我有众多的搭配方案在我的GitHub里
https://github.com/ssrzero123/STF-YOLO
如果对大家有用的话希望得到一个星星star收藏(拜托啦)
2024.4.28
兄弟们注意一下:因为ultralytics使用的一键安装模式,本地再下载,会和环境里的包冲突。
我的方法是将ultralytics替换环境里的ultralytics包,然后更改ultralytics包里的文件、代码
做法:
比如我使用的Ubuntu,于是只要将我新上传的ultralytics文件夹替换掉\wsl.localhost\Ubuntu-20.04\home\ling\miniconda3\envs\torch\lib\python3.8\site-packages目录下的ultralytics即可
一、改进的操作方法
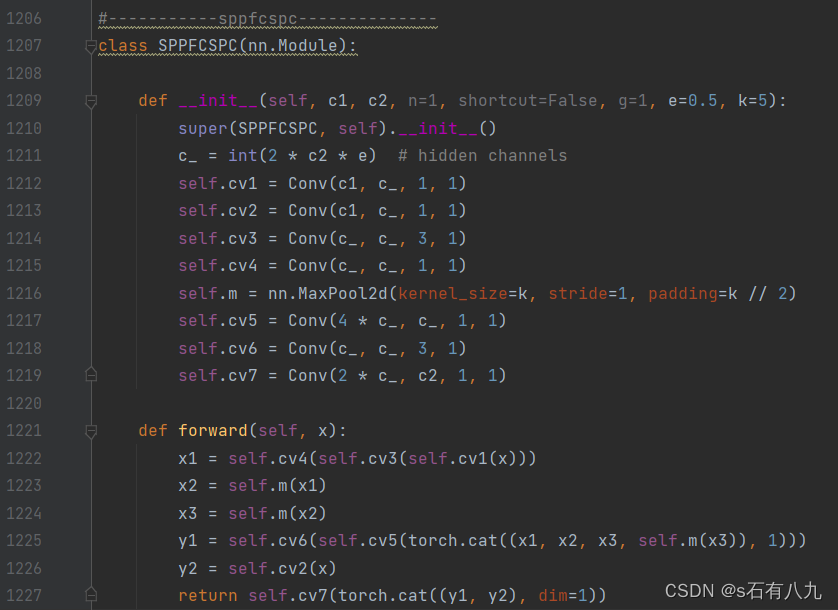
1.注册模块(以SPPFCSPC为例)
在nn/modules/block.py里注册要使用的新模块
有的在block里,有的在conv里,比如深度卷积等等需要在conv里
插入下面的代码:
2.各种引用都加上该模块
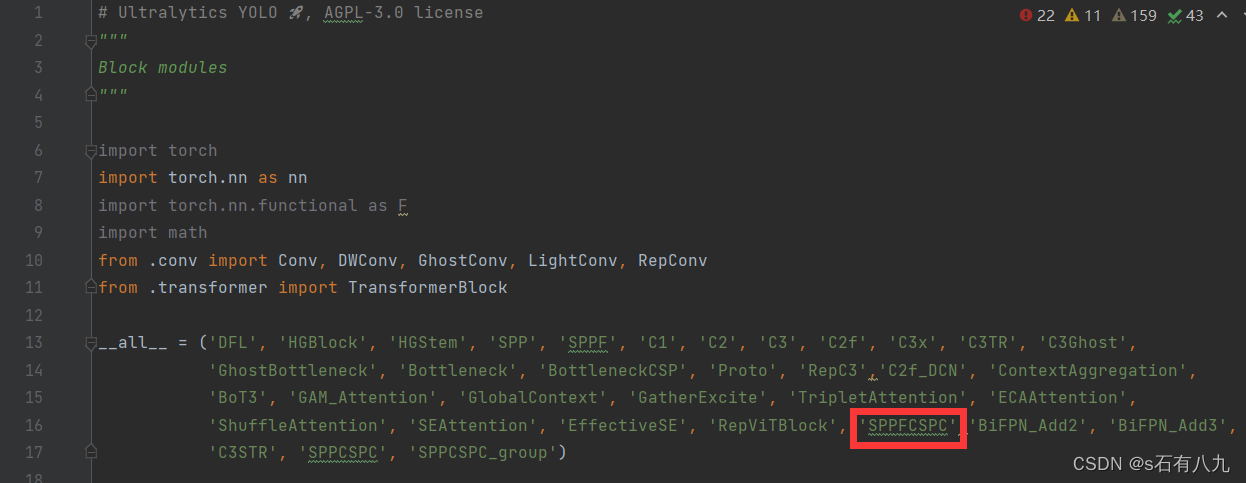
- 翻到block.py最上面,加上模块名
- 打开nn/modules/init.py
需要注意的是,加入两个地方:
①之前模块注册在哪个py文件,就加入到哪里
②__all__的地方添加
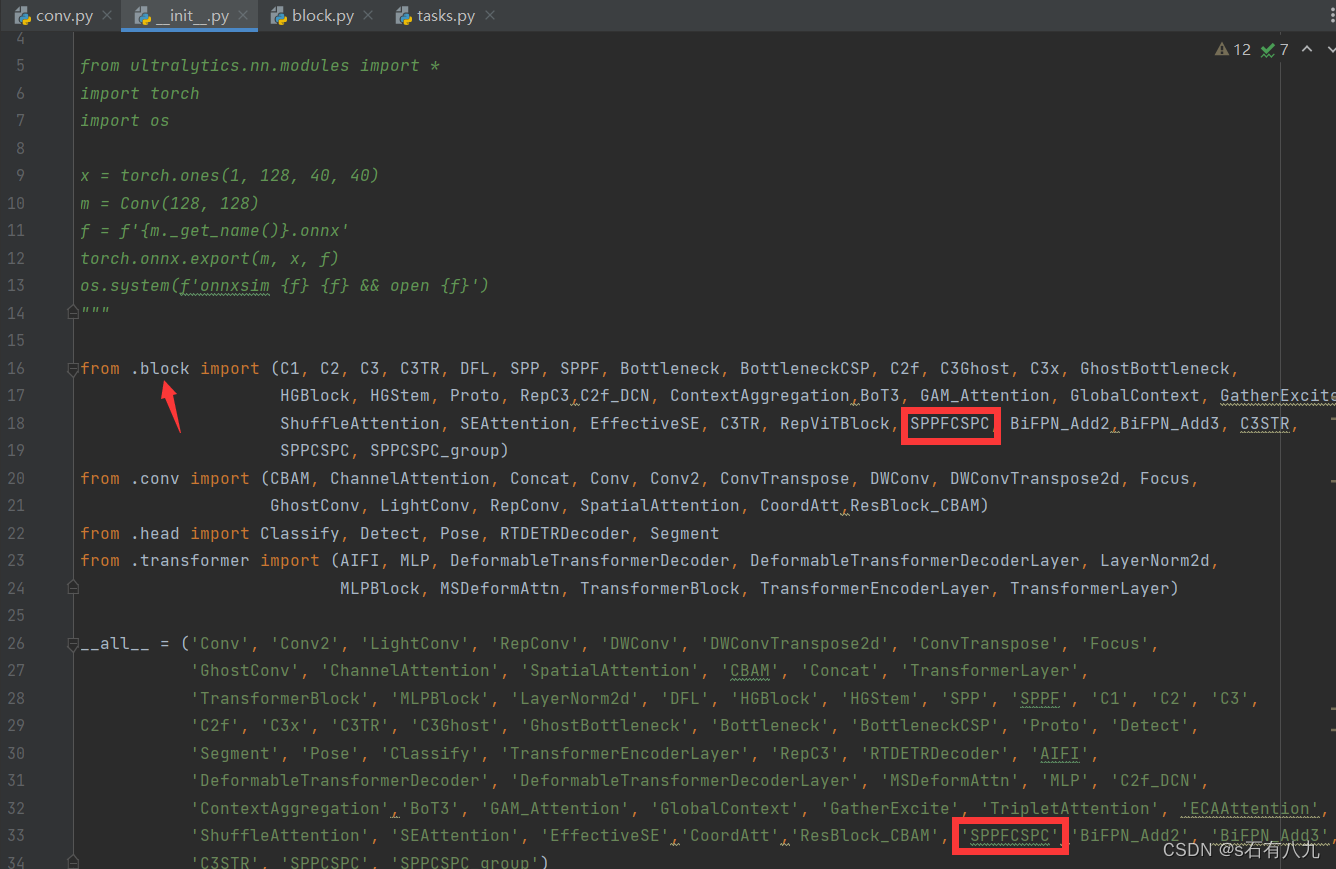
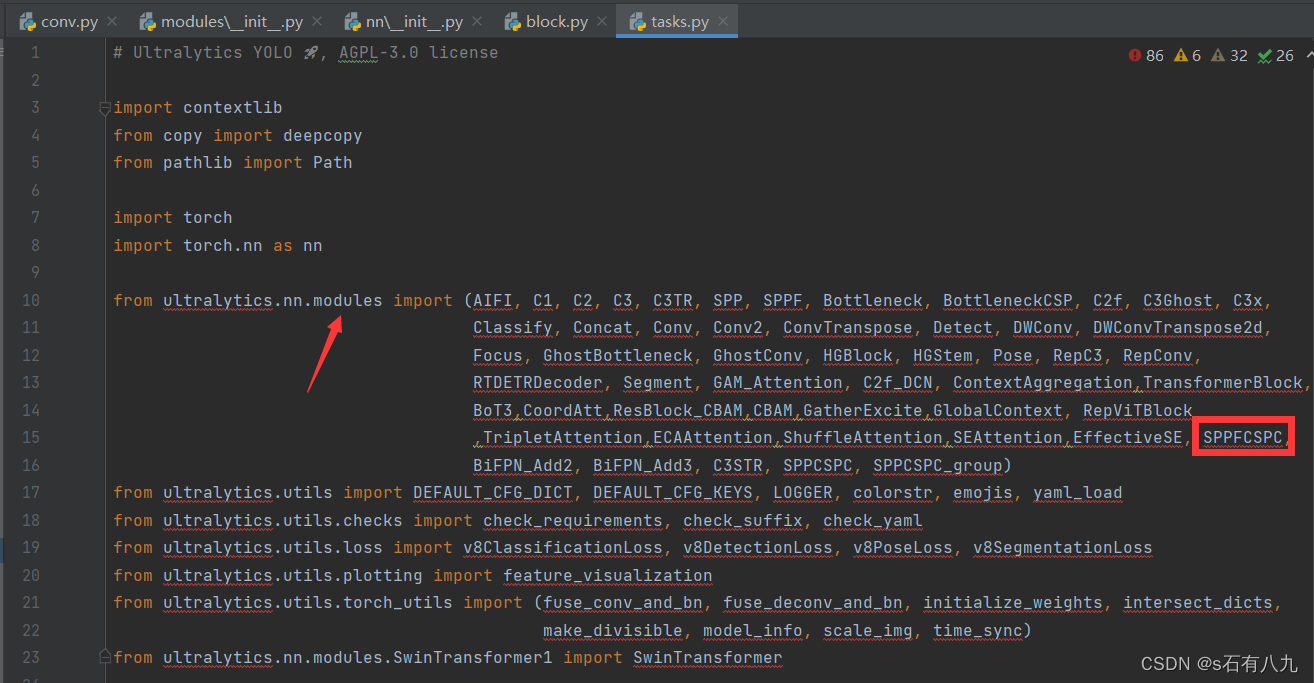
- 打开nn/tasks.py
在ultralytics.nn.modules里import新添加的模块
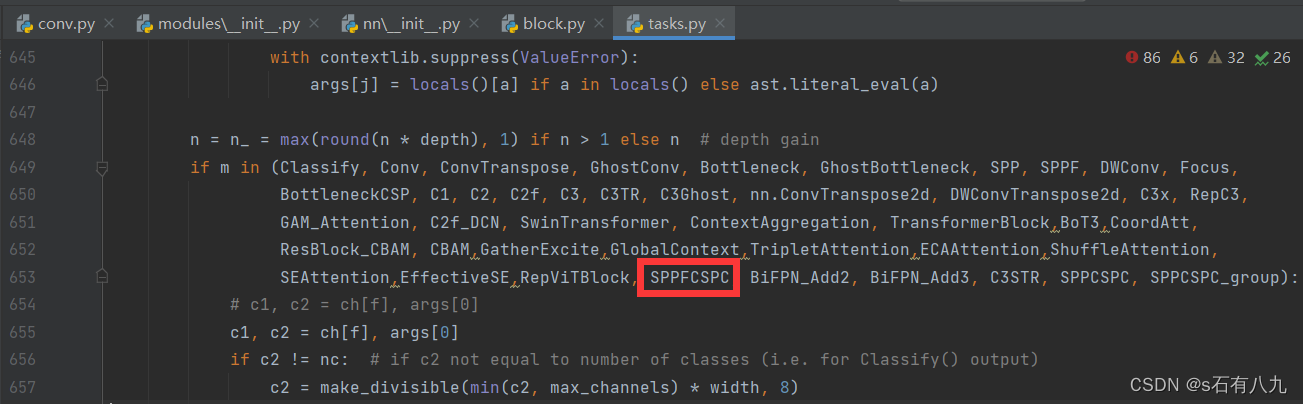
之后翻到下面649行左右,像图中这样添加
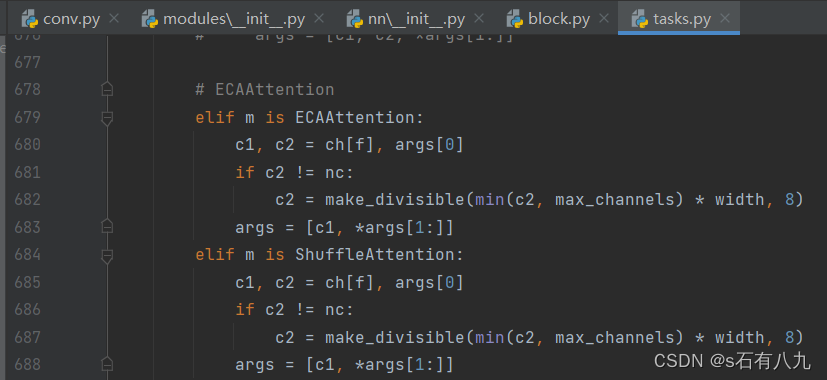
注意: 简单的模块这样添加就注册完成了,但是如果是注意力机制,有的需要在nn/tasks.py再添加一些东西,比如下面这两个注意力机制ECAAttention 和 ShuffleAttention
3.在yaml文件里使用
打开cfg/models/v8,创建一个新的yaml
在你选择好的s、m或x的基础上进行修改,如下:
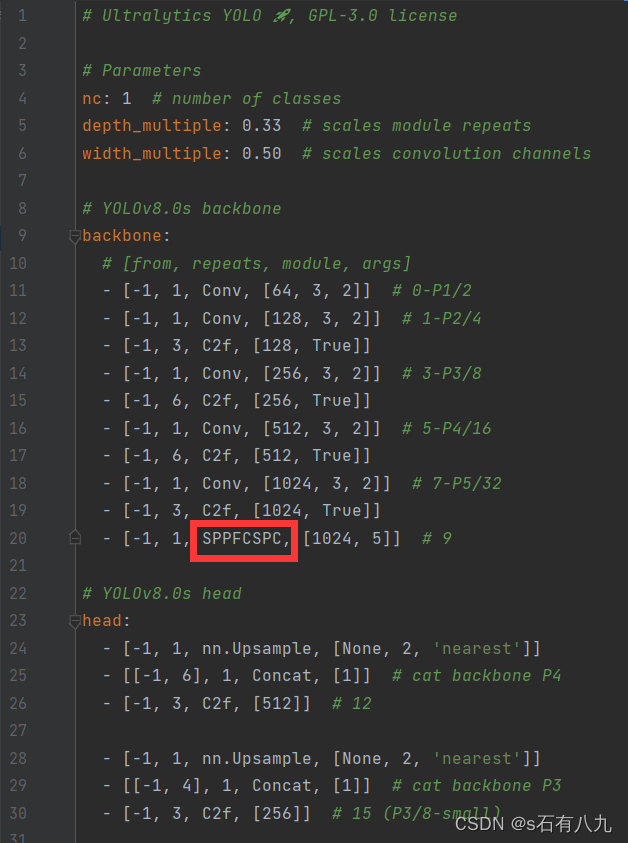
二、注意事项
- 固定的模块只能由某些模块替换,不能随意替换
如:SPPF应替换为SPPCSPC、SPPCSPC_group、SPP等
格式如下:
- [-1, 1, SPPCSPC_group, [1024]] # 11
- [-1, 1, SPPCSPC, [1024]] # 11
如:Conv由DWConv、GhostConv等conv替换,conv.py里有很多模块
因为有些模块有特定的格式,随意替换,不改其他,容易报错,最好还是看我的yaml文件里是如何改的
- DWConv、GhostConv可以减小模型复杂度,提高速度,精度可能会下降
- 模块可以自由替换几个,可以替换所有可以替换的,也可以只替换某几个
比如下面这样
## Ultralytics YOLO 🚀, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 1.00 # scales module repeats
width_multiple: 1.25 # scales convolution channels
# YOLOv8.0x6 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Focus, [64, 3]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [768, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 9-P6/64
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPCSPC, [1024]] # 11
# YOLOv8.0x6 head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 8], 1, Concat, [1]] # cat backbone P5
- [-1, 3, C2, [768, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2, [512, False]] # 17
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2, [256, False]] # 20 (P3/8-small)
- [-1, 1, GhostConv, [256, 3, 2]]
- [[-1, 17], 1, Concat, [1]] # cat head P4
- [-1, 3, C2, [512, False]] # 23 (P4/16-medium)
- [-1, 1, GhostConv, [512, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P5
- [-1, 3, C2, [768, False]] # 26 (P5/32-large)
- [-1, 1, GhostConv, [768, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P6
- [-1, 3, C2, [1024, False]] # 29 (P6/64-xlarge)
- [[20, 23, 26, 29], 1, Detect, [nc]] # Detect(P3, P4, P5, P6)
或者这个,可以替换两个
可以替换三个
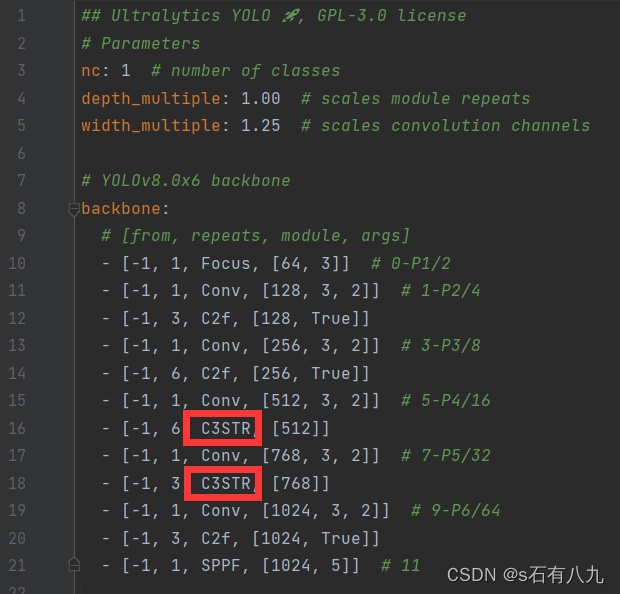
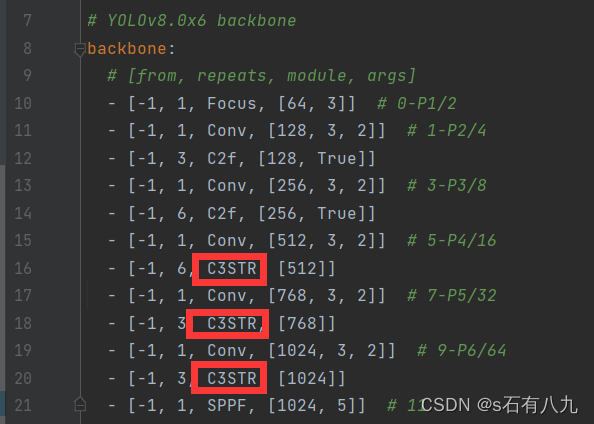
三、众多模块分享
swin transformer模块
#----------swintf-----------------------------------------
class SwinTransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=8):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i in
range(num_layers)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# print(attn.dtype, v.dtype)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
# print(attn.dtype, v.dtype)
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class SwinTransformerLayer(nn.Module):
def __init__(self, dim, num_heads, window_size=8, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# if min(self.input_resolution) <= self.window_size:
# # if window size is larger than input resolution, we don't partition windows
# self.shift_size = 0
# self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# reshape x[b c h w] to x[b l c]
_, _, H_, W_ = x.shape
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size != 0 or W_ % self.window_size != 0:
Padding = True
# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
# print('2', x.shape)
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c
# create mask from init to forward
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h w
if Padding:
x = x[:, :, :H_, :W_] # reverse padding
return x
class C3STR(C3):
# C3 module with SwinTransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
名称叫C3STR
下面为我使用的比较好的搭配:
## Ultralytics YOLO , GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 1.00 # scales module repeats
width_multiple: 1.25 # scales convolution channels
# YOLOv8.0x6 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Focus, [64, 3]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C3STR, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C3STR, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C3STR, [512]]
- [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
- [-1, 3, C3STR, [768]]
- [-1, 1, Conv, [1024, 3, 2]] # 9-P6/64
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPCSPC, [1024, 5]] # 11
# YOLOv8.0x6 head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 8], 1, Concat, [1]] # cat backbone P5
- [-1, 3, C2, [768, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2, [512, False]] # 17
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2, [256, False]] # 20 (P3/8-small)
- [-1, 1, DWConv, [256, 3, 2]]
- [[-1, 17], 1, Concat, [1]] # cat head P4
- [-1, 3, C2, [512, False]] # 23 (P4/16-medium)
- [-1, 1, DWConv, [512, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P5
- [-1, 3, C2, [768, False]] # 26 (P5/32-large)
- [-1, 1, DWConv, [768, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P6
- [-1, 3, C2, [1024, False]] # 29 (P6/64-xlarge)
- [[20, 23, 26, 29], 1, Detect, [nc]] # Detect(P3, P4, P5, P6)
注:swin transformer确实会提高一些精度,但模型复杂度会提高,并且需要耗费资源,最好3090之类的才能跑C3STR模块多的网络结构。
我有众多的搭配方案在我的GitHub里
https://github.com/ssrzero123/STF-YOLO
如果对大家有用的话希望得到一个星星star收藏(拜托啦)
如下是我训练的效果,绝对真实,诸位可以浅浅参考一下
(训练的策略好像大部分都是改成了wiou,不过影响不大)
| Model | Precision | Recall | mAP@ 0.5 | mAP@ 0.5:0.95 | F1 Score | GFLOPs /FPS |
|---|---|---|---|---|---|---|
| YOLOv8n+wiou | 0.791 | 0.713 | 0.809 | 0.55 | 0.75 | 434.78 |
| YOLOv8s | 0.895 | 0.758 | 0.871 | 0.667 | 0.82 | 28.4 |
| YOLOv8s+Wiou | 0.882 | 0.765 | 0.876 | 0.67 | 0.82 | 28.4/277.8 |
| Wiou+soft_nms | 0.857 | 0.771 | 0.845 | 0.705 | 0.81 | 28.4 |
| Wiou+soft_nms+tfbl | 0.843 | 0.759 | 0.834 | 0.676 | FPS | |
| Wiou+tfbl+focus+softn | 0.891 | 0.748 | 0.873 | 0.658 | 0.81 | 232.56 |
| Wiou+tfbl+focus | 0.875 | 0.763 | 0.873 | 0.648 | 153.85 | |
| Wiou+C3TR+focus | 0.89 | 0.753 | 0.873 | 0.649 | 0.82 | 156.25 |
| CA+BOT3 | 0.884 | 0.776 | 0.879 | 0.664 | 0.83 | 82.6 |
| DW+C3TR+focus | 0.897 | 0.741 | 0.868 | 0.64 | 0.81 | 156.25 |
| GatherExcite | 0.888 | 0.756 | 0.874 | 0.665 | 0.82 | 270.27 |
| SEAattention | 0.885 | 0.769 | 0.876 | 0.668 | 0.82 | 222.22 |
| CA+BOT3+SEA | 0.891 | 0.76 | 0.874 | 0.656 | 0.82 | 89.29 |
| DW+CA+BOT3 | 0.886 | 0.776 | 0.874 | 0.66 | 0.83 | 85.47 |
| DW+CA+BOT3+focus | 0.888 | 0.772 | 0.878 | 0.665 | 0.83 | 87.72 |
| DW+CA+BOT3+focus+sppfc | 0.888 | 0.763 | 0.875 | 0.655 | 0.82 | 81.97 |
| gost+CA+BOT3 | 0.886 | 0.774 | 0.877 | 0.662 | 0.83 | 80.0 |
| gost+CA+BOT3+focus | 0.888 | 0.769 | 0.873 | 0.651 | 0.82 | 88.5 |
| DW+CA+BOT3+focus+ESE | 0.885 | 0.768 | 0.873 | 0.659 | 0.82 | 86.21 |
| DW+CA+BOT3+focus+GE | 0.874 | 0.778 | 0.874 | 0.658 | 0.82 | 78.12 |
| Model | Precision | Recall | mAP@ 0.5 | mAP@ 0.5:0.95 | F1 Score | FPS |
|---|---|---|---|---|---|---|
| C2(head) | 0.895 | 0.765 | 0.877 | 0.67 | 0.83 | 256.41 |
| 下面的全加focus和wiou | ||||||
| C2head DWback | 0.879 | 0.769 | 0.88 | 0.667 | 0.82 | 303.03 |
| C2head DWhead | 0.926 | 0.767 | 0.888 | 0.737 | 0.84 | 42.74 |
| C2head DW(head+back) | 0.909 | 0.777 | 0.89 | 0.732 | 0.84 | 46.08 |
| C2head Dwhead+sppcspc | 0.931 | 0.755 | 0.883 | 0.723 | 0.83 | |
| C2 DW SWIN | 0.894 | 0.788 | 0.895 | 0.746 | 0.84 | 22.17 |
| C2head Dwhead sppcspc-g | 0.901 | 0.778 | 0.886 | 0.737 | 0.84 | 45.66 |
| C2head gosthesd sppc | 0.937 | 0.76 | 0.89 | 0.737 | 0.84 | 97.09 |
| C2head Dwhead swin 2 | 0.92 | 0.766 | 0.892 | 0.737 | 0.84 | 38.02 |
| C2head gosthesd sppc swin3 | 0.91 | 0.769 | 0.893 | 0.736 | 0.83 | 78.12 |
| yolov8x_DW_swin4_sppc | 0.915 | 0.776 | 0.894 | 0.71 | 0.84 | 60.98 |
| yolov8x_DW_swin1_sppc | 0.93 | 0.77 | 0.89 | 0.738 | ||
| yolov8x_DW_swin3_sppc | 0.921 | 0.763 | 0.895 | 0.734 | 0.83 | 45.05 |