目录
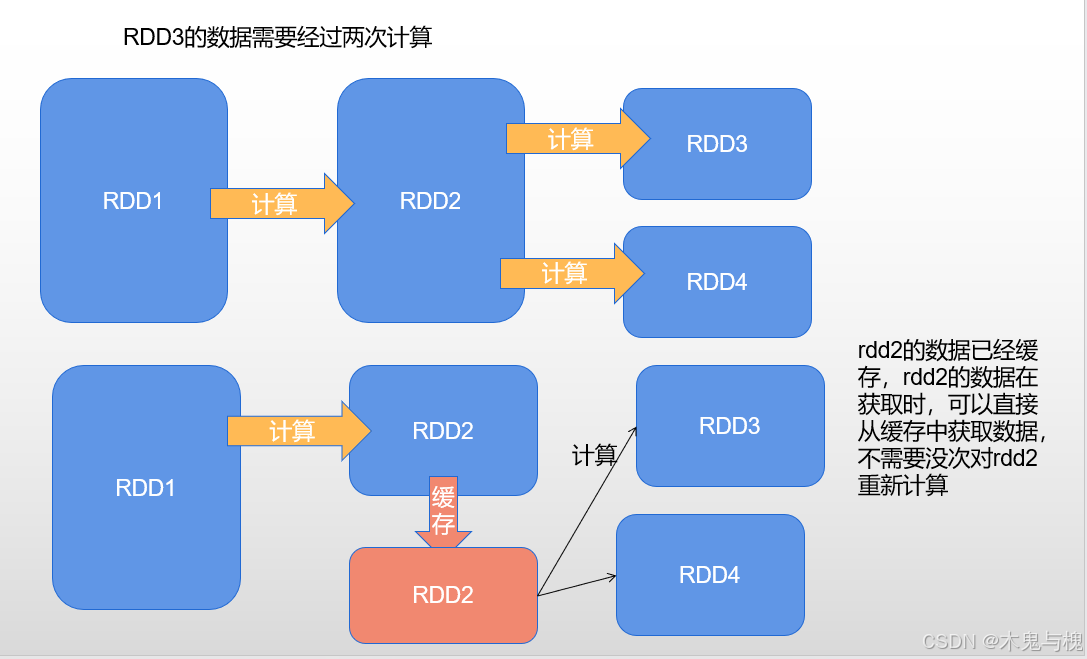
如下图,如果不适用缓存,rdd3的数据需要经过两次计算,而每次计算也是在内存中计算,很消耗内存,而使用了缓存,可以直接从缓存中直接获取数据,不需要每次对rdd2进行计算
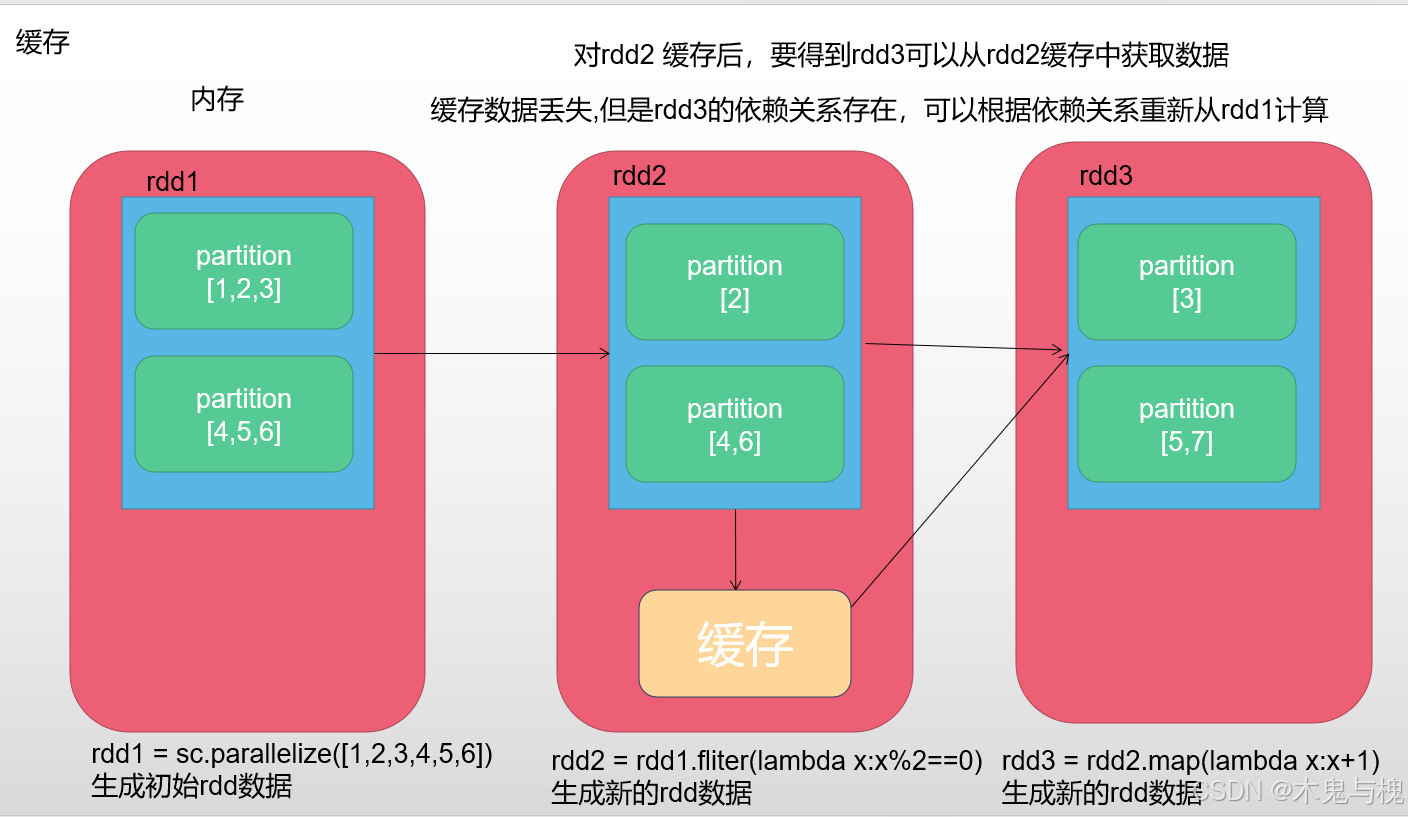
缓存和checkpoint也叫作rdd的持久化,将rdd的数据存储在指定位置
作用:
1-计算容错
2-提升计算速度
缓存使用
缓存是将数据存储在内存或者磁盘上,缓存的特点时,计算结束,缓存自动清空.默认是缓存到内存上.
StorageLevel.DISK_ONLY # 将数据缓存到磁盘上
StorageLevel.DISK_ONLY_2 # 将数据缓存到磁盘上 保存两份
StorageLevel.DISK_ONLY_3 # 将数据缓存到磁盘上 保存三份
StorageLevel.MEMORY_ONLY # 将数据缓存到内存 默认
StorageLevel.MEMORY_ONLY_2 # 将数据缓存到内存 保存两份
StorageLevel.MEMORY_AND_DISK # 将数据缓存到内存和磁盘 优先将数据缓存到内存上,内存不足可以缓存到磁盘
StorageLevel.MEMORY_AND_DISK_2 = # 将数据缓存到内存和磁盘
StorageLevel.OFF_HEAP # 不使用 缓存在系统管理的内存上 heap jvm的java虚拟机中的heap
StorageLevel.MEMORY_AND_DISK_ESER # 将数据缓存到内存和磁盘 序列化操作,按照二进制存储,节省空间
persist使用该方法cache 内部调用persist
手动释放 unpersist
# storageLevel 修改缓存级别
rdd_groupby.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)
对列表单词进行统计
from pyspark import SparkContext
from pyspark.storagelevel import StorageLevel
sc = SparkContext()
rdd = sc.parallelize(['a','b','c','a','a','b'])
# rdd数据转换
rdd_kv = rdd.map(lambda x : (x,1))
# 进行缓存
rdd_kv.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)
# 触发缓存
rdd_kv.collect()
# 分组处理
rdd_group = rdd_kv.groupByKey()
# 聚合处理
rdd_reduce = rdd_kv.reduceByKey(lambda x,y: x+y)
# 查看结果
res = rdd_group.collect()
print(res)
res1 = rdd_reduce.collect()
print(res1)
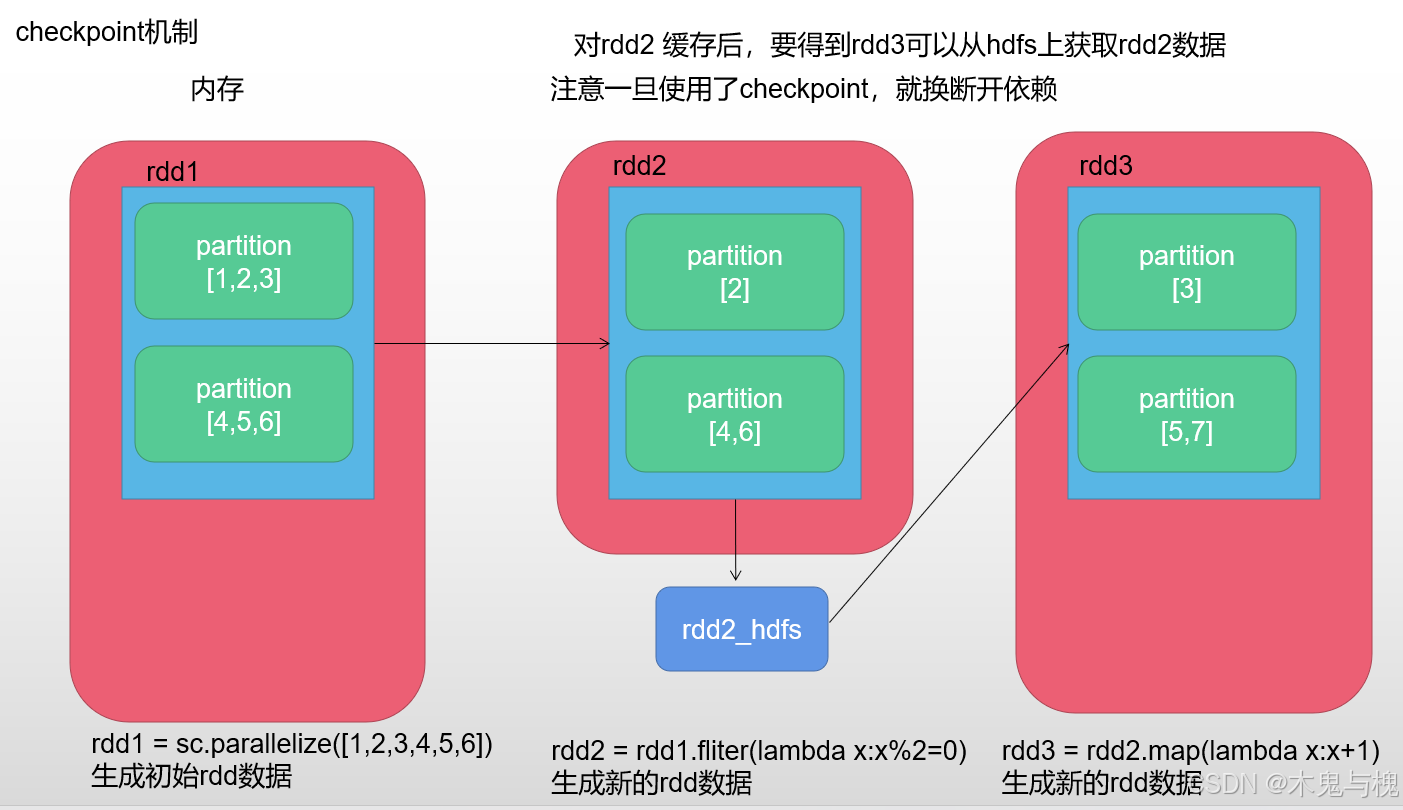
checkpoint使用
也是将中间rdd数据存储起来,但是存储的位置实时分布式存储系统,可以进行永久保存,程序结束不会释放
如果需要删除就在hdfs上删除对应的目录文件
- # 使用sc对象指定checkpoint存储位置
- sc.setCheckpointDir('hdfs://node1:8020/data/checkpoint')
- # 进行checkpoint
- rdd_kv.checkpoint()
对列表单词进行统计,并存储到hdfs上
from pyspark import SparkContext
from pyspark.storagelevel import StorageLevel
sc = SparkContext()
# 使用sc对象指定checkpoint存储位置
sc.setCheckpointDir('hdfs://node1:8020/data/checkpoint')
rdd = sc.parallelize(['a','b','c','a','a','b'])
# rdd数据转换
rdd_kv = rdd.map(lambda x : (x,1))
# 进行checkpoint
rdd_kv.checkpoint()
# 需要使用action触发缓存checkpoint
print(rdd_kv.glom().collect())
# 分组处理
rdd_group = rdd_kv.groupByKey()
# 聚合处理
rdd_reduce = rdd_kv.reduceByKey(lambda x,y: x+y)
# 查看结果
res = rdd_group.collect()
print(res)
res1 = rdd_reduce.collect()
print(res1)
两者的区别
- 生命周期
- 缓存数据, 程序计算结束后自动删除
- checkpoint 程序结束,数据依然保留在hdfs
- 存储位置
- 缓存 优先存储在内存上,也可以选在存储在本地磁盘,是在计算任务所在的内存和磁盘上
- checkpoint 存储在hdfs上
- 依赖关系
- 缓存数据后,会
保留rdd之间依赖关系 缓存时临时存储,数据可能会丢失,需要保留依赖,当缓存丢失后可以按照依赖重新计算 - checkpoint,数据存储后会
断开依赖, 数据保存在hdfs,hdfs三副本可以保证数据不丢失,所以没有比较保留依赖关系
- 缓存数据后,会