这篇论文提出了一种名为HomoFormer的新型Transformer模型,用于图像阴影去除。论文的主要贡献和创新点如下:
1. 研究背景与动机
-
阴影去除的挑战:阴影在自然场景图像中普遍存在,影响图像质量并限制后续计算机视觉任务的性能。阴影的空间分布不均匀且模式多样,导致传统的卷积神经网络(CNN)和基于窗口的Transformer模型难以有效处理。
-
现有方法的局限性:现有的方法通常依赖于复杂的模型来适应阴影的非均匀分布,但这些模型的计算复杂度高,难以应用于高分辨率图像。
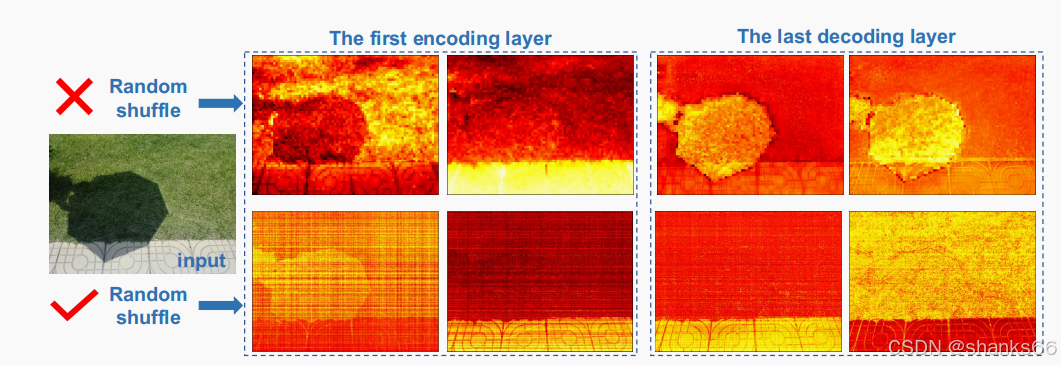
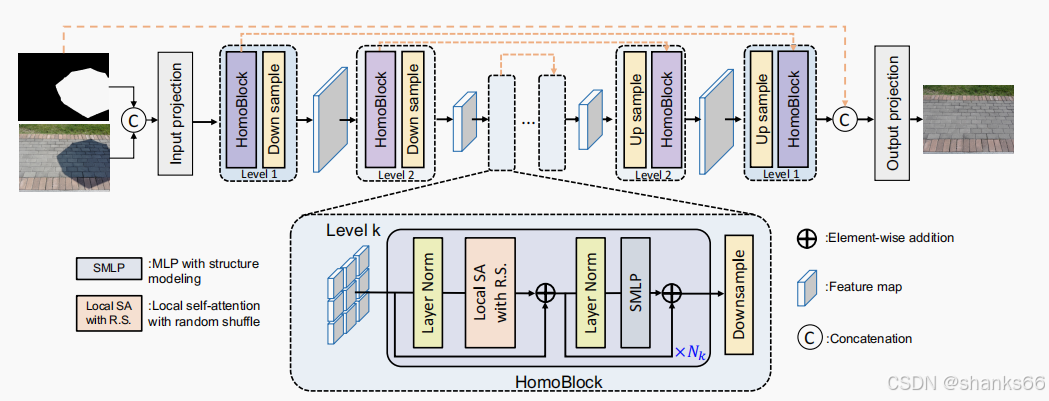
2. 方法概述
-
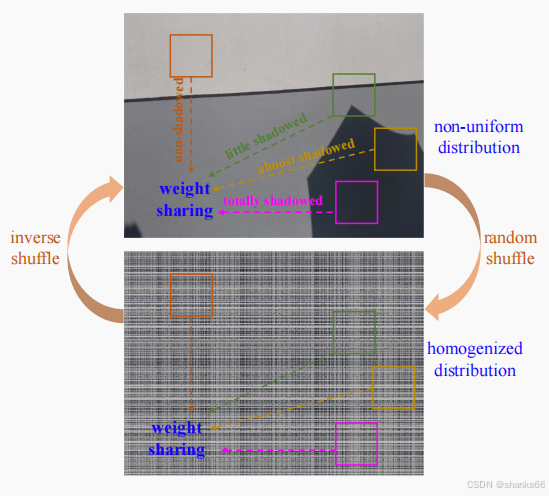
随机打乱操作:为了应对阴影的非均匀分布问题,论文提出了一种新的策略:通过随机打乱操作(Random Shuffle)将阴影的非均匀分布均匀化。随机打乱操作将图像像素在空间上随机重新排列,使得阴影在整个图像中均匀分布,从而便于后续的局部自注意力层处理。
-
逆打乱操作:在随机打乱操作后,通过逆打乱操作(Inverse Shuffle)将像素恢复到原始顺序,确保图像语义信息不丢失。
-
局部自注意力层:在均匀化的空间中,使用局部自注意力层(Local Self-Attention)来处理图像,避免了传统全局自注意力的高计算复杂度。
-
结构建模的前馈网络(FFN):由于随机打乱操作破坏了像素的相对位置信息,论文设计了一种新的前馈网络(FFN),通过深度卷积来建模图像的结构信息。
![![[Pasted image 20250109154028.png]]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvOGFmN2NmOWUzOTg1NDg1Mzg2ZWMzMTg2NDQyYjgyY2IucG5n)
![![[Pasted image 20250109154042.png]]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvN2NkYjZlYmM4NmNkNDA2YzgxMDhhNTVmMzRhMmEwYTYucG5n)
3. 主要贡献
-
均匀化阴影分布:论文提出了一种新的视角,通过随机打乱操作将阴影的非均匀分布均匀化,从而解决了传统模型在处理非均匀阴影时的局限性。
-
HomoFormer模型:基于随机打乱和逆打乱操作,论文构建了一个名为HomoFormer的局部窗口Transformer模型,能够在保持线性计算复杂度的同时,有效处理非均匀分布的阴影。
-
实验验证:论文在多个公开数据集上进行了广泛的实验,验证了HomoFormer在阴影去除任务中的优越性,并展示了其在生成高质量无阴影图像方面的能力。
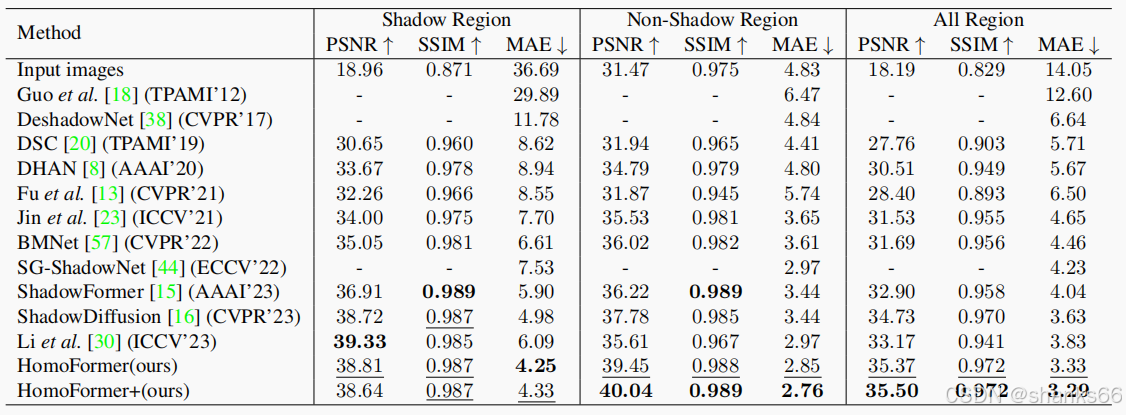
4. 实验与结果
-
数据集:实验在ISTD+和SRD两个基准数据集上进行,评估了HomoFormer与现有最先进方法的性能对比。
-
定量评估:HomoFormer在阴影区域、非阴影区域和整个图像上的均方误差(MAE)、峰值信噪比(PSNR)和结构相似性(SSIM)等指标上均优于现有方法。
SDR
-
定性评估:视觉对比结果显示,HomoFormer生成的图像具有更少的伪影和更清晰的细节。
-
消融实验:通过消融实验验证了随机打乱操作和结构建模FFN的有效性,表明它们对提升模型性能起到了关键作用。


5.核心代码
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
import math
import numpy as np
import time
from torch import einsum
import random
class PModule(nn.Module):
def __init__(self, dim=32, hidden_dim=128, act_layer=nn.GELU, drop=0.):
super().__init__()
self.linear1 = nn.Linear(dim, hidden_dim)
self.dwconv = nn.Conv2d(hidden_dim, hidden_dim, groups=hidden_dim, kernel_size=3, stride=1, padding=1)
#self.selayer = SELayer(hidden_dim//2)
self.linear2 = nn.Sequential(nn.Linear(hidden_dim//2, dim))
self.dim = dim
self.hidden_dim = hidden_dim
def forward(self, x, img_size=(128, 128)):
# bs x hw x c
hh,ww = img_size[0],img_size[1]
x = self.linear1(x)
# spatial restore
x = rearrange(x, ' b (h w) (c) -> b c h w ', h=hh, w=ww)
x1,x2 = self.dwconv(x).chunk(2, dim=1)
x3 = x1 * x2
#x4=self.selayer(x3)
# flaten
x3 = rearrange(x3, ' b c h w -> b (h w) c', h=hh, w=ww)
y = self.linear2(x3)
return y
class SepConv2d(torch.nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1, act_layer=nn.ReLU):
super(SepConv2d, self).__init__()
self.depthwise = torch.nn.Conv2d