其它窗口函数
NTILE排名函数
NTILE(X):将每个分区的数据均匀的分成 X 组,返回每行在分区内对应的组号。
需求: 根据浏览次数,取前四分之一的数据
-- auction
USE winfunc;
SELECT *
from (SELECT *, ntile(4) OVER (ORDER BY views desc) as nle from auction) a
WHERE a.nle = 1;
NTLE(x)排名函数的作用是什么?
- 将每个分区的数据均匀的分成 X 组,返回每行在分区内对应的组号。
- **注意:**如果每组的数量不能平均,前面某些组的数量会比后面多一条。
LAG与LEAD
LAG(字段, [N], [M]):返回分区中当前行前第N行的指定字段的内容,如果没有,默认返回M
LEAD(字段, [N], [M]):返回分区中当前行后第N行的指定字段的内容,如果没有,默认返回M
注意:M和N可以省略,N默认为1,M默认为NULL。
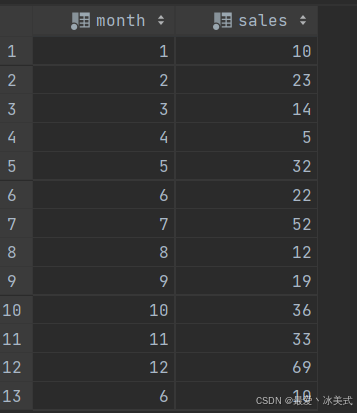
表tb_sales:
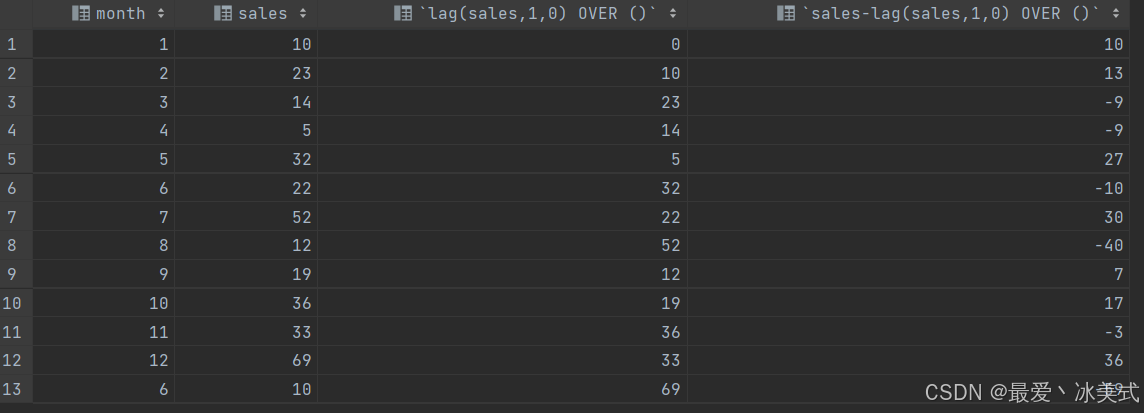
-- 示例1:计算每个月销量和上个月销量的差值
-- month、sales(当前销量)、pre_sales(上月销量)、difference(当月销量和上月销量的差值)
SELECT *,
lag(sales,1,0) OVER (),
sales-lag(sales,1,0) OVER ()
FROM tb_sales;
代码结果如图:
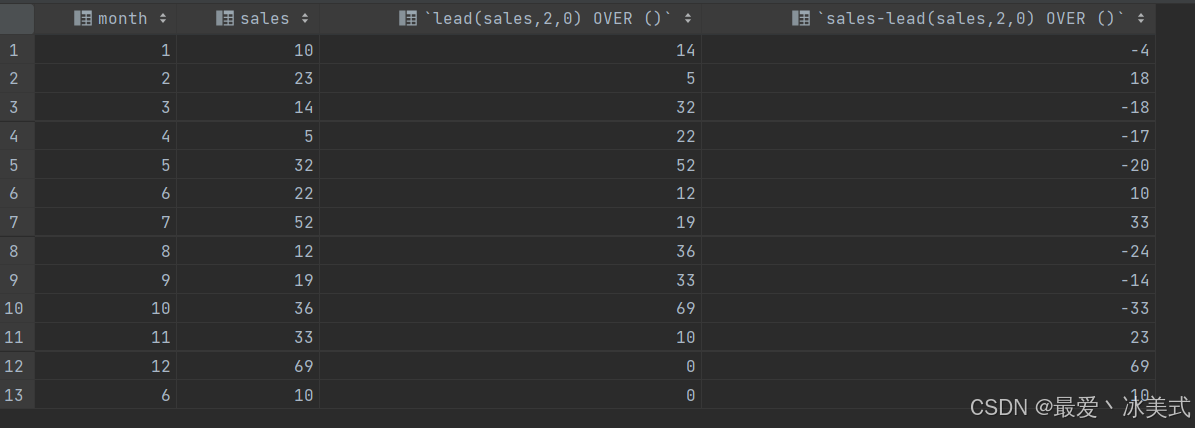
-- 示例2:计算每个月销量和下下个月销量的差值
-- month、sales(当前销量)、next_sales(下下月销量)、difference(当月销量和下下月销量的差值)
SELECT *,
lead(sales,2,0) OVER (),
sales-lead(sales,2,0) OVER ()
FROM tb_sales;
代码结果如图:
窗口函数-自定义window frame
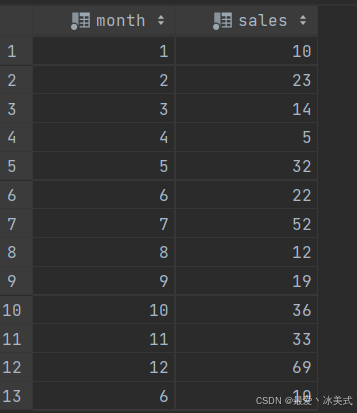
现有一张某年度的月销量信息表 tb_sales,数据如下:
如何计算截止到每个月的累计销量?1月:1月销量,2月:1月销量+2月销量,3月:1月销量+2月销量+3月销量,依次类推。
分区数据范围和window frame数据范围:
在使用窗口函数处理表中的每行数据时,每行数据关联的数据有两种:
1)每行数据关联的分区数据
- OVER()中什么都不写时,整张表默认是一个分区
- OVER(PARTITION BY 列名, …):整张表按照指定的列被进行了分区
2)每行数据关联的window frame数据
每行关联的window frame数据范围 <= 每行关联的分区数据范围window frame数据范围是分区数据范围的子集
已知的窗口函数中,有些窗口函数作用在分区上,有些函数作用在window frame上:
- 聚合函数(SUM、AVG、COUNT、MAX、MIN)作用于每行关联的window frame数据上
- 排名函数(RANK、DENSE_RANK、ROW_NUMBER)作用于每行关联的分区数据上
自定义 window frame 范围:ROWS和RANGE
自定义 window frame 范围有两种方式: ROWS 和 RANGE
SELECT
字段,
...,
<window function> OVER (
PARTITION BY 列名, ...
ORDER BY 列名, ...
[ROWS|RANGE] BETWEEN 上限 AND 下限
)
FROM 表名;
PARTITION BY 列名, ...:按照指定的列,对整张表的数据进行分区ORDER BY 列名, ...:按照指定的列,对每个分区内的数据进行排序[ROWS|RANGE] BETWEEN 上限 AND 下限:在排序之后的分区数据内,设置每行关联的window frame数据范围
上限和下限的设置:
UNBOUNDED PRECEDING:对上限无限制PRECEDING: 当前行之前的 n 行 ( n 表示具体数字如:5PRECEDING)CURRENT ROW:仅当前行FOLLOWING:当前行之后的 n 行 ( n 表示具体数字如:5FOLLOWING)UNBOUNDED FOLLOWING:对下限无限制- 注意:上限需要在下限之前,比如:
ROWS BETWEEN CURRENT ROW AND UNBOUNDED PRECEDING是错误的
应用实例:当排序列的值连续且不重复时,使用ROWS和RANGE效果一样
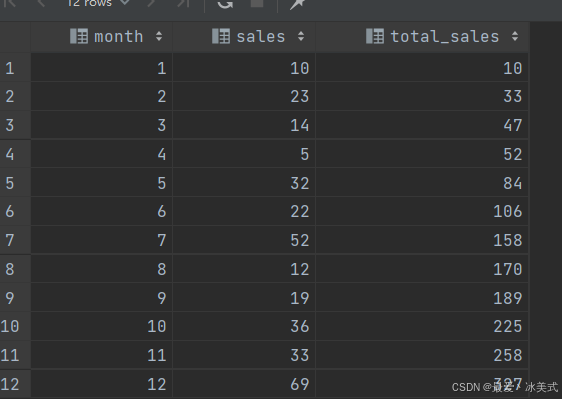
-- 示例1
-- 需求:计算截止到每个月的累计销量。1月:1月销量,2月:1月销量+2月销量,3月:1月销量+2月销量+3月销量,依次类推
-- 查询结果字段:
-- month(月份)、sales(当月销量)、running_total(截止当月累计销量)
SELECT *,
sum(sales) OVER (ORDER BY month
# RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as total_sales
FROM tb_sales;
结果:
window frame定义的简略写法:
自定义 window frame 的边界时,如果使用了CURRENT ROW作为上边界或者下边界,可以使用如下简略写法:
ROWS UNBOUNDED PRECEDING等价于BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWROWS n PRECEDING等价于BETWEEN n PRECEDING AND CURRENT ROWROWS CURRENT ROW等价于BETWEEN CURRENT ROW AND CURRENT ROW- 注意,简略写法不适合
FOLLOWING的情况
window frame设置的语法是什么?
ROWS BETWEEN上限AND下限RANGEBETWEEN上限AND下限- 注意:上限需要在下限之前
ROWS和RANGE的区别:
ROWS和RANGE关键字,都可以用来自定义 windowframe 范围:
ROWS BETWEEN 上限 AND 下限
RANGE BETWEEN 上限 AND 下限
但两者区别如下:
ROWS是根据分区数据排序之后,每一行的行号 确定每行关联的window frame范围的
CURRENT ROW:仅代表当前行
# 假设某一行数据的 行号 为5,ROWS自定义window frame如下:
ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING
# 则这一行关联的window frame是:5-2 <= 行号 <= 5+2 的数据
RANGE是根据分区数据排序之后,每一行的排序列的值确实每行关联的window frame范围的
CURRENT ROW: 代表和当前行排序列的值相同的所有行
# 假设某一行排序列的值为5,RNAGE自定义window frame如下:
RANGE BETWEEN 2 PRECEDING AND 2 FOLLOWING
# 则这一行关联的window frame是:5-2 <= 排序列的值 <= 5+2 的数据
代码示例:
表tb_sales,数据如下:
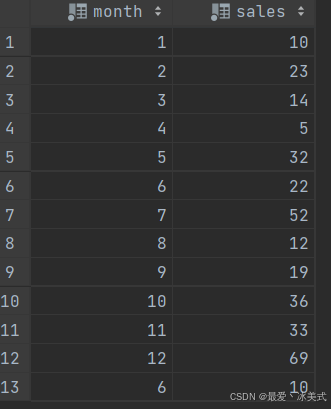
-- 需求:计算每3个月(前1个月、当前月、后1一个月)的累计销量。1月:1月销量+2月销量,2月:1月销量+2月销量+3月销量,3月:2月销量+3月销量+4月销量,依次类推
-- 查询结果字段:
-- month(月份)、sales(当月销量)、running_total(每3个月累计销量)
SELECT *,
sum(sales) OVER (ORDER BY month
# RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING # 六月加一块
rows BETWEEN 1 PRECEDING AND 1 FOLLOWING # 两个六月算不同的月份
) as total_sales
FROM tb_sales;
结果如下:
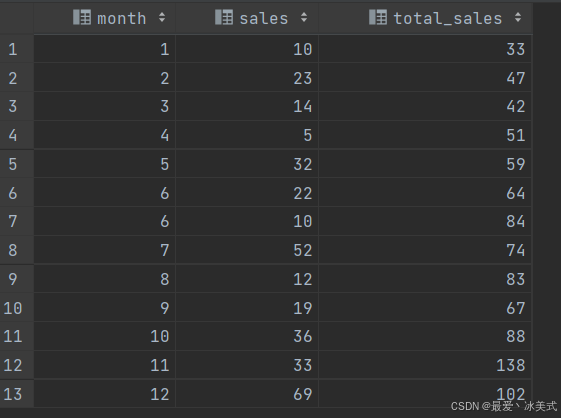
SELECT *,
sum(sales) OVER (ORDER BY month
RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING # 六月加一块
# rows BETWEEN 1 PRECEDING AND 1 FOLLOWING # 两个六月算不同的月份
) as total_sales
FROM tb_sales;
结果如下:
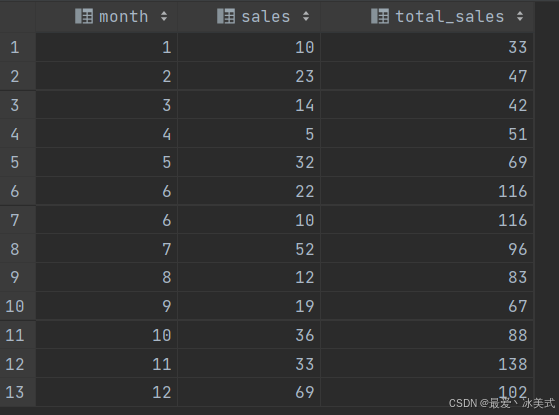
当排序列的值不是数字时,不能使用RANGE
默认的window frame
在 OVER 中只要添加了 ORDER BY,在没有写ROWS或RANGE的情况下,会有一个默认的 window frame范围:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
-- 需求:计算截止到每个月的累计销量。1月:1月销量,2月:1月销量+2月销量,3月:1月销量+2月销量+3月销量,依次类推
SELECT
month,
sales,
SUM(sales) OVER(
# 按照 month 对每个分区(注:此处就一个分区->整张表)数据进行排序
ORDER BY month
# OVER 中添加了 ORDER BY 之后,默认的 window frame 范围
# RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS total_sales
FROM tb_sales;
PARTITION BY和自定义window frame:
-- 需求:计算每个商店截止到每个月的累计销售额。1月:1月销量,2月:1月销量+2月销量,3月:1月销量+2月销量+3月销量,依次类推
-- 查询结果字段:
-- store_id(商店id)、month(月份)、revenue(当月销售额)、sum(截止当月累计销售额)
SELECT *,
sum(revenue) OVER (
# 按照 store_id 对整张表的数据进行分区
PARTITION BY store_id
# 按照 month 对每个分区内的数据排序
ORDER BY month
# 设置 每行关联的分区 window frame 范围
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as total_revenue
FROM tb_revenue;
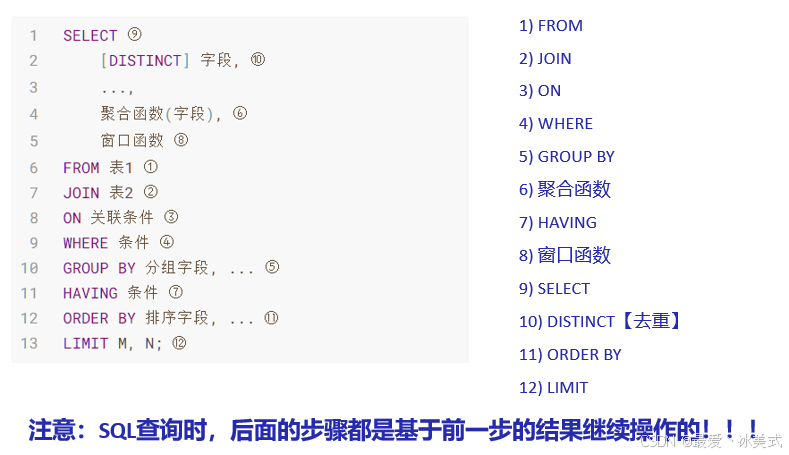
SQL语句的执行顺序
SQL语句的执行顺序如下:
FROM > JOIN > ON > WHERE > GROUP BY > 聚合函数 > HAVING > 窗口函数 > SELECT > DISTINCT > ORDER BY > LIMIT
不能使用窗口函数的3种情况
1.不能在WHERE子句中使用窗口函数
-- 需求:查询出所有拍卖中,最终成交价格高于平均成交价格的拍卖
-- 查询结果字段:
-- id、final_price(最终成交价格)
# 错误示例
SELECT id,
final_price
FROM auction
WHERE final_price > AVG(final_price) OVER ();
# 正确写法(子查询)
SELECT avg(final_price)
FROM auction;
SELECT *
FROM auction
WHERE final_price>(SELECT avg(final_price)
FROM auction);
# CTE表达式
WITH a AS (SELECT avg(final_price) avg_final_price
FROM auction)
SELECT * FROM auction cross JOIN a
WHERE final_price>a.avg_final_price;
WITH a AS (SELECT *,
avg(final_price) over() avg_final_price
FROM auction)
SELECT * FROM a
WHERE final_price>avg_final_price;
2.不能在 HAVING 子句中使用窗口函数
-- 需求:查询出国内平均成交价格高于所有拍卖平均成交价格的国家
-- 查询结果字段:
-- country(国家)、avg(该国家所有拍卖的平均成交价)
# 错误示例
SELECT country,
AVG(final_price) AS `avg`
FROM auction
GROUP BY country
HAVING AVG(final_price) > AVG(final_price) OVER ();
# 正确写法(子查询)
SELECT avg(final_price) from auction;
SELECT country,
avg(final_price) avg
FROM auction
GROUP BY country
HAVING avg>(SELECT avg(final_price) from auction);
3.不能在 GROUP BY子句中使用窗口函数
-- 需求:将所有的拍卖信息按照浏览次数排序,并均匀分成4组,然后计算每组的最小和最大浏览量
-- 查询结果字段:
-- quartile(分组序号)、min_views(当前组最小浏览量)、max_view(当前组最大浏览量)
# 错误示例
SELECT NTILE(4) OVER (ORDER BY views DESC) AS `quartile`,
MIN(views) AS `min_views`,
MAX(views) AS `max_views`
FROM auction
GROUP BY NTILE(4) OVER (ORDER BY views DESC);
# 正确实现(子查询)
SELECT *,
ntile(4) OVER (ORDER BY views DESC ) as nle
FROM auction;
SELECT nle,
min(views),
max(views)
FROM (SELECT *,
ntile(4) OVER (ORDER BY views DESC ) as nle
FROM auction) a
GROUP BY nle
;
# CTE公用表表达式
WITH a as(
SELECT *,
ntile(4) OVER (ORDER BY views DESC ) as nle
FROM auction
)
SELECT nle,min(views),max(views) FROM a GROUP BY nle;
够使用窗口函数的两种情况
1.可以在SELECT和ORDER BY中使用窗口函数
- 需求:将所有的拍卖按照浏览量降序排列,并均分成4组,按照每组编号降序排列
-- 查询结果字段:
-- id(拍卖ID)、views(浏览量)、quartile(分组编号)
SELECT *,
ntile(4) OVER (ORDER BY views DESC ) as nle
FROM auction
ORDER BY nle DESC ;
SELECT *
FROM (
SELECT *,
ntile(4) OVER (ORDER BY views DESC ) as nle
FROM auction
) a
ORDER BY nle DESC
;
2.难点:GROUP BY和窗口函数配合使用
GROUP BY和窗口函数配合使用时,窗口函数处理的分组聚合之后的结果,不再是原始的表数据。
-- 练习1
-- 需求:将拍卖数据按国家分组,返回如下信息
-- 查询结果字段:
-- country(国家)、min(每组最少参与人数)、avg(所有组最少参与人数的平均值)
SELECT country,
min(participants),
avg(min(participants)) OVER () avg
FROM auction
GROUP BY country;
-- 排序函数使用聚合函数的结果
-- 练习2
-- 需求:按国家进行分组,计算了每个国家的拍卖次数,再根据拍卖次数对国家进行排名
-- 查询结果字段:
-- country(国家)、count(该国家的拍卖次数)、rank(按拍卖次数的排名)
SELECT country,count(*) FROM auction GROUP BY country;
-- 对GROUP BY分组后的数据使用PARTITION BY
-- 我们可以对GROUP BY分组后的数据进一步分区(PARTITION BY) ,再次强调,使用GROUP BY 之后使用窗口函数,只能处理分组之后的数据,而不是处理原始数据
SELECT country,
count(*) ,
rank() OVER (ORDER BY count(*) ) `rank`
FROM auction
GROUP BY country;
-- 练习3
-- 需求:将所有的数据按照国家和拍卖结束时间分组,返回如下信息
-- 查询结果字段:
-- country(国家)、ended(拍卖结束时间)、count(该分组拍卖数量)、country_count(该国家拍卖数量)
SELECT country,ended ,count(*),
sum(count(*)) OVER (PARTITION BY country)
FROM auction
GROUP BY 1,2;
分组后的数据进一步分区(PARTITION BY) ,再次强调,使用GROUP BY 之后使用窗口函数,只能处理分组之后的数据,而不是处理原始数据
SELECT country,
count(*) ,
rank() OVER (ORDER BY count(*) ) `rank`
FROM auction
GROUP BY country;
-- 练习3
-- 需求:将所有的数据按照国家和拍卖结束时间分组,返回如下信息
-- 查询结果字段:
-- country(国家)、ended(拍卖结束时间)、count(该分组拍卖数量)、country_count(该国家拍卖数量)
SELECT country,ended ,count(*),
sum(count(*)) OVER (PARTITION BY country)
FROM auction
GROUP BY 1,2;