提示:今天结束机器学习预测部分,从最开始的数据处理到最后模型评估全过程。拥有详细的教程,还浅讨论了AI对编写的影响。
文章目录
前言
从年前开始的机器学习专栏今天终于迎来大结局啦!(看到好多人开收费专栏,内容却水得不行,个人对这种行为表示强烈“嫌弃”。郑重声明:本人专栏永远不会收费,知识尽我最大努力分享,欢迎点评吐槽!)其实大结局的内容我思考了很久,迟迟没有更新,主要是因为最近deepseek爆火,蹭一波deepseek的流量连出了几集教程。不过,还是要回归初心——本博客的宗旨是为大家提供机器学习、深度学习和强化学习的基础入门知识。今天,终于要完成大结局的任务了!
最近我在抖音上看车,总是被直播间的**“一键查询底价诱惑”吸引,然后手一抖就填了懂车帝或者易车的手机号。结果,不出三秒,销售电话就来了,速度快得让我怀疑他们是不是住在基站旁边。于是我就好奇了:他们能不能根据我填的信息**,判断出我是个“买不起豪车但爱看豪车”的群体呢?还有一个主要原因前几期的任务都是回归任务,所以本集完成一个分类任务,这样这一个系列就完整了。今天我们就来聊聊这个话题,顺便给专栏画上一个圆满的句号!
和朋友最近讨论的一个问题,deepseek可以写程序,我们还需要学程序吗?
个人理解:AI 会写代码,但不会"思考代码"。AI 能读懂需求生成代码,本质是提取拼凑数据,遇到复杂场景就会卡壳。真正的学习编程技术能培养发现、拆解和解决问题的能力,这是 AI 无法替代的。未来竞争在于与 AI 合作,会用 AI 的人将超越只会依赖 AI 的人。
所以要自己掌握某种算法的实现流程和每一步具体的意义是目前学习算法的捷径,剩下的琐碎复杂的内容可以问AI。(个人见解欢迎讨论)
提示:以下是本篇文章正文内容,下面案例可供参考
一、项目背景及意义
市场竞争分析:汽车市场竞争激烈,汽车厂商和经销商需要深入了解客户特征和行为,以便制定更有针对性的营销策略,在市场竞争中占据优势。通过分析客户数据,可以了解不同客户群体的需求和偏好,为产品定位和市场推广提供依据。
客户关系管理:良好的客户关系管理对于提高客户满意度和忠诚度至关重要。借助客户数据集,企业能够更好地理解客户的购买行为、消费习惯等,从而提供个性化的服务和关怀,增强客户与企业之间的互动和联系,促进客户的重复购买和口碑传播。
产品研发与创新:了解客户对汽车产品的期望和需求,有助于汽车厂商在产品研发过程中更精准地把握市场方向,进行产品创新和优化。根据客户数据反馈,企业可以确定哪些功能和特性是客户最关注的,从而在新产品开发中加以重点考虑,提高产品的市场适应性和竞争力。
二、数据集介绍
数据来源:百度飞桨公开数据集。地址为:https://aistudio.baidu.com/datasetdetail/109871
数据规模:汽车客户数据集包含2627个测试实例,8068个训练实例,可用于客户分类。数据下载之后如下图所示:
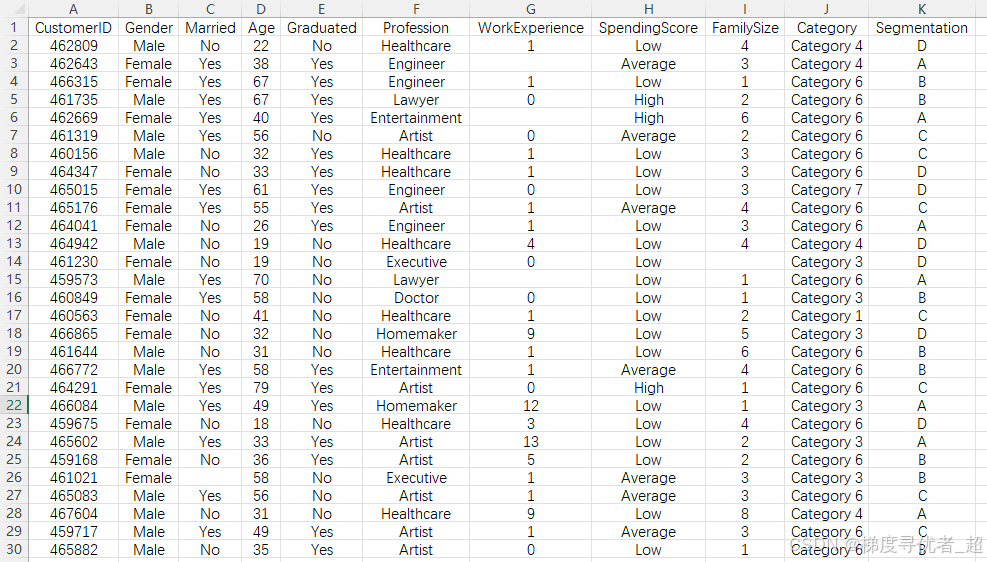
特征说明
Gender:表示客户的性别,通常为 “Male”(男性)或 “Female”(女性),用于分析不同性别客户在汽车购买行为等方面的差异。
Married:反映客户的婚姻状况,可能取值为 “是” 或 “否”,可以帮助了解已婚和未婚客户在购车决策上的特点。
Graduated:显示客户是否毕业,可能为 “Graduated”(毕业)或 “Not Graduated”(未毕业)等,用于探究教育程度对购车行为的影响。
Profession:记录客户的职业,如 “Engineer”(工程师)、“Teacher”(教师)等各种职业类型,不同职业的客户可能对汽车的品牌、款式、功能等有不同的需求。
SpendingScore:消费得分,可能是根据客户在汽车相关消费或其他消费领域的表现,综合评估得出的一个反映客户消费能力或消费倾向的指标,一般可以分为低、中、高不同等级。
Segmentation:客户细分类别,根据客户的综合特征将客户划分为不同的群体,如经济型客户、豪华型客户等,有助于企业针对不同细分市场制定差异化的策略。
Age:客户的年龄,是分析客户需求和购买行为的重要因素,不同年龄段的客户对汽车的需求和偏好往往不同。
WorkExperience:客户的工作经验,可能以年为单位,与客户的收入水平、消费能力等可能存在一定的关联。
Category:可能与汽车的类别或客户所属的某种分类相关,具体含义需要根据数据收集的背景和目的来确定。
三、具体实现步骤
1.导入数据及预处理
进行最基本的数据预处理,缺失值填充和异常值处理以及重复值去除,当然这个地方不同数据操作也不太一样。
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
# 读取数据集
data = pd.read_csv('/home/aistudio/data/data109871/train-set.csv')
# 查看数据集基本信息和前几行
print("数据基本信息:")
data.info()
print("数据前几行信息:")
print(data.head().to_csv(sep='\t', na_rep='nan'))
# 1. 处理缺失值
# 对于数值型特征,使用均值填充
numeric_columns = data.select_dtypes(include=['number']).columns
for col in numeric_columns:
data[col].fillna(data[col].mean(), inplace=True)
# 对于分类型特征,使用众数填充
categorical_columns = data.select_dtypes(include=['object']).columns
for col in categorical_columns:
data[col].fillna(data[col].mode()[0], inplace=True)
# 2. 处理异常值
# 这里以年龄为例,假设年龄合理范围在 18 到 100 岁之间
min_age = 18
max_age = 100
if 'Age' in data.columns:
data['Age'] = data['Age'].apply(lambda x: min_age if x < min_age else (max_age if x > max_age else x))
# 3. 去除重复值
data.drop_duplicates(inplace=True)
2.特征编码
从数据中能看到有一些字符串格式的数据,让模型识别文本信息是不可能的吧。所以这类数据就需要转化,常见的转换方式是Label Encoding 和 One-Hot Encoding 编码。
1. Label Encoding(标签编码)
Label Encoding 就是把每个类别(比如职业、性别等)用一个数字来表示。比如:
- 职业有
Engineer,Doctor,Artist,我们可以分别用0,1,2来表示。 - 性别有
Male,Female,我们可以用0,1来表示。
例子:
原始数据:
| Profession |
|---|
| Engineer |
| Doctor |
| Artist |
| Engineer |
Label Encoding 后:
| Profession |
|---|
| 0 |
| 1 |
| 2 |
| 0 |
优点:
- 简单直接,只需要一列就能表示类别。
- 适合树模型(如决策树、XGBoost),因为这些模型能处理数值型特征。
缺点:
- 可能会让模型误以为类别之间有大小关系。比如
Artist=2比Engineer=0大,但实际上它们只是不同的类别,没有大小之分。
2. One-Hot Encoding(独热编码)
One-Hot Encoding 是把每个类别拆分成多个二进制列,每个列表示一个类别。如果某个样本属于这个类别,对应的列就是 1,否则就是 0。
例子:
原始数据:
| Profession |
|---|
| Engineer |
| Doctor |
| Artist |
| Engineer |
One-Hot Encoding 后:
| Profession_Engineer | Profession_Doctor | Profession_Artist |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
| 1 | 0 | 0 |
优点:
- 避免了类别之间的大小关系问题,每个类别都是独立的。
- 适合线性模型(如逻辑回归、线性回归),因为这些模型需要数值型特征,且不能处理类别之间的虚假关系。
缺点:
- 如果类别很多,会导致特征数量爆炸。比如有 100 种职业,就会生成 100 列。
- 对于树模型来说,可能会增加计算负担。
对比总结
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Label Encoding | 类别数量较少,且模型能处理数值关系 | 简单,不增加特征数量 | 可能引入虚假的大小关系 |
| One-Hot Encoding | 类别数量较少,且模型不能处理数值关系 | 避免虚假关系,适合线性模型 | 类别多时特征爆炸,增加计算负担 |
实际选择
- 如果类别较少(比如性别、是否毕业等),优先用 One-Hot Encoding。
- 如果类别较多(比如职业、城市等),优先用 Label Encoding,或者更高级的编码方法(如 Target Encoding)。
- 如果是树模型(如 XGBoost、随机森林),可以尝试 Label Encoding,因为树模型能处理数值关系。
- 如果是线性模型(如逻辑回归、线性回归),优先用 One-Hot Encoding。
下面是程序实现
由于本文计划采用xgboost和随机森林模型,所以就直接采用 Label Encoding编码。
# 步骤 1:读取数据
df = data
# 步骤 2:提取 Category 列中的数值
df['Category'] = df['Category'].str.extract('(\d+)').astype(int)
# 步骤 3:对分类变量进行 Label Encoding
# 初始化编码器字典(可选,用于后续逆转换)
label_encoders = {}
# 需要编码的列
categorical_cols = ['Gender', 'Married', 'Graduated', 'Profession', 'SpendingScore','Segmentation']
for col in categorical_cols:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
label_encoders[col] = le # 保存编码器(可选)
# 步骤 4:验证编码结果
print(df[['Gender', 'Married', 'Graduated', 'Profession', 'Category', 'Segmentation']].head())
3.数据可视化
本文主要展示
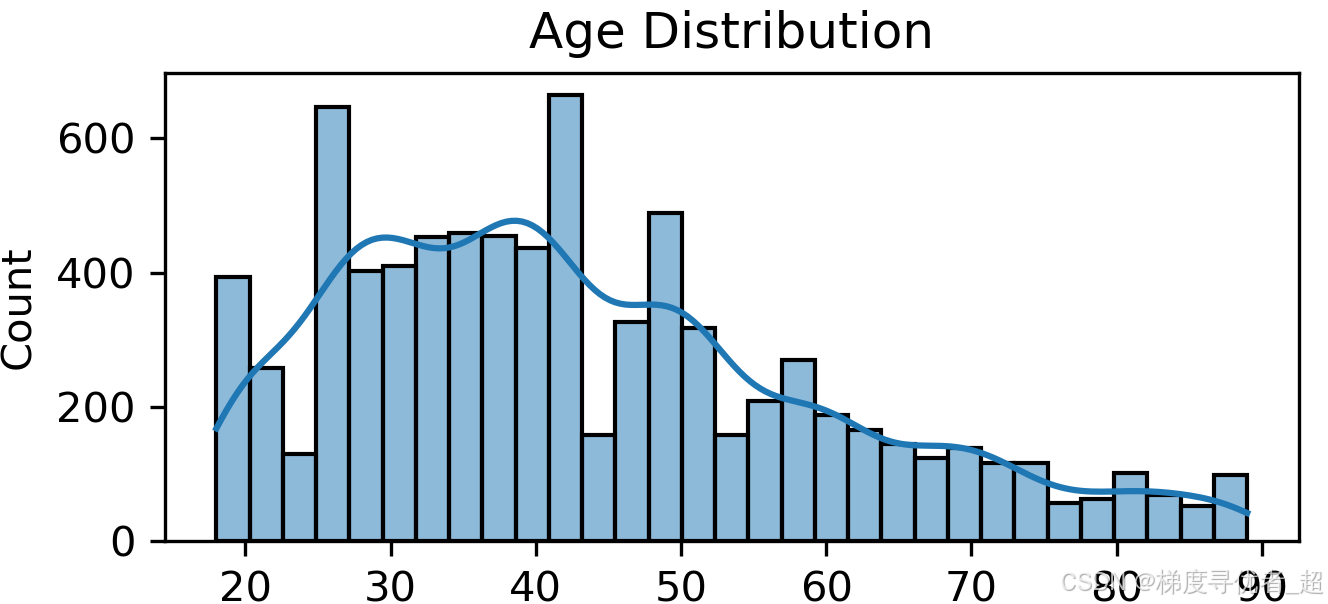
Age 分布直方图:使用 seaborn 的 histplot 函数绘制 Age 列的直方图,并添加核密度估计曲线,以展示年龄的分布情况。
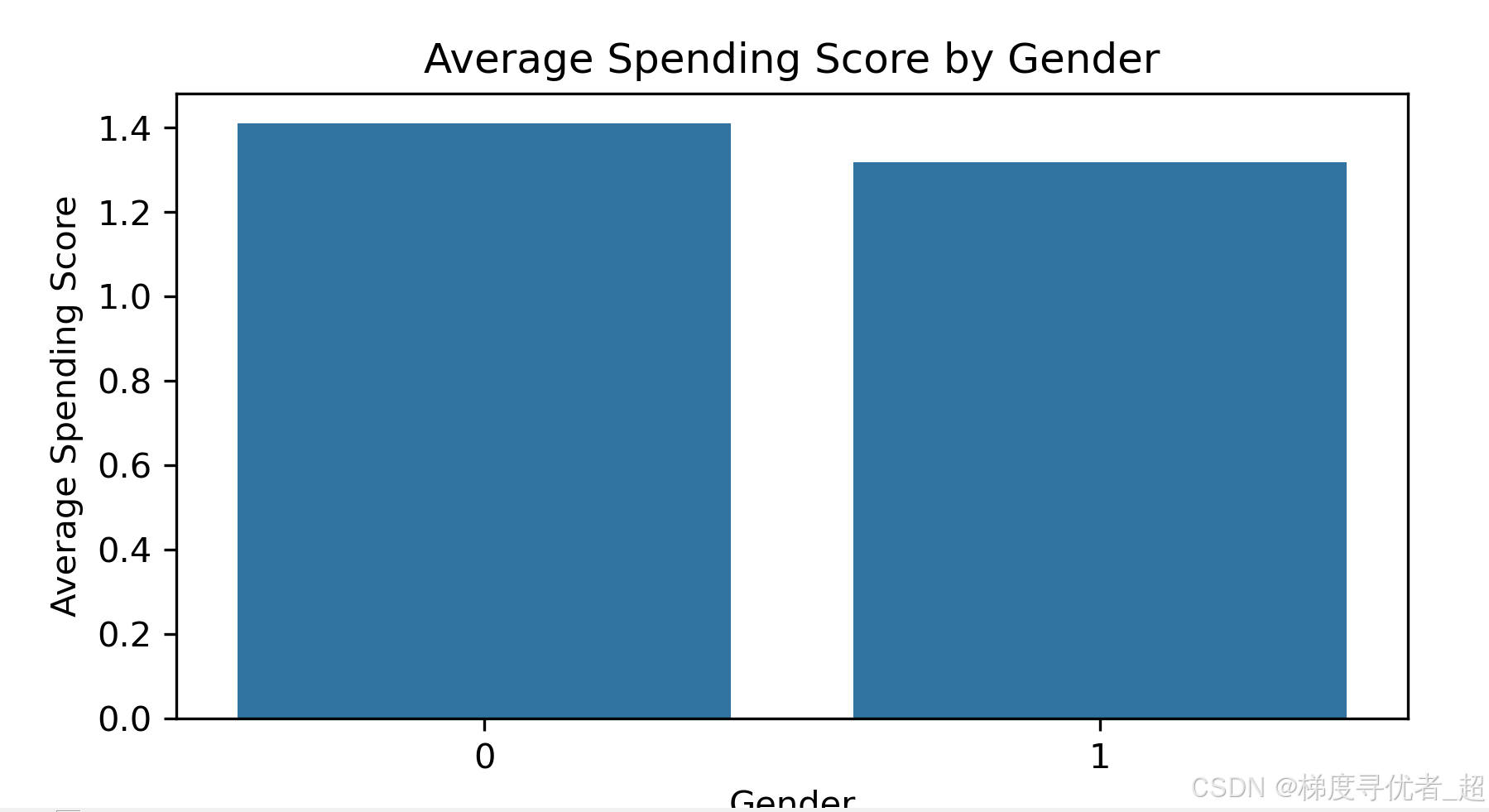
不同 Gender 下的 SpendingScore 均值柱状图:通过 groupby 方法计算不同 Gender 编码下的 SpendingScore 均值,然后使用 seaborn 的 barplot 函数绘制柱状图。
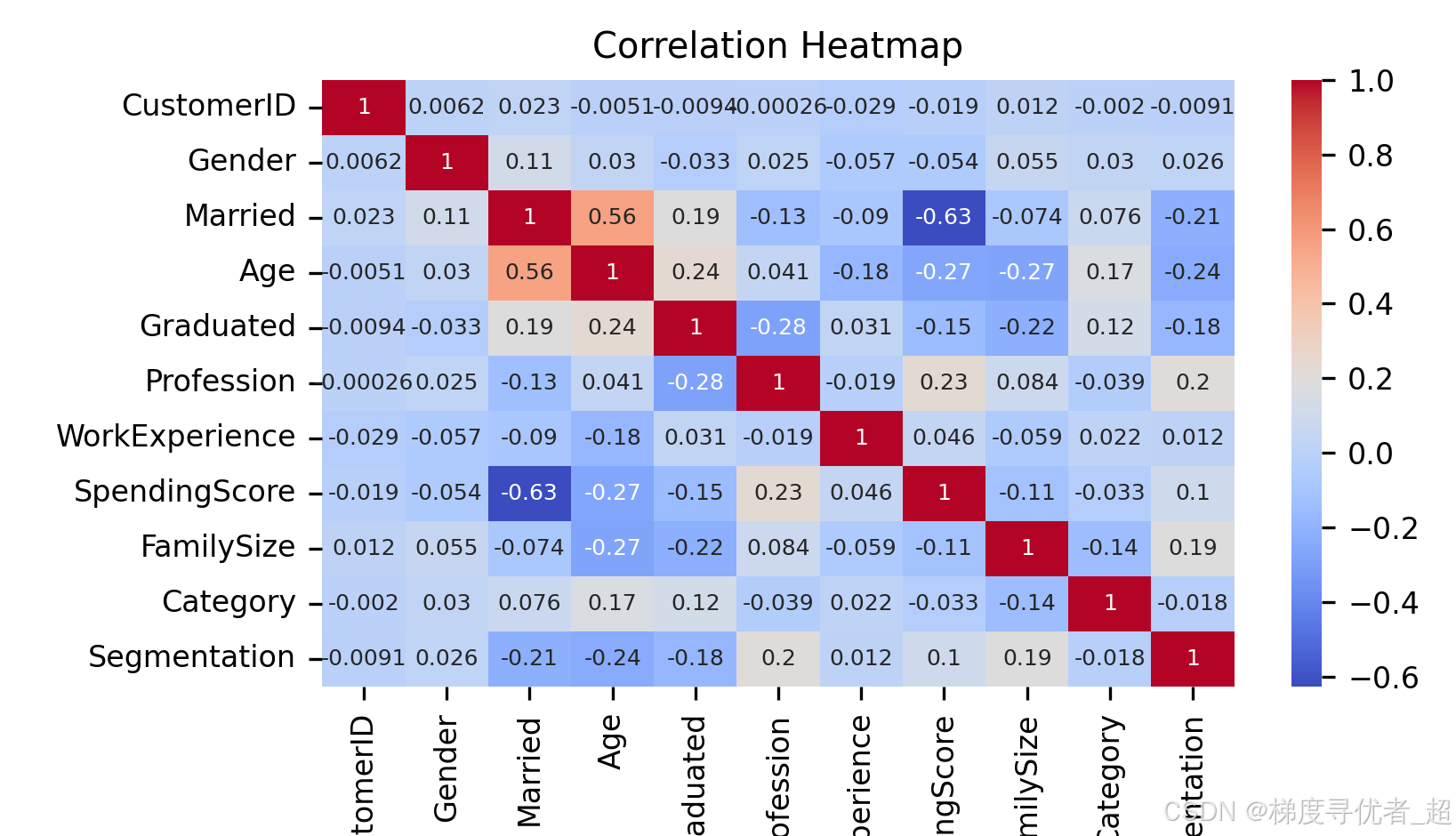
相关性热力图:使用 pandas 的 corr 方法计算特征之间的相关性矩阵,然后使用 seaborn 的 heatmap 函数绘制热力图,直观展示特征之间的相关性。
程序实现:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取编码后的数据
encoded_df = df
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 设置全局字体大小
plt.rcParams.update({'font.size': 8})
# 1. 查看 Age 列的分布(假设 Age 列存在且为数值型)
if 'Age' in encoded_df.columns:
plt.figure(figsize=(6, 4)) # 减小画布尺寸
sns.histplot(encoded_df['Age'], kde=True)
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Count')
plt.show()
# 2. 查看不同 Gender 编码下的 SpendingScore 均值
if 'Gender' in encoded_df.columns and 'SpendingScore' in encoded_df.columns:
gender_spending = encoded_df.groupby('Gender')['SpendingScore'].mean()
plt.figure(figsize=(6, 4)) # 减小画布尺寸
sns.barplot(x=gender_spending.index, y=gender_spending.values)
plt.title('Average Spending Score by Gender')
plt.xlabel('Gender')
plt.ylabel('Average Spending Score')
plt.show()
# 3. 绘制特征之间的相关性热力图
correlation_matrix = encoded_df.corr()
plt.figure(figsize=(8, 6)) # 减小画布尺寸
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', annot_kws={'size': 6}) # 减小热力图注解字体大小
plt.title('Correlation Heatmap')
plt.show()
结果效果:
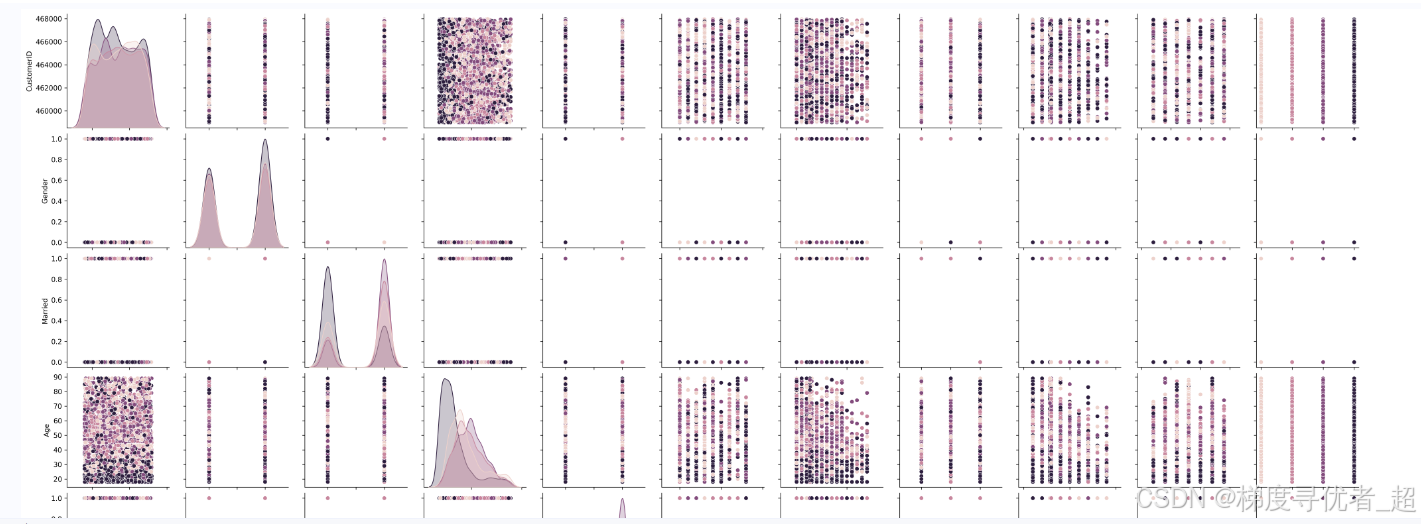
Pair Plot(成对图) 是一种非常有用的可视化工具,它可以同时展示多个数值型特征之间的两两关系,还能展示每个特征与目标变量之间的关系,并且有助于发现数据中的异常值和偏差。
分析要点:
特征之间的相关性:在对角线上方和下方的散点图中,可以观察到不同特征之间的关系。如果散点图呈现出明显的线性或非线性趋势,说明这两个特征之间存在相关性。
与目标变量的关系:通过不同颜色的数据点(由 hue 参数指定),可以观察到每个特征与目标变量之间的关系。例如,不同类别的数据点在某个特征上的分布是否有明显差异。
异常值和偏差:在散点图中,如果存在远离其他数据点的孤立点,可能是异常值。同时,观察数据点的分布是否均匀,是否存在明显的偏差。
实现程序:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取编码后的数据
encoded_df = df
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 选择数值型特征
numeric_columns = encoded_df.select_dtypes(include=['number']).columns
# 设置目标变量是 Segmentation
target_variable = 'Segmentation'
# 绘制 Pair Plot
g = sns.pairplot(encoded_df, vars=numeric_columns, hue=target_variable)
plt.title('Pair Plot of Numeric Features')
plt.show()
总结:
数据可视化的主要目的第一是检查数据分布和有无异常数据影响模型训练,第二目的是筛选特征,揭示特征相关性,可视化可以直观地展示特征之间的相关性。例如,使用热力图可以清晰地看到各个特征之间的相关系数,帮助我们找出哪些特征之间存在较强的相关性,从而在特征选择时避免引入冗余特征,提高模型的性能和解释性。
4.特征工程(特征的选择)
本文根据简单的观察相关性热力图发现,客户编号和最后的客户分类相关性较低。所以剔除这一列数据进行训练。剔除方法为从第二列读取。(当然工作经验相关性也不高,也可以删除哈,具体很多内容都可以自己做实验哈)
代码如下:
import numpy as np
from sklearn.preprocessing import MinMaxScaler # 导入sklearn中的MinMaxScaler,用于特征缩放
values = df.values[:,1:] #只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:
# 把数据集分为训练集和测试集
values = np.array(values)
# 将前面处理好的DataFrame(data)转换成numpy数组,方便后续的数据操作。
num_samples = values.shape[0]
per = np.random.permutation(num_samples) # 打乱后的行号
n_train_number = per[:int(num_samples * 0.8)] # 选择80%作为训练集
n_test_number = per[int(num_samples * 0.8):] # 选择除过80%之外的作为测试集
# 计算训练集的大小。
# 设置80%作为训练集
# int(...) 确保得到的训练集大小是一个整数。
Xtrain = values[n_train_number, :-1] # 取特征列
Ytrain = values[n_train_number, -1] # 取最后一列为目标列
Ytrain = Ytrain.reshape(-1, 1)
Xtest = values[n_test_number, :-1]
Ytest = values[n_test_number, -1]
Ytest = Ytest.reshape(-1, 1)
# 对训练集和测试集进行归一化
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain) # 注意fit_transform() 和 transform()的区别
vp_test = m_in.transform(Xtest) # 注意fit_transform() 和 transform()的区别
# 注意:分类任务对Y不需要归一化
vt_train =Ytrain
vt_test = Ytest
对于分类任务可以不进行归一化操作,但要注意目标列是不能进行归一化操作的。但是通过我的实验发现归一化操作可以提高模型的精确率,上述代码进行了特征列目标列的选择,还进行了数据集划分。
注意:代码写的较为啰嗦和冗余,主要原因是和前几集的回归任务对应起来,不喜勿碰哈,但个人保证代码是完整的,复制即可用。
5.模型构建
本文构建XGboost模型和随机森林模型进行。
XGboost模型构建:
# 创建 XGBClassifier 模型
import xgboost as xgb
model = xgb.XGBClassifier(n_estimators=500,
learning_rate=0.08,
subsample=0.75,
colsample_bytree=1,
max_depth=7,
gamma=0)
# 拟合模型
model.fit(vp_train, vt_train)
随机森林模型:
from sklearn.ensemble import RandomForestClassifier
# 将模型替换为 RandomForestClassifier
model = RandomForestClassifier(n_estimators=60, max_features='sqrt', random_state=42)
# 训练模型
model.fit(vp_train, vt_train)
6.模型评估
先介绍分类任务的常用评估指标和回归任务大有不同
-
准确率(Accuracy):模型预测正确的样本占总样本的比例。
例子:如果有 100 个样本,模型正确预测了 90 个,那么准确率就是 90%。
适用场景:适用于类别分布均衡的情况。如果类别不平衡(例如 95% 是正类,5% 是负类),准确率可能会误导。 -
精确率(Precision):模型预测为正类的样本中,实际也是正类的比例。
例子:模型预测了 50 个样本为正类,其中 45 个确实是正类,那么精确率就是 90%。
适用场景:关注预测的准确性,例如垃圾邮件分类(希望尽可能少的正常邮件被误判为垃圾邮件)。 -
召回率(Recall):实际为正类的样本中,模型预测为正类的比例。
例子:实际有 60 个正类样本,模型预测出了其中的 50 个,那么召回率就是 83.3%。
适用场景:关注不漏掉正类,例如疾病检测(希望尽可能少的患者被漏诊)。 -
F1 分数(F1 Score):精确率和召回率的调和平均值,用于平衡两者。
公式:F1 = 2 × (精确率 × 召回率) / (精确率 + 召回率)
例子:如果精确率是 90%,召回率是 80%,那么 F1 分数就是 84.7%。
适用场景:当精确率和召回率都很重要时,F1 分数是一个综合指标。 -
混淆矩阵(Confusion Matrix)一个表格,展示模型预测结果与实际结果的对比。
| 例子 | 预测为正类 | 预测为负类 |
|---|---|---|
| 实际为正类 | 45 (TP) | 5 (FN) |
| 实际为负类 | 10 (FP) | 40 (TN) |
- TP(True Positive):实际为正类,预测为正类。
- FN(False Negative):实际为正类,预测为负类。
- FP(False Positive):实际为负类,预测为正类。
- TN(True Negative):实际为负类,预测为负类。
- 适用场景:直观展示模型的分类效果,尤其是多分类任务。
-
ROC 曲线和 AUC
ROC 曲线:展示模型在不同阈值下的真阳性率(Recall)和假阳性率(FP Rate) 的关系。
AUC:ROC 曲线下的面积,值越大,模型性能越好。
例子:AUC = 0.9 表示模型有 90% 的概率能够正确区分正类和负类。
适用场景:适用于二分类任务,尤其是类别不平衡的情况。 -
PR 曲线和 AP
PR 曲线:展示模型在不同阈值下的精确率(Precision)和召回率(Recall) 的关系。
AP(Average Precision):PR 曲线下的面积,值越大,模型性能越好。
适用场景:适用于类别不平衡的情况,尤其是关注正类的任务。
程序实现:
from prettytable import PrettyTable
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
confusion_matrix,
precision_recall_curve,
average_precision_score,
)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import label_binarize
# model 是训练好的分类模型,vp_test 是测试集特征,Ytest 是测试集真实标签
yhat = model.predict(vp_test)
def evaluate_classification(Ytest, yhat):
# 初始化存储各个评估指标的列表
accuracy_list = []
precision_list = []
recall_list = []
f1_list = []
average_precision_list = [] # 存储每个类别的平均精确率(AP)
confusion_matrices = []
# 创建一个 PrettyTable 对象来展示结果
table = PrettyTable(['Class', 'Accuracy', 'Precision', 'Recall', 'F1 Score', 'Average Precision (AP)'])
# 如果是多分类任务,需要分别计算每个类别的指标
unique_classes = np.unique(Ytest)
for cls in unique_classes:
# 二分类转换,将当前类别视为正类,其他类别视为负类
binary_Ytest = (Ytest == cls).astype(int)
binary_yhat = (yhat == cls).astype(int)
# 计算准确率
accuracy = accuracy_score(binary_Ytest, binary_yhat)
accuracy_list.append(accuracy)
# 计算精确率
precision = precision_score(binary_Ytest, binary_yhat)
precision_list.append(precision)
# 计算召回率
recall = recall_score(binary_Ytest, binary_yhat)
recall_list.append(recall)
# 计算 F1 值
f1 = f1_score(binary_Ytest, binary_yhat)
f1_list.append(f1)
# 计算平均精确率 (AP)
ap = average_precision_score(binary_Ytest, binary_yhat)
average_precision_list.append(ap)
# 计算混淆矩阵
conf_matrix = confusion_matrix(binary_Ytest, binary_yhat)
confusion_matrices.append(conf_matrix)
table.add_row([cls, f'{accuracy * 100:.2f}%', f'{precision * 100:.2f}%', f'{recall * 100:.2f}%', f'{f1 * 100:.2f}%', f'{ap * 100:.2f}%'])
# 计算总体指标
overall_accuracy = accuracy_score(Ytest, yhat)
overall_precision = precision_score(Ytest, yhat, average='weighted')
overall_recall = recall_score(Ytest, yhat, average='weighted')
overall_f1 = f1_score(Ytest, yhat, average='weighted')
overall_ap = np.mean(average_precision_list) # 总体平均精确率
table.add_row(['Overall', f'{overall_accuracy * 100:.2f}%', f'{overall_precision * 100:.2f}%', f'{overall_recall * 100:.2f}%', f'{overall_f1 * 100:.2f}%', f'{overall_ap * 100:.2f}%'])
return accuracy_list, precision_list, recall_list, f1_list, average_precision_list, confusion_matrices, table
# 调用评估函数
accuracy_list, precision_list, recall_list, f1_list, average_precision_list, confusion_matrices, table = evaluate_classification(Ytest, yhat)
# 显示预测指标数值
print(table)
# 绘制混淆矩阵(以第一个类别为例,你可以循环绘制所有类别的)
for i, cls in enumerate(np.unique(Ytest)):
cm = confusion_matrices[i]
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False,
xticklabels=['Negative', 'Positive'], yticklabels=['Negative', 'Positive'])
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title(f'Confusion Matrix for Class {cls}')
plt.show()
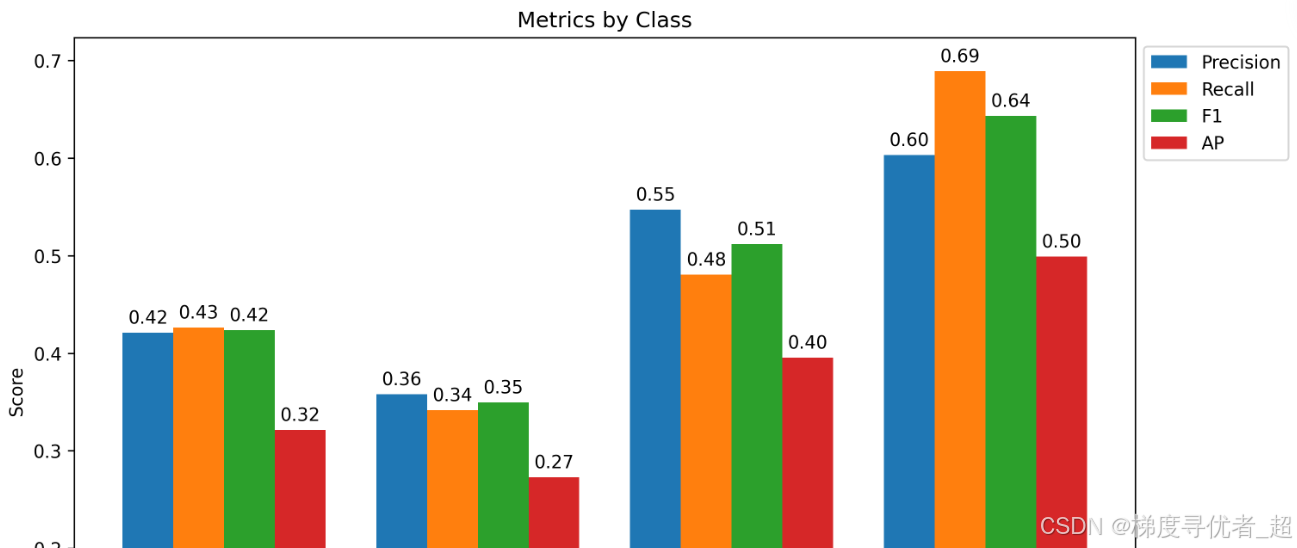
# 绘制各类别精确率、召回率和 F1 值柱状图
unique_classes = np.unique(Ytest)
x = np.arange(len(unique_classes))
width = 0.2
multiplier = 0
fig, ax = plt.subplots(layout='constrained', figsize=(10, 6))
for attribute, measurement in [('Precision', precision_list), ('Recall', recall_list), ('F1', f1_list), ('AP', average_precision_list)]:
offset = width * multiplier
rects = ax.bar(x + offset, measurement, width, label=attribute)
ax.bar_label(rects, fmt='%.2f', padding=3)
multiplier += 1
ax.set_ylabel('Score')
ax.set_title('Metrics by Class')
ax.set_xticks(x + width * 1.5, unique_classes)
ax.legend(loc='upper left', bbox_to_anchor=(1, 1))
plt.show()
# 绘制每个类别的 PR 曲线
Ytest_bin = label_binarize(Ytest, classes=np.unique(Ytest)) # 将标签二值化
Ypred_prob = model.predict_proba(vp_test) # 获取每个类别的预测概率
plt.figure(figsize=(10, 8))
colors = ['blue', 'green', 'red', 'purple'] # 颜色列表,根据类别数量调整
for i, color in zip(range(len(unique_classes)), colors):
precision, recall, _ = precision_recall_curve(Ytest_bin[:, i], Ypred_prob[:, i])
ap = average_precision_list[i]
plt.plot(recall, precision, color=color, lw=2,
label=f'Class {unique_classes[i]} (AP = {ap:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve by Class')
plt.legend(loc='lower left')
plt.show()
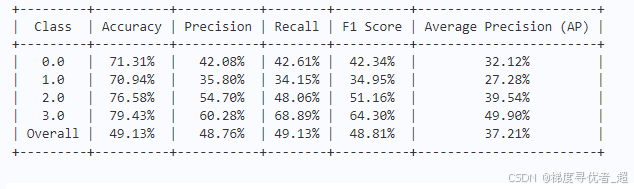
本文运行结果展示:
部分截图不完整哦。但是代码完整可运行。
至此模型训练完成。
如果你都看到这里了,恭喜你我把整理好的文档上传到百度飞桨平台啦,可以直接访问:
机器学习大结局:https://aistudio.baidu.com/projectdetail/8820075?sUid=10593945&shared=1&ts=1740548895244,我发现了一篇高质量的实训项目,使用免费算力即可一键运行,还能额外获取8小时免费GPU运行时长,快来Fork一下体验吧。当然还有老办法蓝奏云网盘免费分享包含项目jupyter格式文件和数据:https://wwyf.lanzoul.com/ia2hD2owbj1a。当然也将资源上传到CSDN了,欢迎下载讨论和咨询,地址是:https://download.csdn.net/download/weixin_60217199/90432547。
总结
至此,从2025年1月21日开始更新的机器学习基础栏目正式画上句号。回顾这段旅程,我们从最基础的内容一路走到完整的流程实现,涵盖了基础分类、原理解读,还附上了代码实现。我已经竭尽全力在撰写这些内容啦!看到不少人开启了收费模式,我虽然不反对赚钱,但对那些收费却没什么干货的栏目还是有点小意见的。所以,我的栏目永远不会开启收费模块,毕竟知识应该是自由的嘛!不过,如果你觉得这些内容对你帮助很大,欢迎在力所能及的范围内打赏一下,就当请我喝杯咖啡啦!感谢你一路陪伴,从机器学习的基础知识看到现在。下一期我们将进入深度学习的奇妙世界,不见不散哦!记得关注、点赞、收藏三连击,咱们下期再见!