1. DOM型XSS
1.1 概念
DOM全称Document Object Model,使用DOM可以使程序和脚本能够动态访问和更新文档的内容、结构及样式。DOM型XSS其实是一种特殊类型的反射型XSS,它是基于DOM文档对象模型的一种漏洞。HTML的标签都是节点,而这些节点组成了DOM的整体结构——节点树。通过HTML DOM,树中的所有结点均可通过JavaScript进行访问。所有HTML元素(节点)均可被修改,也可以创建或删除节点。HTML DOM树结构如下:
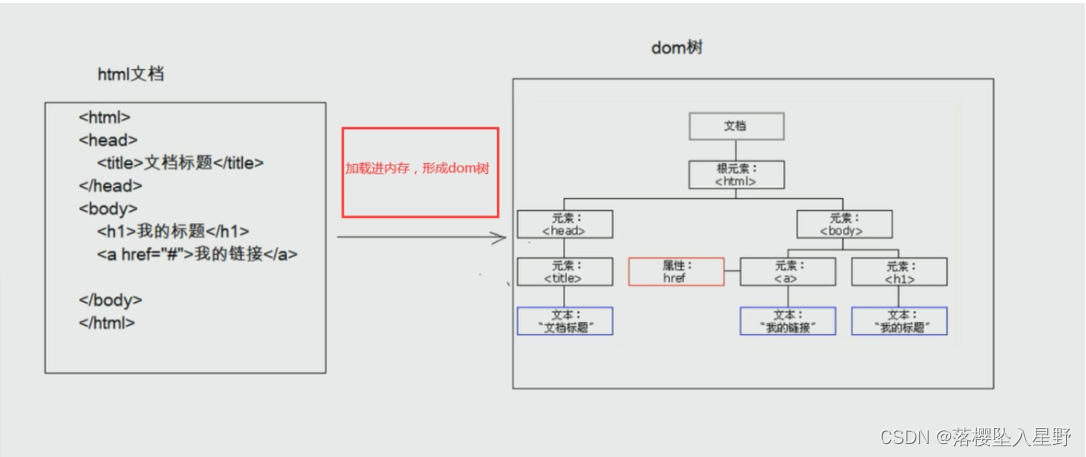
在网站页面中有许多元素,当页面到达浏览器时,浏览器会为页面创建一个项级的Document object文档对象,接着生成各个子文档对象,每个页面元素对应一个文档对象,每个文档对象包含属性、方法和事件。可以通过JS脚本对文档对象进行编辑,从而修改页面的元素。也就是说,客户端的脚本程序可以通过DOM动态修改页面内容,从客户端获取DOM中的数据并在本地执行。由于DOM是在客户端修改节点的,所以基于DOM型的XSS漏洞不需要与服务器端交互,它只发生在客户端处理数据的阶段。
1.2 常见的攻击方式
1、DOM属性污染(Property Pollution):攻击者通过修改或污染页面上的DOM属性值,利用特殊字符或恶意代码注入来触发漏洞。
2、DOM操纵:攻击者可以通过操纵DOM元素,修改页面内容,或者通过动态修改URL片段(fragment)来注入恶意代码。
3、事件处理器的劫持:攻击者可以利用事件处理器(比如onclick、onmouseover等)来执行恶意代码。如果网站未对用户输入进行适当的过滤和转义,攻击者可以注入恶意代码并在用户点击等操作时触发。
4、客户端重定向与操作:攻击者通过修改客户端的重定向行为,让用户访问恶意网站,或者修改浏览器的历史记录等来达到攻击目的。
1.3 常见攻击流程
- 用户提交js恶意代码 ==> 交给后端进行处理(php) ===> 后端将带有恶意代码的数据输出到页面上 ===> 导致恶意代码被执行
- 经过了后端的处理
** 必须要有一个后端的输出 **
但是纯在一种可能,可以不经过后端处理,直接输出到页面上
举个例子:
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<form action="dom.html" method="get">
<input type="text" name="keywords">
<input type="submit">
</form>
<p>搜索记录:<span id="history"></span></p>
</body>
<script>
var url=document.location.href;
// console.log(url);
var index=url.indexOf("keywords=");
// console.log(index);
var value=unescape(url.substring(index+"keywords=".length));
// console.log(value)
var span=document.getElementById("history");
span.innerHTML=value;
</script>
</html>
1.4 反射型和DOM型的区别
- 反射型经过了后端处理
- dom型,完全不经过后端
- 本质上dom型是一种特殊的反射型
存储型,将输入的内容写入到了数据库里面,然后输出的时候去调用库里面的内容
1.5 js操作DOM的简单示例
1、操作dom的方法
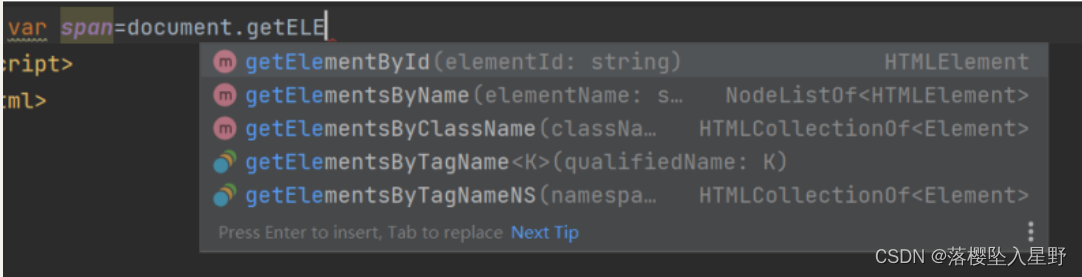
2、找到对象之后,就要操作对象:操作属性 或者 内容
span.innerHTML="内容";
span.innerText="内容";
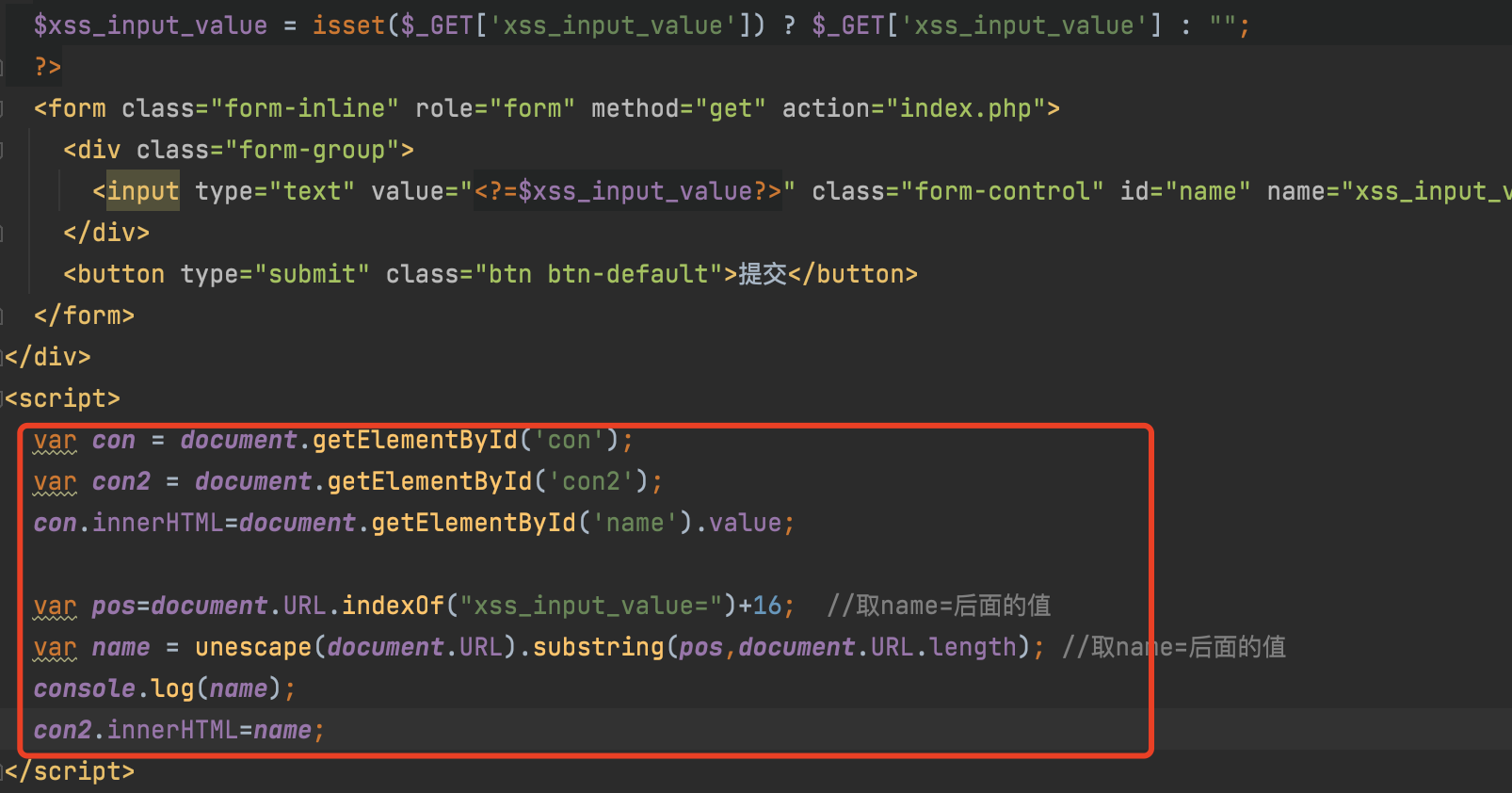
1.6 代码分析
2. XSS构造技巧
2.1常用测试语句
1、经典的脚本注入
<script>alert(1)</script>
2、利用图片的错误事件
<img src=x onerror=alert(1)>
3、利用SVG的加载事件
<svg onload=alert(1)>
4、通过链接执行JavaScript
<a href=javascript:alert(1)>
5、利用Image标签的javascript伪协议
<img src="javascript:alert(1)">
.......
2.2 常见的XSS的绕过编码
2.1.1 HTML实体编码绕过:
大小写混合:
尝试使用不同的大小写或混合大小写来绕过过滤器。例如,将
2.2.2 URL编码绕过:
双重编码:
攻击者可以尝试对特殊字符进行多次URL编码,如将
使用括号和反斜杠:攻击者可能会尝试使用括号、反斜杠等字符来绕过过滤器,例如,将alert(1)写成al\u0065rt(1)。
混合多种编码:
组合不同编码形式:攻击者可能尝试结合多种编码形式,如HTML实体编码和URL编码的混合使用,来绕过过滤器的检测。
JS编码
JS提供了四种字符编码的策略,如下所示:
三个八进制数字,如果个数不够,在前面补0,例如“e”的编码为“\145”。
两个十六进制数字,如果个数不够,在前面补0,例如“e”的编码为“\x65”。
四个十六进制数字,如果个数不够,在前面补0,例如“e”的编码为“\u0065”。
对于一些控制字符,使用特殊的C类型的转义风格(例如\n和\r)。
HTML实体编码
命名实体:以&开头,以分号结尾如 “<”的编码是“<”。字符编码:十进制、十六进制ASCII码或Unicode字符编码,样式为“&#数值”。例如”<”可以编码为“<”和“<”。
https://www.w3school.com.cn/html/html_entities.asp
URL编码
这里的URL编码,也是两次URL全编码的结果,如果alert被过滤,可编码为如下:
%25%36%31%25%36%63%25%36%35%25%37%32%25%37%34
3. XSS防御
HttpOnly
HttpOnly 最早由微软提出,浏览器将禁止页面的JavaScript访问HttpOnly属性的Cookie。HTTPOnly 并未要对抗XSS,HTTPOnly 解决的是XSS后的Cookie劫持攻击。在使用了HTTPOnly之后,会使这种攻击失效。
使用了HttpOnly之后就没有办法偷取cookie了。
输入检查
常见的web漏洞都要求攻击者构造一些特殊字符,这些特殊字符可能是常规用户不会用到的,所以输入检查就很有必要了。在XSS防御上一般就是检查用户输入数据中是否包含一些特殊字符,如<、>、"、’ 如果发现这些特殊字符将这些关键字符过滤或者编码。
比较智能的检查还可以匹配XSS 的特征,比如查找用户数据中是否包含了
输出检查
除了富文本的输出之外,在变量输出到HTML页面时,可以使用编码或者转义的方式来防御XSS攻击。
- HTML代码的编码方式是HtmlEncode。
- PHP中有htmlentities()和htmlspecialchares() 这两个函数可以满足安全要求
- Javascript 可以使用JavascriptEncode。
- 在Django自带的模板系统中,可以使用escape进行htmlencode,并且在Django 1.0中默认所有变量都会被escape。
- web2py中,也默认escape了所有变量。