在当今数字化时代,人工智能已成为推动各领域发展的核心力量,而神经网络作为人工智能的基石,扮演着至关重要的角色。其本质是通过一个复杂的数学函数,将输入转换为期望的输出。在训练过程中,我们通过调整神经网络中各层的参数,逐步提高模型的预测能力,从而解决实际问题。
本文将通过一个简单的文本处理示例,讲解神经网络的基本构成和模型训练的过程。
1. Word Embedding(词嵌入)
在文本处理任务中,首先需要将文本转换为数值形式,才能供神经网络进行计算。
假设我们的任务是判断字符串中是否包含字母“a”。如果包含,则神经网络的输出结果大于0.5;如果不包含,则输出小于0.5。
问题: 直接将字母映射为数字,比如将a映射为1,b映射为2,c映射为3,虽然这样可以数值化字符,但这种映射方式有一个明显的问题——字母之间的数字映射具有大小关系,这显然不符合语言的特性。
在自然语言中,字母、词汇之间并没有天然的大小顺序关系。因此,简单的数字映射无法准确表达语言的语义和结构信息。
解决方案: 为了避免这种问题,我们使用词嵌入(Word Embedding)。通过这种方式,每个字符(或词)都可以用一个向量表示,这个向量通常是高维的,且是通过学习得到的。例如,我们可以为字母“a”表示一个向量:a = [1.234, 3.234, 4.234231, …],假设向量的维度为5。这样每个字母就被表示为一个5维的向量。

假设我们有一个字符串"abcd",那么它就可以转换为一个4×5的矩阵,其中每行表示一个字符的词向量。词嵌入层是神经网络中的第一层,它将文本数据转换为神经网络可以处理的数值形式。
词嵌入的核心思想是将每个词映射到一个高维的连续向量空间中,在这个空间里,语义相近的词会有相似的向量表示。例如,“国王”和“王后”这两个词在语义上有相似之处,因此它们的词向量在空间中也会比较接近。
词嵌入向量可以通过以下两种方式获得:
- 使用预训练好的词向量:如Word2Vec、GloVe等,这些预训练的词向量已经学习到大量的语言知识和语义信息,可以直接应用到我们的任务中,节省训练时间和计算资源。
- 随机初始化并训练:在训练过程中,随机初始化词向量,然后通过反向传播算法不断调整这些向量,使其能更好地服务于当前的任务。
2. 池化层
当文本数据被转换为词向量矩阵后,接下来的任务是降低运算量、提高计算速度。为此,我们通常会对矩阵进行池化操作。池化操作通过对矩阵的每一列(或每一小区域)进行聚合(如求平均或最大值),减少数据的维度。
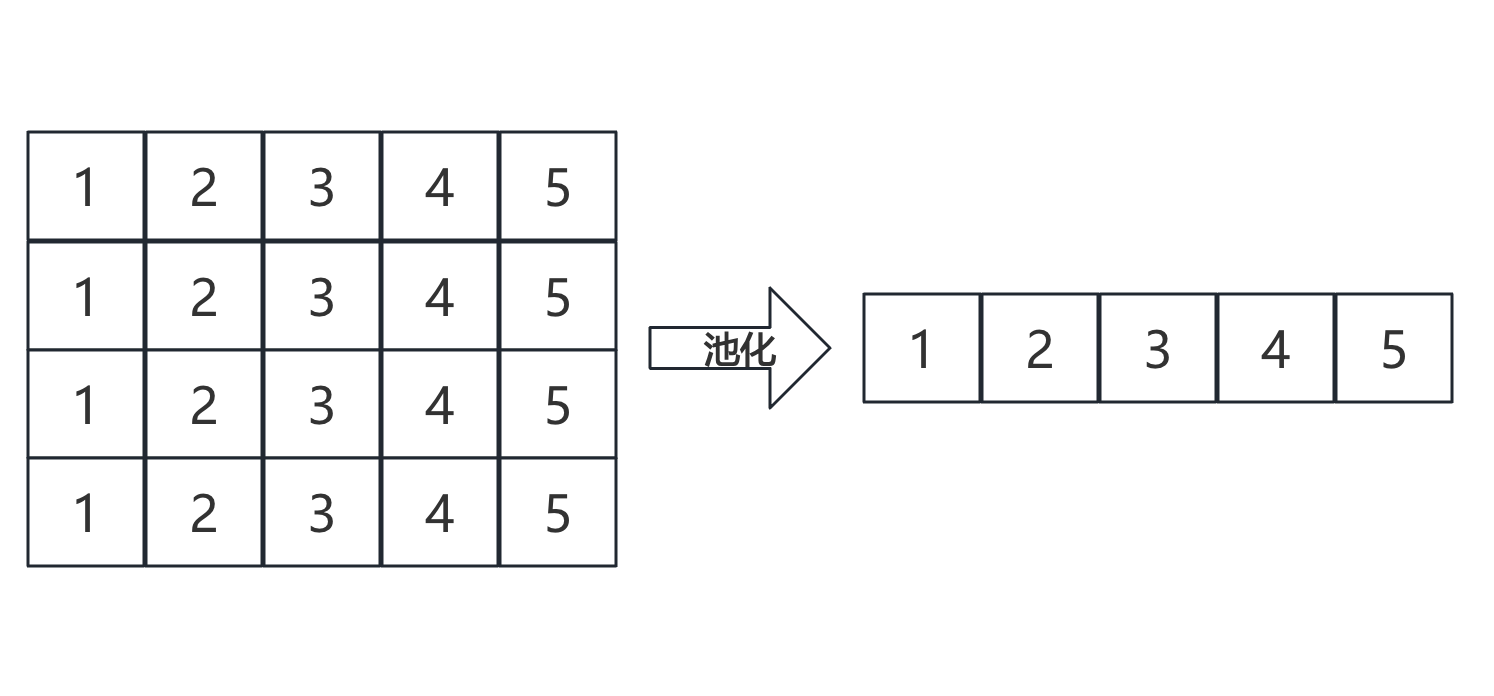
例如,对于一个4×5的矩阵,我们可以对每一列进行求平均值操作,最终得到一个1×5的向量,这个过程叫做池化(Pooling)。池化的常见方法有:
- 最大池化:取每一小区域的最大值。
- 均值池化:取每一小区域的平均值。
池化不仅能降低计算复杂度,还能提高模型的鲁棒性,减少过拟合的风险。
3. 网络层
池化后的结果将传递到神经网络的后续层进行计算。神经网络通常由多个**全连接层(Fully Connected Layer)**组成,其中每一层的神经元都与上一层的所有神经元相连接。该过程通过一系列加权和偏置的计算,将输入信息逐层处理,最终得到输出。
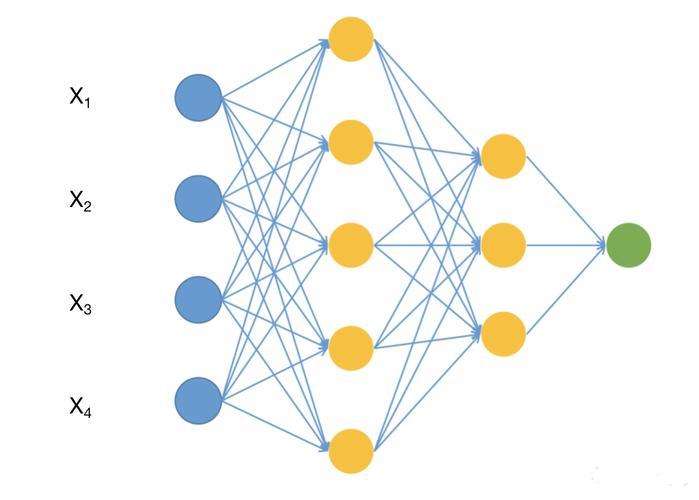
在分类任务中,输出通常是一个表示不同类别概率的向量。神经网络的目标是通过调整每一层的权重,使得最终的输出尽可能接近实际标签
4. 前向传播
在神经网络中,前向传播指的是从输入层到输出层的计算过程。在前向传播中,每一层的计算包括两个重要步骤:
- 加权和:输入与相应的权重相乘并求和。
- 非线性变换:通过激活函数(如ReLU、Sigmoid等)对加权和结果进行非线性变换。
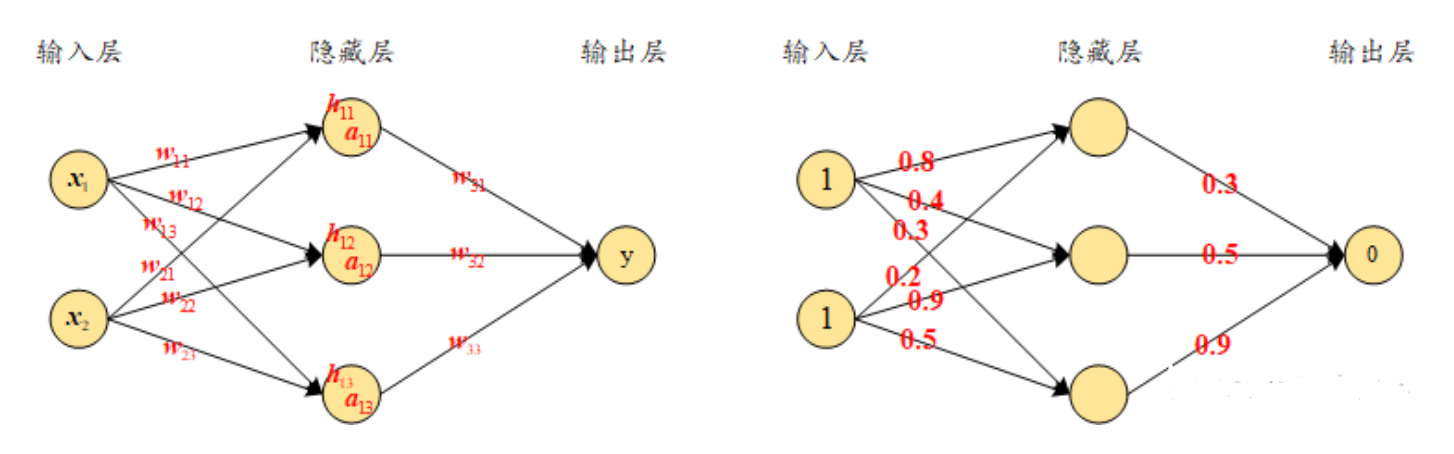
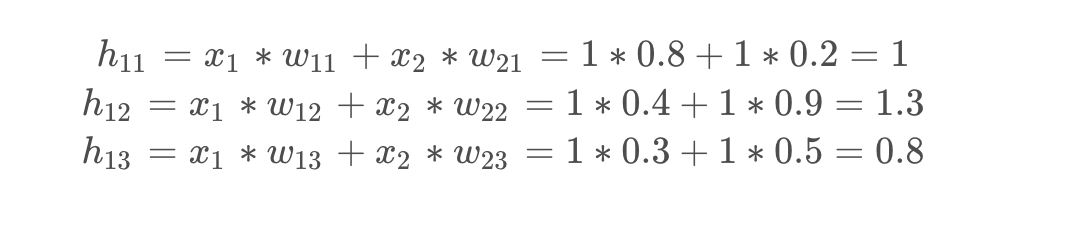
前向传播的核心目标是得到一个预测结果,并将其与实际标签进行对比,从而计算损失值。
5. 反向传播
在得到输出结果后,我们需要计算损失值,以评估神经网络的表现。常见的损失函数之一是均方误差(MSE),它衡量了预测值与真实值之间的差距。损失函数公式如下:
L = 1 m ∑ i = 1 m ( y i − y i ^ ) 2 L = \frac{1}{m} \sum_{i=1}^{m} (y_i - \hat{y_i})^2 L=m1i=1∑m(yi−yi^)2
其中,m是样本数,y_i为实际标签,ŷ_i为神经网络的预测输出。
反向传播算法通过计算损失函数对每个权重的梯度,并根据梯度来调整网络中的权重。通过梯度下降算法,神经网络根据计算得到的梯度信息,逐步调整权重,使得损失值最小化。反向传播的核心思想是:根据输出与实际值的误差,逐步调整网络的参数,以减少预测误差。
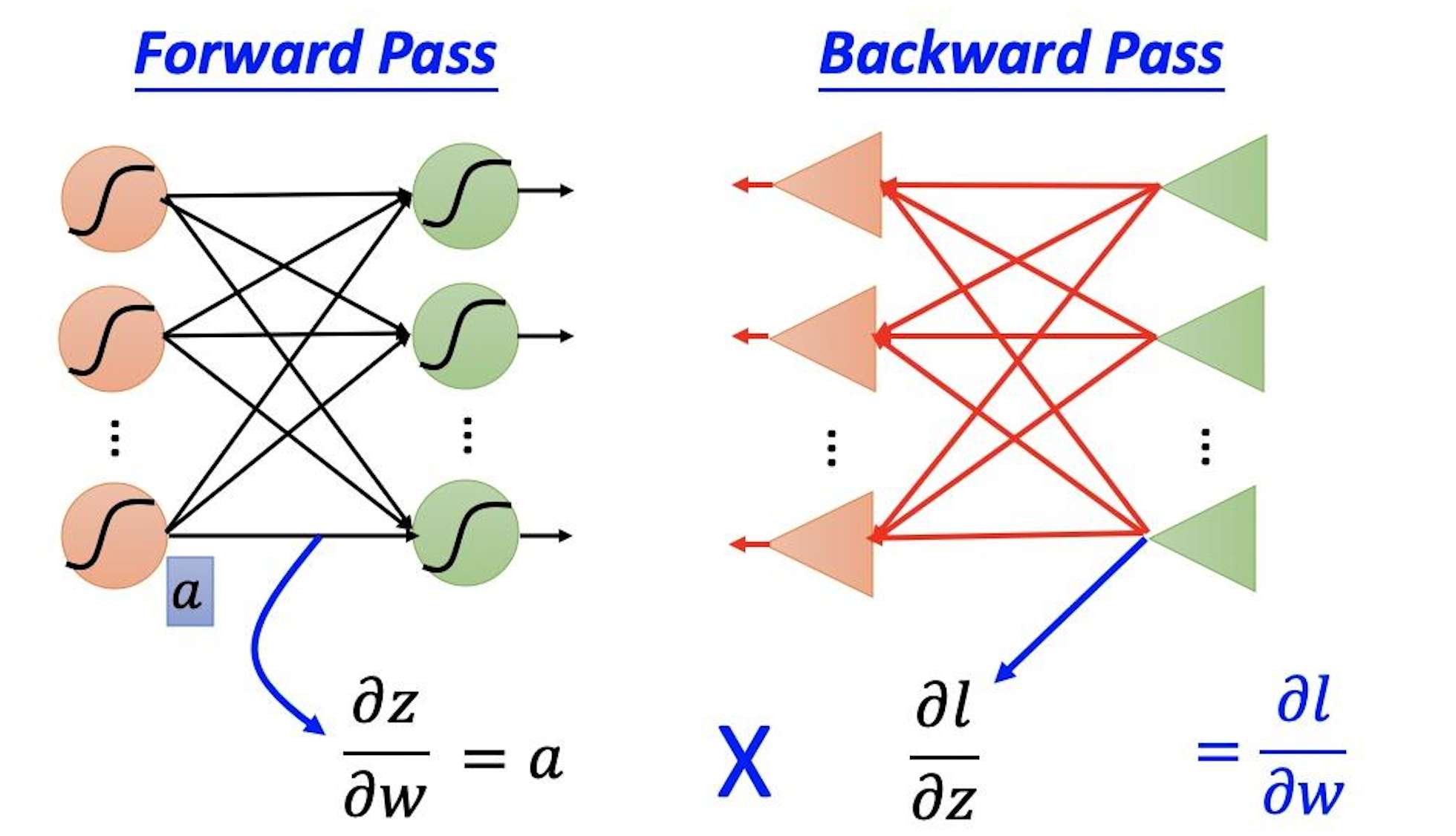
反向传播的过程就像是在一个复杂的地形中寻找最低点,梯度就像是告诉我们应该往哪个方向走,才能更快地到达最低点。
总结
神经网络的训练过程实际上是通过重复前向传播和反向传播这两个关键步骤来调整神经网络中的权重。
在前向传播中,数据从输入层经过各个隐藏层逐层计算,最终得到输出结果;在反向传播中,计算损失值并反向传播回每一层,计算每个权重的梯度,最终更新权重。通过不断地迭代训练,神经网络能够从数据中学习模式和规律,提高预测精度。

感谢各位读者阅读本文,希望通过这篇文章能让大家对神经网络和模型训练过程有更深入的了解。如果有任何疑问或建议,欢迎在评论区留言,我们一起讨论。