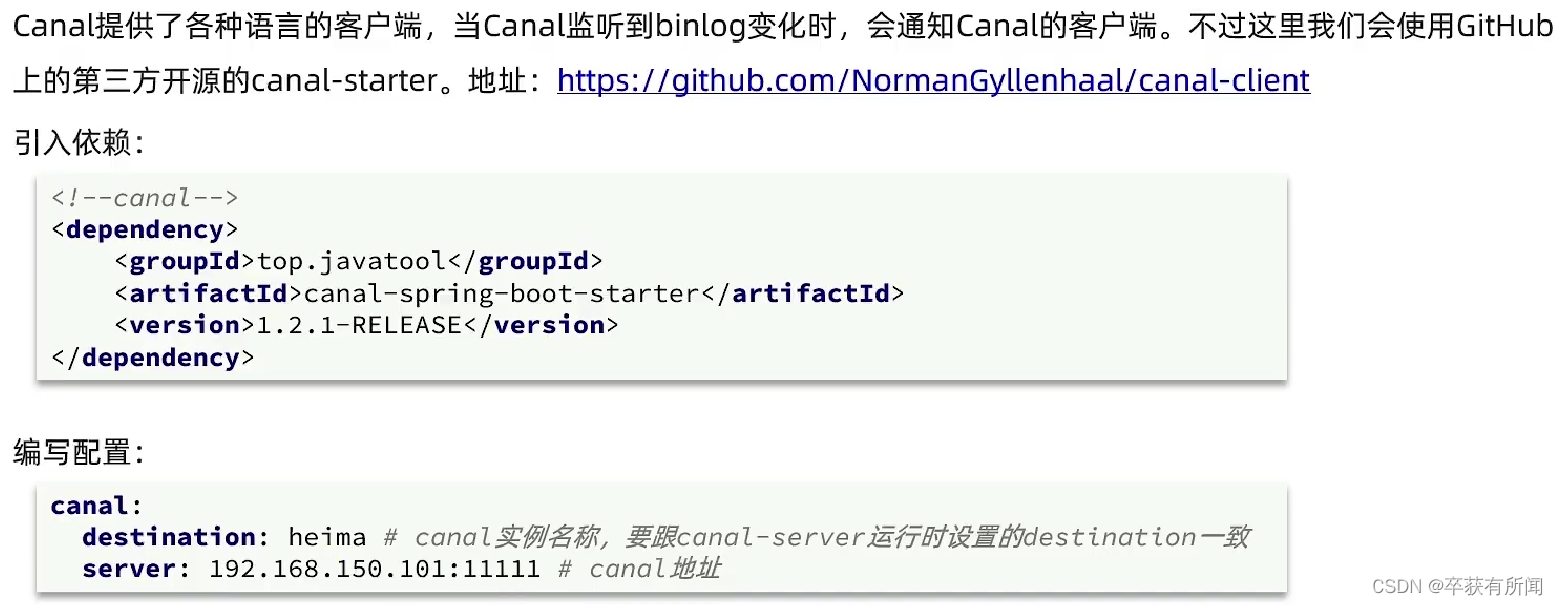
监听Canal我们首先先引入springboot整合canal的依赖,然后配置好canal
然后编写监听器来监听canal的消息
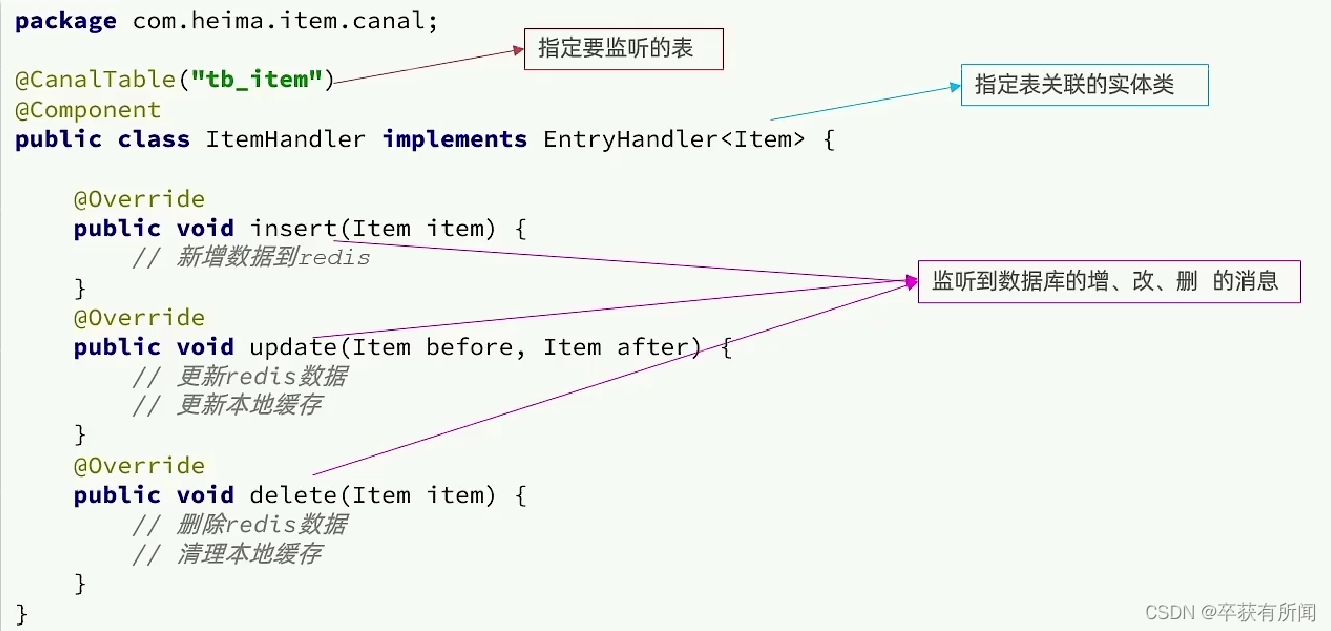
canal推送给canal客户端的是被修改的这一行数据,我们引入的canal客户端会帮助我们把这行数据封装到item实体类中,这个过程需要知道数据库和实体的映射关系,要用到注解来映射
业务逻辑:

总结
最后的架构图: