+++
title = “(一)高效异步:利用消息队列优化大规模Excel文件下载”
date = “2024-04-29T14:00:32+08:00”
draft = false
+++
这是如何构建“实战企业级高性能在线教育平台设计”系列文章的第一章。
在这一系列的开篇,笔者将深入探讨在线教育平台背后的技术架构和设计思想,以及如何通过高效的系统设计来满足日益增长的教育需求和提升用户体验。
接下来的章节中,笔者将详细介绍具体的实现技术、性能优化策略以及如何处理大规模用户并发的挑战。目标是为读者提供一套完整的解决方案,帮助你构建一个既稳定又高效的在线教育平台。
敬请期待更多精彩内容的分享!
0. 前言
当谈论在高并发环境下处理大规模数据时,特别是涉及到文件的上传和下载,性能优化与系统响应能力变得至关重要。在这种场景下,有效地管理和调度大量的数据请求对于保持系统稳定和提高用户体验是一个挑战。
为了应对这一挑战,许多现代应用程序采用了消息队列技术,以异步方式处理输入和输出操作,实现流量削峰和负载平衡。
本文章分为上下两集,旨在深入探讨如何使用消息队列技术优化处理大量Excel文件的上传和下载过程。通过使用消息队列,我们可以将上传和下载任务异步化,从而不仅能缓解服务器的即时负载,还能提供更加平滑和可预测的系统表现。此外,结合对象存储服务如Minio,可以进一步提升文件管理的效率和安全性。
上集中,将聚焦于文件下载的处理。详细介绍如何从接收下载请求到最终通过消息队列完成文件传输的整个流程,探讨其中的关键技术点和性能优化策略。下集则将关注文件上传,从用户发起上传请求,到文件数据通过消息队列被安全高效地处理和存储的全过程,同时讨论如何在保证数据完整性和安全性的前提下优化性能。
通过这两篇文章,笔者希望为读者提供一个清晰的视角,了解如何在面对大规模文件处理需求时,通过技术和架构上的选择,实现一个高效、可扩展且健壮的系统解决方案。
(一)高效异步:利用消息队列优化大规模Excel文件下载
1. 引言
1.1 背景
在大规模教育或企业系统中处理成千上万的Excel文件下载请求时,尤其在报告生成或数据分析高峰期,系统性能面临严峻挑战。本人负责的教育平台项目涉及大量Excel数据的导入与导出操作,通过对服务器进行压力测试,观察到在学期末或毕业季等关键时期,多个教学点的管理员同时发起数据导入或导出请求时,会显著增加服务器的CPU负载。分析表明,当CPU资源已被大量数据处理任务或其他应用占用时,垃圾回收(GC)的效率会显著降低,导致系统负担加重,并可能触发更频繁的Full GC操作,以尝试释放充足的内存资源。
项目和数据库部署于同一服务器,可能在视频点播或论坛讨论高峰时段造成性能瓶颈。若未对这些高峰请求进行有效管理,可能导致服务器响应延迟或服务暂时不可用,严重影响用户体验和业务连续性。
为提高系统应对高并发数据请求的能力,本文提出利用消息队列技术优化Excel文件处理流程。通过引入消息队列,可以有效地分散请求压力,提升数据处理效率,增强系统的可靠性和响应速度。这种方法不仅有助于降低直接对服务器的请求负荷,还能确保在业务高峰期系统的稳定运行。
1.2 目标
本文的目标是具体阐述如何通过消息队列技术来优化Excel文件下载的系统性能及提升用户体验。具体来说,本文将围绕以下几个核心优势进行详细说明:
- 即时响应机制:使用消息队列,系统可以对用户的下载请求进行即时响应,即用户提交请求后立即收到一个系统已接受任务的确认。这种响应方式与传统的同步处理相比,大大减少了用户等待的时间,提升了用户的感知速度,从而优化了用户体验。
- 失败恢复能力:在下载任务处理过程中,如果遇到失败情况,消息队列可以重新将任务放回队列中重新执行,或者标记异常供系统管理员处理。这不仅提高了任务的成功率,也减轻了因处理失败带来的手动干预成本。
2. 系统架构概览
本节将概述本系统的主要组成部分,包括客户端、服务器、消息队列(RabbitMQ)和文件存储系统(Minio),并深入探讨消息队列的设计及其在系统中的实际应用。
先献上一个整体流程的用例图

-
客户端:用户界面,用于提交文件下载或上传请求。对接RabbitMQ,客户端的Service层调用rabbitMQ的MessageSender中的封装好的send方法,使用异步的消息发送。
-
服务器:核心处理单元,接收来自客户端的请求,执行必要的业务逻辑处理,并与消息队列和文件存储系统交互。服务器在这个架构中扮演调度者的角色,确保数据的正确流转及有效处理。
-
消息队列(RabbitMQ):作为系统的中枢神经,负责接收、存储并转发消息。通过使用RabbitMQ,系统能够异步处理来自客户端的众多请求,有效分散高峰流量,减轻服务器的即时处理压力。
-
文件存储系统(Minio):Minio是一个高性能的对象存储引擎,用于存储和管理上传的文件及处理后的文件。在本处,Excel文件的上传下载文件的过程中,Minio存储Excel各种文件的父模板,也寄存着各种转换成功的Excel文件。
2.1 消息队列在本系统中的设计

在本系统中,消息队列的设计和实现是通过两个核心类MessageSender和MessageReceiver完成的,这两个类通过RabbitMQ交换消息,实现了系统内各组件间的解耦和异步通信。
- 发送普通消息 (
send方法):- 消息发送至
queue1,包含普通文本信息,用于系统内基本的通信需求。 - 消息接收由
MessageReceiver类中的process方法处理,该方法监听queue1。
- 消息发送至
- 发送数据导出请求 (
sendExportMsg方法):- 发送至
queue4,此队列处理包含具体数据和类型信息的复杂JSON对象,用于数据导出任务。 - 消息的接收和处理通过
MessageReceiver中的processExportData方法完成,它监听queue3和queue4。
- 发送至
- 发送系统消息 (
sendSystemMsg方法):- 用于发送系统级别的通知或警告,发送至
queue5。 - 对应的接收处理由
MessageReceiver中的processSystemMsg方法完成,专门监听queue5。
- 用于发送系统级别的通知或警告,发送至
- 发送导入数据请求 (
sendImportMsg方法):- 发送至
queue6,处理与文件上传相关的操作请求。 MessageReceiver类中的processImportData方法负责接收此队列消息,进行文件上传后的数据处理。
- 发送至
- 发送CDN操作消息 (
send方法用于 CDN):- 特定于CDN操作的消息发送至
cdn_queue1,用于处理与内容分发网络相关的任务。
- 特定于CDN操作的消息发送至
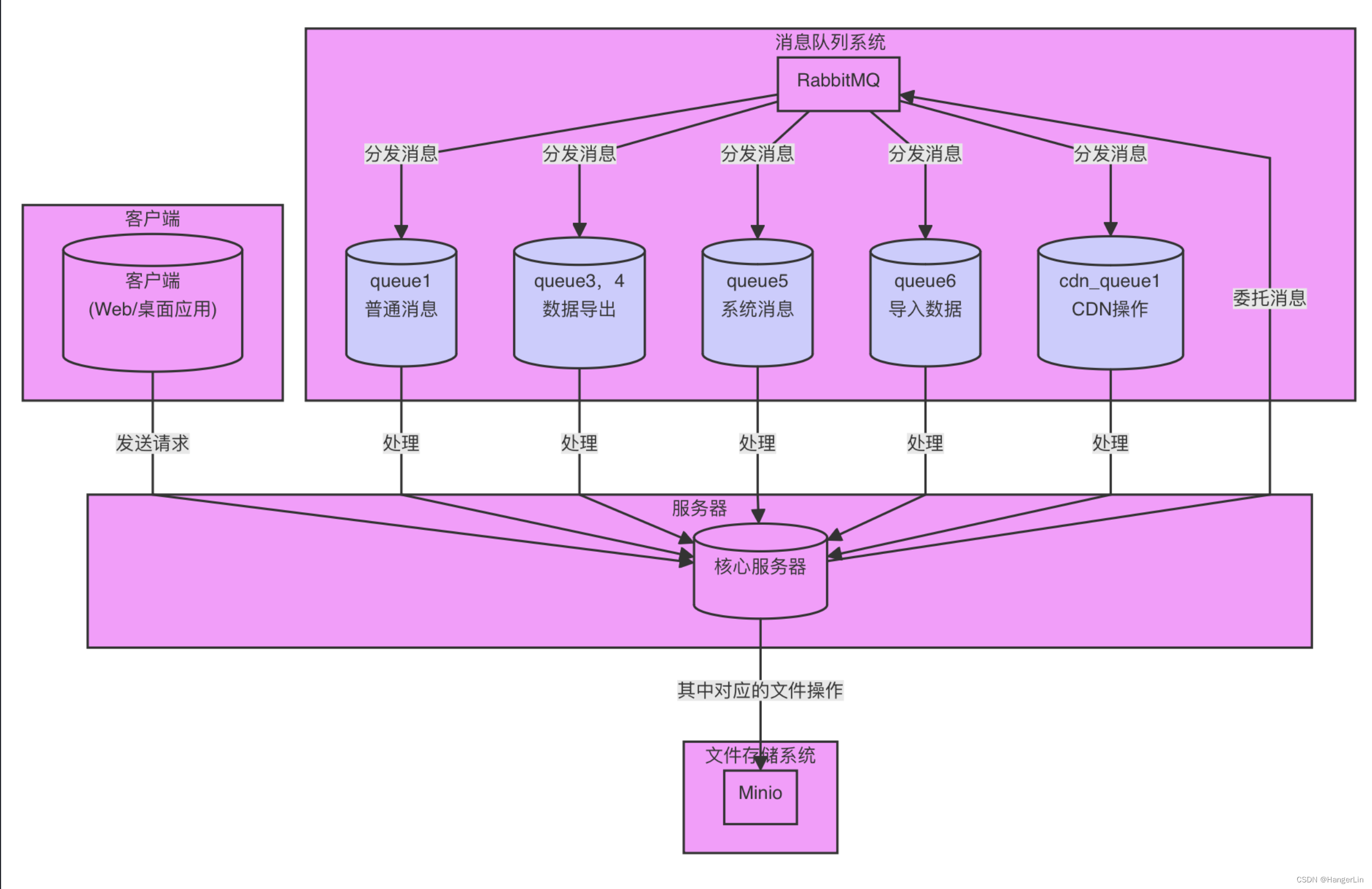
迫于篇幅位置所限,笔者只讨论文件上传,下载的具体实现。文件的下载,实际上对应着系统的ExportData(数据导出),因此消费者就监听着queue3,4。类似的,文件上传就是由queue6负责监听。
2.2 Minio文件存储
在现代软件应用中,有效的文件管理是关键功能之一,尤其是在依赖对象存储服务进行文件存储的场景下。
在本高性能教育平台的设计中,笔者选择开源的Minio作为存储解决方案,用户可以享受到显著的灵活性和成本效益,因为它允许自托管且完全兼容Amazon S3 API,减少了依赖于第三方服务提供商,如阿里云OSS的必要。
与此同时,阿里云OSS虽然提供稳定的服务支持,但可能带来增长的费用和服务依赖性,特别是在数据访问频繁或政策和服务变动时,可能导致成本增加和迁移难度。
通过Minio,组织可以更好地控制数据存储和管理策略,避免了供应商锁定,同时降低了长期的运营成本。接下来,笔者将详细讲解在数据库中如何存储文件的相对地址,文件在Minio中如何管理,以及文件上传的完整流程,以充分利用Minio带来的这些优势。
对于不熟悉Minio或类似对象存储服务的读者来说,理解其存储架构的不同层级可能初看起来略显复杂。为了帮助大家更好地掌握这一点,接下来的部分将通过详细的代码示例展示文件的上传和下载过程。在此过程中,我们将重点讲解三个核心概念:“桶(Bucket)”,“子目录(Subdirectory)”,以及“文件名(Filename)”。
这三个概念在Minio的存储结构中扮演着至关重要的角色。笔者先详细讲讲这三个概念,而且他们是怎么在Minio存储中起到作用的。
笔者的设计图如下:
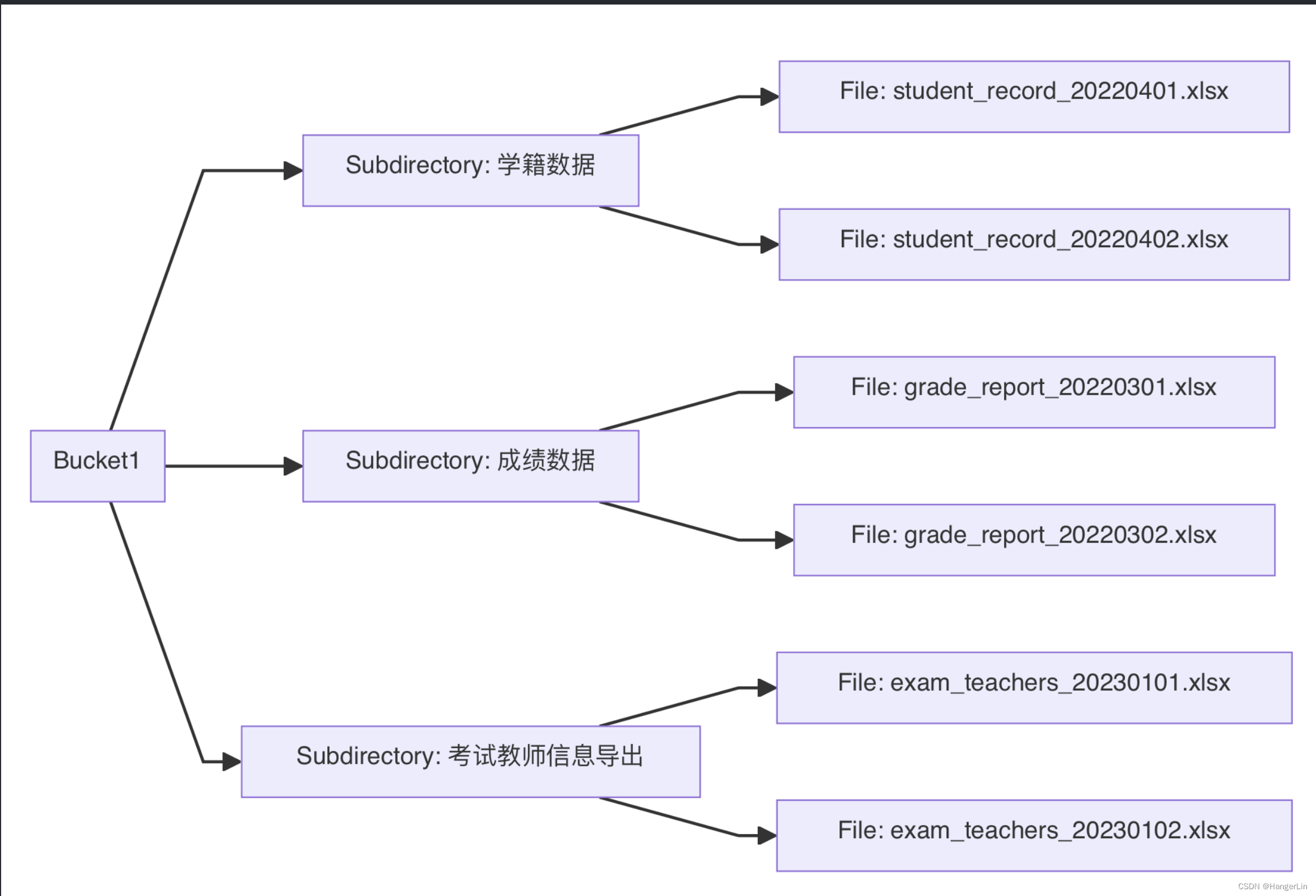
1. 桶(Bucket)
在Minio以及其他对象存储系统中,桶是最顶层的数据容器,类似于文件系统中的“根目录”或数据库中的“数据库实例”。每个桶可以包含任意数量的对象(文件),并且桶内的对象通过唯一的键(即文件名和路径)来访问,而这个键由“子目录”和“文件名”构成。
2. 子目录(Subdirectory)
虽然Minio是一个扁平的存储结构,没有真正的文件夹或目录概念,但可以通过在对象键中使用斜杠(/)来模拟目录结构。这种方式允许用户在逻辑上组织和管理文件,使得文件的存取更加直观。
3. 文件名(Filename)
文件名在Minio中是唯一标识一个对象的键,通常会包含实际的文件名以及模拟的目录路径。在Minio中,完整的对象键由子目录和文件名组成,如“subdirectory/filename”。
有以下使用方式:
String bucketName = MinioBucketEnum.DATA_DOWNLOAD_EXAM_THEACHER.getBucketName();
String subDirectory = MinioBucketEnum.DATA_DOWNLOAD_EXAM_THEACHER.getSubDirectory();
String fileName = subDirectory + "/" + username + "_" + currentDateTime + "_examTeachersData.xlsx";
bucketName 指定了数据将存储在哪个桶中,这个桶可以独立于其他桶进行管理和权限设置。subDirectory 用于在这个桶内逻辑上组织数据,而 fileName 包括了路径信息和实际的文件名,使得文件在桶中的位置清晰明确。
3. 实现文件下载的详细调用链
3.1 消息发送
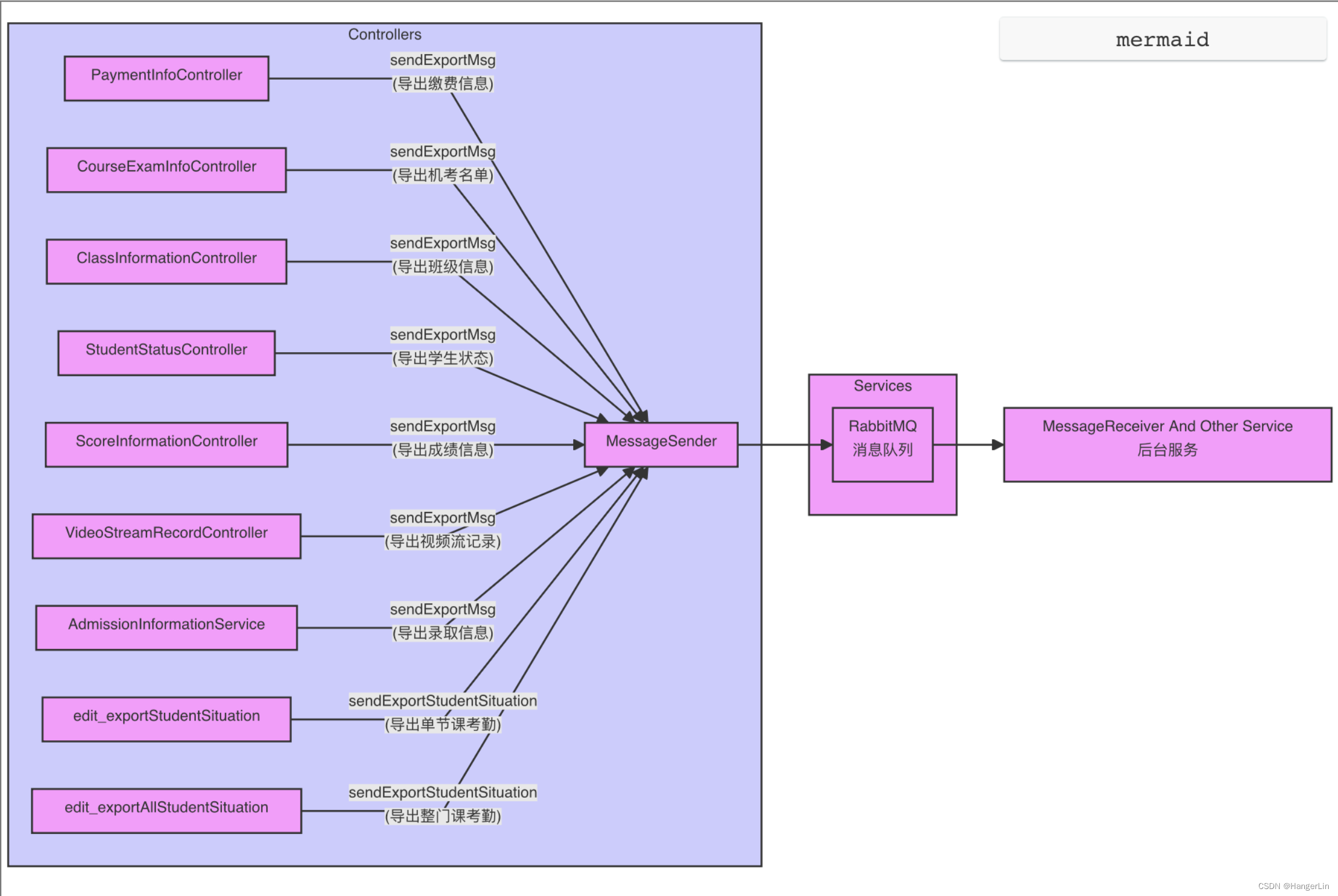
-
接收文件下载请求
当用户通过客户端(Web或桌面应用)发起文件下载请求时,请求首先被发送到服务器端的控制器(Controller)。以
batchExportExamStudentsInfo方法为例,服务器端的PaymentInfoController接收到批量导出机考名单的请求。@PostMapping("/batch_export_exam_students") public SaResult batchExportExamStudentsInfo(@RequestBody BatchSetTeachersInfoRO batchSetTeachersInfoRO) { // ... PageRO<BatchSetTeachersInfoRO> batchSetTeachersInfoROPageVO = new PageRO<>(); batchSetTeachersInfoROPageVO.setEntity(batchSetTeachersInfoRO); if(roleList.contains(SECOND_COLLEGE_ADMIN.getRoleName())){ CollegeInformationPO userBelongCollege = scnuXueliTools.getUserBelongCollege(); batchSetTeachersInfoROPageVO.getEntity().setCollege(userBelongCollege.getCollegeName()); boolean send = messageSender.sendExportMsg(batchSetTeachersInfoROPageVO, collegeAdminFilter, userId); if (send) { return SaResult.ok("导出学籍数据成功"); } }else if(roleList.contains(XUELIJIAOYUBU_ADMIN.getRoleName())){ boolean send = messageSender.sendExportMsg(batchSetTeachersInfoROPageVO, managerFilter, userId); if (send) { return SaResult.ok("导出学籍数据成功"); } } } -
发送消息到消息队列
紧接着,根据不同用户角色,构造一个
PageRO<BatchSetTeachersInfoRO>对象,并调用messageSender的sendExportMsg方法,将下载任务发送到消息队列中。在此过程中,
sendExportMsg方法创建一个包含任务信息的JSON对象,并使用rabbitTemplate.convertAndSend方法将该消息发送到指定的RabbitMQ队列。boolean send = messageSender.sendExportMsg(pageRO, filter, userId);sendExportMsg 是笔者根据
SpringBoot的rabbiltTemplate自行封装的。封装了rabbitTemplate.convertAndSend方法,而rabbitTemplate.convertAndSend方法的参数是一个队列的名称,一个消息的实体类对象。而笔者在sendExportMsg方法中,就是把传入的pageRO, filter, userId属性做一个拼接成convertAndSend中传输的方法。方法签名如下:
- 参数列表:
PageRO<?> pageRO: 这是一个泛型类对象,用于包装要导出的数据。PageRO类似于一个分页响应对象,其中entity属性被用来存储具体的数据实体。AbstractFilter filter: 这是一个过滤器的抽象类对象,实际上传入的是按照实际情况的实现的Filter。名为过滤器,实际上就是一个封装了特殊行为的类。传入的继承了AbstractFilter,内部实现了具体的函数方法。这部分也是一个策略模式的具体实现(多态),将会在后面专门开一篇文章来讲解这部分~String userId: 用户的唯一标识,用于记录或验证是哪个用户发起的导出请求。
- 返回值: 方法返回一个布尔值
boolean,表示消息是否成功发送到消息队列。 - 这个方法
sendExportMsg用于向消息队列发送导出任务的消息,具体用于后台的异步数据处理。以下是该方法的详细介绍:
- 参数列表:
方法逻辑描述
-
JSON对象创建: 首先创建一个
JSONObject,用来封装要发送的消息内容。"type": 存储pageRO中实体的类名称,用于消息接收端识别处理的数据类型。"data": 将pageRO对象转换成JSON字符串,这样消息接收者可以反序列化回原始对象进行处理。"filter": 将过滤器对象转换成JSON字符串,允许消息接收端应用相同的数据筛选逻辑。"dataType": 标记消息的类型,此处为“普通消息”,可能用于区分不同优先级或类型的消息处理。"userId": 传递发起请求的用户ID,可能用于权限验证或跟踪用户行为。
-
消息发送: 使用
rabbitTemplate.convertAndSend方法将消息发送到指定的队列 (queue4)。这是通过 RabbitMQ 实现的,rabbitTemplate是 Spring AMQP 的核心类之一,用于消息的发送和接收。 -
日志记录:
- 成功发送消息后,记录一条成功日志。
- 如果发送过程中遇到
AmqpException(AMQP协议异常),则记录错误日志并返回false,表示消息发送失败。
/**
* 往消息队列中发送导出消息 后台异步处理导出任务
* @param pageRO
* @param filter
* @param userId
* @return
*/
public boolean sendExportMsg(PageRO<?> pageRO, AbstractFilter filter, String userId){
try {
// 创建一个包含数据和类型信息的JSON对象
JSONObject message = new JSONObject();
message.put("type", pageRO.getEntity().getClass().getName());
message.put("data", JSON.toJSONString(pageRO));
message.put("filter", JSON.toJSONString(filter));
message.put("dataType", "普通消息");
message.put("userId", userId);
this.rabbitTemplate.convertAndSend(queue4, message.toJSONString());
log.info("成功发送导出文件处理消息 ");
return true;
} catch (AmqpException e) {
log.error("发送导出文件处理消息失败: " + e.getMessage());
return false;
}
}
发送成功后,服务器立即向客户端返回一个操作成功的响应。
if (send) {
return SaResult.ok("导出考试名单信息成功");
}
至此,消息发送结束。
3.2 消息消费

在这个后半部分的流程中,主要关注的是如何在后端服务中处理通过消息队列接收到的导出任务。我们以导出老师学生的信息为例:
3.2.1 在MessageReceiver类内
-
监听和接收消息队列中的导出任务:
后端服务使用
@RabbitListener注解来监听消息队列。当sendExportMsg方法发送消息到队列时,相应的监听器会触发processExportData方法,开始处理导出任务。@RabbitListener(queuesToDeclare = { @Queue("${spring.rabbitmq.queue3}"), @Queue("${spring.rabbitmq.queue4}") }) @RabbitHandler public void processExportData(String messageContent, Channel channel, Message msg) { // ... } -
解析消息内容并执行业务逻辑
在
processExportData方法中,接收到的消息内容被解析为JSON对象。根据type字段的值,方法确定如何处理消息。对于机考名单导出类型的消息,会调用exportExamStudentsInfo方法进行处理。else if ("com.scnujxjy.backendpoint.model.ro.exam.BatchSetTeachersInfoRO".equals(type)) { PageRO<BatchSetTeachersInfoRO> pageRO = JSON.parseObject(message.getString("data"), new TypeReference<PageRO<BatchSetTeachersInfoRO>>() { }); String loginId = message.getString("userId"); String dataType = message.getString("dataType"); List<String> roleList = StpUtil.getRoleList(loginId); // 生成下载消息 PlatformMessagePO platformMessagePO = scnuXueliTools.generateMessage(loginId); if (roleList.contains(RoleEnum.XUELIJIAOYUBU_ADMIN.getRoleName())) { // 学历教育部管理员 AbstractFilter managerFilter = JSON.parseObject(message.getString("filter"), new TypeReference<ManagerFilter>() { }); log.info("接收到批量导出考试信息消息,开始准备数据 "); if(dataType.equals("机考名单")){ managerFilter.exportExamStudentsInfo(pageRO.getEntity(), loginId, platformMessagePO); }else{ managerFilter.exportExamTeachersInfo(pageRO.getEntity(), loginId, platformMessagePO); }
接下来,我们以传入的message对应的type == com.scnujxjy.backendpoint.model.ro.exam.BatchSetTeachersInfoRO为例子,分析一下是怎么使用 *managerFilter*.exportExamStudentsInfo(*pageRO*.getEntity(), *loginId*, *platformMessagePO*); 去批量导出(下载)文件的。
3.2.2 在managerFilter类内
-
数据库查询获取导出数据:
根据接收到的消息内容,例如
BatchSetTeachersInfoRO,进行数据库查询。
// 使用Mapper获取数据库中的考试名单数据
List<CourseExamInfoPO> courseExamInfoPOS = courseExamInfoMapper1.batchSelectData(entity);
// 处理数据,构造ExamStudentsInfoVO列表
-
Excel文件流的构建
使用从 Minio 获取的模板文件流,
exportExamStudentsInfo方法接下来创建一个ExcelWriter对象,并利用 EasyExcel 库将数据库查询到的数据填充到 Excel 模板中。这个过程创建了一个在内存中的 Excel 文件流(ByteArrayOutputStream)。ExcelWriter excelWriter = EasyExcel.write(outputStream, ExamStudentsInfoVO.class) .withTemplate(fileInputStreamFromMinio) .build(); -
使用EasyExcel库生成Excel文件:
利用EasyExcel和模板文件流,将查询到的数据填充进Excel模板中,并生成Excel文件。
ExcelWriter excelWriter = EasyExcel.write(outputStream, ExamStudentsInfoVO.class) .withTemplate(fileInputStreamFromMinio) .build(); FillConfig fillConfig = FillConfig.builder().forceNewRow(Boolean.TRUE).build(); excelWriter.fill(examStudentsInfoVOS, fillConfig, EasyExcel.writerSheet().build()); excelWriter.finish(); -
上传Excel文件到Minio服务:
生成的Excel文件作为字节流上传到Minio服务,并记录上传文件的大小。
ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray()); boolean b = minioService1.uploadStreamToMinio(inputStream, fileName, bucketName); -
数据库记录用户下载消息:
如果文件成功上传到Minio,更新数据库中的用户下载消息记录,提供文件的下载链接。
if (b) { // 插入或更新数据库中的下载消息记录 } -
确认或取消文件操作
一旦文件上传成功,相应的用户下载消息会被插入或更新到数据库中,确保前端能够检索到文件的下载链接。
如果文件成功上传到Minio,则通过消息通道确认消息处理成功;如果在处理过程中出现异常,则拒绝消息,可以选择是否重新入队。
if (b) { // 成功操作 channel.basicAck(msg.getMessageProperties().getDeliveryTag(), false); } else { // 异常操作 channel.basicNack(msg.getMessageProperties().getDeliveryTag(), false, false); }
在整个过程中,从接收消息开始,到从Minio获取模板,再到填充数据、生成文件、上传到Minio,并最终处理确认消息,整个数据导出任务是在后台服务中异步执行的。这个异步处理机制允许前端立即响应用户的请求,而无需等待文件的实际生成,从而显著提高了用户体验。
4. 文件存储和管理
4.1 如何在数据库中存储Minio的相对地址
为了在数据库中存储文件的相对地址,笔者使用一个实体类 GlobalConfigPO,该类映射到数据库中的一个表,可以用来存储各种配置信息,包括文件在Minio中的存储路径。
@Data
@TableName("global_config")
public class GlobalConfigPO implements Serializable {
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String configKey;
private String configValue; // 存储Minio文件路径
private String description;
private Date updatedAt;
}
当需要存储一个文件路径时,可以这样做:
GlobalConfigPO config = GlobalConfigPO.builder()
.configKey("file_path")
.configValue("minio/bucket/path/to/file")
.description("Minio中文件的存储路径")
.build();
globalConfigMapper.insert(config);
这样,文件的路径就被存储在数据库中,方便进行管理和检索。

4.2 文件命名设计-枚举类设计
文件命名的设计至关重要。为了对需要下载或上传的文件进行命名,笔者采用了一种结合了硬编码和动态拼接的模式。在硬编码部分,笔者利用枚举来管理Minio的桶名和子目录,这样可以确保文件存储在正确的位置。而在动态部分,笔者通常包含时间戳和用户信息,以确保每个文件名的唯一性。这种方法既保证了文件名的逻辑性和可管理性,又确保了文件名的唯一性,从而提高了系统的可靠性和效率。
为了应对多种Minio的变量名存储,笔者设计了一个枚举类。MinioBucketEnum 枚举类扮演了一个关键角色。它为Minio存储的不同数据类型定义了统一的桶名和子目录,这种设计有助于组织和标准化文件存储结构,同时也简化了文件管理。
@Getter
public enum MinioBucketEnum {
// 定义不同类型的数据存储桶和子目录
DATA_DOWNLOAD_STUDENT_STATUS("dataexport", "学籍数据"),
DATA_DOWNLOAD_SCORE_INFORMATION("dataexport", "成绩数据"),
DATA_DOWNLOAD_STUDENT_FEES("dataexport", "缴费数据"),
DATA_DOWNLOAD_SYSTEM("dataexport", "系统反馈数据"),
DATA_DOWNLOAD_EXAM_THEACHER("dataexport", "考试教师信息导出"),
DATA_DOWNLOAD_EXAM_STUDENT("dataexport", "考试考生信息导出"),
DATA_DOWNLOAD_ADMISSION_STUDENT("dataexport", "新生录取信息导出"),
DATA_DOWNLOAD_CLASS_INFORMATIONS("dataexport", "班级数据"),
ANNOUNCEMENT_BUCKET("dataexport", "公告附件数据");
private final String bucketName;
private final String subDirectory;
MinioBucketEnum(String bucketName, String subDirectory) {
this.bucketName = bucketName;
this.subDirectory = subDirectory;
}
}
通过枚举类定义的**桶名和子目录**,所有文件存储操作都遵循统一的路径标准。这不仅减少了路径硬编码的需要,也使得文件的组织和访问更加系统化和一致。
4.3 从数据库获取实体类,构建Excel文件上传
文件上传到Minio的过程涉及几个关键步骤:
- 数据写入:
- 使用
ByteArrayOutputStream收集需要上传的数据。这一步涉及将数据内容写入到内存中的一个字节流中。
- 使用
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
- 文件大小获取:
- 在数据完全写入流后,可以获取到数据的大小。
int fileSize = outputStream.size();
- 文件命名:
- 文件名的生成是根据当前的日期和时间来构建的,确保每个文件名的唯一性,同时附加用户信息,从而在多用户环境中避免命名冲突。
Date generateData = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd_HHmmss_SSS");
String currentDateTime = sdf.format(generateData);
String fileName = subDirectory + "/" + username + "_" + currentDateTime + "_examTeachersData.xlsx";
- 文件上传:
- 将
ByteArrayOutputStream转换为ByteArrayInputStream,以便上传数据到Minio。这一步骤是通过调用封装了Minio的API的uploadStreamToMinio(inputStream, fileName, bucketName);完成的,需要指定桶名和文件名。
- 将
ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray());
boolean success = minioService.uploadStreamToMinio(inputStream, fileName, bucketName);
简单介绍一下本处的uploadStreamToMinio(inputStream, fileName, bucketName)方法:
/**
* 把文件流直接写入到 Minio 作为一个文件
* @param inputStream
* @param fileName
*/
public boolean uploadStreamToMinio(InputStream inputStream, String fileName, String diyBucketName) {
try {
Map<String, String> headers = new HashMap<>();
headers.put("Content-Disposition", "attachment; filename*=UTF-8''" + URLEncoder.encode(fileName, "UTF-8"));
minioClient.putObject(
PutObjectArgs.builder()
.bucket(diyBucketName)
.object(fileName)
.stream(inputStream, -1, 10485760) // 10485760 是 10MiB
.headers(headers)
.build());
return true;
} catch (Exception e) {
log.error("上传文件到 Minio 失败: " + e.getMessage());
// throw new RuntimeException("上传文件到 Minio 失败: " + e.getMessage());
}
return false;
}
- InputStream inputStream: 这是要上传的文件的数据流。在实际应用中,这可以是从一个文件、数据库或任何其他数据源获取的数据流。
- String fileName: 上传到Minio后文件的名称,这也会成为对象存储中的对象键。
- String diyBucketName: 指定要上传文件的Minio存储桶名称。
相信各位读者在阅读的时候,也能很清楚地发现这方法就是一个动态拼装,通过传递的数据流、文件名和桶名作为参数传入构造方法中,然后利用Springboot提供的minioClient来自动构造。但是读者可能会疑惑,本处在 minioClient.putObject传入的Map参数是什么?
这个Map参数实际上是用来存放HTTP头部信息,其中最关键的一个是Content-Disposition。Content-Disposition头部在HTTP协议中用来指定客户端接收到的内容该如何处理。
它支持以下两种基本的呈现形式:
- inline:
inline默认值,意味着内容应当直接在浏览器中显示,例如图片或PDF文档,如果内容类型被浏览器支持的话。- 例:
Content-Disposition: inline
- attachment:
attachment指示浏览器将响应视为一个文件,提示用户下载或询问存储位置。这是控制文件作为下载项提供给用户的标准方法。- 例:
Content-Disposition: attachment; filename="filename.jpg"
本处在我们的上下文中,当文件通过Minio服务上传后,这个头部将决定文件在被下载时的表现形式,比如文件是否应当直接在浏览器中显示(inline),还是作为一个附件提供给用户下载(attachment)。
特别地,这里我们设置了Content-Disposition为“attachment”,这意味着文件将被作为附件处理。这是非常适合下载操作的设置,因为它会提示用户保存文件,而不是直接在浏览器中打开。此外,该头部还支持一个非常有用的参数filename,这允许我们指定一个默认的文件名,当用户保存文件时,这个名字将会被浏览器自动使用。
为了解决可能的文件名编码问题(特别是包含非ASCII字符的文件名),我们还使用了filename*参数,该参数允许文件名包含特殊字符,通过URL编码的方式进行传递。这种方式确保了无论用户的操作系统是什么,文件名都能正确显示,避免了因字符编码问题导致的文件名错误或损坏:
headers.put("Content-Disposition", "attachment; filename*=UTF-8''" + URLEncoder.encode(fileName, "UTF-8"));
这段代码通过URL编码fileName并将其设置到Content-Disposition中,确保了文件名在HTTP头部中的正确传递和解析。通过这种方法,无论文件名中包含何种字符,都能被正确处理,从而在用户下载文件时提供无缝和准确的用户体验。
5.文件数据变更记录
在开发过程中,处理文件上传并确保跟踪数据正确无误是一个核心任务。我们不仅要确保文件被安全上传到Minio,还要更新数据库以记录这一事件,以便进行进一步的操作或审计。
当应用成功将文件上传到Minio后,下一步是记录这一事件。这不仅有助于追踪文件的状态,也是确保用户和系统能够访问到最新数据的关键步骤。
5.1 创建和插入下载消息记录
首先,假设上传操作成功(即if (b)返回true),我们需要创建一个记录实体,这里使用的是DownloadMessagePO。这个实体将保存关键信息,如文件的创建时间、文件名、文件在Minio中的URL和文件大小。这样的记录对于后续的用户下载请求非常重要,因为它们提供了文件的具体存储位置和其他元数据。
DownloadMessagePO downloadMessagePO = new DownloadMessagePO();
downloadMessagePO.setCreatedAt(generateData);
downloadMessagePO.setFileName(DownloadFileNameEnum.EXAM_TEACHERS_EXPORT_FILE.getFilename());
downloadMessagePO.setFileMinioUrl(bucketName + "/" + fileName);
downloadMessagePO.setFileSize((long) fileSize);
int insert = downloadMessageMapper.insert(downloadMessagePO);
log.info("下载考试信息数据、下载文件消息插入 " + insert);
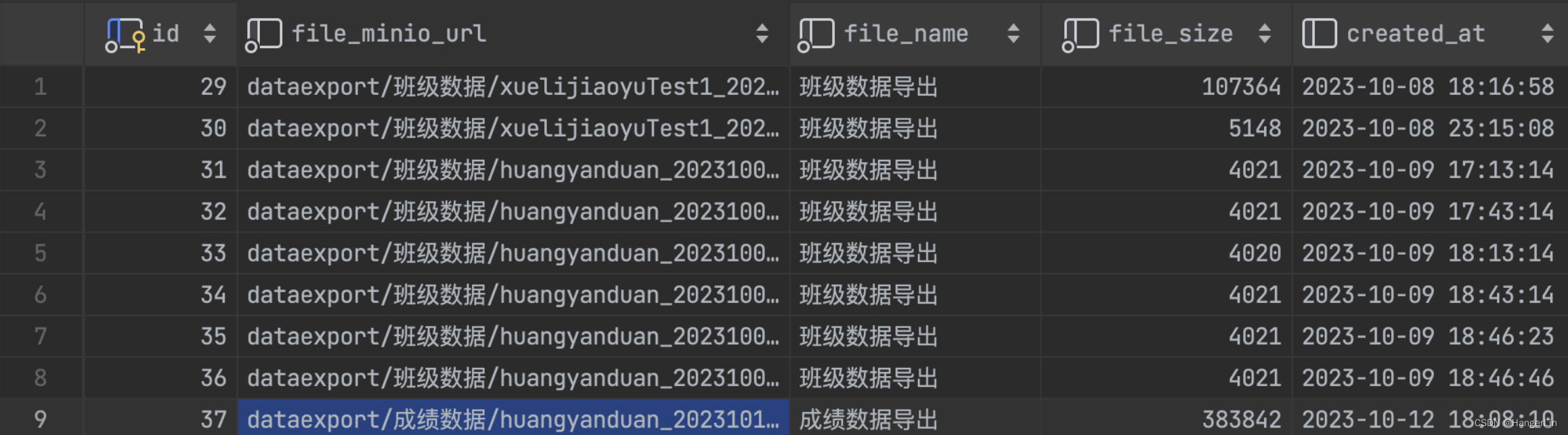
在这段代码中,每一个属性的设置都承担着特定的数据追踪功能,确保所有相关信息都被系统记录并可查询。例如,setFileMinioUrl存储了文件在Minio中的具体位置,这对于后续的访问尤为重要。
5.2 更新关联消息记录
接下来,如果涉及到系统中其他相关的操作或消息(这里假设是关于平台信息的更新),我们需要利用已创建的下载消息记录的ID来更新其他记录。这是数据一致性和完整性的关键步骤,确保所有相关的系统部分都引用到正确的数据。
Long generatedId = downloadMessagePO.getId();
platformMessagePO.setRelatedMessageId(generatedId);
int update = platformMessageMapper.updateById(platformMessagePO);
log.info("机考信息附件1下载消息所需附件生成完毕 更新结果 " + update);
这里,generatedId是新插入的下载消息记录的自动生成ID,它被用来更新平台消息记录,指明这两条记录之间的关联。
在后续的“群发消息的设计”的文章中,笔者将会讲解,为什么使用两张数据库表相互关联,以及这么设计的原因是什么。
6. 结语
在本章中,笔者深入探讨了通过利用消息队列技术来优化大规模Excel文件下载的策略。通过消息队列的应用,我们实现了任务的异步处理,有效分担了高峰时段的服务器负载,提升了系统的响应能力和用户体验。
如大家所见,消息队列不仅提高了数据处理的效率,还通过异步执行增加了系统的可扩展性和弹性。结合Minio文件存储系统,我们进一步增强了文件管理的安全性和效率,实现了多文件云端存储的搭建。
转向下一章《(二)高效异步:消息队列加速Excel文件的异步上传》,笔者将继续探索消息队列在文件上传过程中的应用。各位读者将看到,尽管处理的是数据的上传,但许多策略和技术原理与下载过程相似,依旧围绕异步处理和性能优化进行。我们将详细讲解文件上传的架构设计、消息处理流程及性能优化技巧,帮助你全面理解如何在高负载环境下保持系统的高性能和稳定性。
请继续关注,了解如何将这些高效策略应用于文件上传,进一步提升系统架构的性能表现。
希望大家看到这里都能有所收获!