关联查询进阶
自关联查询
1.使用AS关键字起别名
在SQL查询时,可以使用 AS 给表或者字段起别名,AS可以省略
如果别名和关键字相同,必须在别名两侧添加反引号``
2.多表关联查询-自关联查询
进行关联时,左表和右表是同一个表,这样的连接叫自关联。
-- 创建一个地区表
CREATE TABLE areas(
id VARCHAR(30) NOT NULL PRIMARY KEY,
title VARCHAR(30),
pid VARCHAR(30)
);
-- 示例1:查询'辽宁省'下的所有市的信息
-- 查询结果字段:
-- 市级地区id、市级地区名称、父级地区id、父级地区名称
SELECT
c.id,
c.title,
c.pid,
p.title
FROM areas c -- 理解为市表
JOIN areas p -- 理解为省表
ON c.pid = p.id
WHERE p.title = '辽宁省';
注意:
- 自关联时,需要给表起别名
- 自关联时,一定要把左右表当作不同的表来理解。
自关联查询的妙用:
-- 自关联的妙用
CREATE TABLE sales (
month INT NOT NULL, -- 月份
revenue DECIMAL(10, 2) -- 销售额
);
INSERT INTO sales
VALUES
(1, 1000),
(2, 800),
(3, 1200),
(4, 2000),
(5, 1800),
(6, 5000),
(7, 3000),
(8, 2500),
(9, 1600),
(10, 2200),
(11, 900),
(12, 4600);
-- 示例:查询每个月的销售额和前一个月的销售额的差值
-- 查询结果字段:
-- 月份、当前月销售额、前一个月销售额,当前月销售额和前一个月销售额的差
SELECT
a.month,
a.revenue, -- 当前月销售额
b.revenue, -- 上个月销售额
a.revenue - b.revenue -- 当前月销售额 和 上个月销售额 的差值
FROM sales a
LEFT JOIN sales b
ON a.month = b.month + 1
ORDER BY a.month;
子查询操作【重点】
在一个 SELECT 语句中,嵌入了另外一个 SELECT 语句,那么被嵌入的 SELECT 语句称之为子查询语句,外部那个SELECT 语句则称为主查询。
主查询和子查询的关系:
1)子查询是嵌入到主查询中
2)子查询是辅助主查询的,要么充当条件,要么充当数据源,要么充当查询字段
3)子查询是可以独立存在的语句,是一条完整的 SELECT 语句
注意:子查询作用数据源时,必须起别名
-- 示例1:查询当前商品大于平均价格的商品
-- ① 查询商品的平均价格
SELECT AVG(price) FROM products;
-- ② 查询所有商品
SELECT * FROM products;
-- ③ 将第①步的结果作为第②步的查询条件
SELECT
*
FROM products
WHERE price > (SELECT AVG(price) FROM products);
-- 示例2:查询不同类型商品的平均价格
-- 查询结果字段:
-- id(分类id)、cname(分类名称)、avg(分类商品平均价格)
-- 两种计算方式: 1.先关联,再计算; 2.先计算,再关联
-- 1.先关联,再计算
SELECT c.id,c.name,avg(price)
FROM category c JOIN products p ON p.category_id = c.id
GROUP BY category_id;
-- 2.先计算,再关联
SELECT c.id,c.name,avg_price
FROM test_db.category c
JOIN (SELECT category_id,avg(price) avg_price
FROM products GROUP BY 1) a
ON c.id=a.category_id;
-- 示例3:针对 students 表的数据,计算每个同学的Score分数和整体平均分数的差值
SELECT *,
(SELECT avg(score) FROM students) as avg_score,
Score - (SELECT avg(score) FROM students) as dif_score
FROM students;
窗口函数【重点】
窗口函数是 MySQL8.0 以后加入的功能,之前需要通过定义临时变量和大量的子查询才能完成的工作,使用窗口函数实现起来更加简洁高效。同时窗口函数也是面试的高频考点。
作用:查询每一行数据时,使用窗口函数针对这一行关联的一组数据进行处理,得出一个结果。
-- 示例1:针对 students 表的数据,计算每个同学的Score分数和整体平均分数的差值
SELECT *,
avg(Score)OVER () as avg_score,
Score - avg(Score)OVER () as dif_score
from students;
窗口函数的优点:
1)简单
- 窗口函数更易于使用。在上面的示例中,与使用聚合函数然后合并结果相比,使用窗口函数的 SQL 语句更加简单。
2)快速
- 这一点与上一点相关,使用窗口函数比使用替代方法要快得多。当你处理成百上千个千兆字节的数据时,这非常有用。
3)多功能性
- 最重要的是,窗口函数具有多种功能,比如:添加移动平均线、添加行号和滞后数据等等。
1.基本用法
over()关键字
-- 语法
SELECT
字段,
...,
<window function> OVER(...)
FROM 表名;
<window function>表示使用的窗口函数,窗口函数可以使用之前已经学过的聚合函数,比如COUNT()、SUM()、AVG()等,也可以是其他函数,比如 ranking 排序函数等,rank:排名序号可能重复不连续dense_rank:排名序号可能重复但连续row_number:排名序号连续不重复OVER(...)的作用就是设置每行数据关联的一组数据范围,OVER()时,每行关联的数据范围都是整张表的数据。OVER(PARTITION BY 字段)时,每一个关联的是一个分区。
典型应用场景:占比—每个值和整体之和的比值
1)场景1:计算每个值和整体平均值的差值
# 需求:计算每个学生的 Score 分数和所有学生整体平均分的差值。
# 查询结果字段:
# ID、Name、Gender、Score、AVG_Score(学生整体平均分)、difference(每位学生分数和整体平均分的差值)
SELECT ID,
Name,
Gender,
Score,
avg(Score)OVER () as avg_score,
Score - avg(Score)OVER () as dif_score
from students;
2)场景2:计算每个值占整体之和的占比
# 需求:计算每个学生的Score分数占所有学生分数之和的百分比
# 查询结果字段:
# ID、Name、Gender、Score、sum(所有学生分数之和)、ratio(每位学生分数占所有学生分数之和的百分比)
SELECT *,
sum(Score)OVER () as total_score,
concat( round(Score /sum(Score)OVER ()*100,2),'%') as ratio
from students;
OVER() 的作用:avg(max(final_price)) OVER () 为什么不加over()错误
- 当你加上
OVER()时,avg(max(final_price))被解释为窗口函数,而不是嵌套聚合函数。窗口函数允许对聚合结果进行计算,因此不会报错。
2.PARTITION BY分区
PARTITION BY分区:
# 基础语法
SELECT
字段,
...,
<window function> OVER(PARTITION BY 字段, ...)
FROM 表名;
PARTITION BY 列名, ...的作用是按照指定列的值对整张表的数据进行分区,OVER()中没有PARTITION BY时,整张表就是一个分区。- 分区之后,在处理每行数据时,
<window function>是作用在该行数据关联的分区上,不再是整张表上
典型应用场景:差值—每个值和整体平均值的差值
-- 需求:计算每个学生的 Score 分数和同性别学生平均分的差值
-- students查询结果字段:
-- ID、Name、Gender、Score、Avg(同性别学生的平均分)、difference(每位学生分数和同性别学生平均分的差值)
-- 方法1:窗口函数
SELECT *,
avg(Score)OVER (PARTITION BY Gender) as avg_score,
Score - avg(Score)OVER (PARTITION BY Gender) as dif_score
from students;
-- 方法2:子查询
select
s.*,s.Score - avg_score as dif_score
from (select Gender,avg(score) as avg_score FROM students GROUP BY 1) a
join students s
on a.Gender = s.Gender;
-- 需求:计算每人各科分数与对应科目最高分的占比
-- tb_score查询结果字段:
-- name、course、score、max(对应科目最高分数)、ratio(每人各科分数与对应科目最高分的占比)
select * from tb_score;
-- 方法1:窗口函数
select *,
max(score) OVER (PARTITION BY course) as max_score, score / max(score) OVER (PARTITION BY course) as ratio
from tb_score;
-- 方法2:子查询
SELECT b.*, a.max_score, b.score / a.max_score
from (SELECT course, max(score) as max_score FROM tb_score GROUP BY 1) a
join tb_score b
on a.course = b.course;
PARTITION BY与GROUP BY区别:
-
GROUP BY:
- 用于聚合数据,将分组后的数据汇总为单行。
- 通常与聚合函数(如
SUM、AVG、COUNT等)一起使用。 - 结果集中的每一行代表一个分组。
-
PARTITION BY:
- 用于窗口函数(如
ROW_NUMBER、RANK、SUM等),将数据分组但不聚合。 - 结果集中保留原始行数,窗口函数在每个分组内独立计算。
PARTITION BY与GROUP BY 何时使用?
使用 GROUP BY:
- 当你需要对数据进行分组并汇总时(如计算每个部门的总工资)。
使用 PARTITION BY:
- 当你需要保留原始数据行的同时,在分组内进行计算时(如计算每个部门的累计工资或排名)。
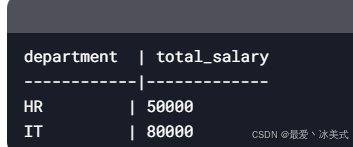
GROUP BY:
- 用于窗口函数(如
SELECT
department,
SUM(salary) AS total_salary
FROM employees
GROUP BY department;
每个部门返回一行,显示该部门的总工资。
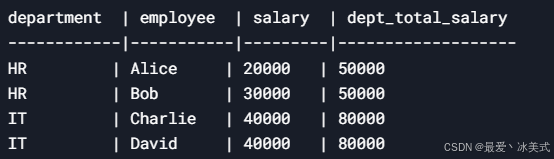
PARTITION BY:
SELECT
department,
employee,
salary,
SUM(salary) OVER (PARTITION BY department) AS dept_total_salary
FROM employees;
每个部门的每一行都保留,并显示该部门的总工资。
3.排名函数使用
不同的排名函数:
RANK():产生的排名序号 ,有并列的情况出现时序号重复不连续DENSE_RANK():产生的排名序号是连续的,有并列的情况时序号会重复ROW_NUMBER():返回连续唯一的行号,排名序号不会重复
SQL举例:
SELECT
name,
course,
score,
-- 可能重复不连续
RANK() OVER(ORDER BY score DESC) as `rank`,
-- 一定连续,可能重复
DENSE_RANK() OVER(ORDER BY score DESC) as `dense_rank`,
-- 一定连续,且不重复
ROW_NUMBER() OVER(ORDER BY score DESC) as `row_number`
FROM tb_score;

PARTITION BY和排序函数配合使用:
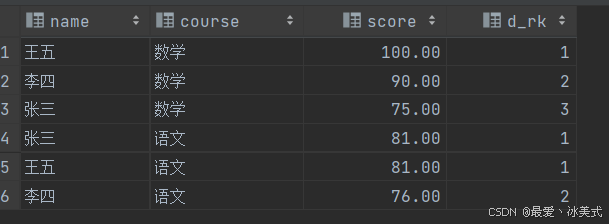
-- 需求:按照不同科目,对学生的分数从高到低进行排名(要求:连续可重复)
-- tb_score查询结果字段:
-- name、course、score、dense_rank(排名序号)
SELECT name,
course,
score,
-- 对每个分区内的每一行产生排名序号
DENSE_RANK() OVER(
-- 将整张表的数据按照科目进行分区
PARTITION BY course
-- 对每个分区内的数据按照score降序排列
ORDER BY score DESC
) as d_rk
from tb_score ;
排名函数典型应用:求指定排名的数据
1)场景:获取指定排名的数据
-- 需求:获取每个科目,排名第二的学生信息
-- 查询结果字段:
-- name、course、score
SELECT * FROM (
SELECT *,dense_rank() OVER (
PARTITION BY course ORDER BY score desc) as d_rk from tb_score
) a
WHERE a.d_rk = 2;
CTE公用表表达式
CTE(公用表表达式):Common Table Expresssion,类似于子查询充当数据源,就是把查询结果作为一个临时表,可以在 CTE 结果的基础上,进行进一步的查询操作。
注意:子查询充当条件和充当查询字段时,不能使用CTE代替。
-- 基础语法
# WITH some_name AS (
# -- your cte --
# -- 完整的 SQL 语句
# )
# SELECT
# ...
# FROM some_name;
- 需要给CTE起一个名字(上面的例子中使用了
some_name),具体的查询语句写在括号中 - 在括号后面,就可以通过
SELECT将CTE的结果当作一张表来使用 - 将CTE称为“内部查询”,其后的部分称为“外部查询”
- 需要先定义CTE,即在外部查询的
SELECT之前定义CTE
-- 需求:获取每个科目,排名第二的学生信息
-- 查询结果字段:
-- name、course、score
SELECT * FROM (
SELECT *,dense_rank() OVER (
PARTITION BY course
ORDER BY score desc) as d_rk from tb_score
) a
WHERE a.d_rk = 2;
WITH a AS (
SELECT *,dense_rank() OVER (
PARTITION BY course ORDER BY score desc) as d_rk from tb_score
)
SELECT * from a WHERE a.d_rk = 2;