一、背景意义
随着人们对生态保护和环境健康的关注加剧,有毒动植物的识别和分类变得尤为重要。这些动植物不仅对人类健康构成威胁,还可能对生态系统的平衡造成影响。随着人工智能和深度学习技术的发展,利用计算机视觉技术对有毒动植物进行自动识别,能够大幅提高识别的效率和准确性。数据集包含多种有毒动植物的名称。该数据集的多样性使其成为训练深度学习模型的理想选择。通过深度学习算法,尤其是卷积神经网络(CNN),可以实现对这些动植物的自动识别,为野外调查、教育普及和公共安全提供有力支持。
二、数据集
2.1数据采集
首先,需要大量的动植物图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示动植物特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
在使用LabelImg标注野外有毒动植物数据集时,你将面临着一项复杂而耗时的任务。这个数据集包含着多样的有毒动植物分类,每个分类都有独特的形态特征和识别要点,需要仔细辨认和标注。以下是一份描述该标注任务的内容:
标注野外有毒动植物数据集的复杂性描述:
-
分类繁多: 数据集包含了多达21种不同的有毒动植物分类,每种分类都有其独特的特征和外貌,需要准确识别和标注。
-
形态特征复杂: 每个分类的形态特征可能存在细微差异,如有毒蘑菇的菌盖、菌褶、菌柄等部位的特征,或毒蛇的斑纹、眼睛形状等特征,要求标注员具备辨别的专业知识。
-
标注精度要求高: 由于这些动植物具有潜在的毒性,标注的准确性至关重要。对于训练模型来说,准确标注有助于模型的正确识别和分类。
-
工作量巨大: 面对如此多的分类和复杂的形态特征,标注过程将是一项耗时费力的工作,需要标注员投入大量精力和时间。
-
专业性要求: 由于标注的复杂性,标注员需要具备对有毒动植物分类的专业知识和经验,以确保标注的质量和准确性。

包含2884张野外动植物图片,数据集中包含以下几种类别
- 鳞伞菌:野外的一种真菌,具有特征性的白色鳞片。
- 拟蝰蛇:野外的一种蛇类,常见于北美地区。
- 风蕈:野外的一种有毒真菌,通常具有鲜艳的红色。
- 长柄鹅膏菌:野外的一种有毒真菌,有毒性很强。
- 美味黄孢菌:野外的一种可食用的真菌,呈漂亮的黄色。
- 波氏环蛇:野外的一种环蛇,常见于北美洲。
- 大黄细鳞蛇:野外的一种蛇类,常见于北美地区。
- 纤细美龙:野外的一种蛇类,体型纤细。
- 黑喙乌鸡膀:野外的一种真菌,具有黑色的喙。
- 火锅菌:野外的一种可食用真菌,形似号角。
- 俄勒冈响尾蛇:野外的一种毒蛇,分布于俄勒冈地区。
- 阿特罗克斯响尾蛇:野外的一种响尾蛇,毒性较强。
- 点颈圆蛇:野外的一种圆蛇,具有特征性的斑点颈部。
- 加州光环蛇:野外的一种非常色彩斑斓的蛇类。
- 红边墨头鱼:野外的一种有毒海蛇。
- 红棕杏鹤菌:野外的一种可食用真菌,具有红褐色。
- 橄榄伞菌:野外的一种有毒真菌,呈橄榄绿色。
- 铃腹松蛇:野外的一种松蛇,体型较大。
- 根生绒菌:野外的一种真菌,具有根状结构。
- 北部条纹蛇:野外的一种非常常见的条纹蛇类。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)是一种深度学习模型,其设计灵感源于生物视觉系统,尤其是视觉皮层的结构。CNN通过多层次的结构逐步提取图像特征,实现高效的图像识别和分类。其基本原理包括特征提取、降维处理、非线性激活和全连接层的整合。特征提取阶段,CNN利用卷积层提取局部特征,如边缘、纹理和形状,通过卷积核在图像上滑动生成特征图,捕捉局部区域的信息。接下来的降维处理通过池化层(如最大池化)减少特征图的尺寸,降低计算复杂度并提高模型的鲁棒性,从而保留重要特征并减少过拟合风险。非线性激活函数(如ReLU)在激活层被引入,以增强模型的表达能力,使其能够学习复杂的特征表示。最后,在全连接层中,经过多层卷积和池化后提取的特征被整合,进行最终的分类或回归,输出每个类别的概率。

CNN的基本结构通常包含输入层、卷积层、激活层、池化层和全连接层。输入层接收原始图像数据,通常为三维张量(宽度、高度、通道数)。卷积层通过卷积操作提取图像特征,计算局部区域的加权和,生成特征图。激活层使用非线性激活函数增强模型能力,池化层通过下采样降低特征图尺寸,提升模型的泛化能力。全连接层则将提取的特征映射到类别标签,实现最终分类。CNN的优势在于其能够自动从原始图像中学习特征,无需手动设计特征提取方法,这对有毒动植物的多样性及复杂性尤为重要。此外,CNN对物体在图像中的位置变化具有鲁棒性,能够有效识别不同姿态和位置的有毒动植物。同时,通过参数共享和局部连接,CNN显著减少了模型的参数数量,提高了训练和推理的效率,使其成为处理图像识别任务的理想选择。
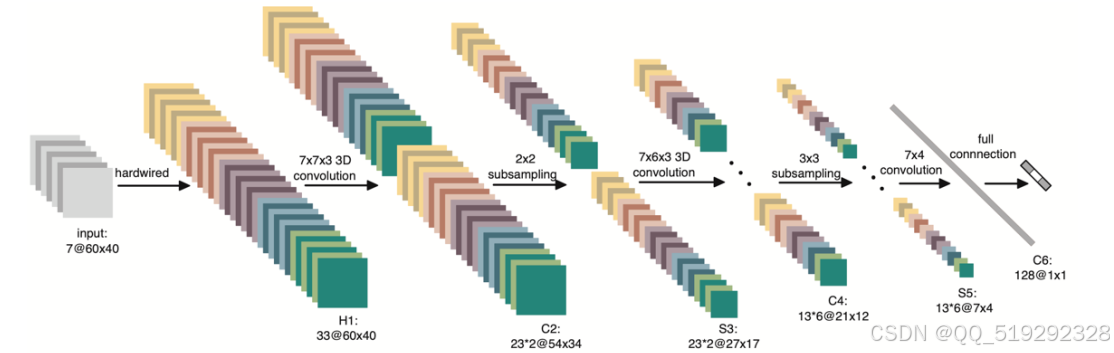
在有毒动植物检测中,卷积神经网络(CNN)展现出显著的应用潜力,能够有效支持多种任务。首先,CNN通过训练模型,能够高效识别各种有毒动植物,如有毒蘑菇和蛇类,这对于生态研究及保护工作至关重要,提供了丰富的数据支持。其次,在野外监测系统中,CNN具备实时处理图像的能力,能够快速识别出有毒动植物,帮助减少误食和误用的风险,保障公众安全。
3.2模型训练
在开发一个YOLO项目之前,首先需要进行数据集的划分和准备工作。这包括将数据集分为训练集、验证集和测试集,并准备好标注文件和图像数据。下面是关于数据集划分和准备的步骤介绍及示例代码:
数据集划分: 首先,将整个数据集按照一定比例划分为训练集、验证集和测试集,通常采用70-20-10的比例划分。这有助于评估模型的泛化能力。
import os
import random
from shutil import copyfile
data_dir = 'path/to/dataset'
train_dir = 'path/to/train'
val_dir = 'path/to/val'
test_dir = 'path/to/test'
images = os.listdir(data_dir)
random.shuffle(images)
train_size = int(0.7 * len(images))
val_size = int(0.15 * len(images))
train_images = images[:train_size]
val_images = images[train_size:train_size + val_size]
test_images = images[train_size + val_size:]
# 将图像文件复制到相应的文件夹
for img in train_images:
copyfile(os.path.join(data_dir, img), os.path.join(train_dir, img))
for img in val_images:
copyfile(os.path.join(data_dir, img), os.path.join(val_dir, img))
for img in test_images:
copyfile(os.path.join(data_dir, img), os.path.join(test_dir, img))
标签文件准备: YOLO模型需要每张图像对应一个标签文件,包含了物体的类别和位置信息。准备好与图像文件对应的标签文件是关键的一步。
# 示例标签文件格式
# <object-class> <x_center> <y_center> <width> <height>
# 0 0.5 0.5 0.4 0.3
# 保存标签文件
def save_label_file(label_path, label_data):
with open(label_path, 'w') as file:
for line in label_data:
file.write(line + '\n')
模型训练: 在进行模型训练时,需要定义网络结构、损失函数和优化器,加载数据集并进行训练。
# 示例模型训练代码
model = YOLOv3(num_classes)
criterion = YOLOLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
for images, targets in dataloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
模型评估: 完成模型训练后,需要对模型进行评估以验证其性能。可以使用验证集进行预测并计算准确率、召回率等指标。
# 模型评估示例代码
model.eval()
with torch.no_grad():
for images, targets in val_dataloader:
outputs = model(images)
# 计算准确率等指标
模型部署和推理: 最后一步是将训练好的模型部署到实际应用中进行推理,检测野外有毒动植物并给出相应的预测结果。
# 模型推理示例代码
model.eval()
with torch.no_grad():
for images in test_dataloader:
outputs = model(images)
# 处理模型输出,进行物体检测和预测
通过以上步骤,可以完成一个YOLO项目的开发过程,从数据准备到模型训练再到部署和推理,实现对野外有毒动植物的检测和识别。
四、总结
数据集详细记录了多种野外动植物的毒性信息,涵盖了鳞伞菌、拟蝰蛇、风蕈、长柄鹅膏菌等物种。这些生物展现出独特的外观特征和各自不同的毒性程度。一些物种如美味黄孢菌和火锅菌可供食用,而其他如阿特罗克斯响尾蛇和红边墨头鱼则具有高度毒性。此数据集的信息对于户外爱好者具有重要意义,帮助他们识别和避免接触有害物种。通过这些记录,人们能更好地了解野外环境中潜在的危险,并促进对自然生态系统的保护和尊重。