一、什么是数据预处理
数据预处理是指在机器学习、数据分析和数据挖掘等领域中,对原始数据进行一系列的处理和转换,以便为后续的分析和建模做好准备。数据预处理是数据科学项目中的重要步骤,因为原始数据往往存在各种质量问题,如缺失值、异常值、重复数据、不一致的格式等,这些问题会直接影响模型的性能和最终结果的准确性。因此在数据分析中,对数据做数据预处理是必不可少的一个环节。
二、数据预处理的步骤
1、数据清洗:
-
处理缺失值:通过删除、填充或插值等方法处理数据中的缺失值。
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'C': [1, 2, 3, None]
})
df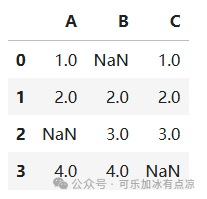
-
删除含有缺失值的行
# 删除含有缺失值的行
no_null_data = df.dropna()
no_null_data
-
填充缺失值
# 填充缺失值
fillna_data_mean=df.fillna(value=df.mean()) # 使用每一列的平均值填充
fillna_data_mean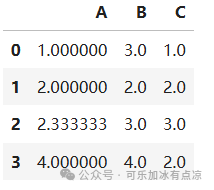
filled_data_before=df.fillna(method='ffill') # 使用前一个值填充
filled_data_before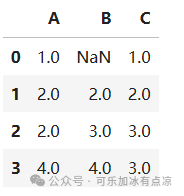
filled_data_last=df.fillna(method='bfill') # 使用后一个值填充
filled_data_last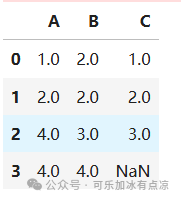
# 用指定的值填充所有缺失值
filled_df = df.fillna(15)
filled_df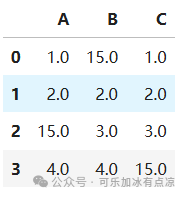
- 处理异常值:识别并处理数据中的异常值,使用统计方法(如Z-Score)。
from scipy import stats
data = filled_df #使用刚才用指定值填充的数据
z_scores = stats.zscore(data['A']) #获取A这一列的z分数
abs_z_scores = abs(z_scores) # 获取A这一列z分数的绝对值
filtered_entries = (abs_z_scores < 3) #统计学上认为Z分数的绝对值大于3的数据点为异常值
normal_data = data[filtered_entries] # 保留那些在‘A’列中没有被认为是异常值的行
normal_data- 处理重复数据:删除数据集中的重复记录。
# 删除所有列上的重复行
df = pd.DataFrame({
'A': [1, 2, 2, 3],
'B': [1, 1, 1, 2]
})
df
# 删除所有列上的重复行
df.drop_duplicates(inplace=True)
df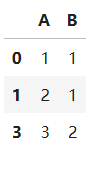
2、数据集成:
- 将来自不同来源的数据合并在一起,形成一个一致的数据集。
df1 = pd.DataFrame({
'EmpID':[1,2,3],
'Name':['John','Anna','Peter'],
'Department':['HR','Finance','IT']
})
df1
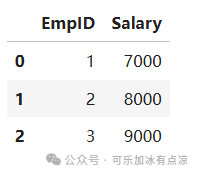
df2 = pd.DataFrame({
'EmpID':[1,2,3],
'Salary':[7000,8000,9000]
})
df2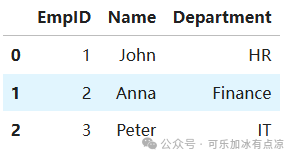
-
使用merge函数进行数据合并
# 合并数据集
# 这里使用内连接(inner join),这意味着只有当EmpID在两个数据集中都存在时,才会包含在合并后的数据集中
merged_df = pd.merge(df1, df2, on='EmpID')
merged_df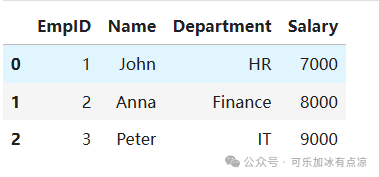
在这个例子中,我们使用了内连接来合并数据集。pandas还支持其他类型的连接,如左连接(left join)、右连接(right join)和全外连接(full outer join),读者可以根据需要选择合适的连接方式。
- 使用concat函数合并数据
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})

# 沿轴0堆叠数据框
result = pd.concat([df1, df2])
result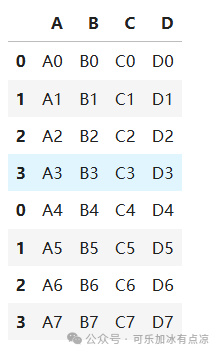
# 沿轴1堆叠数据框
result = pd.concat([df1, df2], axis=1)
result
3、数据类型转换
-
将浮点型数据转换为整数型
import numpy as np
arr=np.arange(1,5,0.5)
arr1=arr.astype(np.int) #将浮点型转换为整数型-
数据规范化:将数据转换成适合分析的格式,如归一化、标准化等
from sklearn.preprocessing import MinMaxScaler
# 假设df是一个包含数值数据的DataFrame
scaler = MinMaxScaler()# 数据归一化
scaled_data = scaler.fit_transform(df)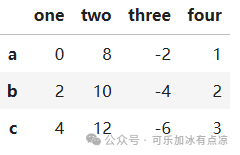
-
4、数据删除
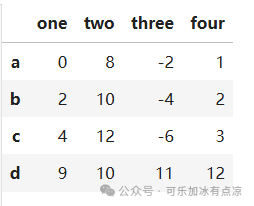
data=[[0,8,-2,1],[2,10,-4,2],[4,12,-6,3],[9,10,11,12]] index=['a','b','c','d'] columns=['one','two','three','four'] dff=pd.DataFrame(data=data,index=index,columns=columns) dff按列删除数据
#删除第四列数据,按列删除,将drop方法的axis参数设置为1 #方法一 df4=dff.drop(labels='four',axis=1) df4 #删除列,也可以直接设置drop方法中的columns参数 # 方法二 df5=dff.drop(columns='four') df5 -
按行删除数据
-
#按行删除 #方法一:设置index参数 df6=dff.drop(index='d') df6 #方法2:设置labels参数 df4=df.drop(labels='d',axis=0)数据预处理是一个深奥且广泛的领域,涵盖了从数据清洗到特征工程等多个方面。今天我们讨论了一些基本的方法和技巧,但这些只是冰山一角。在实际的数据分析、机器学习项目中,每个步骤都可能涉及到更复杂的决策和技术。
学习永无止境,希望今天的分享能够为您在数据预处理的旅程中提供一些帮助和启发。
-
更多精彩内容,请关注“可乐加冰有点凉”公众号