由于网页动态加载,无法直接在静态页面爬取相关数据
以这个天气网站为例
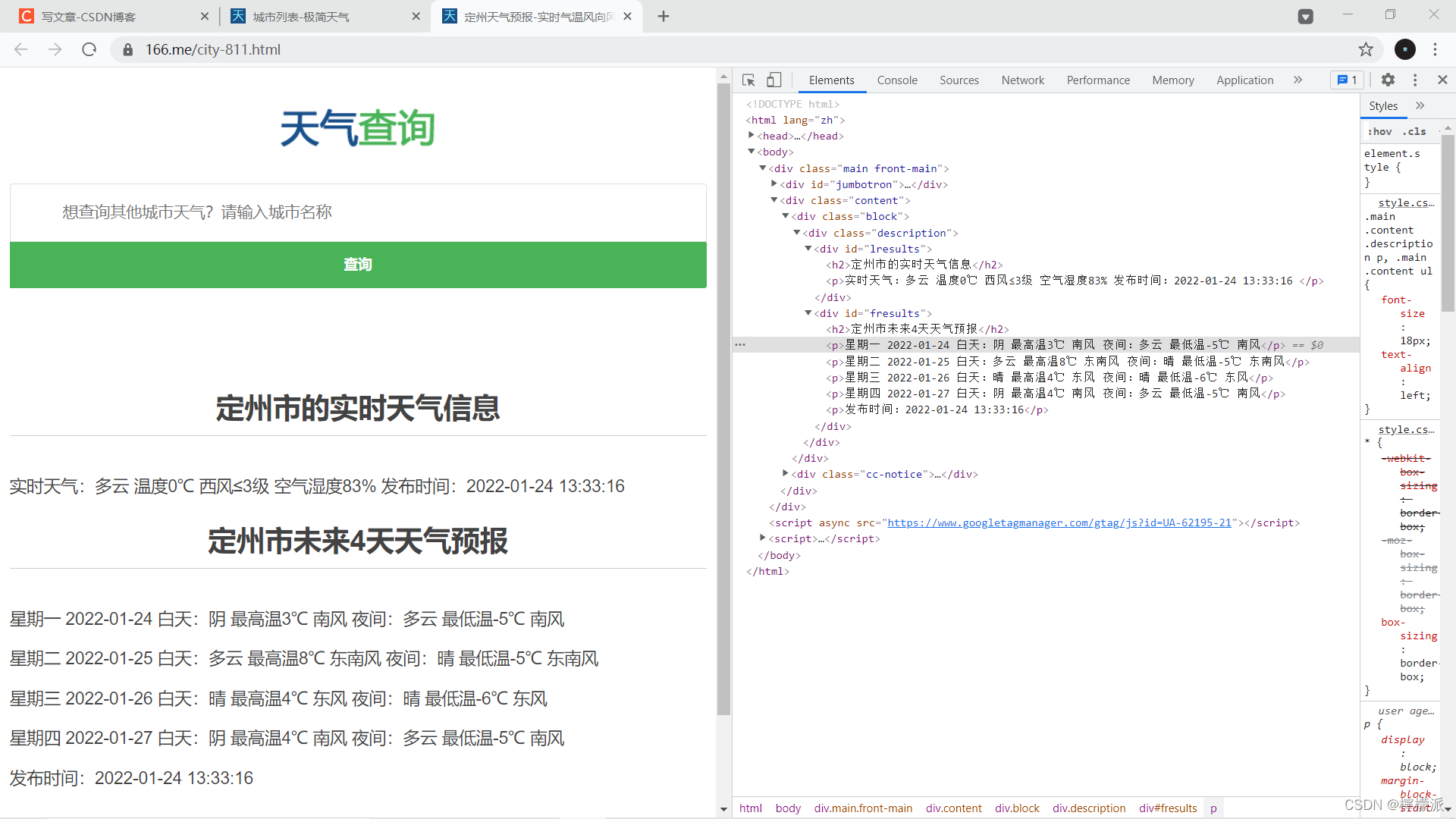
可以看到数据,但html静态文件无天气数据
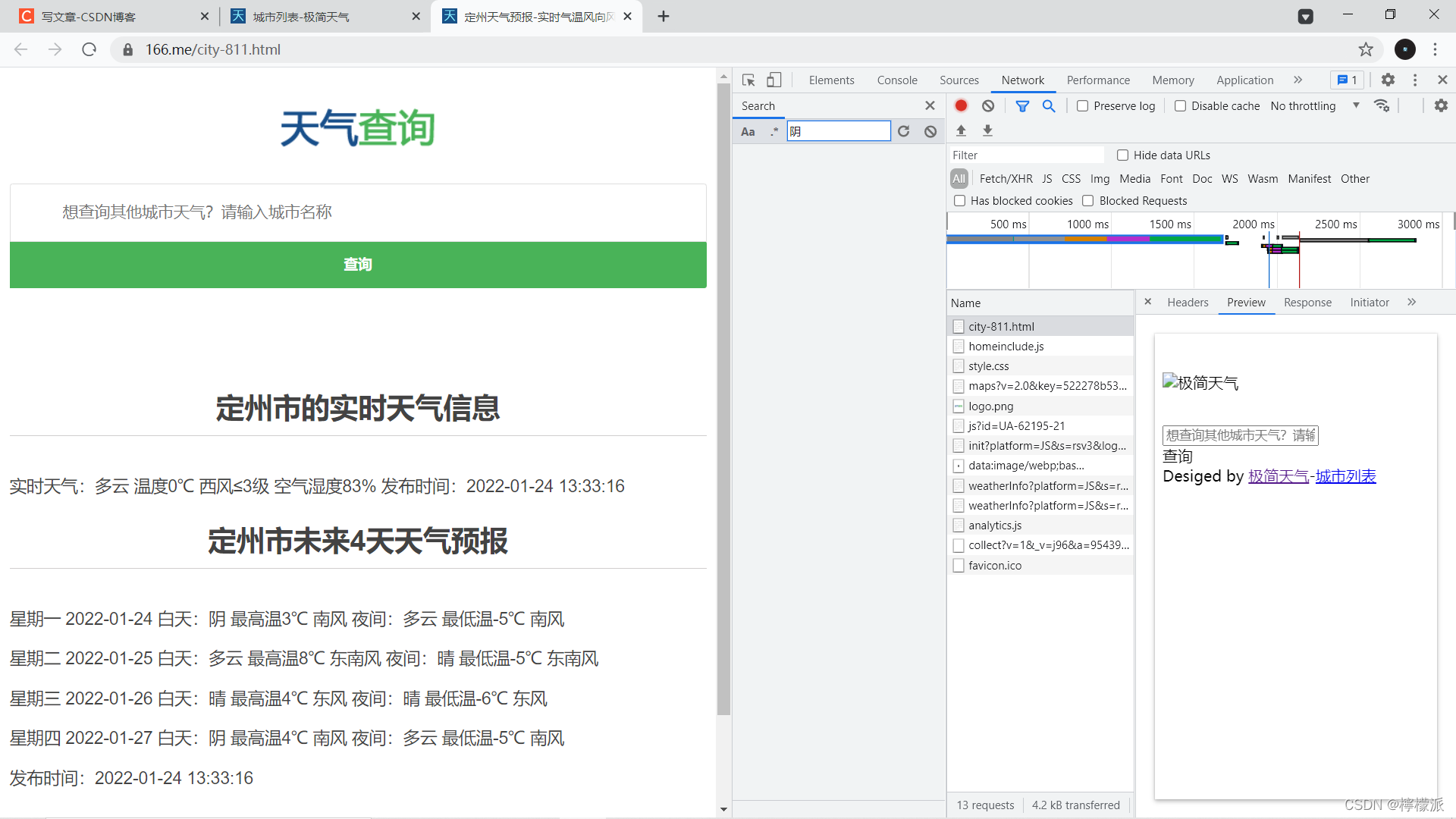
此处数据是由js加载出来的
可以直接使用selenium暴力爬取
代码如下
# 导入webdriver
from selenium import webdriver
# 导入time模块
import time
# 导入bs
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
# 向指定url发起请求
driver.get('https://www.166.me/city-109.html')
# 刷新页面,防止页面未渲染
driver.refresh()
# 等待页面渲染
time.sleep(2)
# 获取网页源代码
html = driver.page_source
# 退出模拟浏览器,防止进程残留
driver.quit()
# 获取完页面源代码之后就是一般的页面解析
bs = BeautifulSoup(html, 'html.parser')