前言
最近写了一个有关使用tushare数据库对某个公司的财务数据进行静态分析的工作,本质还是很简单的,就像将这个内容记录下来。本文操作使用的是python3.12,在jupyter当中进行编写的代码。
一、要求
选择一个企业对其进行财务能力分析,要求不少于3年的数据,通常使用5年的数据。对其进行财务能力分析,主要关注盈利能力、偿债能力、运营能力和成长能力。
二、使用步骤
1.引入库
pandas 库和tushare 库主要用于获取数据,numpy用于矩阵的转置,matplotlib用于数据的可视化,代码如下(示例):
# 导入相关库
import tushare as ts
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
2.爬取数据
要想使用tushare库爬取相关的数据,首先要先进入tushare官网注册账号,如果是高校的学生可以免费获得2000积分,获取完后即可使用代码进行爬取,tushare官网也提供了生成代码的功能,这个大家可以自己摸索,根据具体需要什么数据进行探索,一下只以企业的三大报表为例。进入之后按照自己所需要的进行输入即可获得相应的数据,左下角提供了生成代码的功能。
# 初始化pro接口
pro = ts.pro_api('你的token')#token需替换
# 设置起始和结束年份
start_year = 2015
end_year = 2023
# 创建一个空的DataFrame用于存储所有年份的数据
all_data = pd.DataFrame()
# 循环获取每年12月31日的数据
for year in range(start_year, end_year + 1):
df = pro.cashflow(**{
"ts_code": "600519.SH",
"period": str(year) + "1231", # 指定报告期为12月31日
# 其他参数...
}, fields=[
"ts_code",
"ann_date",
"f_ann_date",
"end_date",
"comp_type",
"report_type",
"net_profit",
"finan_exp"
])
# 将每年的数据追加到all_data中
all_data = pd.concat([all_data, df], ignore_index=True)
# 将所有数据保存到Excel文件中
all_data.to_excel('600519_现金流量表.xlsx', index=False) # 路径需更改,当然可以使用默认路径,即代码所在路径
# 循环获取每年12月31日的数据
for year in range(start_year, end_year + 1):
df = pro.income(**{
"ts_code": "600519.SH",
"period": str(year) + "1231", # 指定报告期为12月31日
# 其他参数...
}, fields=[
"ts_code",
"ann_date",
"f_ann_date",
"end_date",
"report_type",
"comp_type",
"basic_eps",
"diluted_eps",
"total_revenue",
"revenue",
"total_cogs",
"oper_cost",
"operate_profit",
"n_income",
"n_income_attr_p",
"ebit",
"int_exp",
"fin_exp_int_exp"
])
# 将每年的数据追加到all_data中
all_data = pd.concat([all_data, df], ignore_index=True)
# 将所有数据保存到Excel文件中
all_data.to_excel(r'600519_利润表.xlsx', index=False)
# 循环获取每年12月31日的数据
for year in range(start_year, end_year + 1):
df = pro.balancesheet(**{
"ts_code": "600519.SH",
"period": str(year) + "1231", # 指定报告期为12月31日
"fields": [
"ts_code",
"ann_date",
"f_ann_date",
"end_date",
"report_type",
"comp_type",
"total_hldr_eqy_exc_min_int",
"total_hldr_eqy_inc_min_int",
"inventories",
"total_assets",
"accounts_receiv",
"total_cur_assets",
"total_cur_liab",
"prepayment"
]
})
# 将每年的数据追加到all_data中
all_data = pd.concat([all_data, df], ignore_index=True)
# 将所有数据保存到Excel文件中
all_data.to_excel('600519_资产负债表.xlsx', index=False)
通过上述循环过程我们就能够得到茅台企业的三大报表,但是在进行分析师读取三个文件进行处理是存在一定的难度的,因此可以将三个文件合并成同一个。
2.读入数据
代码如下(示例):
# 读取Excel文件
cashflow_df = pd.read_excel('600519_现金流量表.xlsx')
income_df = pd.read_excel('600519_利润表.xlsx')
balance_df = pd.read_excel('600519_资产负债表.xlsx')
# 确保每个DataFrame都有一个共同的列来合并,例如'ts_code'和'ann_date'
# 如果列名不一致,需要先重命名以确保一致性
# 合并三个DataFrame
merged_data = pd.merge(income_df, cashflow_df, on=["ts_code", "ann_date", "f_ann_date", "end_date", "report_type", "comp_type"], how="outer")
merged_data = pd.merge(merged_data, balance_df, on=["ts_code", "ann_date", "f_ann_date", "end_date", "report_type", "comp_type"], how="outer")
# 如果需要,可以删除重复的列,例如如果'ts_code'和'ann_date'在所有DataFrame中都存在
merged_data.drop_duplicates(subset=["ts_code", "ann_date"], inplace=True)
# 将合并后的数据保存到新的Excel文件中
merged_data.to_excel('600519_合并.xlsx', index=False)
同上述过程我们发现获取到的数据表头都是英文,因此可以将其转换为中文以便后续的处理。
# 读取Excel文件
data = pd.read_excel('600519_合并.xlsx')
# 创建列名及其对应中文翻译的字典
column_names_chinese = {
'ts_code': 'TS股票代码',
'ann_date': '公告日期',
'f_ann_date': '实际公告日期',
'end_date': '报告期',
'report_type': '报表类型',
'comp_type': '公司类型',
'total_hldr_eqy_exc_min_int': '股东权益合计(不含少数股东权益)',
'total_hldr_eqy_inc_min_int': '股东权益合计(含少数股东权益)',
'inventories': '存货',
'total_assets': '资产总计',
'accounts_receiv': '应收账款',
'total_cur_assets': '流动资产合计',
'total_cur_liab': '流动负债合计',
'prepayment': '预付款项',
'basic_eps': '基本每股收益',
'diluted_eps': '稀释每股收益',
'total_revenue': '营业总收入',
'revenue': '营业收入',
'total_cogs': '营业总成本',
'oper_cost': '减:营业成本',
'int_exp': '减:利息支出',
'operate_profit': '营业利润',
'n_income': '净利润(含少数股东损益)',
'n_income_attr_p': '净利润(不含少数股东损益)',
'ebit': '息税前利润',
'fin_exp_int_exp': '财务费用:利息费用',
'net_profit': '净利润',
'finan_exp': '财务费用'
}
# 使用rename方法重命名列
data.rename(columns=column_names_chinese, inplace=True)
# 将重命名后的DataFrame保存到新的Excel文件中
data.to_excel('600519_合并_中文列名.xlsx', index=False)
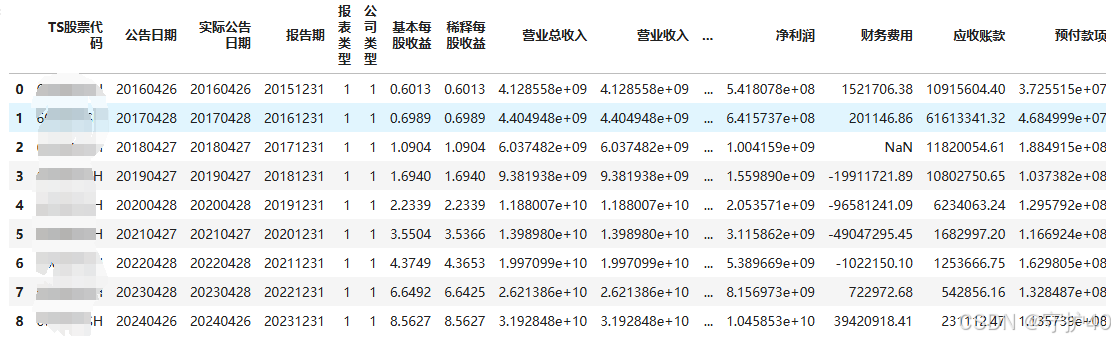
我们可以读取数据查看我们的结果是否成功。
可以看出我们的列名称已经成为了汉字,后续我们就可以直接使用中文进行索引,但也发现了一些问题数据当中存在空值,因此需要对数据进行处理,nan可以使用平均值填充也可以使用0值填充,本文两种方式都使用了,可供参考。
# 找出包含缺失值的列
cols_with_missing = data.columns[data.isnull().any()].tolist()
# 计算这些列的平均值,跳过NaN值
means = data[cols_with_missing].mean()
# 只对存在缺失值的列使用平均值填充
for column in cols_with_missing:
if data[column].isnull().any():
data.loc[:, column] = data[column].fillna(means[column])
# 查找所有值都缺失的列
all_na_columns = data.columns[data.isna().all()]
# 将这些列的所有值设置为0
data[all_na_columns] = data[all_na_columns].fillna(0)
# 显示处理后的DataFrame
data
3.指标计算
3.1 计算盈利能力
企业盈利能力的指标,主要包括毛利率、净利润率、营业利润率和净资产收益率。
毛利率的计算:
毛利率 = 毛利/ 营业收入 = (营业收入-营业成本)/营业收入
# 计算毛利率
data['毛利率'] = round((data['营业收入'] - data['减:营业成本']) / data['营业收入'], 4)#最后的4表示保留小数位数
data[["TS股票代码", "报告期", "毛利率"]]
计算营业利润率:
营业利润率 = 营业利润 / 营业收入
data['营业利润率'] = round((data['营业利润'] / data['营业收入']), 4)
data[['TS股票代码', '报告期', '营业利润率']]
计算净利润率:
净利润率 = 净利润 / 营业收入
data['净利润率'] = round((data['净利润(含少数股东损益)'] / data['营业收入']), 4)
data[['TS股票代码', '报告期', '净利润率']]
计算净资产收益率:
净资产收益率 = 归母净利润 / 平均归母净资产 = 归母净利润 / 平均股东权益(不含少数股东)
# 获取2014年的净资产数据
df_2014 = pro.balancesheet(ts_code='600519.SH', period='20141231')[-1:]
asset_2014 = df_2014['total_hldr_eqy_exc_min_int'][1]
# 把 2014年~2023年的股东权益(不含少数股东)作为新列表,并把列表加入表格
assetO = data['股东权益合计(不含少数股东权益)'][1:].to_list()
assetO.append(asset_2014)
data['股东权益(上期余额)'] = assetO
# 计算 ROE
data['ROE'] = round((data['净利润(不含少数股东损益)'] / ((data['股东权益合计(不含少数股东权益)'] + data['股东权益(上期余额)']) / 2)), 4)
data[['TS股票代码', '报告期', 'ROE']]
在这里需要注意的是,9年的报表数据只能计算出后8年的ROE,想要计算2015年的ROE还需要获取2014年的数据,所以进行上述调整。
3.2计算运营能力
运营能力主要由存货周转率、总资产周转率以及应收账款周转率等指标表征。
计算存货周转率:
存货周转率 = 营业成本 / ((期初存货+期末存货)/2)
# 获取2014年的净资产数据
df_2014 = pro.balancesheet(ts_code='600519.SH', period='20141231')[-1:]
asset_2014 = df_2014['total_hldr_eqy_exc_min_int'][1]
# 把 2014年~2023年的股东权益(不含少数股东)作为新列表,并把列表加入表格
assetO = data['股东权益合计(不含少数股东权益)'][1:].to_list()
assetO.append(asset_2014)
data['股东权益(上期余额)'] = assetO
# 计算 ROE
data['ROE'] = round((data['净利润(不含少数股东损益)'] / ((data['股东权益合计(不含少数股东权益)'] + data['股东权益(上期余额)']) / 2)), 4)
data[['TS股票代码', '报告期', 'ROE']]
为什么获取2014年的数据上面说过了这就不再说了,后续也一样。
计算总资产周转率:
总资产周转率= 营业收入 / 平均总资产= 营业收入 / ((期初总资产 + 期末总资产)/2)
# 获取2014年的总资产数据
df_2014 = pro.balancesheet(ts_code='600519.SH', period='20141231')[-1:]
inv_2014 = df_2014['total_assets'].iloc[0]
# 把2014年~2023年的总资产作为新列表,并把列表加入表格
invo = data['资产总计'][1:].to_list()
invo.append(inv_2014)
data['资产总计(上期余额)'] = invo
# 计算总资产周转率
data['总资产周转率'] = round(data['营业收入'] / ((data['资产总计'] + data['资产总计(上期余额)']) / 2), 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '总资产周转率']]
计算应收账款周转率:
应收账款周转率 = 营业收入 / 平均应收账款
# 获取2014年的应收账款数据
df_2014 = pro.balancesheet(ts_code='600519.SH', period='20141231')[-1:]
inv_2014 = df_2014['accounts_receiv'][1]
# 把2014年~2018年的应收账款作为新列表,并把列表加入表格
invo = data['应收账款'][1:].to_list()
invo.append(inv_2014)
data['应收账款(上期余额)'] = invo
# 计算应收账款周转率
data['应收账款周转率'] = round(data['营业收入'] / ((data['应收账款'] + data['应收账款(上期余额)']) / 2), 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '应收账款周转率']]
3.3计算偿债能力
反映企业财务风险水平或者说偿债能力的指标,主要包括流动比率、速动比率和利息保障倍数。
计算流动比率:
流动比率 = 流动资产总额 / 流动负债总额
# 计算流动比率
data['流动比率'] = round(data['流动资产合计'] / data['流动负债合计'], 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '流动比率']]
计算速动比率:
速动比率 = ( 流动资产总额 - 存货 - 预付款项) / 流动负债总额
# 计算速动比率
data['速动比率'] = round((data['流动资产合计'] - data['存货'] - data['预付款项']) / data['流动负债合计'], 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '速动比率']]
计算利息保障倍数:
利息保障倍数 = 息税前利润(EBIT) / 利息费用
# 计算比率
data['利息保障倍数'] = round(data['息税前利润'] / data['减:利息支出'], 4)
data[['TS股票代码', '报告期', '利息保障倍数']]
3.4计算成长能力
成长能力主要通过营收增长率、营业利润增长率以及净利润增长率等指标表征。
计算营收增长率:
营收增长率 = (本期营业收入 - 上期营业收入) / 上期营业收入
# 获取2014年的营业收入数据
df_2014 = pro.income(ts_code='600519.SH', period='20141231')[-1:]
revenue_14 = df_2014['revenue'].iloc[0]
# 把2014年~2023年的营业收入作为新列表,并把列表加入表格
revenueO = data['营业收入'][1:].to_list()
revenueO.append(revenue_14)
data['营业收入(上期余额)'] = revenueO
# 计算营业收入增长率
data['营业收入增长率'] = round((data['营业收入'] - data['营业收入(上期余额)']) / data['营业收入(上期余额)'], 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '营业收入增长率']]
计算营业利润增长率:
营业利润增长率= (本年营业利润总额 - 上年营业利润总额) / 上年营业利润总额
# 获取2014年的营业利润数据
df_2014 = pro.income(ts_code='600519.SH', period='20141231')[-1:]
revenue_14 = df_2014['operate_profit'].iloc[0]
# 把2014年~2023年的营业利润作为新列表,并把列表加入表格
revenueO = data['营业利润'][1:].to_list()
revenueO.append(revenue_14)
data['营业利润(上期余额)'] = revenueO
# 计算营业利润增长率
data['营业利润增长率'] = round((data['营业利润'] - data['营业利润(上期余额)']) / data['营业利润(上期余额)'], 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '营业利润增长率']]
计算净利润增长率:
净利润增长率 =(期末净利润 - 期初净利润)/ 期初净利润
# 获取2014年的净利润数据
df_2014 = pro.income(ts_code='600519.SH', period='20141231')[-1:]
profit_14 = df_2014['n_income'].iloc[0]
# 把2014年~2023年的净利润作为新列表,并把列表加入表格
profitO = data['净利润'][1:].to_list()
profitO.append(profit_14)
data['净利润(上期余额)'] = profitO
# 计算净利润增长率
data['净利润增长率'] = round((data['净利润'] - data['净利润(上期余额)']) / data['净利润(上期余额)'], 4)
# 选择并打印需要的列
data[['TS股票代码', '报告期', '净利润增长率']]
至此我们就计算完了所有的指标。
4.数据可视化
在这一步我们要对上述的数据进行可视化分析,首先需要提取出我们计算出各项指标的结果。
# 重新调整代码以确保正确执行
df_ratio = data[['报告期', '毛利率', '营业利润率', '净利润率', 'ROE', '存货周转率', '总资产周转率', '应收账款周转率', '流动比率', '速动比率', '利息保障倍数', '营业收入增长率', '营业利润增长率', '净利润增长率']]
df_ratio = df_ratio.set_index('报告期').T # 设置报告期为索引并转置
# 插入行标签为新的第一列
df_ratio.insert(0, '报告期', df_ratio.index)
# 将DataFrame保存到Excel
with pd.ExcelWriter('600519_合并.xlsx', mode='a', engine='openpyxl', if_sheet_exists='new') as writer:
df_ratio.to_excel(writer, sheet_name='财务比率表', index=False)
在这里进行了转置处理,是为了能够更好的将数据放入word当中,否则列名称多,会造成很宽的效果。进一步我们可以根据上述结果进行读取数据可视化,因为我们将上表放入了我们的原文件,创建了新的sheet所以在读取数据时也要记得读取我们对应的sheet即可。
# 读取并处理财务比率表数据
df_ratio = pd.read_excel('6005199_合并.xlsx', sheet_name='财务比率表')
# 重命名第一列索引列名从 'Unnamed: 0' 改为 '报告期'
df_ratio = df_ratio.rename(columns={'Unnamed: 0': '报告期'})
# 设置 '报告期' 列为行索引
df_ratio = df_ratio.set_index('报告期')
# 转置表格
df_ratio = df_ratio.T
# 时间顺序排列
data = df_ratio[::1]
# 把 inf(无限大)替换为 0
data[np.isinf(data)] = 0
# 输出处理后的数据
data
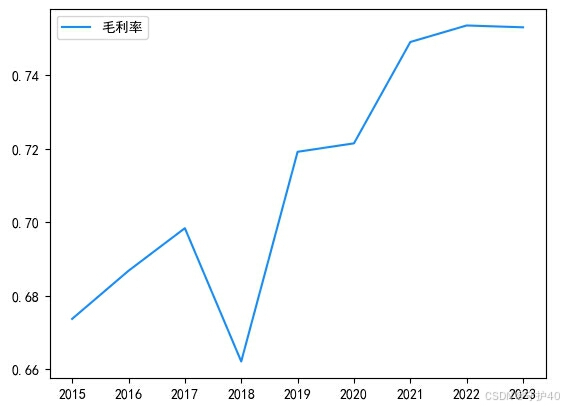
紧接着我们就可以对各个数据绘制折线图进行可视化的呈现,代码和图如下所示:
years = ['2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022', '2023']
plt.plot(years, data['毛利率'], label='毛利率', color='#FFB6C1')# 这是颜色 适中的紫罗兰红色 #C71585 道奇蓝 #1E90FF 绿玉\碧绿色 #7FFFAA
plt.legend(loc='upper left') # 设置图例的位置在左上角
plt.show()
总结
以上就是今天要讲的内容,内容看似有点多,但是很多代码都是重复的,有感兴趣的小伙伴可以自行学习。