目录
1 背景
在各类学科竞赛中,常常要求参赛者提交
Excel
或
/
和
PDF
格式的竞赛作品。本赛题以某届数据分析竞赛作品的评阅为背景,要求参赛者根据给定的评分准则和标准答案,使用 Python
编程
完成竞赛作品的自动评判。
2 目标
1.
使用
Python
解压压缩文件,从中读取指定的文件。
2.
使用
Python
解析
PDF
文件,获取其中的图片信息。
3.
使用
Python
解析
Excel
和
PDF
文件,对数据进行处理与统计,根据评分准则对每份作品打分,并输出报表。
3 任务
根据提供的评分标准及要求,对每份作品进行自动评分,
并撰写报告,在报告中详细描述各项任务的处理思路、过程及必要的结果。
同时,将
Python
源代码保存为 py
文件,文件名为任务编号,例如“
task1_1.py
”“
task1_2.py
”“
task2_1.py
” 等
3.1 任务 1 基本处理
压缩文件“
DataA.rar
”中包括所有待评分的作品,每份作品是以作品号为文件名、包含若干结果文件的压缩文件,文件格式可能是 rar
、
zip
或
7z
。
任务 1.1 将压缩文件“ DataA.rar ”中的所有作品解压到当前文件夹的同名子文件夹(即以每份作品的作品号为子文件夹名)中。任务 1.2 在当前文件夹中新建“ summary ”子文件夹,在每份作品文件夹中新建“image ”子文件夹。任务 1.3 判断每份作品中是否包含文件“ task2_1.xlsx ”“ task2_2.xlsx ” “task2_3.pdf”及“ task3.xlsx”,每包含一个文件得 2 分,满分 8 分。任务 1.4 对每份作品提取文件“ task2_3.pdf ”中的图片,保存在“ image ”文件夹的“ XXXX_n.png ”文件中,其中“ XXXX ”为作品号、 n 为图片在文件 “task2_3.pdf ”中的图片序号。提取所有作品中的图片信息,按照表 1 的格式保 存在文件夹“summary ”的“ result1_4.xlsx ”文件中。将含有作品号 A118~A120 的结果截屏放在报告中。

3.2 任务 2 数据分析
任务 3.2.1 通用名称评分
以“
criteria2_1.xlsx
”为标准,根据正式登记证号对每份作品中的“
task2_1.xlsx
”
进行匹配,按以下规则统计错误数:
(1)
对匹配的记录,判断“产品通用名称”是否一致,如不一致,错误数
s
加 1。
(2)
对“
criteria2_1.xlsx
”中的每条记录,查找“
task2_1.xlsx
”,如没有匹配
的记录,错误数
s
加
1
。
(3)
对“
task2_1.xlsx
”中的每条记录,查找“
criteria2_1.xlsx
”,如没有匹配的记录,错误数 s
加
1
。
对错误数
s
:
s = 0
得
15
分,
1 ≤ s ≤ 10
得
10
分,
11 ≤ s ≤ 20
得
5
分,s ≥ 21 得
0
分。
任务 3.2.2 分组标签评分
以“
criteria2_2.xlsx
”为标准,根据正式登记证号对每份作品中的“
task2_2.xlsx
” 进行匹配,按以下规则统计错误数:
(1)
对匹配的记录,判断“分组标签”中的数值和顺序是否一致,如不一致, 错误数 s
加
1
。
(2)
对“
criteria2_2.xlsx
”中的每条记录,查找“
task2_2.xlsx
”,如没有匹配的记录,错误数 s
加
1
。
(3)
对“
task2_2.xlsx
”中的每条记录,查找“
criteria2_2.xlsx
”,如没有匹配的记录,错误数 s
加
1
。
对错误数
s
:
s ≤ 5
得
15
分,
6 ≤ s ≤ 15
得
10
分,
16 ≤ s ≤ 30
得
5
分,s ≥ 31 得
0
分。
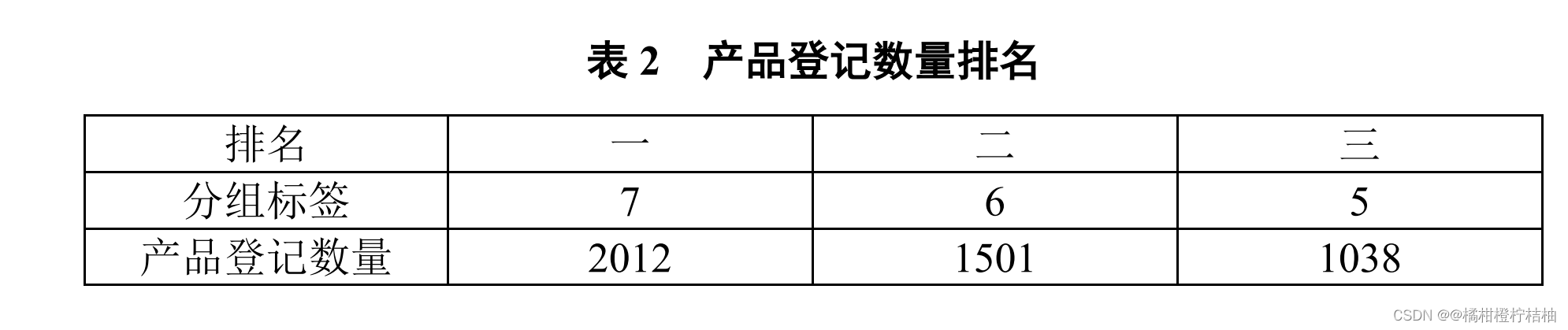
任务 3.2.3
读取每份作品“
task2_3.pdf
”中产品登记数量及排名的表格,针对每个排名判断“分组标签”和“产品登记数量”的数值与表 2
中的标准答案是否 一致,每个匹配的数值得 2
分,满分
12
分。
3.3 任务 3 相似矩阵评分
以“
criteria3.xlsx
”为标准,对每份作品“
task3.xlsx
”中的相似矩阵(以下简 称相似矩阵)按以下规则进行评分。
任务 3.3.1
判断相似矩阵的维数与“
criteria3.xlsx
”中的是否一致,如一致得5 分,否则得
0
分。
任务 3.3.2
公司
ID
匹配
对相似矩阵进行匹配,按以下规则统计错误数:
(1)
对“
criteria3.xlsx
”中的每个公司
ID
,查找“
task3.xlsx
”,如没有匹配的公司 ID
,错误数
s
加
1
。
(2)
对“
task3.xlsx
”中的每个公司
ID
,查找“
criteria3.xlsx
”,如没有匹配的公司 ID
,错误数
s
加
1
。
对错误数
s
:
s = 0
得
15
分,
1 ≤ s ≤ 2
得
10
分,
3 ≤ s ≤ 5
得
5
分,
s ≥ 6 得 0
分。
任务 3.3.3
判断相似矩阵的对角线元素是否均为
1
(允许误差
10
−6
),如均为 1
得
5
分,否则得
0
分。
任务 3.3.4
判断相似矩阵的元素是否关于主对角线对称(允许误差 10 −6),每出现一组不对称的元素,错误数 s 加 1。对错误数 s:s = 0 得 10 分,1 ≤ s ≤ 5得 7 分,6 ≤ s ≤ 10 得 4 分,s ≥ 11 得 0 分。
任务 3.3.5
以“criteria3.xlsx”为标准,统计相似矩阵上三角元素的错误数 s。对每个匹配的元素计算绝对误差 e,0.005 ≤ e < 0.01,错误数 s 加 0.5;e ≥ 0.01, 错误数 s 加 1。对每个匹配不上的元素,错误数 s 加 1。对错误数 s:s = 0 得 15 分,1 ≤ s ≤ 5 得 10 分,6 ≤ s ≤ 10 得 5 分,s ≥ 11 得 0 分。
3.4 任务 4 评分结果汇总
对每份作品,完成任务
1~3
,对得分进行统计,按表
3~5
的格式生成 “score.xlsx”,保存在文件夹“
summary
”中。
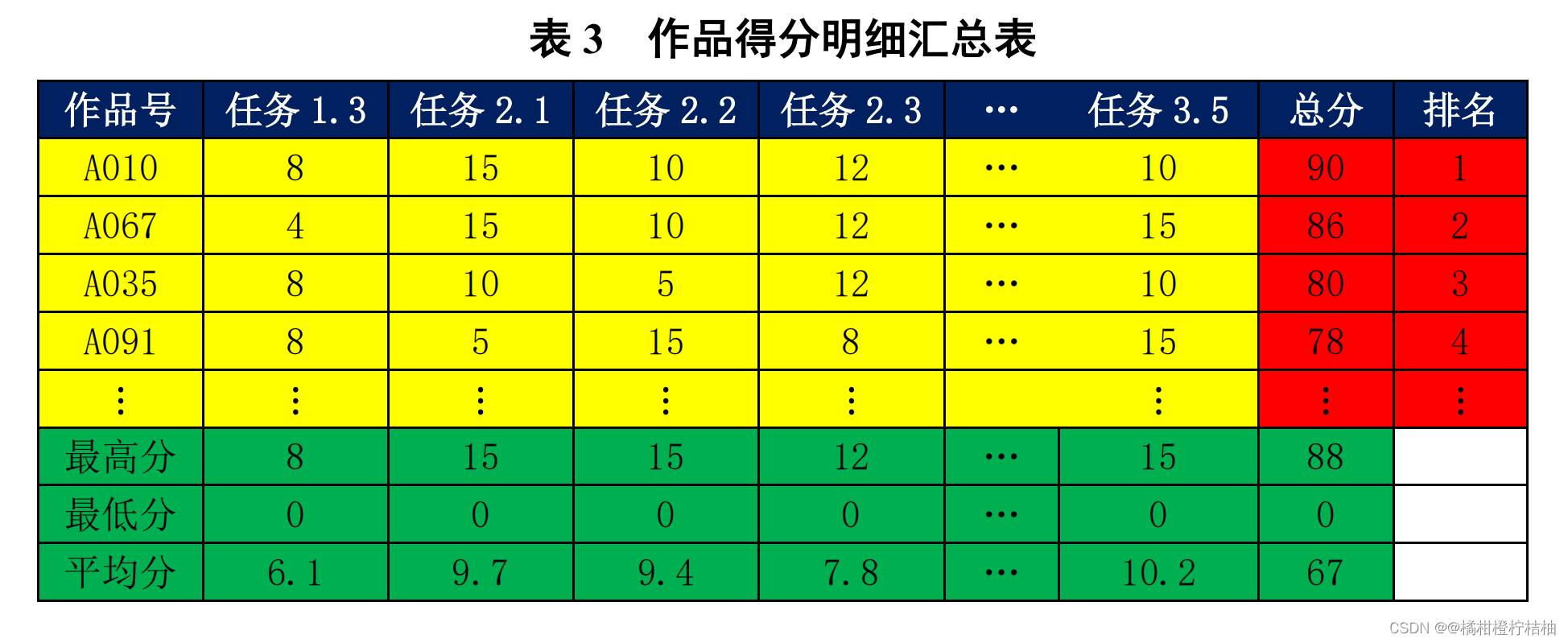
任务 3.4.1
按表
3
的格式,在工作表“
report4_1
”中保存所有作品的得分明 细,计算各作品的总分,并进行排名。按总分降序排列。作品号放在第 1
列,字 段名放在第 1
行,从第
2
行第
2
列开始列出明细数据。字段名单元格底色设置为 蓝色,总分与排名单元格底色设置为红色,其他单元格底色设置为黄色。
任务 3.4.2
在明细数据之后列出每项评分的汇总数据:最高分、最低分和平均分。汇总数据单元格底色设置为绿色。将含有作品号 A417~A419
及统计结果的截屏放在报告中。
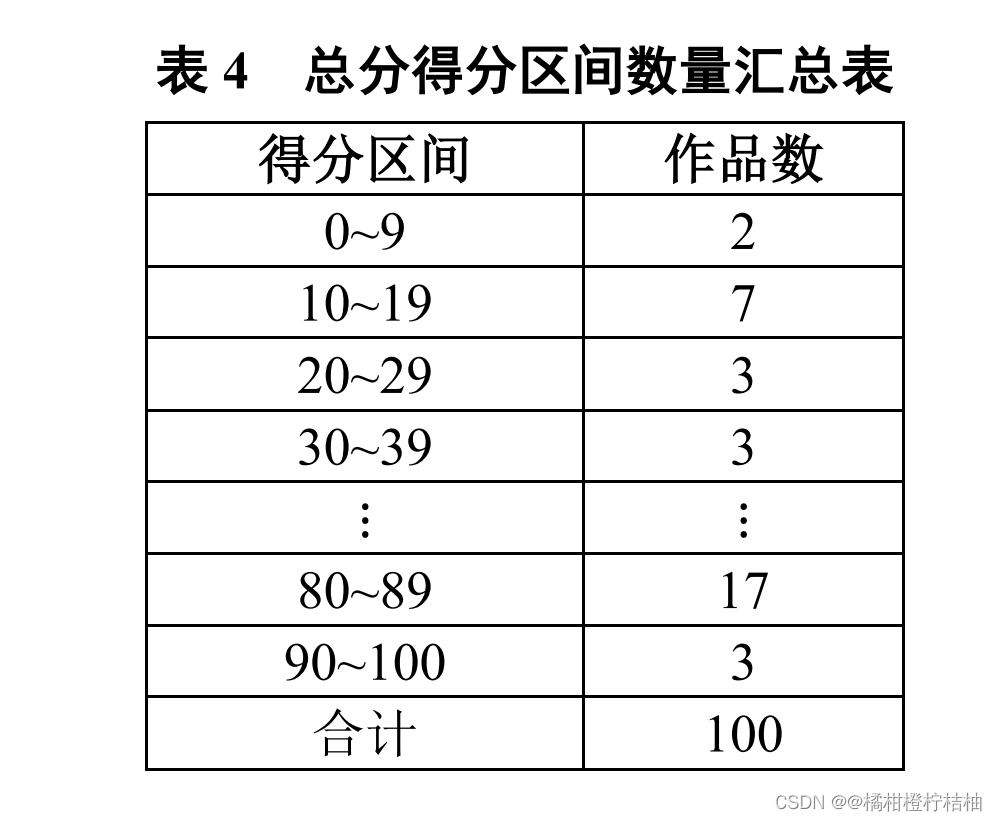
任务 3.4.3
在工作表“
report4_3
”中,以
10
分为一段(参见表
4
)分段汇总 各段的作品数。得分区间在第 1
列,作品数在第
2
列,字段名在第
1
行。同时,将结果放在报告中。
任务 3.4.4
基于任务
4.3
的结果,在工作表“
report4_4
”中绘制各得分段作品数的柱形图。同时,将柱形图放在报告中。
3.5 任务 5 嵌套压缩文件处理
任务 3.5.1
将压缩文件“
DataB.rar
”中的所有作品解压到当前文件夹的同名子文件夹中。
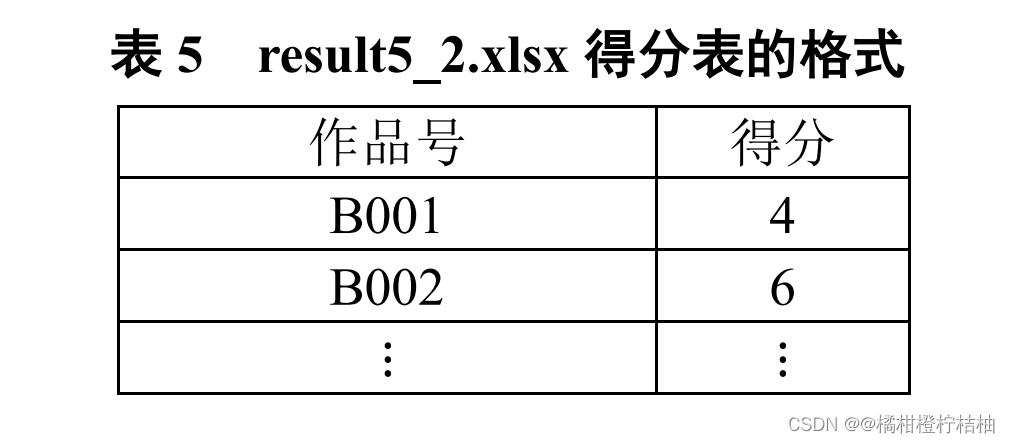
任务 3.5.2
判断每份作品中是否包含文件“
task2_1.xlsx
”“
task2_2.xlsx
” “task2_3.pdf
”及“task3.xlsx”,每包含一个文件得
2
分,满分
8
分。按照表
5
错误
!
未找到引用源。
的格式,将所有作品的得分保存在文件夹“
summary
”的 “result5_2.xlsx
”文件中。
任务 3.5.3
基于任务
5.2
的结果,对每份作品提取到的文件,按照表
6
的格式列出各文件的路径,保存在文件夹“summary
”的“
result5_3.xlsx
”文件中。
